redis缓存设计与性能优化
缓存设计
一、缓存穿透
查询一个一定不存在的数据就是缓存穿透。
造成条件:
1、自己的业务代码或者设计出现问题
2、一些个黑客网站进行攻击,用一些压测软件进行高并发的访问
解决:
1、对该key缓存控对象(切记:设置一个过期时间)
2、布隆过滤器
布隆过滤器是在redis上设置了一层过滤器,这个过滤器通过一定的算法(例如:CRC12,CRC16算法),根据redis的key进行一个除余操作,得到一个数值,然后将相应数值上的位变为1,一个key会根据不同的算法进行多次计算,下次进行访问的时候,先根据key进行这些算法的计算,在相应位置上如果有一个为0,则直接告诉你这个key在redis中不存在。
布隆过滤器通过key进行计算后如果告诉你该key在redis中不存在,则一定是不存在的,如果告诉你存在,则该key不一定在redis中存在。
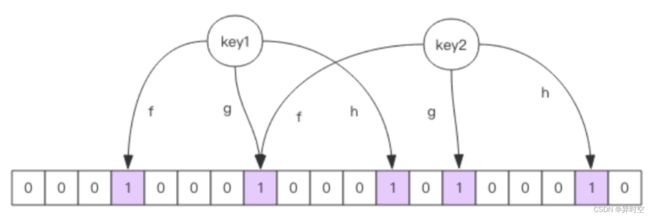
那么很多小伙伴就有问题了:
如果我访问了很多个key(大约100w个),但是我的布隆过滤器才1w个位置,这样不就造成我的布隆过滤器都变成1了吗,那在进行key的访问的时候过滤器就没用了?
其实布隆过滤器的bit字节是很大的,底层会有几亿、几十亿甚至几百亿个bit,这些bit最多几十兆的内存,用来解决恶意攻击还是非常方便的。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
packagecom.redisson;
importorg.redisson.Redisson;
importorg.redisson.api.RBloomFilter;
importorg.redisson.api.RedissonClient;
importorg.redisson.config.Config;
publicclassRedissonBloomFilter{
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小
bloomFilter.tryInit(100000000L,0.03);
//将zhuge插入到布隆过滤器中
bloomFilter.add("cc");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("aa"));//false
System.out.println(bloomFilter.contains("bb"));//false
System.out.println(bloomFilter.contains("cc"));//true
}
}
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器
缓存过滤伪代码:
//初始化布隆过滤器 RBloomFilterbloomFilter=redisson.getBloomFilter("nameList"); //初始化布隆过滤器:预计元素为100000000L,误差率为3% bloomFilter.tryInit(100000000L,0.03);
//把所有数据存入布隆过滤器 voidinit(){
for (String key: keys) {
bloomFilter.put(key);
} }
Stringget(Stringkey){
// 从布隆过滤器这一级缓存判断下key是否存在 Boolean exist = bloomFilter.contains(key); if(!exist){
return ""; }
// 从缓存中获取数据
String cacheValue = cache.get(key); // 缓存为空
//初始化布隆过滤器 RBloomFilterbloomFilter=redisson.getBloomFilter("nameList"); //初始化布隆过滤器:预计元素为100000000L,误差率为3% bloomFilter.tryInit(100000000L,0.03);
//把所有数据存入布隆过滤器 voidinit(){
for (String key: keys) {
bloomFilter.put(key);
} }
Stringget(Stringkey){
// 从布隆过滤器这一级缓存判断下key是否存在 Boolean exist = bloomFilter.contains(key); if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key); // 缓存为空
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
二、缓存失效(缓存击穿)
由于可能在同一时间大量的key过期了,这时候可能大量的请求进来访问缓存,发现在数据库中没有,然后就会访问数据库,给数据库造成了一定的压力。
解决:
给key加的过期时间保证不相同,可以在过期时间基数上加一个随机时间,确保每个key的过期时间不一致
三、缓存雪崩
高并发情况下很多个请求过来,redis承受不住压力,造成崩溃,然后所有请求就去访问数据库,造成数据库及联宕机。
解决:
1、保证缓存层的高可用:使用哨兵集群或集群架构
2、对服务器后端进行一些限流熔断并降级,像sentinal、Hystrix进行限流。
比如服务降级,对于非核心的业务,暂时停止从缓存中去拿取数据,返回事先设定好的值或者返回异常信息;对于核心业务,我们还是让他去访问缓存,缓存拿不到数据,让他去数据库中去取。
热点key问题
对于某一个热点key,在某一时刻过期了,这时候如果突然有大量的请求过来,就会给系统造成一定的压力。
解决:
通过加互斥锁来让某一个线程进行获取热点key,然后存放在缓存中,其他线程可以睡眠个几十毫秒,然后在尝试获取。
缓存与数据库双写不一致(同步问题)
问题:
1、双写不一致的情况

2、读写不一致的情况
很多人为了保证双写不一致的情况都会在执行数据库的写操作之后删除缓存,这样就能保证数据的一致性吗?
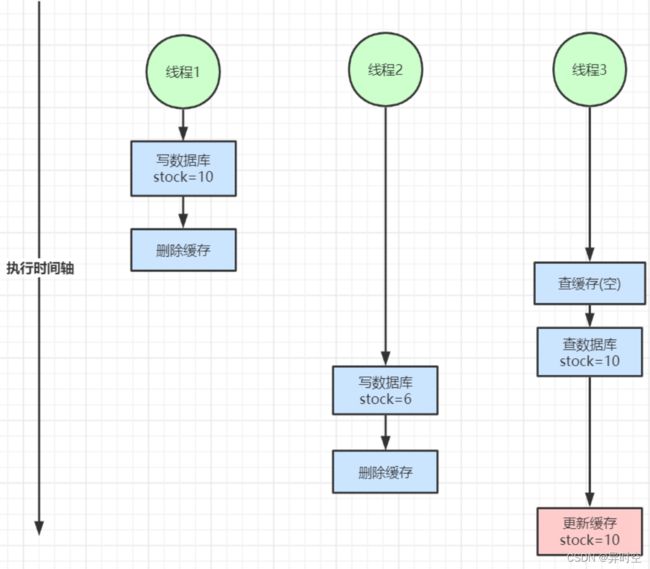
上图这种情况就会导致读写不一致的情况
解决:
1、大部分的场景其实是不会出现写写或者读写不一致的情况,除非是非常大的并发的情况下。这种几乎可以不用去进行处理,给数据加上过期时间,然后过一段时间去触发读的主动更新即可。
2、如果不能容忍缓存数据不一致,可以加读写锁,保证并发读写、写写的时候按顺序排好队,读读的时候相当于无锁
3、也可以通过阿里云的canal中间件,对mysql的binlog日志进行实时监控进行修改缓存,不过这种情况增加中间件就会加大系统的复杂性。
总结:
以上都是针对读多写少的情况,如果是读多写多的情况又不能容忍数据的不一致,就没必要加缓存了,直接操作数据库。
redis缓存清除策略
redis对于过期键有三种清除策略:
1、被动删除:当key过期后,不会进行删除,在访问时进行删除(当然客户端不会访问到数据)
2、主动删除:当key过期后进行主动删除
3、当redis缓存超过maxmemory的值时,会执行主动清除策略
主动清楚策略
redis的主动清除策略有三种形式:
1)、针对过期时间的key做处理:
1、volatile-ttl:将即将过期的key进行删除
2、volatile-random: 在过期的key中随机进行删除
3、volatile-lru: 使用lru算法对过期的key进行删除
4、volatile-lfu: 使用lfu算法对过期的key进行删除
2)、针对所有的key做处理:
1、allkeys-random:对所有的key进行随机删除
2、allkeys-lru:使用lru算法对所有的key进行删除
3、allkeys-lfu:使用lfu算法对所有的key进行删除
3)、不做任何处理
noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息
LRU算法
淘汰很久没被访问过的数据,以最近一次访问时间作为参考
LFU算法
淘汰访问次数最少的数据,以访问次数作为参考
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下 降,缓存污染情况比较严重。这时使用LFU可能更好点。
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。如果不设置最大内存,当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),会让 Redis 的性能急剧下降。 当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作”del key”同 步到从结点删除数据。