python-16-线程池和进程池python并发编程
Python ThreadPoolExecutor线程池
线程池的基本原理是什么?
利用Python快速实现一个线程池,非常简单
Python并发编程专题
1 并发编程
1.1 并发编程概念
一、为什么要引入并发编程?
场景1:一个网络爬虫,按顺序爬取花了1小时,采用并发下载减少到20分钟!
场景2:一个APP应用,优化前每次打开页面需要3秒,采用异步并发提升到每次200毫秒!
引入并发,就是为了提升程序运行速度。
二、有哪些程序提速的方法?

三、Python对并发编程的支持
(1)多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成。
(2)多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务。
(3)异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行。
(4)使用Lock对资源加锁,防止冲突访问。
(5)使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式。
(6)使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果。
(7)使用subprocess启动外部程序的进程,并进行输入输出交互。
Python并发编程有三种方式:
多线程Thread、多进程Process、多协程Coroutine。
1.2 线程进程协程
一、什么是CPU密集型计算、IO密集型计算?
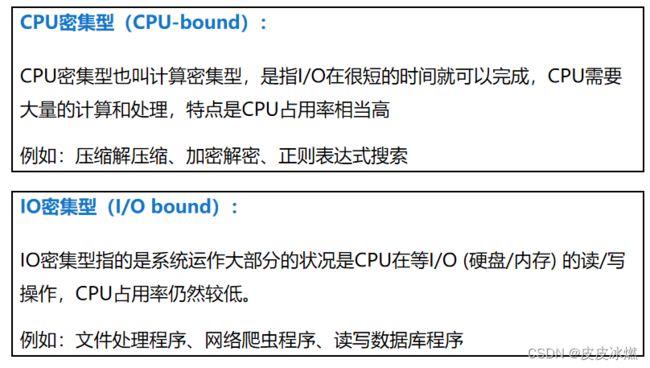
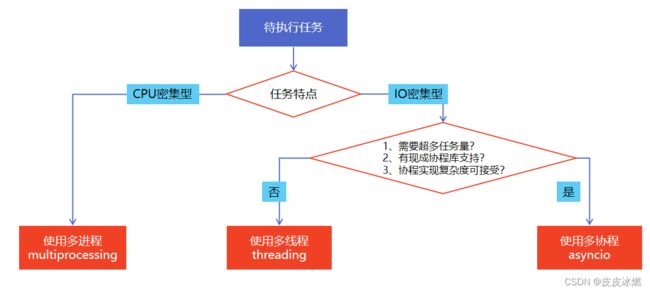
二、多线程、多进程、多协程的对比

三、怎样根据任务选择对应技术?
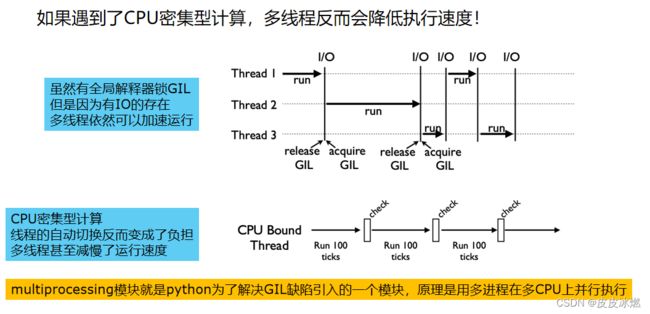
1.3 全局解释器锁GIL
一、Python速度慢的两大原因
相比C/C++/JAVA,Python确实慢,在一些特殊场景下,Python比C++慢100~200倍。由于速度慢的原因,很多公司的基础架构代码依然用C/C++开发,比如各大公司阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块。

全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。

二、为什么有GIL这个东西?

三、怎样规避GIL带来的限制?

2 爬虫代码blog
import requests
from bs4 import BeautifulSoup
# 列表推导式获取url列表
urls = [
f"https://www.cnblogs.com/sitehome/p/{page}"
for page in range(1, 50 + 1)
]
def craw(url):
# 爬取网页信息
r = requests.get(url)
return r.text
def parse(html):
# 解析网页信息class="post-item-title"
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
# 返回链接和文本信息
return [(link["href"], link.get_text()) for link in links]
if __name__ == "__main__":
for result in parse(craw(urls[2])):
print(result)
3 多线程加速爬虫
3.1 创建多线程的方法

3.2 单线程和多线程对比
import blog
import threading
import time
def single_thread():
print("single thread begin")
# 循环遍历,逐步执行
for url in blog.urls:
blog.craw(url)
print("single thread end")
def multi_thread():
print("multi thread begin")
threads = []
# 每个链接创建一个线程
for url in blog.urls:
threads.append(threading.Thread(target=blog.craw, args=(url,)))
# 逐个启动线程
for thread in threads:
thread.start()
# 等待运行结束(阻塞主线程)
for thread in threads:
thread.join()
print("multi thread end")
if __name__ == "__main__":
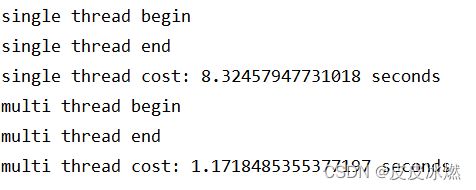
start = time.time()
single_thread()
end = time.time()
print("single thread cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start, "seconds")
4 生产者消费者模式多线程爬虫
4.1 生产者消费者架构
一、多组件的Pipeline技术架构
复杂的事情一般都不会一下子做完,而是会分很多中间步骤一步步完成。
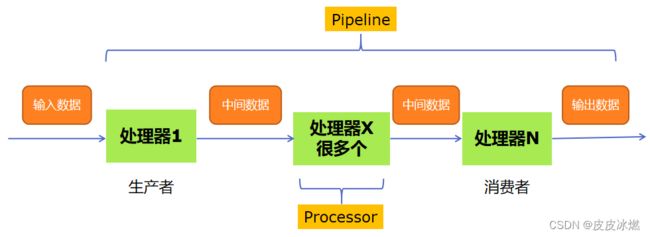
二、生产者消费者爬虫的架构

三、多线程数据通信的queue.Queue
queue.Queue可以用于多线程之间的、线程安全的数据通信。

4.2 生产者消费者代码
import queue
import blog
import time
import random
import threading
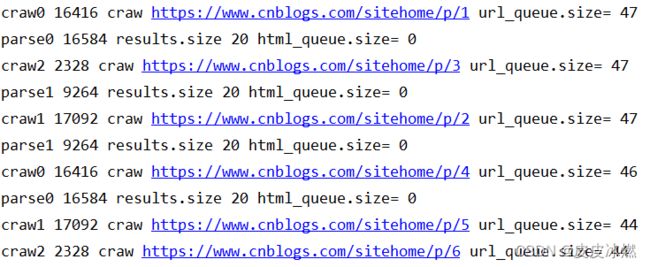
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get() # 从队列中获取url
html = blog.craw(url)
html_queue.put(html) # 爬取的网页信息写入队列
print(threading.current_thread().name,
threading.current_thread().ident,
f"craw {url}",
"url_queue.size=", url_queue.qsize())
# 随机休眠1或2秒
time.sleep(random.randint(1, 2))
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name,
threading.current_thread().ident,
f"results.size", len(results),
"html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == "__main__":
url_queue = queue.Queue() # 待爬取的url队列
html_queue = queue.Queue() # 爬取的网页信息队列
for url in blog.urls:
url_queue.put(url)
# 启动3个线程,爬取网页信息
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue),
name=f"craw{idx}")
t.start()
# 启动2个线程,写入文件
fout = open("02.data.txt", "w")
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout),
name=f"parse{idx}")
t.start()
print("jiesu")
5 线程安全问题
5.1 线程安全概念
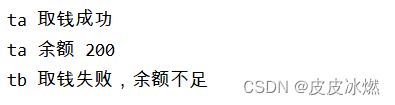
线程安全指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全。

import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
# with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name, "取钱成功")
account.balance -= amount
print(threading.current_thread().name, "余额", account.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()

5.2 解决线程安全问题

import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name, "取钱成功")
account.balance -= amount
print(threading.current_thread().name, "余额", account.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()
6 好用的线程池
(1)降低资源消耗。通过重复利用已创建的线程降低线程创建、销毁线程造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配、调优和监控。
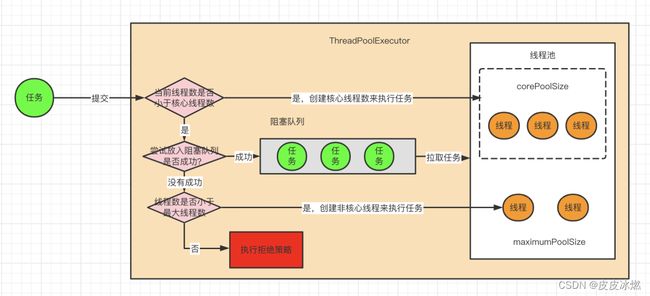
Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?以爬虫为例,需要控制同时爬取的线程数,例如创建了20个线程,而同时只允许3个线程在运行,但是20个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?
其实只需要三个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。
但是自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池)。
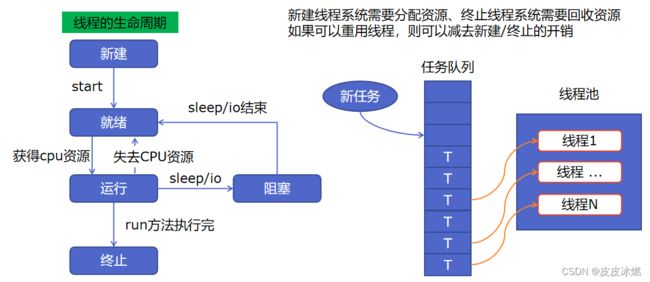
6.1 线程池原理
1、提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;
2、适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短;
3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题;
4、代码优势:使用线程池的语法比自己新建线程执行线程更加简洁。
6.2 ThreadPoolExecutor的用法

import concurrent.futures
import blog
# craw爬取
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(blog.craw, blog.urls)
htmls = list(zip(blog.urls, htmls))
for url, html in htmls:
print(url, len(html))
print("craw over")
# parse解析
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog.parse, html)
futures[future] = url
# 方式一:按顺序返回
for future, url in futures.items():
print(url, future.result())
# 方式二:先完成的先返回
# for future in concurrent.futures.as_completed(futures):
# url = futures[future]
# print(url, future.result())
6.3 在Web服务中使用线程池加速
一、Web服务的架构以及特点

使用线程池ThreadPoolExecutor的好处:
1、方便的将磁盘文件、数据库、远程API的IO调用并发执行;
2、线程池的线程数目不会无限创建(导致系统挂掉),具有防御功能。
二、代码用Flask实现Web服务并实现加速
5秒后出结果。
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_file():
time.sleep(5)
return "file result"
def read_db():
time.sleep(4)
return "db result"
def read_api():
time.sleep(3)
return "api result"
@app.route("/")
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file": result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result(),
})
if __name__ == "__main__":
app.run()
7 好用的进程池
7.1 多进程对比多线程
一、有了多线程threading,为什么还要用多进程multiprocessing?
二、多进程multiprocessing对比多线程threading

7.2 对比CPU密集计算速度
质数又称素数。一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数(规定1既不是质数也不是合数)。
CPU密集型计算:100次"判断大数字是否是素数"的计算。
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
PRIMES = [112272535095293] * 100
def is_prime(n):
if n == 1:
return False
for i in range(2, int(math.sqrt(n))+1):
if n % i == 0:
return False
return True
def single_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single thread, cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi thread, cost:", end - start, "seconds")
start = time.time()
multi_process()
end = time.time()
print("multi process, cost:", end - start, "seconds")

由于GIL的存在,多线程比单线程计算的还慢,而多进程可以明显加快执行速度。
7.3 在Web服务中使用进程池加速
http://127.0.0.1:5000/is_prime/1001245678353,3257385365375634564,3432434345657677
import flask
from concurrent.futures import ProcessPoolExecutor
import math
import json
app = flask.Flask(__name__)
def is_prime(n):
if n == 1:
return False
for i in range(2, int(math.sqrt(n))+1):
if n % i == 0:
return False
return True
@app.route("/is_prime/" )
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(",")]
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == "__main__":
process_pool = ProcessPoolExecutor()
app.run()

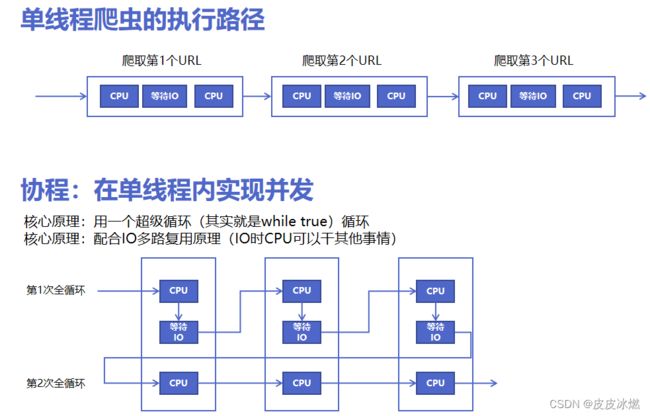
8 异步IO实现并发爬虫
8.1 协程原理

import asyncio
import aiohttp
import blog
# async语法进行声明为异步协程方法
# await语法进行声明为异步协程可等待对象
async def async_craw(url):
print("craw url: ", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url: {url}, {len(result)}")
# 获取事件循环
loop = asyncio.get_event_loop()
# 创建task列表
tasks = [
loop.create_task(async_craw(url))
for url in blog.urls]
import time
start = time.time()
# 执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
8.2 使用信号量控制爬虫并发度

import asyncio
import aiohttp
import blog
semaphore = asyncio.Semaphore(10)
async def async_craw(url):
async with semaphore:
print("craw url: ", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
await asyncio.sleep(2)
print(f"craw url: {url}, {len(result)}")
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog.urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
附录 ThreadPoolExecutor线程池
常用函数
将函数提交到线程池里面运行的时候,会自动创建Future对象并返回。这个Future对象里面就包含了函数的执行状态(比如此时是处于暂停、运行中还是完成等)。并且函数在执行完毕之后,还会调用future.set_result将自身的返回值设置进去。
(1)创建一个线程池,可以指定max_workers参数,表示最多创建多少个线程。如果不指定,那么每提交一个函数,都会为其创建一个线程。
在启动线程池的时候,肯定是需要设置容量的,不然处理几千个函数要开启几千个线程。
(2)通过submit即可将函数提交到线程池,一旦提交,就会立刻运行。因为开启了一个新的线程,主线程会继续往下执行。至于submit的参数,按照函数名,对应参数提交即可。
(3)future相当于一个容器,包含了内部函数的执行状态。
(4)# 函数执行完毕时,会将返回值设置在future里,也就是说一旦执行了 future.set_result,那么就表示函数执行完毕了,然后外界可以调用result拿到返回值。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
print(future) #
print(future.running()) # 函数是否正在运行中True
print(future.done()) # 函数是否执行完毕False
time.sleep(3) # 主程序也sleep 3秒,显然此时函数已经执行完毕了
print(future) # 返回值类型是str
print(future.running()) # False
print(future.done()) # True
print(future.result())
添加回调
注意: future.result(),这一步是会阻塞的。future.result()就是为了获取函数的返回值。所以只能先等待函数执行完毕,将返回值通过set_result设置到future里面之后,外界才能调用future.result()获取到值。
future有两个被保护的属性,分别是_result和_state。显然_result用于保存函数的返回值,而future.result()本质上也是返回_result属性的值。而_state属性则用于表示函数的执行状态,初始为PENDING,执行中为RUNING,执行完毕时被设置为FINISHED。
调用future.result()的时候,会判断_state的属性,如果还在执行中就一直等待。当_state 为FINISHED的时候,就返回_result 属性的值。
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
start = time.perf_counter()
future.result()
end = time.perf_counter()
print(end - start) # 3.009
因为我们不知道函数什么时候执行完毕。所以最好的办法还是绑定一个回调,当函数执行完毕时,自动触发回调。
需要注意的是,在调用 submit 方法之后,提交到线程池的函数就已经开始执行了。而不管函数有没有执行完毕,我们都可以给对应的 future 绑定回调。
如果函数完成之前添加回调,那么会在函数完成后触发回调。
如果函数完成之后添加回调,由于函数已经完成,代表此时的 future 已经有值了,或者说已经set_result了,那么会立即触发回调。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
def callback(f):
print("我是回调",f.result())
executor = ThreadPoolExecutor()
future = executor.submit(task, "自我休眠", 3)
# time.sleep(5)
# 绑定回调,3秒之后自动调用
future.add_done_callback(callback)
如果我们需要启动多线程来执行函数的话,那么不妨使用线程池。每调用一个函数就从池子里面取出一个线程,函数执行完毕就将线程放回到池子里以便其它函数执行。如果池子里面空了,或者说无法创建新的空闲线程,那么接下来的函数就只能处于等待状态了。
附录 ProcessPoolExecutor进程池
concurrent.futures不仅可以用于实现线程池,还可以用于实现进程池,两者的 API 是一样的,但工作中很少会创建进程池。