深入浅出RPC原理
转自:https://ketao1989.github.io/2016/12/10/rpc-theory-in-action/
深入浅出RPC原理
远程过程调用(Remote Procedure Call,简称RPC),在微服务大行其道的今天,得到了广泛的应用。因此,在分布式系统服务群中开发应用,了解RPC一些原理和实现架构,还是很有必要的。本文,将从大的框架层面来聊聊RPC原理和实现。
前言
远程过程调用RPC,就是客户端基于某种传输协议通过网络向服务提供端请求服务处理,然后获取返回数据(对于ONE WAY模式则不返还响应结果);而这种调用对于客户端而言,和调用本地服务一样方便,开发人员不需要了解具体底层网络传输协议。简单讲,就是本地调用的逻辑处理的过程放在的远程的机器上,而不是本地服务代理来处理。
目前,Java界的RPC中间件百家争鸣,国内开源的就有阿里的Dubbo(当当二次开发的DubboX),新浪Motan;国外跨语言的有Facebook的Thrift, Google的gRpc等。
LPC & IPC
既然存在RPC这种远程过程调用,必然会有与之对应的本地过程调用了。本地过程调用在不同的操作系统中,叫法不同,使用方式也不太一样。在Windows编程中,称为LPC;在linux编程中,更习惯称之为IPC,即进程间通信。
但是,不管如何,其本质上就是本地机器上的不同进程之间通信协作的调用方式。
服务端开发,一般我们基于Linux,所以这里简单介绍下Linux环境下 IPC实现方式:
- 管道
- 共享内存
- 信号量
- Socket套接字
除此之外,还有消息队列和信号两种实现进程间通信的方式。
信号很容易理解,比如我们在控制台输入的CTRL + C来向执行的进程发送kill信号来结束该进程。对于信号,一般我们再终端交互窗口中使用比较多,在服务端开发中很少涉及。
Linux提供的消息队列和各种分布式MQ不同,它是在内核中使用链表结构来保持消息的队列,然后其他进程从内核的消息队列中获取消息。目前,Linux官方不太推荐使用,将渐渐被淘汰。
管道
管道命令,在我们的linux shell中经常使用,一般,我们使用|操作符来保证两个命令之间的数据通信。比如,使用命令:
ps -ef | grep java | xargs echo
管道命令,其实内部实现就是使用的linux管道接口,每个命令其实是一个进程,各个进程的标准输出STDOUT,作为下一个进程的标准输入STDIN。
Linux管道包含:匿名管道和命名管道。
- 匿名管道:只能父子进程间通信。使用pipe()方法来创建:
#includeint pipe(int filedis[2]); 参数filedis返回两个文件描述符:filedes[0]为读而打开,filedes[1]为写而打开。filedes[1]的输出是filedes[0]的输入
- 命名管道:可以在单台机器内的任何一组进程间进行通信。一般我们使用mkfifo()来创建命名管道:
#include#include int mkfifo(const char * pathname,mode_t mode) 成功返回0,失败返回-1。成功返回之后,pathname其实就可以看着一个管道文件操作(当然并没有真实文件在磁盘存在),对于文件操作的方法例如open,read,write都适用于fifo命名通道。
信号量Semaphore
Linux中的信号量和Java中的信号量一样,其主要用处是同步协作。
信号量其实就是一个比较特殊的变量,然后对它的操作都是原子进行的,并且一般只提供两种方法:P和V操作(在java中为wait()和notify())。
- P(sv):如果sv的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行;
- V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1。
linux对外提供的API接口方法如下所示:
struct sem {
short sempid;/* pid of last operaton */
ushort semval;/* current value */
ushort semncnt;/* num procs awaiting increase in semval */
ushort semzcnt;/* num procs awaiting semval = 0 */
}
#include
#include
#include
//首先获取一个信号量,只有该方法可以才能直接使用key,其他方法必须先semget然后才能使用信号量
int semget(key_t key, int nsems, int flag);
//对信号量进行操作,直接控制信号量信息,比如删除信号量
int semctl(int semid, int semnum, int cmd, union semun arg);
//改变信号量的值,P,V操作都是通过该方法
int semop(int sem_id, struct sembuf *sem_opa, size_t num_sem_ops);
信号量的主要作用就是同步,所以我们一般是使用共享内存方式完成进程间通信,而在此过程中通过信号量来完成多进程间的同步协调机制。
共享内存
由于同一台机器的硬件设备一般对于同一个系统来说,都是共享的。所以使用内存来完成进程间通信开发的思路,必然是很容易想到的,但是未必容易做到。
众所周知,进程和线程最大的区别就是一些资源是否隔离。也就是说,不同的进程,其内存资源使用是隔离独立的,每个进程有自己的一套内存地址映射逻辑,也即是系统是无法直接从不同进程的相同虚拟内存地址找到共同的物理内存地址的,这样,就无法像线程一样,简单把数据对象设置为static然后线程间就可以共享获取了。
因此,Linux对外提供了共享内存的方法来完成进程间通信。
共享内存是最有效的进程间通信方式。其对外提供的API如下所示:
#include
#include
#include
//创建共享内存空间,大小为size
int shmget(key_t key, size_t size, int shmflg);
//所有需要使用共享内存通信的进程,映射到自身的内存地址空间中
void *shmat(int shmid, void *addr, int flag);
//从当前进程地址空间中分离该共享内存
int shmdt(const void *shmaddr);
//控制共享内存的,比如删除该共享内存空间等
int shmctl(int shm_id, int command, struct shmid_ds *buf);
从上面的方法可以很显然的看出,进程间的内存地址空间是独立隔离的(内核地址空间由于虚拟地址和物理地址是一致的,所以在进程间这块地址空间也是一致的,不过我们操作的都是用户空间的内存,所以不考虑这块)。当我们想要共享操作,必须要把物理内存分别绑定到对应进程的地址空间,才能共享操作。
使用的时候,很简单。
shmat方法返回一个void *就可以强转某个指定的struct,然后直接操作该对象结构体即可。由于共享,所以需要考虑多线程同步安全问题。
Socket套接字
从上面的几个API方法可以看到都是利用单机同用一套资源,然后各自进程的资源之间通过内核方式或者内存方式协作完成单机多进程间通信。
此外,还有一种方式来完成进程间通信,就是套接字socket。Socket一般情况下是用在不同的两台机器的不同进程之间通信的,当Socket创建时的类型为 AF_LOCAL或AF_UNIX时,则是本地进程通信了(当然你也可以直接使用网络套接字,如果你觉得走下网络更酷,或者以后便于服务分离)。
关于Socket的API介绍,这里就省略了。服务端/客户端模式的介绍和示例相对很常见,也很容易开发和理解。
从使用网络套接字Socket来实现进程间通信这个角度来说,其和RPC并没有什么不同了,所以有些文献分类时,说广义来讲RPC也应该包括LPC(IPC),因为从大的来讲,单机进程通信其实算是远程过程调用的一种特殊简化的方式而已。
当然,本文还是觉得还是区别开比较通用,也便于理解。
如在Socket介绍的那样,本地过程调用很多情况下都是依赖操作系统对外提供的API来协调操作某个共享资源来完成进程间的数据交换。
如果不依赖单机共享资源,就只有Socket接口。因此,如果要扩展到分布式环境下的进程间通信,那就只能使用网络套接字来完成。
说完单机的服务调用,在互联网时代,自然要讲web服务(Web Service)了。
Web Service技术
Web Service一般有两种定义:
- 特指 W3C组织制定的
web service规范技术。其包括SOAP(一个基于XML的可扩展消息信封格式,需同时绑定一个网络传输协议。这个协议通常是HTTP或HTTPS,但也可能是SMTP或XMPP)、WSDL(一个XML格式文档,用以描述服务端口访问方式和使用协议的细节。通常用来辅助生成服务器和客户端代码及配置信息)和UDDI(一个用来发布和搜索WEB服务的协议,应用程序可借由此协议在设计或运行时找到目标WEB服务)。从上面三个定义就可以看出,这种规范技术是一个重量级的协议。- 泛指网络系统对外提供web服务所使用的技术。这里,我们主要是基于该定义来理解。
一般而言,技术体系,必然是服务于架构体系的。不同的架构,所约定的技术结构设计还是有些区别的。
因此,要了解web服务技术,必然要先了解其服务于哪个架构体系;也就是说,先去了解技术产生的架构背景。
SOA & 微服务
在分布式网络服务架构体系中,最火的莫过于 SOA(面向服务架构,Service-Oriented Architecture)和微服务。
嗯,一般将服务化架构,必然会扯到全家桶设计升级的故事。
简化版是这样子的:
-
在很久很久以前,网络应用也是单机部署的,所有的业务代码全部都在一个大项目内,然后更改一个逻辑就需要重启部署应用,停止对外服务。
-
然后,这样子肯定不行的,就有了多机部署,通过Nginx或者其他代理/均衡软件来分发请求到相同服务的不同机器上,当其中一台机器停机部署时,请求全部打到其他机器上去。但是这个时候,所有机器上的代码还是一套。
-
后来,机器不断升级,但是业务不断变多,项目代码越来越大,更改一个地方编译打包部署时间非常长,于是,我们就把一些独立隔离开的业务代码分成多个项目。但是,实现业务逻辑的时候,必然有一些功能和数据是多个业务都会用到的,简单以前的代码copy过来,数据就直接操作数据库。但是,当有个公用的功能需要更改时,就发现所有相关业务都需要更改,并且数据库上的操作,还会带来其他同步兼容等等问题。
-
于是,就出现了SOA,也就是基于服务的架构设计理念。SOA的设计理念,就是把所有的服务都对外以HTTP或者其他协议方式对外暴露,绝对
不允许相同的服务在不同的业务系统独立一套,然后共用底层数据库。服务化的设计系统,所有拆分的业务,彼此之间都通过暴露的服务接口通信,操作对方的数据。这样,各个业务系统之间开始独立自主的向着美好的方向发展了。 -
再后来,单个业务发展的越来越好,提供的功能也越来越多,这样一个业务系统的代码也变得很大了,开发人员也越来越多。于是乎,单个业务系统内部就存在问题了,当然,我们也可以拆分成不同的业务系统来开发发展。但是,单个业务系统,很多的公用逻辑都是一些业务细节,并不好独立成业务系统;此外,单个业务系统开发人员都很容易交流,因此,对于内部业务系统的架构设计,就出现了
微服务Micro-Service了。我们把单个业务系统中一些功能细节的结构封装成服务,大的对外业务系统,组装各个微服务的接口数据,然后提供SOA服务。
因此,SOA其实和微服务,从我的视角来看,其实就是 业务外部和内部服务的不同架构设计而已,其技术框架很大程度上都可以通用。其区别如下图:

从上面发展历程可以看到,SOA一般使用SOAP或者REST方式来提供服务,这样外部业务系统可以使用通用网络协议来处理请求和响应,而微服务,还可以有一些私有的协议方式来提供服务,例如基于自定义协议的RPC框架。RPC使得调用服务简单,但是需要一些其他耗时间的交流协调工作,这适合微服务的场景,但是不一定适合SOA场景了。
web服务技术结构
先给出一个web服务的技术体系结构图:
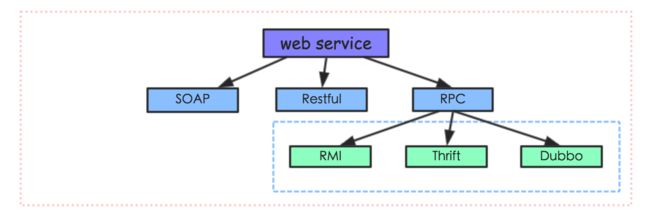
web service被W3C设立规范之初,SOAP方案就被提出来。但是,随着服务化技术和架构的发展,SOAP多少有点过于复杂,因此就出现了简化版的REST方案。此后,由于分布式服务应用越来越大,对性能和易用性上面要求越来越大,因此就出现了RPC框架(很多时候,RPC并不被当做一种web service方案。在绝大部分博客中,介绍web service 只会讨论 SOAP和REST,主要是其基本上都是基于SOA来介绍服务方案)。
SOAP
SOAP,全称为 Simple Object Access Protocol,也就是 简单对象访问协议。跟着web service一起出来的,说明历史悠久,不过感觉现在也慢慢要淘汰了。
SOAP,是基于XML数据格式来交换数据的;其内部定义了一套复杂完善的XML标签,标签中包含了调用的远程过程、参数、返回值和出错信息等等,通信双方根据这套标签来解析数据或者请求服务。与SOAP相关的配套协议是WSDL (Web Service Description Language),用来描述哪个服务器提供什么服务,怎样找到它,以及该服务使用怎样的接口规范,类似我们现在聊服务治理中的服务发现功能。
因此,SOAP服务整体流程是:首先,获得该服务的WSDL描述,根据WSDL构造一条格式化的SOAP请求发送给服务器,然后接收一条同样SOAP格式的应答,最后根据先前的WSDL解码数据。绝大多数情况下,请求和应答使用HTTP协议传输,那么发送请求就使用HTTP的POST方法。
REST
REST,全称 REpresentational State Transfort,也就是 表示性状态转移。由于SOAP方案过于庞大复杂,在很多简单的web服务应用场景中,轻量级的REST就出现替代SOAP方案了。
和SOAP相比,REST只是对URI做了一些规范,数据才有JSON格式,底层传输使用HTTP/HTTPS来通信,因此,所有web服务器都可以快速支持该方案;开发人员也可以快速学习和使用。
SOAP & REST
从命名来看,SOAP是一种协议,而REST只是一种方案。协议的设计很多时候,从上而下一整套都是新的,需要设计开发专门的工具支持;而方案相对就是基于目前以后的工具来做一些设计和约束,这就是为什么REST快速替换了SOAP的地位。
REST特点:
- 由于数据返回格式是自定义的,绝大部分使用JSON,这种数据结构节省带宽,并且前端JavaScript能天生支持。
- 无状态,基于HTTP协议,所以只能适应无状态场景。
SOAP特点:
- 协议有安全性的一些规范。
- 基于xml的标签约束,而且也不要去底层是HTTP传输,所以支持有状态的场景。
RPC家族
RPC家族中,RMI是Java制定的远程通信协议。而后,基本上RPC框架都或多或少有RMI的影子(当然,其实主要是RPC本身的实现方式就是这样子了-_-)。RMI既然是Java的标准RPC组件,那必然其他编程语言就无法使用了;因此,Thrift这种基于IDL来跨语言的RPC组件就出现了。Thrift的使用者,只需要按照Thrift官方规定的方式来写API结构,然后生成对应语言的API接口,继而就可以跨语言完成远程过程调用了。但是,作为服务化的组件,如果没有服务治理来完成大规模应用集群中服务调用管理工作,则运维工作则是非常繁重的,因此类似dubbo这种包含服务治理的RPC组件出现了。
下面,就来介绍RPC组件。
RPC介绍
RMI作为Java自带的官方RPC组件,单独介绍;然后我们来看看通用RPC实现结构。
RMI介绍
RMI,全称是Remote Method Invocation,也就是远程方法调用。在JDK 1.2的时候,引入到Java体系的。当应用比较小,性能要求不高的情况下,使用RMI还是挺方便快捷的。
下面先看看RMI的调用流程。

其中,有些概念需要说明:
stub(桩):stub实际上就是远程过程在客户端上面的一个代理proxy。当我们的客户端代码调用API接口提供的方法的时候,RMI生成的stub代码块会将请求数据序列化,交给远程服务端处理,然后将结果反序列化之后返回给客户端的代码。这些处理过程,对于客户端来说,基本是透明无感知的。
remote:这层就是底层网络处理了,RMI对用户来说,屏蔽了这层细节。stub通过remote来和远程服务端进行通信。
skeleton(骨架):和stub相似,skeleton则是服务端生成的一个代理proxy。当客户端通过stub发送请求到服务端,则交给skeleton来处理,其会根据指定的服务方法来反序列化请求,然后调用具体方法执行,最后将结果返回给客户端。
registry(服务发现):rmi服务,在服务端实现之后需要注册到rmi server上,然后客户端从指定的rmi地址上lookup服务,调用该服务对应的方法即可完成远程方法调用。registry是个很重要的功能,当服务端开发完服务之后,要对外暴露,如果没有服务注册,则客户端是无从调用的,即使服务端的服务就在那里。
下面给出一个简单的Java示例来show code下。
/**
* 接口必须继承RMI的Remote
*/
public interface RmiService extends Remote {
/**
* 必须有RemoteException,才是RMI方法
*/
String hello(String name) throws RemoteException;
}
/**
* UnicastRemoteObject会生成一个代理proxy
*/
public class RmiServiceImpl extends UnicastRemoteObject implements RmiService {
public RmiServiceImpl() throws RemoteException {
}
public String hello(String name) throws RemoteException {
return "Hello " + name;
}
}
/**
* 服务端server启动
*/
public class RmiServer {
public static void main(String[] args) {
try {
RmiService service = new RmiServiceImpl();
//在本地创建和暴露一个注册服务实例,端口为9999
LocateRegistry.createRegistry(9999);
//注册service服务到上面创建的注册实例上
Naming.rebind("rmi://127.0.0.1:9999/service1",service);
}catch (Exception e){
e.printStackTrace();
}
System.out.println("------------server start-----------------");
}
}
/**
* 客户端调用rmi服务
*/
public class RmiClient {
public static void main(String[] args) {
try {
// 根据注册的服务地址来查找服务,然后就可以调用API对应的方法了
RmiService service = (RmiService)Naming.lookup("rmi://localhost:9999/service1");
System.out.println(service.hello("RMI"));
}catch (Exception e){
e.printStackTrace();
}
}
}
上面一些核心的代码已经在注释中给了说明。
通用RPC架构
一般,远程过程调用RPC就是本地动态代理隐藏通信细节,通过组件序列化请求,走网络到服务端,执行真正的服务代码,然后将结果返回给客户端,反序列化数据给调用方法的过程。
RPC具体调用流程如下所示: 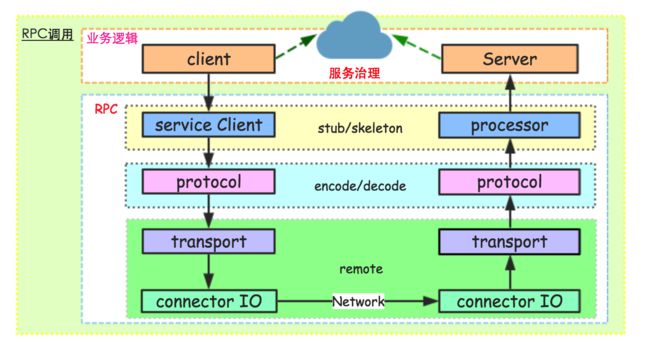
通用的RPC组件一般包括以下一些模块:
serviceClient:这个模块主要是封装服务端对外提供的API,让客户端像使用本地API接口一样调用远程服务。一般,我们使用动态代理机制,当客户端调用api的方法时,serviceClient会走代理逻辑,去远程服务器请求真正的执行方法,然后将响应结果作为本地的api方法执行结果返回给客户端应用。类似RMI的stub模块。
processor:在服务端存在很多方法,当客户端请求过来,服务端需要定位到具体对象的具体方法,然后执行该方法,这个功能就由processor模块来完成。一般这个操作需要使用反射机制来获取用来执行真实处理逻辑的方法,当然,有的RPC直接在server初始化的时候,将一定规则写进Map映射中,这样直接获取对象即可。类似RMI的skeleton模块。
protocol:协议层,这是每个RPC组件的核心技术所在。一般,协议层包括编码/解码,或者说序列化和反序列化工作;当然,有的时候编解码不仅仅是对象序列化的工作,还有一些通信相关的字节流的额外解析部分。序列化工具有:hessian,protobuf,avro,thrift,json系,xml系等等。在RMI中这块是直接使用JDK自身的序列化组件。
transport:传输层,主要是服务端和客户端网络通信相关的功能。这里和下面的IO层区分开,主要是因为传输层处理server/client的网络通信交互,而不涉及具体底层处理连接请求和响应相关的逻辑。
I/O:这个模块主要是为了提高性能可能采用不同的IO模型和线程模型,当然,一般我们可能和上面的transport层联系的比较紧密,统一称为remote模块。
此外,还有业务代码自己去实现的client和server层。client当需要远程调用服务时,会首先初始化一个API接口代理对象,然后调用某个代理方法。server在对外暴露服务时,需要首先实现对应API接口内部的方法,当请求过来时,通过反射找到对应的实例对象,执行对应的业务代码。
简单RPC组件实现
介绍完RPC相关结构和概念之后,给一个简单的RPC组件示例来对各个模块进行code级别的说明。
以下代码仅仅是了解RPC各个模块功能的示例,对性能和异常等情况未考虑全面,生产环境不适用。
protocol模块代码
协议层主要包括编解码和序列化部分。编解码就是我们对传输通信的远程调用请求接口和方法参数等数据按照我们规定的格式进行组装编码,然后在接收的一方负责把数据解码成原始的对象,然后找到需要执行的接口和方法。序列化/反序列化,则是将数据对象,按照一定的映射关系转换成字节流,供网络传输,接收的一方首先将流映射为对象数据。
有的时候,序列化/反序列化组件会包含编解码部分。此外,编解码和序列化工作先后关系也不一定。一般高性能RPC,序列化工具十分强大和通用,所以编解码部分会放在序列化之后,主要是解码的时候,可以不完成反序列化就对流进行一些处理工作,比如映射、分发等。
/**
* 很明显,这里使用JSON来序列化和反序列化RPC调用传递的数据
*/
public class ServiceProtocol {
public static final ServiceProtocol protocol = new ServiceProtocol();
/**
* 将对象序列化为字符串字节
*/
public byte[] encode(Object o) {
return JsonUtils.encode(o).getBytes();
}
/**
* 反序列化成字符串
*/
public T decode(byte[] data, Class clazz) {
return JsonUtils.decode(new String(data), clazz);
}
/**
* 编解码模型
*/
public static class ProtocolModel {
private String clazz;
private String method;
private String[] argTypes;
private Object[] args;
// setter getter方法省略
}
}
示例中的代码使用JSON来序列化/反序列化工作。由于JSON序列化组件比较弱,所以这边需要将执行调用方法相关的请求数据进行编码成ProtocolModel对象。
remote模块代码
remote模块是提供服务端和客户端通信的功能。因此,在服务端需要起一个端口来监听外部的请求,在客户端则负责发送请求,接收响应数据。
/**
* 客户端通信组件,客户端和外部服务端数据交互时使用
*/
public class ClientRemoter {
public static final ClientRemoter client = new ClientRemoter();
public byte[] getDataRemote(byte[] requestData) {
try (Socket socket = new Socket()) {
socket.connect(new InetSocketAddress("127.0.0.1", 9999));
socket.getOutputStream().write(requestData);
socket.getOutputStream().flush();
byte[] data = new byte[10240];
int len = socket.getInputStream().read(data);
return Arrays.copyOfRange(data, 0, len);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
/**
* 服务端起一个端口监听服务,绑定到相关processor处理器上。
*/
public class ServerRemoter {
private static final ExecutorService executor =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public void startServer(int port) throws Exception {
final ServerSocket server = new ServerSocket();
server.bind(new InetSocketAddress(port));
System.out.println("-----------start server----------------");
try {
while (true) {
final Socket socket = server.accept();
executor.execute(new MyRunnable(socket));
}
} finally {
server.close();
}
}
class MyRunnable implements Runnable {
private Socket socket;
public MyRunnable(Socket socket) {
this.socket = socket;
}
public void run() {
try (InputStream is = socket.getInputStream(); OutputStream os = socket.getOutputStream()) {
byte[] data = new byte[10240];
int len = is.read(data);
ServiceProtocol.ProtocolModel model = ServiceProtocol.protocol
.decode(Arrays.copyOfRange(data, 0, len), ServiceProtocol.ProtocolModel.class);
Object object = ServiceProcessor.processor.process(model);
os.write(ServiceProtocol.protocol.encode(object));
os.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
// close socket...
} } }
}
简单处理,直接让网络一次获取所有的数据,假设一次请求和响应的数据大小小于10K。
在server端的remote中,启动服务之前是需要绑定对外提供的服务的,也就是服务server启动,其内部需要指定序列化、服务处理器等逻辑。
通用RPC的通信层,是非常复杂的,其需要考虑各种网络环境导致的数据半包,分包和粘包情况,需要考虑高性能NIO组件,多线程处理超时,连接复用等等。
processor模块代码
服务端接口方法定位处理器。作为一个组件,显然不应该在业务代码中嵌入一些非业务逻辑。processor会根据序列化完了之后的请求数据来定位具体的处理逻辑,然后调用对应的业务代码来处理获取返回结果。
public class ServiceProcessor {
public static final ServiceProcessor processor = new ServiceProcessor();
private static final ConcurrentMap PROCESSOR_INSTANCE_MAP = new ConcurrentHashMap();
public boolean publish(Class clazz, Object obj) {
return PROCESSOR_INSTANCE_MAP.putIfAbsent(clazz.getName(), obj) != null;
}
public Object process(ServiceProtocol.ProtocolModel model) {
try {
Class clazz = Class.forName(model.getClazz());
Class[] types = new Class[model.getArgTypes().length];
for (int i = 0; i < types.length; i++) {
types[i] = Class.forName(model.getArgTypes()[i]);
}
Method method = clazz.getMethod(model.getMethod(), types);
Object obj = PROCESSOR_INSTANCE_MAP.get(model.getClazz());
if (obj == null) {
return null;
}
return method.invoke(obj, model.getArgs());
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
PROCESSOR_INSTANCE_MAP publish这个逻辑,在Spring环境中,一般通过xml配置自动注入进来,然后从context中获取对应的实例。但是,不管怎样,底层其实都是一个map来维护映射关系。
如上文介绍的那样,经过解码获取到的调用对象,然后通过java反射机制,执行指定的方法获取结果。
serviceClient模块代码
其实,这块叫做serviceProxyClient比较直接点。
public class ServiceProxyClient {
public static T getInstance(Class clazz) {
return (T) Proxy.newProxyInstance(clazz.getClassLoader(), new Class[] {clazz}, new ServiceProxy(clazz));
}
public static class ServiceProxy implements InvocationHandler {
private Class clazz;
public ServiceProxy(Class clazz) {
this.clazz = clazz;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
ServiceProtocol.ProtocolModel model = new ServiceProtocol.ProtocolModel();
model.setClazz(clazz.getName());
model.setMethod(method.getName());
model.setArgs(args);
String[] argType = new String[method.getParameterTypes().length];
for (int i = 0; i < argType.length; i++) {
argType[i] = method.getParameterTypes()[i].getName();
}
model.setArgTypes(argType);
byte[] req = ServiceProtocol.protocol.encode(model);
byte[] rsp = ClientRemoter.client.getDataRemote(req);
return ServiceProtocol.protocol.decode(rsp, method.getReturnType());
}
}
}
ProxyClient就是对客户端调用API时透明化底层序列化和网络操作相关细节。所以,在proxyClient内部,我们可以看到它封装代理了这块调用逻辑,业务代码直接使用getInstance方法就可以获取对象实例,然后按照正常使用api方法来执行调用逻辑,获取结果。
如果使用spring框架的话,可以进一步封装成一个bean,然后客户端业务代码只需要在xml中配置一下,就可以通过注解annotation等方式注入进来。
server业务接口实现代码
这里给出接口对外发布和测试
public interface RpcService {
String sayHi(String name);
}
public class RpcServiceImpl implements RpcService {
public String sayHi(String name) {
return "Hello," + name;
}
}
/**
* 服务端测试main执行代码
*/
public class ServerDemo {
public static void main(String[] args) throws Exception {
// 发布接口
ServiceProcessor.processor.publish(RpcService.class,new RpcServiceImpl());
// 启动server
ServerRemoter remoter = new ServerRemoter();
remoter.startServer(9999);
}
}
如上,我们构造了一个
RpcService接口对外提供sayHi的服务。在main方法中,我们首先需要对外发布这个接口和对应的实现类对象。在一些框架中,这些对外暴露的接口,都是通过xml配置或者annotation来发布的。然后,我们就可以启动server服务,对外提供RPC服务。
6. client调用测试代码
public class ClientDemo {
public static void main(String[] args) {
System.out.println("----------start invoke----------------");
RpcService service = ServiceProxyClient.getInstance(RpcService.class);
System.out.println(service.sayHi("RPC World"));
System.out.println("----------end invoke----------------");
}
}
看我们的测试代码非常简单,当要远程调用某个接口方法时,只需要getInstance该接口类代理对象,然后就像调用本地方法一直执行方法执行和结果处理。
RPC技术深入
上文简单的介绍了RPC模块各个部分,并且实现了一个简单的RPC组件。这一部分,我们要介绍在生产环节下RPC需要使用的一些技术点。
RPC序列化
将RPC序列化和编解码分开,是因为个人觉得,虽然在很多时候,编解码其实就是序列化操作,但是有的时候,我们会自定义一些数据结构来封装业务数据对象,然后再序列化成二进制流。此外,在协议层,我们可能也会对普通序列化完了之后,还会对传输头进行编码工作。因此,为了更好的说明,这里分开来。
序列化,说的简单,就是将对象转换成二进制流,也就是byte[],而反序列化就是讲二进制流转换成对象。使用序列化/反序列化,主要是我们想把内存对象数据,持久化到文件fd或者通过网络传输到其他地方,而这只能使用二进制流来呈现。此外,由于RPC是通过网络通信的,所以序列化工具的性能和二进制流的大小,都是直接影响整体处理能力的关键因素。
目前基于Java的序列化工具,主要有:
- JDK Serializable工具
- Hessian工具
- Kryo工具
- JSON工具
JDK内置序列化工具
JDK自带的序列化工作不需要引入任何第三方包就可以直接使用,我们仅仅只需要实现java.io.Serializable接口。然后,我们在需要序列化/反序列化的时候,直接使用ObjectInputStream/ObjectOutStream来readObject将流反序列化成对象或者writeObject将对象序列化成流。
很多时候,我们并不使用原生的JDK序列化工具进行序列化,主要原因是因为其序列化后的二进制流太大,并且序列化耗时也比较长。但是,其最大的优点就是原生支持,快速使用,引入成本低,此外,其支持java所有类型,所以在有些RPC组件中,其作为默认序列化工具。
使用JDK自带的序列化工具,尤其需要注意
serialVersionUID这个静态变量,在反序列化的时候,会根据这个变量来判断两个类是否一样,如果修改了该变量,那么将无法兼容来的二进制数据的反序列化操作。此外,你可以通过在类中增加writeObject 和 readObject 方法可以实现自定义序列化。
测试代码如下:
public class JdkSerialiable {
public static void serial(Blog blog) throws Exception {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream os = new ObjectOutputStream(baos);
os.writeObject(blog);
os.close();
ObjectInputStream is = new ObjectInputStream(new ByteArrayInputStream(baos.toByteArray()));
Blog blog1 = (Blog) is.readObject();
is.close();
System.out.println(blog1);
}
}
Hessian工具
Hessian,其实是一个开源的轻量级RPC组件。从上面分析RPC通用结构,可以看到很多RPC为了性能会自己实现序列化/反序列化工具,比如Thrift,而hessian也是如此。hessian2的性能相对JDK来说,提高了很多,而且序列化完了之后的流也小了很多。由于hessian已经生产实践了很长时间,所以其还是很值得使用的。
hessian在处理序列化的时候,会根据对象的数据类型采用不同的序列化策略,比如有些直接使用JavaSerializer,有些事自己来实现对应类型的序列化方法,其实就是如上面所介绍的那样,实现对应类型的writeObject和readObject方法。
我们只是使用hessian工具来完成序列化和反序列化工作,如果你需要自己实现一个自定义序列化工具,那么可以参考hessian的实现方式。
测试代码如下:
public class HessianSerialibale {
public static void serial(Blog blog) throws Exception{
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Hessian2Output os = new Hessian2Output(baos);
os.writeObject(blog);
os.close();
Hessian2Input is = new Hessian2Input(new ByteArrayInputStream(baos.toByteArray()));
Blog blog1 = (Blog) is.readObject();
is.close();
System.out.println(blog1);
}
}
尤其需要说明,在上面的测试代码中,如果不将os close掉,则一直会报错,告诉
java.io.EOFException: readObject: unexpected end of file.此外,处理性能上的优势,hessian还可以在
serialVersionUID被后期更改的时候,反序列化也没有问题。这是因为,hessian不依赖UID来匹配类型,而且hessian在序列化完了之后的二进制流里面,会保留每个field对应的一些属性信息,虽然这些信息会增加一点流大小,但是对反序列化工作很有帮助。
Kryo工具
关于Kryo的性能对比,可以参考各种 Java 的序列化库的性能比较测试结果。
Kryo是一个快速高效的Java对象序列化框架,其在java的序列化上的性能指标甚至优于google著名的序列化框架protobuf,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。总之,Kryo性能非常霸道。
测试代码如下:
public class KryoSerializable {
public static void serial(Blog blog)throws Exception{
Kryo kryo = new Kryo();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Output output = new Output(baos);
kryo.writeClassAndObject(output, blog);
output.close();
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
Input input = new Input(bais);
Blog blog1 = (Blog) kryo.readClassAndObject(input);
input.close();
System.out.println(blog1);
}
}
由于Kryo工具生成的字节码中是不包含field元数据信息的,这样的话,在兼容性上就很难处理了。比如我现在对一个对象增加一个字段属性,但是这样子的话,老的所有序列化二进制流就无法被正常反序列化成对象了。在很多场景下,这都是无法容忍的。
JSON工具
JSON工具进行序列化和反序列化在上文已经进行了说明,并且RPC示例代码就是使用这种方式。其性能上跟hessian差不多,并且反序列化兼容会很,但是其有个比较大的缺点,就是很多类型,可能JSON工具无法支持,并且其是基于String然后再转成二进制流的,所以流的大小,可能并没有想象的那么好。
RPC协议编解码
除了序列化,在编码的上/下游还需要对二进制流或者对象做一些额外的处理,而这些处理本身和二进制流化没有太大关系。
比如dubbo给出的处理流程,可以清晰的看出序列化和编码之间的区别(个人觉得广义的编码应该包括序列化那部分)如下:

每个RPC组件,基本上都是直接基于Socket来开发通信层功能,但是在网络传输的数据由于网络链路和协议的问题,会出现半包,分包和粘包情况。这样就需要设计编解码协议头来解码网络流,如上dubbo视图。
下面我们来看下dubbo的协议编码格式(具体参考:远程通讯细节):

Dubbo协议头分析:
协议头固定长度
16个字节,也就是128位。这样,当我们解码流的时候,会首先提取前16byte来解析。先来看看MAGIC设计:
// magic header. protected static final short MAGIC = (short) 0xdabb; protected static final byte MAGIC_HIGH = Bytes.short2bytes(MAGIC)[0]; protected static final byte MAGIC_LOW = Bytes.short2bytes(MAGIC)[1];
SerializationID表示序列化类型ID,Dubbo支持多种序列化工具,比如hessian,jdk,fastjson等,所以需要在协议头里面指定序列化方式,这样在解码完了之后才能知道内容使用哪种工具反序列化。
event表示事件,比如这个请求是heartbeat。two way表示请求是否是需要交互返回数据的请求。req/res表示该数据是请求还是响应。status表示状态位,当响应数据的时候,根据该字段判断是否成功。
id表示请求id。这个ID真的真的很重要!!!这个id是请求客户端生成的唯一id,保证在服务运行期内id不会重复。此外,在阿里内部的RPC组件HSF最开始是将id放在data数据内,这样只有在反序列化的时候,才能拿到ReqId,但是有些时候ReqId对应的RPC请求可能由于超时或者已经被处理,导致客户端对于这种case直接丢弃就可以。因此,将id放在head里面,则直接解码的时候就可以拿到ReqId去check,而不需要额外反序列化工作。
data length则表示正文内容的长度。解码是通过该字段来判断消息正文字节流的整个完整包,这样反序列化就可以进行正确的转换对象了。
RPC路由和负载均衡
路由策略,是完成单个机器对于服务方调用链路的选择策略,然后把客户端的服务请求传输到具体的某台服务端的机器上。负载均衡是完成路由的一种实现方式,其将前端请求根据一定算法策略来分发到不同机器上,使得集群中机器资源得到充分均衡的利用,此外还可以将不可用机器剔出请求列表。但是,显然路由除了负载均衡之外,还有其他方式。
我们知道,现在的服务后台都是多台机器部署的服务集群,在这些集群在请求的入口,一般会有负责负载均衡的机器部署,来完成请求的合理分发。RPC的结构也是客户端和服务端模式,但是其结构中我们发现是没有中间代理server层的,所以对于客户端在集群中的远程服务调用,就需要客户端自己来完成负载均衡的逻辑了。
除负载均衡之外,我们还会存在其他路由加强方式。比如,我们有多个机房都部署服务的时候,我需要优先选择同机房内的服务调用。
一般定义类似如下的接口,然后根据自己的需求实现自己的负载均衡/路由策略:
public interface ILoadBalanceStrategy {
/**
* 从众多连接池子中选择其中一个池子.
*
* @param invokeConns 客户端维持的和各个服务端维持的连接池对象列表
* @param invocation 本次客户端调用服务端相关的信息
* @return 返回和其中一个服务端维持链接的连接池对象
*/
public InvokeConn select(List invokeConns, Invocation invocation);
}
一般RPC组件中,会实现两个通用的负载均衡策略。随机和轮询。具体实现可以参考:https://github.com/ketao1989/ourea/tree/master/ourea-core/src/main/java/com/taocoder/ourea/core/loadbalance
再谈谈维护可用服务列表:
一般我们会在客户端和服务端之间维持长连接,然后通过心跳机制来确保服务端是否在线提供服务。此外,对一些没有维护长连接或者可选择不建立长连接的RPC组件来说,只能通过注册服务机制来监听服务端是否下线。
如果调用比较频繁的服务来说,客户端可以在服务连接未成功的情况下,将该机器从服务连接列表中剔除,放在暂时不可用机器列表,然后起一个定时任务,当机器暂存5s后,再放到可用列表尝试请求服务调用。
关于心跳请求的定时任务,可以参考使用Netty提供的HashedWheelTimernetty源码解读之时间轮算法实现-HashedWheelTimer,其提供了在不要求高精度触发定时任务的场景下,性能非常高。
最后,再聊聊服务调用路由:
服务路由,这里特指除负载均衡之外的一些服务寻址策略。和负载均衡不同的是,这里的路由策略是单个机器根据自身特点做出的服务方选择策略,而负载均衡策略则是基于整个集群中所有机器的普适策略。如上所言,我们的多机房部署,再拿到集群机器列表之后,我们还需要维持一个本机房的机器列表(一般,对服务集群列表进行按IP前缀规则来过滤),这样当我们选择调用机器的时候,会优先从本机房获取连接,如果没有才会按照负载均衡来获取服务调用连接。
此外,对于一些完善的RPC框架,可能还会支持动态可配置路由规则。比如,我们可以按照机器ip来配置,某些客户端调用只能路由到某些服务端机器上。对于线上测试问题跟踪而言,可以很好的根据服务调用链路,来查看日志解决问题。
RPC超时管理
作为一个健康的服务,一定需要超时机制。相当多的服务不可用问题,都是因为客户端没有超时机制,导致服务端抖动的一段时间内,客户端一直处于占用连接等待响应的阶段,耗尽服务端资源,最后导致服务端集群雪崩。所以在请求网络服务的时候,增加超时设置是多么重要(当然,连接使用现在最大连接数的连接池也非常重要)。
RPC的调用实现,一般会有一个IO线程池来处理RPC调用,也就是我们的业务线程会将调用请求交给RPC线程来处理,返回一个future对象。远程调用处理完成之后,RPC线程会将结果填充到futrue对象内部,然后告知调用方调用完成,可以使用futrue.get来获取返回数据。如下所示:

从上图可以看出,超时1我们可以直接使用futrue.get特性来设置和处理超时问题。超时2指的是服务端执行的超时,比如我们客户端调用的时间是1s,但是服务端可能会超过1s,而这个时候客户端其实已经超时丢弃这次请求,但是服务端还一直执行直到完成返回,这个时候服务端需要序列化对象然后传输到客户端,但是这个流程其实可以简化的。
因此,服务端的超时管理,是当服务端业务逻辑执行完成之后(这期间实现超时中断比较难),比较执行时间和客户端设置的超时时间,如果接近,则打包服务端超时错误信息返回给客户端即可。这样可以节省序列化数据时间(直接使用序列化好了的数据返回),已经减少网络传输时间。
RPC 服务发现
在对外http服务里,我们有一个配套的支撑基础组件叫做DNS,其根据域名找到某几个外网ip地址。然后,请求打到网站内部,一般首先到nginx群,nginx也会根据url规则找到配置好的一组ip地址,此外,nginx根据healthcheck来检查http服务是否可用。但是,使用nginx时,我们通常需要把ip地址离线配置到nginx上。
我们提供的RPC服务都是集群部署,所以我们需要在客户端维持一个服务调用地址列表。所以,我们也需要类似DNS功能的服务。 但是,我们不想我们的RPC服务集群有机器迁移或者增加时,所需要离线给客户端配置,这就是说,我们还需要实时更新集群机器列表的功能。
这,就是RPC服务发现模块需要解决的问题。
一般,服务发现主要包括2部分:
- 服务地址存储;
- 服务状态感知。
服务地址存储
服务地址存储,首先需要一个组件来存放服务机器列表等RPC服务数据,提供存储服务的组件有很多,比如:zookeeper,redis,mysql等等。然后,在服务端正常启动可以提供服务之后,需要将自己的服务地址,比如ip,port,以及服务信息,比如接口,版本号等信息,提交到存储服务机器上。然后,客户端在启动的时候,从存储服务的机器上,根据接口,版本等服务信息来拿到提供对应服务的RPC地址列表,客户端根据这个列表就可以开始调用远程服务了。
此外,为了服务治理,比如我们需要知道哪些客户端调用了我们对外提供的服务,就需要客户端在启动的时候,把自己的地址数据和调用的服务信息提交到存储服务上去。
对于提供比较完善的服务治理功能,还可以提供后台操作界面,让某些服务端机器手动操作上/下线,这样让通过RPC调用的客户端不将流量打到下线的服务器上。
简单的服务发现,RPC方和存储组件之间的交互如下:

服务状态感知
这里的服务感知,包括客户端感知服务端状态,以及存储服务感知RPC参与方的状态。
正常情况下,我们从存储组件那里拿到服务端地址后,自己来处理路由策略,然后选择一个服务端建立连接,执行远程调用。在执行的过程中,如果有服务不可用,我们可以从我们的服务列表中,将它剔除。但是,如果服务增加机器或者服务机器迁移了呢?这就需要我们及时了解服务端集群的整体机器状态。两种方式:
- 客户端其一个定时调度任务,周期去存储组件处拉取最新的服务集群地址列表,但是这个周期粒度比较难控制。
- 客户端和存储组件建立一个长连接,当存储组件发现有服务集群状态发生变更,推送给客户端。但是,这又要求存储组件具有推送功能。
目前有这个功能的存储组件,主要有zookeeper和redis,此外,也可以自己实现一个简单可靠的服务发现中间件,对外提供推送存储服务。
我们在服务启动的时候,会告知存储组件我们对外提供服务的地址信息和客户端的地址信息;在服务已知操作的服务下线的时候,会将存储组件中存储的服务相关信息清除掉。但是,显然,在服务下线或者客户端下线的时候,都存在没有清除存储信息就宕机的情况,这个时候就需要存储组件需要有感知各个参与方的状态了。
一般,我们会让RPC两方都和存储组件保持连接,然后通过心跳等方式来探测对方是否下线。
目前提供这个功能的存储组件,主要有zookeeper和redis。当然,你也可以实现一个,可以和所有注册服务和查找服务的server保持长连接。由于,可能有大量的机器建立长连接,所以服务器性能一定要高。
基于zookeeper实现服务发现功能的代码,可以参考:https://github.com/ketao1989/ourea
RPC 多线程IO模型
最后
RPC其实是一个说简单简单,说复杂复杂的组件。就如上文写的一个简单的RPC示例,其本身就是一个具备RPC功能的组件。但是,在深入篇中,可以看到每一个模块都可以深入优化,以及支持模块化插件话设计开发。
本文从单机到集群,从本地调用到远程调用的渐进过度。然后再从一个满足RPC结构图的简单示例开始,代码介绍每个模块,进而深入成熟RPC框架所需要考虑和优化的各个技术点。
本文的目的,旨在对RPC整体结构和各个模块进行介绍和深入,然后根据这些点,可以去分析开源的RPC框架或者自己写一个RPC组件。
在本文中,很多点都是一边学习,一边总结,所以知识有限,如有问题,欢迎交流。
参考文献
- linux内存管理浅析
- 微服务、SOA 和 API:是敌是友?
- 序列化和反序列化