【Netty专题】Netty调优及网络编程中一些问题补充(面向面试学习)
目录
- 前言
- 阅读对象
- 阅读导航
- 笔记正文
-
- 一、如何选择序列化框架
-
- 1.1 基本介绍
- 1.2 在网络编程中如何选择序列化框架
- 1.3 常用Java序列化框架比较
- 二、Netty调优
-
- 2.1 CONNECT_TIMEOUT_MILLIS:客户端连接时间
- 2.2 SO_BACKLOG:最大同时连接数
- 2.3 TCP_NODELAY:关闭TPC网络传输优化Nagle算法
- 2.4 SO_SNDBUF & SO_RCVBUF:TCP层面的缓存大小
- 2.5 ALLOCATOR:内存分配器
- 2.6 RCVBUF_ALLOCATOR:入站内存分配器
- 三、Netty面试题
-
- 3.1 Netty如何解决空轮询BUG
- 3.2 如何单机下支持百万连接
-
- 3.2.0 硬件层面支持
- 3.2.1 OS层面支持
- 1.2.2 Netty层面支持
- 3.2.3 JVM层面支持
- 学习总结
- 感谢
前言
很直接哈,最近去面试的时候遇到了一些Netty网络编程,序列化框架上的问题,当时回答的不是很好,所以赶紧回来学习了一下,顺便做一下笔记,沉淀一下了。
阅读对象
- 熟悉网络编程
- 熟悉Netty基本应用
- 想要了解序列化框架选择思路
- 想要了解Netty参数优化
阅读导航
系列上一篇文章:《【Netty专题】用Netty手写一个远程长连接通信框架》
笔记正文
一、如何选择序列化框架
1.1 基本介绍
什么是序列化/反序列化?我在前面的文章中有提到过,但那时候没有写的很仔细,我自己也忘了,罪过啊。其实我知道,序列化/反序列化在网络编程中是很重要的概念,只不过被我自己疏忽了。
言归正传。
什么是序列化、反序列化?
我们知道,数据在网络中传输不可能是原文传输的,人家机器设备只认得二进制01串。所以,把原文转换为01串字节流这个过程就是序列化;反之,则叫做反序列化
序列化有什么作用?
主要目的有:【网络传输】及【对象持久化保存】。持久化保存知道啥意思吧,就是存到各种数据库中
感兴趣的朋友可以看这篇文章《给我5分钟,一次性给你讲明白Java中的序列化和反序列化》学习一下。
1.2 在网络编程中如何选择序列化框架
市面上有很多序列化工具,如:
- 原生的JDK序列化
- ProtoBuff
- Kryo
- Thrift
- Avro
那我们在编程中如何选择呢?正常来说我们需要从以下4个维度做比较:
- 语言支持:是否支持当前项目使用语言,比如原生的JDK序列化框架只支持Java,我要是C++项目不可能使用JDK序列化框架吧
- 空间效率:序列化后占用的空间
- 时间效率:序列化/反序列化的速度
- 易用性:使用是否友好、便捷
是的,正常来说就是需要通过以上4个维度考虑。综合考虑后,再决定选用什么样的序列化框架
1.3 常用Java序列化框架比较
来自阿里开发者社区的一个Java序列化框架比较:几种Java常用序列化框架的选型与对比
跨语言来说:

结论:Protobuf在通用上是最佳的,能够支持多种主流变成语言。
易用性来说:
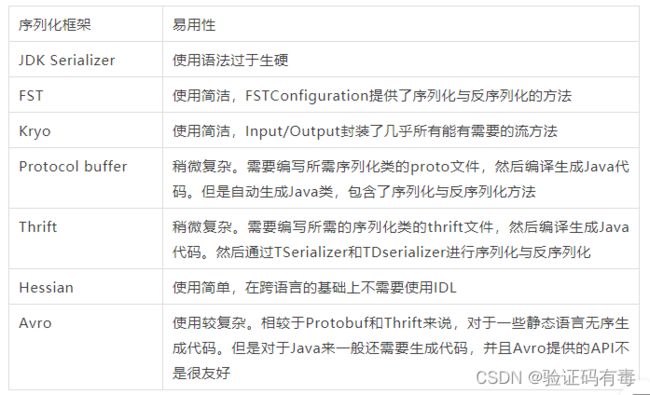
结论:JDK Serializer外的序列化框架都提供了不错API使用方式
可扩展性来说:

结论:下面是各个序列化框架的可扩展性对比,可以看到Protobuf的可扩展性是最方便、自然的。其它序列化框架都需要一些配置、注解等操作。
性能来说:(空间、时间)

结论:对比各个序列化框架序列化后的数据大小如下,可以看出kryo preregister(预先注册序列化类)和Avro序列化结果都很不错。所以,如果在序列化大小上有需求,可以选择Kryo或Avro。

结论:下面是序列化与反序列化的时间开销,kryo preregister和fst preregister都能提供优异的性能,其中fst pre序列化时间就最佳,而kryo pre在序列化和反序列化时间开销上基本一致。所以,如果序列化时间是主要的考虑指标,可以选择Kryo或FST,都能提供不错的性能体验。
数据类型和语法结构支持

二、Netty调优
Netty的调优参数有很多,感兴趣的朋友可以去看看Netty包下的 io.netty.channel.ChannelOption类里面。在这里,只是简单介绍一下Netty常用调优参数。
PS:下面参数的主要释义来自于【百度-文心一言】
2.1 CONNECT_TIMEOUT_MILLIS:客户端连接时间
CONNECT_TIMEOUT_MILLIS参数的作用是:设置客户端连接超时时间,默认值20秒。这个参数用于定义客户端在尝试连接到服务器时可以等待的最大时间。如果在这段时间内无法建立连接,Netty将抛出一个连接超时的异常。
修改设置方式是使用Bootstrap的option方法。如下:

在服务端设置了,如果客户端在发起连接后的5秒如果仍未连接成功,则抛出异常。
2.2 SO_BACKLOG:最大同时连接数
Netty中的SO_BACKLOG参数主要用于TCP协议,它定义了操作系统内核应为此套接字排队的最大传入连接数。当新连接到达,且套接字已达到其最大容量时,操作系统内核将根据这个参数的值决定如何处理新连接。
具体来说,如果SO_BACKLOG的值较大,那么当套接字已达到其最大容量时,操作系统内核将会暂时存储在队列中等待处理的新的连接。如果SO_BACKLOG的值较小,那么当套接字已达到其最大容量时,操作系统内核将会拒绝新的连接请求,并向客户端返回一个错误信息,告诉它连接请求被拒绝。
因此,通过合理地设置SO_BACKLOG的值,我们可以控制Netty应用程序能够同时处理的最大连接数。这在进行网络编程时非常重要,尤其是当我们需要处理大量并发连接时。
window的默认值是200,linux和mac的128,如果配置文件存在以配置为准。
修改示例如下:

2.3 TCP_NODELAY:关闭TPC网络传输优化Nagle算法
Netty中的TCP_NODELAY参数主要用于关闭Nagle算法。Nagle算法是一种改善网络性能的算法,它通过将小的数据包组装为更大的帧进行发送,以减少网络中的数据包数量。但是,这种算法可能会导致数据传输的延迟。
所以,TCP_NODELAY参数的作用就是关闭Nagle算法,禁用Nagle算法,因此适用于小数据即时传输。它的默认值为true,如果需要发送一些较小的报文,则需要禁用该算法,设置为false。
(PS:如果你不在意这些带宽消耗,更在意传输效率,那么关闭它)
修改示例代码如下:

2.4 SO_SNDBUF & SO_RCVBUF:TCP层面的缓存大小
我在标题中特意注明了这是TCP传输层面的缓存大小,这是因为缓存思想在很多地方都用到了,比如NIO/Netty等都自己封装了一层应用层级的缓存。
下面是【文心一言】的答案,但是感觉怪怪的:
Netty中的SO_SNDBUF和SO_RCVBUF参数主要用于设置TCP发送和接收缓冲区的大小。
SO_SNDBUF是发送缓冲区的大小,用于限制系统为此套接字排队的最大待发送字节数。如果应用程序尝试发送超过这个缓冲区大小的字节,系统将会阻塞或返回错误。SO_RCVBUF是接收缓冲区的大小,用于限制系统为此套接字排队的最大待接收字节数。如果应用程序接收到的数据超过这个缓冲区的大小,那么数据将会被丢弃。
通过合理地设置这两个参数,我们可以控制Netty应用程序的TCP发送和接收性能,以及防止因缓冲区溢出而导致的数据丢失或程序阻塞。
需要注意的是:发送缓冲区和接受缓冲区都是SocketChannal的参数,SO_RCVBUF也可以用于ServerSocketChannel参数。理论上不建议自己调整,因为操作系统会自动根据网络流量来调整大小。
2.5 ALLOCATOR:内存分配器
这个参数略显复杂,也算是比较重要吧。
首先,这里配置的其实就是ByteBuf分配器,有了分配器就可以创建ByteBuf,ctx.alloc()。这个参数决定了分配的buf是【池化】还是【非池化】,是【直接内存】还是【堆内存】。
然后,这个分配器有一个很有意思的设置:
- 该参数默认值是由系统类型决定的,不过可以通过命令行
Dio.netty.allocator.type修改,可修改值为unpooled和pooled - 如果没有设置,默认按照系统类型。安卓系统则是
unpooled,其他则为pooled
哈哈,这个默认设置逻辑不知道是不是因为安卓系统小内存比较多
- 然后就是默认为使用
直接内存,所谓直接内存即堆外内存,反之也有堆内存。当然也可以通过命令函参数Dio.netty.noPreferDirect修改,值分别为true跟false,默认为false
2.6 RCVBUF_ALLOCATOR:入站内存分配器
这个跟上面的参数比较相似,只不过RCVBUF_ALLOCATOR是设置入站数据缓存的分配。不同于上面的,这里在内存方面强制使用【直接内存】策略,没有【堆内存】可选。这是因为Netty零拷贝需要。如果被设置为【堆内存】了则又多了一次拷贝过程。
最后,它的【池化】【非池化】则由ALLOCATOR参数决定,跟随ALLOCATOR参数。
三、Netty面试题
3.1 Netty如何解决空轮询BUG
在JDK NIO里面有一个BUG,就是臭名昭著的:空轮询。它的现象就是:多路复用器Selector会突然醒来,然后进行轮询socket,然而此时并没有任何事件进来,导致CPU飙升至100%,进而进程崩溃。
据JDK反馈:这是linux内核的BUG,不是我的问题,你们别瞎说。所以JDK没有做什么处理,也就是放任这个BUG没管
然后体贴的Netty为了让我们免于这个烦恼,用了一个很简单粗暴的方式解决空论询:统计周期时间T内空轮训次数N,若达到一定阈值则认为触发了空轮询BUG,然后重建Selector,重新注册SocketChannel。
3.2 如何单机下支持百万连接
单机支持百万连接,需要做不少工作,甚至包括OS层面。
3.2.0 硬件层面支持
当然啦,需要一定层面的硬件支持,你想在1G2核的机器下做百万连接,还是有点难度的。
3.2.1 OS层面支持
在 Linux 平台上,无论编写客户端程序还是服务端程序,在进行高并发 TCP 连接处理时,最高的并发数量都要受到系统对用户单一进程同时可打开文件数量的限制(这是因为系统为每个 TCP 连接都要创建一个 socket 句柄,每个 socket 句柄同时也是一个文件句柄)。
Linux系统下可使用ulimit命令查看系统允许当前用户进程打开的句柄数限制,默认情况下,最多支持1024个。
所以,对于想支持更高数量的 TCP 并发连接的通讯处理程序,就必须修改 Linux 对当前用户的进程同时打开的文件数量。修改单个进程打开最大文件数限制的最简单的办法就是使用 ulimit 命令:$ ulimit –n 1000000
如果系统回显类似于Operation not permitted之类的话,说明上述限制修改失败,实际上是因为在中指定的数值超过了 Linux 系统对该用户打开文件数的软限制或硬限制。因此,就需要修改 Linux 系统对用户的关于打开文件数的软限制和硬限制。
软限制( soft limit ) : 是指 Linux 在当前系统能够承受的范围内进一步限制一个进程同时打开的文件数;
硬限制( hardlimit ) : 是根据系统硬件资源状况(主要是系统内存)计算出来的系统最多可同时打开的文件数量。
第一步:
修改/etc/security/limits.conf文件,在文件中添加如下行:
# *号表示修改所有用户的限制
* soft nofile 1000000
* hard nofile 1000000
soft 和 hard 为两种限制方式,其中 soft 表示警告的限制,hard 表示真正限制,nofile表示打开的最大文件数。1000000 则指定了想要修改的新的限制值,即最大打开文件数(请注意软限制值要小于或等于硬限制)。修改完后保存文件。
第二步:
修改/etc/pam.d/login文件,在文件中添加如下行:
session required /lib/security/pam_limits.so
这是告诉 Linux 在用户完成系统登录后,应该调用 pam_limits.so 模块来设置系统对该用户可使用的各种资源数量的最大限制(包括用户可打开的最大文件数限制),而 pam_limits.so模块就会从/etc/security/limits.conf 文件中读取配置来设置这些限制值。修改完后保存此文件。
第三步:
查看 Linux 系统级的最大打开文件数限制,使用如下命令:cat /proc/sys/fs/file-max
修改这个系统最大文件描述符的限制,修改sysctl.conf文件vi /etc/sysctl.conf:
# 在末尾添加
fs.file_max = 1000000
接着:sysctl -p表示立刻生效
1.2.2 Netty层面支持
第一步:设置合理的线程数
线程方面的调优,其实主要就是集中在,Netty的Boss跟WorkerEventLoop上了。BossEventLoop即所谓Reactor模型中的Accpetor线程池,WorkerEventGroup即所谓的Reactor线程池。
对于 Nety 服务端,通常只需要启动一个监听端口用于端侧设备接入即可,但是如果服务端集群实例比较少,甚至是单机(或者双机冷备)部署,在端侧设备在短时间内大量接入时,需要对服务端的监听方式和线程模型做优化,以满足短时间内(例如 30s)百万级的端侧设备接入的需要。
服务端可以监听多个端口,利用主从 Reactor 线程模型做接入优化,前端通过 SLB 做 4 层门 7 层负载均衡。
主从 Reactor 线程模型特点如下:服务端用于接收客户端连接、处理客户端IO事件的线程不再一条现成,而是一个NIO线程池。正常来说是两组Reactor线程池,即MainReactor和SubReactor。前者主要是处理客户端连接业务;后者接收IO读写业务。
对于 IO 工作线程池的优化,可以先采用系统默认值(即 CPU 内核数×2)进行性能测试,在性能测试过程中采集 IO 线程的 CPU 占用大小,看是否存在瓶颈,具体可以观察线程堆栈,如果连续采集几次进行对比,发现线程堆栈都停留在Selectorlmpl.lockAndDoSelect,则说明IO线程比较空闲,无须对工作线程数做调整;如果发现 IO 线程的热点停留在读或者写操作,或者停留在 Channelhandler 的执行处,则可以通过适当调大 Nio EventLoop 线程的个数来提升网络的读写性能
附上一张主从Reactor多线程模型图

第二步:心跳优化
1)有效监测无效连接,及时剔除,避免占用系统句柄资源
2)设置合理的心跳周期
3)使用Netty提供的链路空闲检测机制,不要自己创建定时任务线程池去做
第三步:接收和发送缓冲区调优
在一些场景下,端侧设备会周期性地上报数据和发送心跳,单个链路的消息收发量并不大,针对此类场景,可以通过调小 TCP 的接收和发送缓冲区来降低单个 TCP 连接的资源占用率
当然对于不同的应用场景,收发缓冲区的最优值可能不同,用户需要根据实际场景,结合性能测试数据进行针对性的调优
第四步:IO 线程和业务线程分离
如果服务端不做复杂的业务逻辑操作,仅是简单的内存操作和消息转发,则可以通过调大NioEventLoop工作线程池的方式,直接在IO线程中执行业务 Channelhandler,这样便减少了一线程上下文切换,性能反而更高。
如果有复杂的业务逻辑操作,则建议 IO 线程和业务线程分离,对于 IO 线程,由于互相之间不存在锁竞争,可以创建一个大的 NioEvent Loop Group 线程组,所有 Channel 都共享同一个线程池。
对于后端的业务线程池,则建议创建多个小的业务线程池,线程池可以与 IO 线程绑定,这样既减少了锁竞争,又提升了后端的处理性能。
3.2.3 JVM层面支持
当客户端的并发连接数达到数十万或者数百万时,系统一个较小的抖动就会导致很严重的后果。例如服务端的 GC,会导致STW(Stop-The-World)事件的发生,严重的时候可能会导致程序几秒钟不工作,这个在大并发的情况下是非常危险的。
JVM层面的调优主要在于【GC参数优化】,毕竟GC参数设置不当会导致频繁GC,甚至OOM异常,对服务端的稳定运行产生重大影响。解决思路通常如下:
1)确定GC优化目标
GC有三个主要指标:
- 吞吐量:吞吐量是评价 GC 能力的重要指标,在不考虑 GC 引起的停顿时间或内存消耗时,吞吐量是 GC 能支撑应用程序达到的最高性能指标
- 延迟(STW时间):GC 能力的最重要指标之一,是由于 GC 引起的停顿时间,优化目标是缩短延迟时间或完全消除停顿(STW),避免应用程序在运行过程中发生抖动
- 内存占用:GC 正常时占用的内存量
而对应过来,JVM调优的三个基本原则如下:
- MinorGC回收原则:每次新生代 GC 回收尽可能多的内存,减少应用程序发生 Full gc 的频率
- GC 内存最大化原则:垃圾收集器能够使用的内存越大,垃圾收集效率越高,应用程序越流畅。但是过大的内存一次 FullGC耗时比较长,毕竟要扫描的地方也比较多了。所以就需要比较精细的调优了
- 3 选 2 原则:吞吐量、延迟和内存占用是不太能够兼得的,无法同时做到吞吐量和暂停时间都最优,需要根据业务场景做选择。总得来说,对于大多数应用,吞吐量优先,其次是停顿时间
2)确定服务端内存占用
在优化 GC 之前,需要确定应用程序的内存占用大小,以便为应用程序设置合适的内存,提升 GC 效率。内存占用与活跃数据有关,活跃数据指的是应用程序稳定运行时长时间存活的Java 对象。活跃数据的计算方式:通过 GC 日志采集 GC 数据,获取应用程序稳定时老年代占用的 Java 堆大小,以及永久代(元数据区)占用的 Java 堆大小,两者之和就是活跃数据的内存占用大小
3)GC优化过程
- GC数据的采集和分析
- 设置合适的JVM堆大小
- 选择合适的垃圾回收器和回收策略
当然具体如何做,请参考 JVM 相关课程。而且 GC 调优会是一个需要多次调整的过程,期间不仅有参数的变化,更重要的是需要调整业务代码
学习总结
- 学习了Netty常用的调优参数
- 学习了序列化框架选择思路
感谢
感谢【智云科技】的文章《给我5分钟,一次性给你讲明白Java中的序列化和反序列化》
感谢本站大佬【作者:卒获有所闻】的文章《Netty序列化算法&参数调优》