kafka-2.集群搭建,topic+partition消费逻辑梳理
kafka
集群搭建
这里博主用的kafka2.6.0
https://archive.apache.org/dist/kafka/2.6.0/kafka_2.13-2.6.0.tgz
上传服务器
解压安装
$ tar -xzf kafka_2.13-2.6.0.tgz
$ cd kafka_2.13-2.6.0/
要修改的配置项
broker.id=0
listeners=PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
修改Linux 命令目录
vi /etc/profile
export KAFKA_HOME=/home/vmuser/kafka_2.13-2.6.0
export PATH=$PATH:${KAFKA_HOME}/bin
source /etc/profile
启动zookeeper
进入客户端目前目录下有
[zk: localhost:2181(CONNECTED) 1] ls /
[bbb, ooxx, zookeeper]
配置完成后启动kafka
kafka-server-start.sh server.properties
[zk: localhost:2181(CONNECTED) 4] ls /
[admin, bbb, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, ooxx, zookeeper]
[zk: localhost:2181(CONNECTED) 3] get -s /controller
{"version":1,"brokerid":0,"timestamp":"1646317349694"}
cZxid = 0x50000001c
ctime = Thu Mar 03 22:22:29 CST 2022
mZxid = 0x50000001c
mtime = Thu Mar 03 22:22:29 CST 2022
pZxid = 0x50000001c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x20d24b2a3e60000
dataLength = 54
numChildren = 0
[zk: localhost:2181(CONNECTED) 8] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 9] ls /brokers/topics
[]
这个时候博主觉得这种配置有点杂乱,如果有不同的人配置kafka,或者别的东西怎么办,不能都在根目录
- 进入zk客户端 删除目录
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183/kafka
- 重新启动kafka 发现出问题
The broker is trying to join the wrong cluster. Configured zookeeper.connect
zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:223)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44)
at kafka.Kafka$.main(Kafka.scala:82)
at kafka.Kafka.main(Kafka.scala)
删除kafka 配置文件下的log 目录日志文件。重新启动就行
重新进入zk
[zk: localhost:2181(CONNECTED) 0] ls /
[kafka, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /kafka
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification]
创建分区
[root@localhost vmuser]# kafka-topics.sh --zookeeper node1:2181/kafka --create --topic ooxx --partitions 2 --replication-factor 2
Created topic ooxx.
create Create a new topic.
Partition Count:partition 个数。
Replication-Factor:副本个数。
Partition:partition 编号,从 0 开始递增。
Leader:当前 partition 起作用的 breaker.id。
Replicas: 当前副本数据所在的 breaker.id,是一个列表,排在最前面的其作用。
Isr:当前 kakfa 集群中可用的 breaker.id 列表。
[root@localhost vmuser]# kafka-topics.sh --zookeeper node1:2181/kafka --list
ooxx
[root@localhost vmuser]# kafka-topics.sh --zookeeper node1:2181/kafka --describe ooxx
Topic: ooxx PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: ooxx Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2
Topic: ooxx Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
[root@localhost vmuser]#
消费端
[root@localhost config]# kafka-console-consumer.sh
This tool helps to read data from Kafka topics and outputs it to standard output.
Option Description
------ -----------
--bootstrap-server <String: server to REQUIRED: The server(s) to connect to.
connect to>
--consumer-property <String: A mechanism to pass user-defined
consumer_prop> properties in the form key=value to
the consumer.
--consumer.config <String: config file> Consumer config properties file. Note
that [consumer-property] takes
precedence over this config.
--enable-systest-events Log lifecycle events of the consumer
in addition to logging consumed
messages. (This is specific for
system tests.)
--formatter <String: class> The name of a class to use for
formatting kafka messages for
display. (default: kafka.tools.
DefaultMessageFormatter)
--from-beginning If the consumer does not already have
an established offset to consume
from, start with the earliest
message present in the log rather
than the latest message.
--group <String: consumer group id> The consumer group id of the consumer.
--help Print usage information.
--isolation-level <String> Set to read_committed in order to
filter out transactional messages
which are not committed. Set to
read_uncommitted to read all
messages. (default: read_uncommitted)
--key-deserializer <String:
deserializer for key>
--max-messages <Integer: num_messages> The maximum number of messages to
consume before exiting. If not set,
consumption is continual.
--offset <String: consume offset> The offset id to consume from (a non-
negative number), or 'earliest'
which means from beginning, or
'latest' which means from end
(default: latest)
--partition <Integer: partition> The partition to consume from.
Consumption starts from the end of
the partition unless '--offset' is
specified.
--property <String: prop> The properties to initialize the
message formatter. Default
properties include:
print.timestamp=true|false
print.key=true|false
print.value=true|false
key.separator=<key.separator>
line.separator=<line.separator>
key.deserializer=<key.deserializer>
value.deserializer=<value.
deserializer>
Users can also pass in customized
properties for their formatter; more
specifically, users can pass in
properties keyed with 'key.
deserializer.' and 'value.
deserializer.' prefixes to configure
their deserializers.
--skip-message-on-error If there is an error when processing a
message, skip it instead of halt.
--timeout-ms <Integer: timeout_ms> If specified, exit if no message is
available for consumption for the
specified interval.
--topic <String: topic> The topic id to consume on.
--value-deserializer <String:
deserializer for values>
--version Display Kafka version.
--whitelist <String: whitelist> Regular expression specifying
whitelist of topics to include for
consumption
- 使用 replica-assignment 参数手动指定 Topic Partition Replica 与 Kafka Broker 之间的存储映射关系。
bin/kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic topicName
因为博主上面没有配置监听端口所以出错
修改程本机ipo
listeners=PLAINTEXT://:9092
消费端
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092 --topic ooxx --group kafkatest
生产者
kafka-console-producer.sh --broker-list node3:9092 --topic ooxx
>hello
查看组的
kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group kafkatest
![]()
zk 里面看到提交数,自动为维护offsets在老版本中是通过zk去维护的
[zk: localhost:2181(CONNECTED) 6] ls /kafka/brokers/topics
[__consumer_offsets, ooxx]
查看分区数
[zk: localhost:2181(CONNECTED) 9] get /kafka/brokers/topics/__consumer_offsets
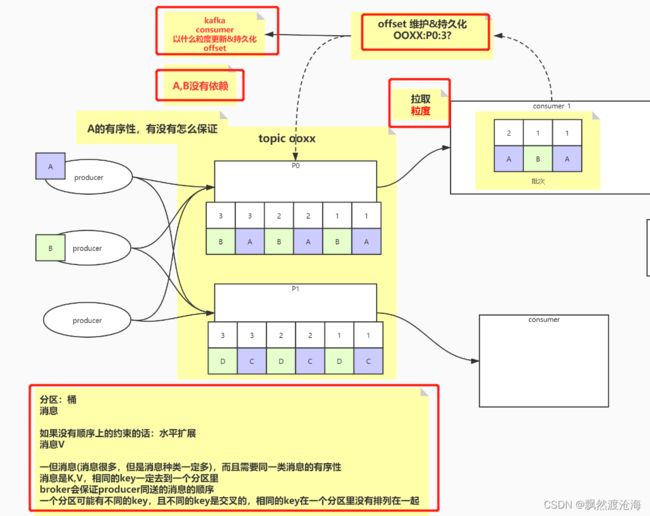
topic+partition消费逻辑梳理
消息顺序性
分区:桶
如果没有顺序上的约束的话:水平扩展
一但消息(消息很多,但是消息种类一定多),而且需要同一类消息的有序性
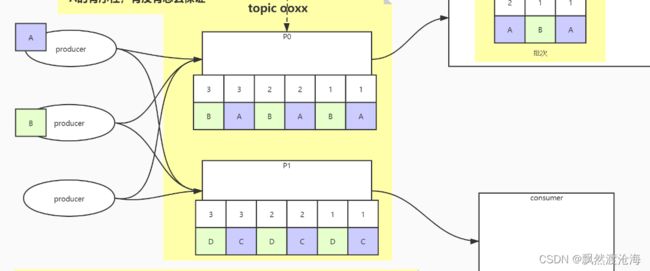
消息是K,V,相同的key一定去到一个分区里!
broker会保证producer同送的消息的顺序
一个分区可能有不同的key,且不同的key是交叉的,相同的key在一个分区里没有排列在一起
如何保证消息顺序性呢?
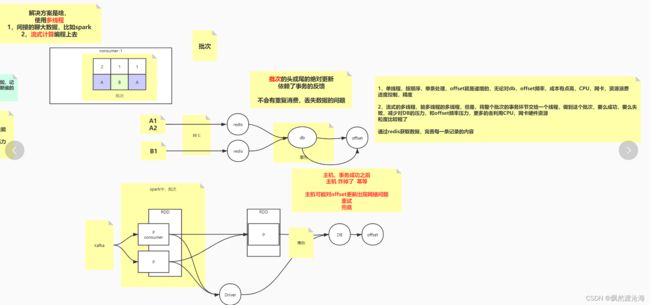
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
是把当前分区的消息再细化一次:比如消息里是带table名的行记录,就按table名拆分,比如分区1里有90条消息,来自ABC三个表,消费者接口顺序性的一边消费一边按表名划分填入到ABC三个队列,A队列放A表的数据,B队列是B表的数据,C是C的,然后开3个线程,对应3个队列去执行后续操作,这3个线程谁先谁后都不干扰自己写入数据库对应的三个表。
虽然在区分放入哪个队列的时候是串行的,但放入到队列后,下发到后续执行比如落库,就是并行的了,虽然区分队列时有点损失时效,但好在下发到mysql时是并行的,弥补了时效,还保证了有序消费。
拉取v.s推送
- 推送说的是server,主动去推送,网卡打满。。。
- 拉取,consumer,自主,按需,去订阅拉取server的数据
如果是拉取的话,粒度如何处理?
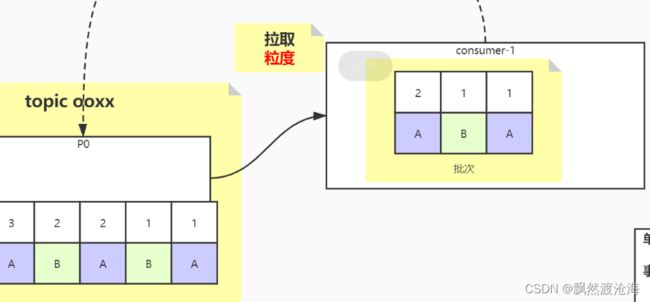
必须按顺序处理前提
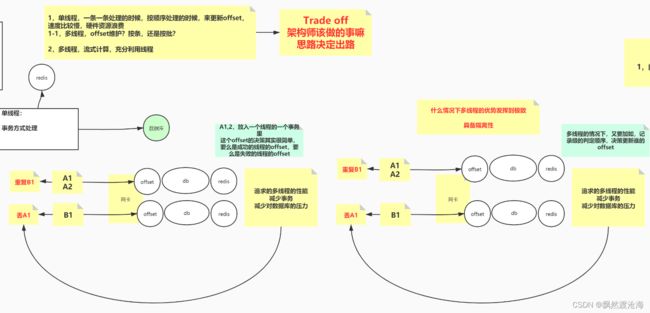
consumer是多线程的还是单线程去处理?offset如何维护呢
其实单线程多线程都可以!
offset 在以前版本是丢给zk处理,后来使用的redis或者数据库处理,在后面就是由自己维护,那么offset的偏移量怎么维护?
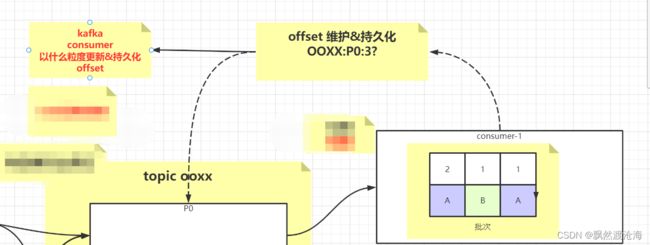 offset维护
offset维护
1,单线程,一条一条处理的时候,按顺序处理的时候,来更新offset,速度比较慢,硬件资源浪费
1-1,多线程,offset维护?按条,还是按批?
多线程下如果消费了A1,B1 失败了,该如何维护?从头开始,就面临重复消费,从b1开始,就丢失了A1

别想着每条都加锁?每条都加锁那不成了单线程吗?多线程的优点发挥到极致就是具有隔离性!
解决方法:
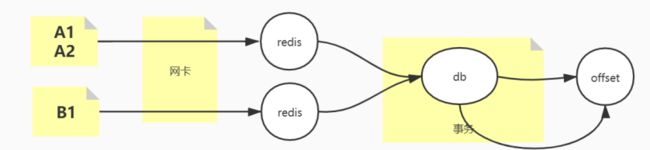
2,多线程,流式计算,充分利用线程