解读Lawyer LLaMA,延申专业领域大模型微调:数据集构建,模型训练
解读Lawyer LLaMA,延申自己领域大模型微调:数据集构建,模型训练
项目地址link
自己领域的大模型微调,实现思路大都和这篇文章是一样的,有的是基于LLaMA,或者有的是基于Chinese-LLaMA,或者是其他开源的大模型,本文基于自己训练过程和参考了老刘说NLP中的《也读Lawyer LLaMA法律领域微调大模型:从训练数据、模型训练到实验效果研读》,从模型要达到的结果出发,倒推介绍整个流程,供大家参考,
欢迎大家点赞关注,一起交流
一、模型重点关注的能力

专业领域的大模型应用需要具备三种能力,
1.生成回答精确,没有歧义,在任何一个专业领域,有些仅仅替换一个词就可以影响其中表达的含义,有可能会导致巨大的不同的结果,例如,定金和订金在中文只有一字之差,但它们在合同法中的含义和法律效力却完全不同,
2.理解和区分专业术语,很多概念只出现在对应的专业领域,例如台区,即使是广泛使用的词汇,其含义在不同的专业领域也是不同的,因此要在具体的句子情景中表达出不同的含义,
3.能够识别分析专业场景的实际事件,现实世界中情景总是复杂多样的,模型需要具备法律术语和应用专业领域数据来分析具体问答能力,
为了能够实现这些能力,可以使用LLaMa模型来具体实现这些功能,
1.注入专业领域的知识,收集大量的专业领域原始文本,来让模型进行无监督训练学习。
2.训练学习特定领域的技能,有监督微调模型,教模型如何用适当的知识来解决特定领域的任务。
3.用外部知识进行增强,为了使模型能够更准确和精准回答,另外引入一个信息检索模块,在生成每个回复前,首先利用用户的查询和上下文信息来检索相关的标准信息,然后在这些专业领域的文章基础上做出回答。
二、数据准备
1.预训练语料库
为提升模型在中文专业领域的回答表现,防止模型在学习专业领域数据后灾难性遗忘问题,该工作采用两种语料对LLaMA模型进行持续性训练,
首先在一个普通的多语言语料库上训练模型,以提升模型的中文能力,然后使用另一个专业领域的语料库来增强模型。
(1)多语言通用语料库
由于LLaMA主要是在英语和其他语言语料库进行训练,因此它在理解和生成中文语句方面并不完美,
为了解决这个问题,同时收集中文预训练英文语料库进行记忆重放,以避免灾难性遗忘,
具体的,为构建中文通用语料库,可以从WuDaoCorpora、CLUECorpus2020和维基百科的简体中文版本中抽取文章。
对于英文通用语料,从C4语料库中抽取文章,
(2)中文专业领域语料库
各种途径获取专业领域的数据,并按照专业和来源分类,然后解析专业数据,生成各种专业数据有没有什么比例,解析的格式是按照段落进行分段学习,问答和文本生成有没有什么区别的对待
2.专业领域指令微调数据
(1)通用能力问答公开数据集地址
https://github.com/chaoswork/sft_datasets/tree/master
(2)将专业领域数据进行数据分类构建微调数据集,再细分为多轮对话和单论对话,并使用使用ChatGPT生成回复
为了保证单轮和多轮能力,同时收集单轮和多轮对话能力,同时为了提高生成式的回答准确性,将检索文章添加到提示词中,帮助ChatGPT生成准确的回复,
1)单论问答数据的构造
让chatgpt扮演回答者,回应客户的问题,并在输入提示中,生成的回答应该满足以下要求。
1.正确引用制度条文;
2.正确理解问句含义和制度条文给出有根据的分析;
3.全面回答并分析潜在的可能性;
4.提出适当为问题来挖掘事实以帮助进一步的回答;
5.使用平实的语言;
6.给出初步意见和咨询结论。
输入ChatGPT格式例如:
{
"instruction": "阅读以下文章:[],请回答:[]",
"input": "",
"output": "[答案]"
}
生成格式如下:

2)多轮问答数据的构造
生成多轮对话,需要设计两个不同的提示词,让ChatGPT分别扮演两个对话着角色,交替使用两个提示,连同对话历史作为ChatGPT的输入
下面是github具体开放的数据例子:

最后收集大约16000个单论和5000个2或3轮对话。
3.外部知识进行检索增强
对于单轮问答,使用文本检索工具选择前3篇相关文章输入到提示词中,
对于多轮问答,假设对话的主题不变,继续使用相同的3篇相关文章

或者不用训练模型,直接使用现成的文本检索框架,请参考我的另一篇博文
文本检索系统
或者使用LangChain地址
三、模型训练
微调开源模型LLaMA的步骤,如下图从S1逐步到S12
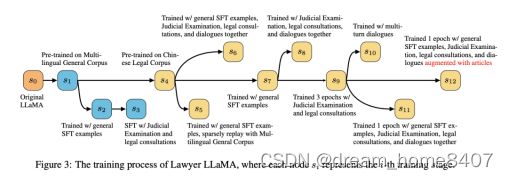
可以看到,训练是逐步进行的,并做了系列对比实验

表中显示了模型再不同阶段对NLP任务的表现,其中每个阶段的细节,可以参考上图,(1)~(6)代表不同阶段用于训练LLaMAd的预训练语料或监督微调数据集,(1)为多语言通用语料库,(2)为中文法律语料库,(3)为通用SFT数据集,(4)为司法考试和法律咨询,(5)为多轮法律对话,(6)为多轮法律对话中增加了检索的法律文章。勾号意味着相应的语料库/数据集已在前一阶段使用,而花号意味着该语料库/数据集在当前阶段被用于训练。
1、提高LLaMA的中文表达能力,S0-S1
为提升LLaMA的中文理解和生成能力,在中文通用语料库对LLaMA进行持续的预训练,Chinese-LLaMA采用的是使用汉字扩充词表的方式,
使用英文和中文的混合语料,模型很多复杂的推理能力可能来自于英文的训练,希望模型在持续的预训练中保持这些能力。
2、加入专业领域的知识S4
加入专业领域文本进行预训练,学习专业领域的能力
3、学习推理能力S7
收集专业领域真实场景的问答对,并要求ChatGPT为提供详细的解释,在训练过程中,QA对被视为指令,模型要求给出解释。
4、学习真实回复能力S9
让模型学习到单轮问答和多轮问答数据的能力,为用户的特定查询生成合适的回复。
5、提高模型回复可靠性S12
引入法律条文检索模块,使得模型能够产生可信的回复
这里初步的实验结果表明,即使模型在持续的训练阶段反复学习这些文章,它也不能在生成时正确的使用他们,它也可能引用不相关的法律条文,或者使用语句相似的词来代替一个术语,而这个词在法律领域中的含义是截然不同的意思
这时候,我们需要一个可靠的模型来召回和用户搜索词相关的三条文档,具体的,训练一个检索模型,数据集构成方面,收集一些用户的咨询问题,并要求专业人士为每个问题标注最多3篇必要文章回复,然后训练一个基于RoBERTa或者双塔模型的文本检索模型,该模型在被保留的测试集上可以达到0.85的召recall@1和0.94的recall@5。
并且,该工作还发现,直接将检索的文章和用户的问题串联起来作为新的输入,该模型会倾向于在其响应中引用所提供的文章,而不区分它们是否与当前情景正在相关
四、实验效果
收集不同领域的英文和中文通用任务,包括自然语言推理,情感分析,常识推理,对话问题回答等,测试模型在不同阶段推理表现
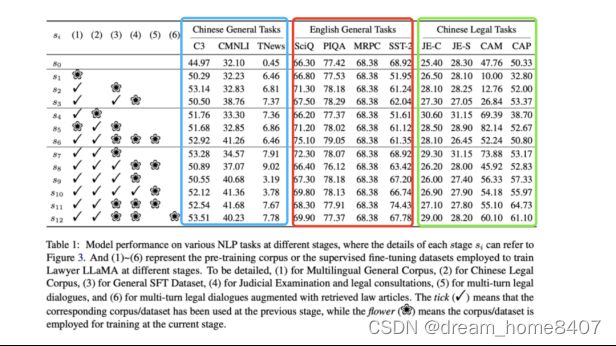
首先,比较s0和s1的结果,可以发现LLaMA在C3上获得了+5.3%的准确率;英语常识推理方面,s1在SciQ和PIQA的时的表现也不比s0差。这表明对多语种语料库的预训练可以增强模型对中文的表达能力,而不会牺牲其对英文的表达能力。
其次,比较s2和s3,s7和s9/s8/s6的CMNLI的结果,可以发现s3/s9/s8/s6的模型,经过司法考试的例子和法律咨询的微调,可以更好地处理中文NLI任务,准确率提高到+9.3%。
最后,该模型不能处理英语NLI和情感分析任务。在所有阶段,该模型只能对所有的MRPC实例输出Yes,而当不断地训练LLaMA时,它对SST-2也不能获得明显的改善,猜测这是因为没有足够的英语NLI和情感分析的SFT例子。那么该模型就不能理解这种任务的提示中的指令。
五、总结
大模型微调思路和数据集构建方式大致是如此,实操中发现项目最难的一点在于怎么构建自己的数据,无监督数据量太大,解析起来很费功夫,有监督的数据怎么完美构建等,因此需要数据梳理之处将数据有效分类很重要,
提高模型识别其最核心的结论在于,通过加入检索模块,可以提升问答的可靠性,并且通过引入垂直领域的预巡数据和微调数据,都可以提升其领域性能。但在具体实践中,还需要考虑到领域数据和通用数据的组成情况,以及与下游任务之间的对齐情况。