自制编程语言基于c语言实验记录之七:总结第八章之内建类及方法
1.Bool类及方法
//返回核心类name的value结构
static Value getCoreClassValue(ObjModule* objModule, const char* name) {
int index = getIndexFromSymbolTable(&objModule->moduleVarName, name, strlen(name));
if (index == -1) {
char id[MAX_ID_LEN] = {'\0'};
memcpy(id, name, strlen(name));
RUN_ERROR("something wrong occur: missing core class \"%s\"!", id);
}
return objModule->moduleVarValue.datas[index];
}
//返回bool的字符串形式:"true"或"false"
static bool primBoolToString(VM* vm, Value* args) {
ObjString* objString;
if (VALUE_TO_BOOL(args[0])) { //若为VT_TRUE
objString = newObjString(vm, "true", 4);
} else {
objString = newObjString(vm, "false", 5);
}
RET_OBJ(objString);
}
//bool值取反
static bool primBoolNot(VM* vm UNUSED, Value* args) {
RET_BOOL(!VALUE_TO_BOOL(args[0]));
}
//编译核心模块
void buildCore(VM* vm) {
//核心模块不需要名字,模块也允许名字为空
ObjModule* coreModule = newObjModule(vm, NULL);
//创建核心模块,录入到vm->allModules
mapSet(vm, vm->allModules, CORE_MODULE, OBJ_TO_VALUE(coreModule));
//创建object类并绑定方法
vm->objectClass = defineClass(vm, coreModule, "object");
PRIM_METHOD_BIND(vm->objectClass, "!", primObjectNot);
PRIM_METHOD_BIND(vm->objectClass, "==(_)", primObjectEqual);
PRIM_METHOD_BIND(vm->objectClass, "!=(_)", primObjectNotEqual);
PRIM_METHOD_BIND(vm->objectClass, "is(_)", primObjectIs);
PRIM_METHOD_BIND(vm->objectClass, "toString", primObjectToString);
PRIM_METHOD_BIND(vm->objectClass, "type", primObjectType);
//定义classOfClass类,它是所有meta类的meta类和基类
vm->classOfClass = defineClass(vm, coreModule, "class");
//objectClass是任何类的基类
bindSuperClass(vm, vm->classOfClass, vm->objectClass);
PRIM_METHOD_BIND(vm->classOfClass, "name", primClassName);
PRIM_METHOD_BIND(vm->classOfClass, "supertype", primClassSupertype);
PRIM_METHOD_BIND(vm->classOfClass, "toString", primClassToString);
//定义object类的元信息类objectMetaclass,它无须挂载到vm
Class* objectMetaclass = defineClass(vm, coreModule, "objectMeta");
//classOfClass类是所有meta类的meta类和基类
bindSuperClass(vm, objectMetaclass, vm->classOfClass);
//类型比较
PRIM_METHOD_BIND(objectMetaclass, "same(_,_)", primObjectmetaSame);
//绑定各自的meta类
vm->objectClass->objHeader.class = objectMetaclass;
objectMetaclass->objHeader.class = vm->classOfClass;
vm->classOfClass->objHeader.class = vm->classOfClass; //元信息类回路,meta类终点
//执行核心模块
executeModule(vm, CORE_MODULE, coreModuleCode);
//Bool类定义在core.script.inc中,将其挂载Bool类到vm->boolClass
vm->boolClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Bool"));
PRIM_METHOD_BIND(vm->boolClass, "toString", primBoolToString);
PRIM_METHOD_BIND(vm->boolClass, "!", primBoolNot);
}
在核心模块coreModule的模块变量moduleVarValue中记录着Bool类。
Bool类获得后保存到vm->boolClass,并调用PRIM_METHOD_BIND绑定not、tostring方法
//绑定方法func到classPtr指向的类
#define PRIM_METHOD_BIND(classPtr, methodName, func) {\
uint32_t length = strlen(methodName);\
int globalIdx = getIndexFromSymbolTable(&vm->allMethodNames, methodName, length);\
if (globalIdx == -1) {\
globalIdx = addSymbol(vm, &vm->allMethodNames, methodName, length);\
}\
Method method;\
method.type = MT_PRIMITIVE;\
method.primFn = func;\
bindMethod(vm, classPtr, (uint32_t)globalIdx, method);\
}
method保存到classPtr指向的类中,当虚拟机执行callX的时候,会先对method的type做判断,如果类型为MT_PRIMITIVE,说明是原生方法,从而调用method->func来执行c语言实现的原生方法。同时,args作为func的参数,args[0]是实例、实例的类或类的元类。args[1]开始都是要执行的方法的参数
2.Thread类及其方法
2.1 线程的具体用法举例

可以看出来,Thread.yield的传参"see you again"是t.call的返回值,而t.call的传参"welcome back"是Thread.yield的返回值。t.call负责执行线程,Thread.yield负责让出cpu给主调方。
2.2 线程类的方法
//以下以大写字符开头的为类名,表示类(静态)方法调用
//Thread.new(func):创建一个thread实例
static bool primThreadNew(VM* vm, Value* args) {
//代码块为参数必为闭包
if (!validateFn(vm, args[1])) {
return false;
}
ObjThread* objThread = newObjThread(vm, VALUE_TO_OBJCLOSURE(args[1]));
//使stack[0]为接收者,保持栈平衡
objThread->stack[0] = VT_TO_VALUE(VT_NULL);
objThread->esp++;
RET_OBJ(objThread);
}
创建线程实例,stack[0]为接收者,栈顶为stack[1],存储着线程实例,而args[1]就是该原生方法的参数,在编译方法调用的时候,已经调用processArgList中的expression将方法实参压入栈顶。创建线程的参数为函数。newObjThread创建线程,线程有一个大运行时栈。线程有很多个框架,每个框架有一个小运行时栈,作为函数运行的运行时栈。newObjThread已经将传入的闭包(即为该线程第一个执行的函数)准备在该线程最新的框架上。Thread.new会调用该原生方法primThreadNew
//Thread.abort(err):以错误信息err为参数退出线程
static bool primThreadAbort(VM* vm, Value* args) {
//此函数后续未处理,暂时放着
vm->curThread->errorObj = args[1]; //保存退出参数
return VALUE_IS_NULL(args[1]);
}
//Thread.current:返回当前的线程
static bool primThreadCurrent(VM* vm, Value* args UNUSED) {
RET_OBJ(vm->curThread);
}
//Thread.suspend():挂起线程,退出解析器
static bool primThreadSuspend(VM* vm, Value* args UNUSED) {
//目前suspend操作只会退出虚拟机,
//使curThread为NULL,虚拟机将退出
vm->curThread = NULL;
return false;
}
//Thread.yield(arg)带参数让出cpu
static bool primThreadYieldWithArg(VM* vm, Value* args) {
ObjThread* curThread = vm->curThread;
vm->curThread = curThread->caller; //使cpu控制权回到主调方
curThread->caller = NULL; //与调用者断开联系
if (vm->curThread != NULL) {
//如果当前线程有主调方,就将当前线程的返回值放在主调方的栈顶
vm->curThread->esp[-1] = args[1];
//对于"thread.yield(arg)"来说, 回收arg的空间,
//保留thread参数所在的空间,将来唤醒时用于存储yield结果
curThread->esp--;
}
return false;
}
//Thread.yield() 无参数让出cpu
static bool primThreadYieldWithoutArg(VM* vm, Value* args UNUSED) {
ObjThread* curThread = vm->curThread;
vm->curThread = curThread->caller; //使cpu控制权回到主调方
curThread->caller = NULL; //与调用者断开联系
if (vm->curThread != NULL) {
//为保持通用的栈结构,如果当前线程有主调方,
//就将空值做为返回值放在主调方的栈顶
vm->curThread->esp[-1] = VT_TO_VALUE(VT_NULL) ;
}
return false;
}
Thread.abort(err)的原生方法primThreadAbort,errorObj不为空表示异常
primThreadCurrent返回当前线程,Thread.current
primThreadSuspend,线程挂机,Thread.suspend
primThreadYieldWithArg,Thread.yield(arg),线程让出cpu,使cpu控制权回到主调方,主调方线程保存在curThread->caller,类Thread是arg[0],arg[1]是arg放在主调方栈顶,作为主调方的返回值,主线程一定是t.call来调用的,t是线程实例,返回false表示要切换线程。
对于Thread.yield(arg),为什么args[0]是类Thread,args[1]是arg,可以回看CALLX代码
argNum还加了1,也就是还算上了调用对象(线程类实例或者线程类)
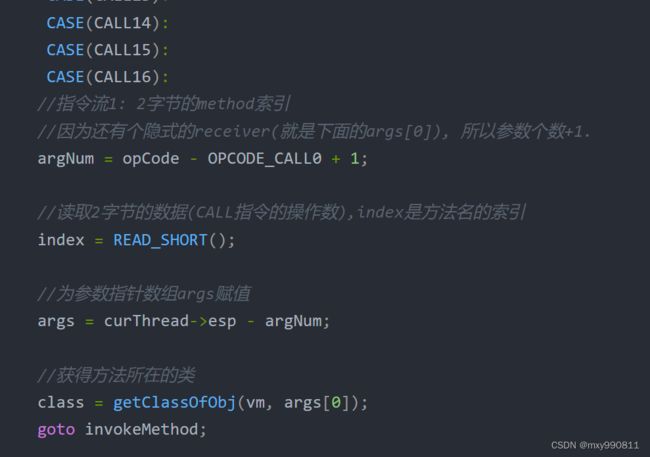
//切换到下一个线程nextThread
static bool switchThread(VM* vm,
ObjThread* nextThread, Value* args, bool withArg) {
//在下一线程nextThread执行之前,其主调线程应该为空
if (nextThread->caller != NULL) {
RUN_ERROR("thread has been called!");
}
nextThread->caller = vm->curThread;
if (nextThread->usedFrameNum == 0) {
//只有已经运行完毕的thread的usedFrameNum才为0
SET_ERROR_FALSE(vm, "a finished thread can`t be switched to!");
}
if (!VALUE_IS_NULL(nextThread->errorObj)) {
//Thread.abort(arg)会设置errorObj, 不能切换到abort的线程
SET_ERROR_FALSE(vm, "a aborted thread can`t be switched to!");
}
//如果call有参数,回收参数的空间,
//只保留次栈顶用于存储nextThread返回后的结果
if (withArg) {
vm->curThread->esp--;
}
ASSERT(nextThread->esp > nextThread->stack, "esp should be greater than stack!");
//nextThread.call(arg)中的arg做为nextThread.yield的返回值
//存储到nextThread的栈顶,否则压入null保持栈平衡
nextThread->esp[-1] = withArg ? args[1] : VT_TO_VALUE(VT_NULL);
//使当前线程指向nextThread,使之成为就绪
vm->curThread = nextThread;
//返回false以进入vm中的切换线程流程
return false;
}
//objThread.call()
static bool primThreadCallWithoutArg(VM* vm, Value* args) {
return switchThread(vm, VALUE_TO_OBJTHREAD(args[0]), args, false);
}
//objThread.call(arg)
static bool primThreadCallWithArg(VM* vm, Value* args) {
return switchThread(vm, VALUE_TO_OBJTHREAD(args[0]), args, true);
}
//objThread.isDone返回线程是否运行完成
static bool primThreadIsDone(VM* vm UNUSED, Value* args) {
//获取.isDone的调用者
ObjThread* objThread = VALUE_TO_OBJTHREAD(args[0]);
RET_BOOL(objThread->usedFrameNum == 0 || !VALUE_IS_NULL(objThread->errorObj));
}
//Thread类也是在core.script.inc中定义的,
//将其挂载到vm->threadClass并补充原生方法
vm->threadClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Thread"));
//以下是类方法
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "new(_)", primThreadNew);
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "abort(_)", primThreadAbort);
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "current", primThreadCurrent);
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "suspend()", primThreadSuspend);
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "yield(_)", primThreadYieldWithArg);
PRIM_METHOD_BIND(vm->threadClass->objHeader.class, "yield()", primThreadYieldWithoutArg);
//以下是实例方法
PRIM_METHOD_BIND(vm->threadClass, "call()", primThreadCallWithoutArg);
PRIM_METHOD_BIND(vm->threadClass, "call(_)", primThreadCallWithArg);
PRIM_METHOD_BIND(vm->threadClass, "isDone", primThreadIsDone);
当前线程esp减一是因为主线程需要切换线程时,运行时栈分别是线程实例nextThread和要传入给待切换线程的参数args,占了两个slot,但是主线程只需要一个slot存储nextThread的返回值。
nextThread.call(arg)中的arg做为nextThread.yield的返回值被nextThread使用,因此存储在nextThread的栈顶。
线程类的类方法注册到线程类vm->threadClass的meta类即vm->threadClass->objHeader.class
线程类的实例方法注册到线程类中
3.函数类及其方法和函数调用重载
3.1 函数调用与方法调用的区别

tt是t的等价形式,t接收块参数
3.2 函数类原生方法
//Fn.new(_):新建一个函数对象
static bool primFnNew(VM* vm, Value* args) {
//代码块为参数必为闭包
if (!validateFn(vm, args[1])) return false;
//直接返回函数闭包
RET_VALUE(args[1]);
}
primFnNew:块参数即args[1]
3.3 call的重载
//绑定fn.call的重载
static void bindFnOverloadCall(VM* vm, const char* sign) {
uint32_t index = ensureSymbolExist(vm, &vm->allMethodNames, sign, strlen(sign));
//构造method
Method method = {MT_FN_CALL, {0}};
bindMethod(vm, vm->fnClass, index, method);
}
//绑定函数类
vm->fnClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Fn"));
PRIM_METHOD_BIND(vm->fnClass->objHeader.class, "new(_)", primFnNew);
//绑定call的重载方法
bindFnOverloadCall(vm, "call()");
bindFnOverloadCall(vm, "call(_)");
bindFnOverloadCall(vm, "call(_,_)");
bindFnOverloadCall(vm, "call(_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_,_,_,_,_)");
bindFnOverloadCall(vm, "call(_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_)");
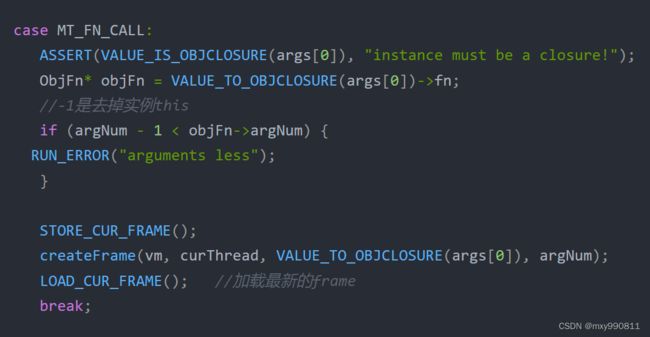
args[0]是函数实例对象,也就是函数闭包。fn.call是由函数实例调用,fn为函数实例。 bindFnOverloadCall将call方法存储到了vm->fnClass,所以call是实例方法,call方法method类型是MT_FN_CALL
4 NULL类及其方法
4.1 NULL类使用例子

4.2 NULL的原生方法
//null取非
static bool primNullNot(VM* vm UNUSED, Value* args UNUSED) {
RET_VALUE(BOOL_TO_VALUE(true));
}
//null的字符串化
static bool primNullToString(VM* vm, Value* args UNUSED) {
ObjString* objString = newObjString(vm, "null", 4);
RET_OBJ(objString);
}
//绑定Null类的方法
vm->nullClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Null"));
PRIM_METHOD_BIND(vm->nullClass, "!", primNullNot);
PRIM_METHOD_BIND(vm->nullClass, "toString", primNullToString);
!和tostring都是NULL类的实例方法
5 Num类及其方法
5.1 NUM类使用例子

5.2 NUM类的方法
//将数字转换为字符串
static ObjString* num2str(VM* vm, double num) {
//nan不是一个确定的值,因此nan和nan是不相等的
if (num != num) {
return newObjString(vm, "nan", 3);
}
if (num == INFINITY) {
return newObjString(vm, "infinity", 8);
}
if (num == -INFINITY) {
return newObjString(vm, "-infinity", 9);
}
//以下24字节的缓冲区足以容纳双精度到字符串的转换
char buf[24] = {'\0'};
int len = sprintf(buf, "%.14g", num);
return newObjString(vm, buf, len);
}
//判断arg是否为数字
static bool validateNum(VM* vm, Value arg) {
if (VALUE_IS_NUM(arg)) {
return true;
}
SET_ERROR_FALSE(vm, "argument must be number!");
}
//判断arg是否为字符串
static bool validateString(VM* vm, Value arg) {
if (VALUE_IS_OBJSTR(arg)) {
return true;
}
SET_ERROR_FALSE(vm, "argument must be string!");
}
//将字符串转换为数字
static bool primNumFromString(VM* vm, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* objString = VALUE_TO_OBJSTR(args[1]);
//空字符串返回RETURN_NULL
if (objString->value.length == 0) {
RET_NULL;
}
ASSERT(objString->value.start[objString->value.length] == '\0', "objString don`t teminate!");
errno = 0;
char* endPtr;
//将字符串转换为double型, 它会自动跳过前面的空白
double num = strtod(objString->value.start, &endPtr);
//以endPtr是否等于start+length来判断不能转换的字符之后是否全是空白
while (*endPtr != '\0' && isspace((unsigned char)*endPtr)) {
endPtr++;
}
if (errno == ERANGE) {
RUN_ERROR("string too large!");
}
//如果字符串中不能转换的字符不全是空白,字符串非法,返回NULL
if (endPtr < objString->value.start + objString->value.length) {
RET_NULL;
}
//至此,检查通过,返回正确结果
RET_NUM(num);
}
//返回圆周率
static bool primNumPi(VM* vm UNUSED, Value* args UNUSED) {
RET_NUM(3.14159265358979323846);
}
#define PRIM_NUM_INFIX(name, operator, type) \
static bool name(VM* vm, Value* args) {\
if (!validateNum(vm, args[1])) {\
return false; \
}\
RET_##type(VALUE_TO_NUM(args[0]) operator VALUE_TO_NUM(args[1]));\
}
PRIM_NUM_INFIX(primNumPlus, +, NUM);
PRIM_NUM_INFIX(primNumMinus, -, NUM);
PRIM_NUM_INFIX(primNumMul, *, NUM);
PRIM_NUM_INFIX(primNumDiv, /, NUM);
PRIM_NUM_INFIX(primNumGt, >, BOOL);
PRIM_NUM_INFIX(primNumGe, >=, BOOL);
PRIM_NUM_INFIX(primNumLt, <, BOOL);
PRIM_NUM_INFIX(primNumLe, <=, BOOL);
#undef PRIM_NUM_INFIX
#define PRIM_NUM_BIT(name, operator) \
static bool name(VM* vm UNUSED, Value* args) {\
if (!validateNum(vm, args[1])) {\
return false;\
}\
uint32_t leftOperand = VALUE_TO_NUM(args[0]); \
uint32_t rightOperand = VALUE_TO_NUM(args[1]); \
RET_NUM(leftOperand operator rightOperand);\
}
PRIM_NUM_BIT(primNumBitAnd, &);
PRIM_NUM_BIT(primNumBitOr, |);
PRIM_NUM_BIT(primNumBitShiftRight, >>);
PRIM_NUM_BIT(primNumBitShiftLeft, <<);
#undef PRIM_NUM_BIT
//使用数学库函数
#define PRIM_NUM_MATH_FN(name, mathFn) \
static bool name(VM* vm UNUSED, Value* args) {\
RET_NUM(mathFn(VALUE_TO_NUM(args[0]))); \
}
PRIM_NUM_MATH_FN(primNumAbs, fabs);
PRIM_NUM_MATH_FN(primNumAcos, acos);
PRIM_NUM_MATH_FN(primNumAsin, asin);
PRIM_NUM_MATH_FN(primNumAtan, atan);
PRIM_NUM_MATH_FN(primNumCeil, ceil);
PRIM_NUM_MATH_FN(primNumCos, cos);
PRIM_NUM_MATH_FN(primNumFloor, floor);
PRIM_NUM_MATH_FN(primNumNegate, -);
PRIM_NUM_MATH_FN(primNumSin, sin);
PRIM_NUM_MATH_FN(primNumSqrt, sqrt); //开方
PRIM_NUM_MATH_FN(primNumTan, tan);
#undef PRIM_NUM_MATH_FN
//这里用fmod实现浮点取模
static bool primNumMod(VM* vm UNUSED, Value* args) {
if (!validateNum(vm, args[1])) {
return false;
}
RET_NUM(fmod(VALUE_TO_NUM(args[0]), VALUE_TO_NUM(args[1])));
}
//数字取反
static bool primNumBitNot(VM* vm UNUSED, Value* args) {
RET_NUM(~(uint32_t)VALUE_TO_NUM(args[0]));
}
//[数字from..数字to]
static bool primNumRange(VM* vm UNUSED, Value* args) {
if (!validateNum(vm, args[1])) {
return false;
}
double from = VALUE_TO_NUM(args[0]);
double to = VALUE_TO_NUM(args[1]);
RET_OBJ(newObjRange(vm, from, to));
}
//atan2(args[1])
static bool primNumAtan2(VM* vm UNUSED, Value* args) {
if (!validateNum(vm, args[1])) {
return false;
}
RET_NUM(atan2(VALUE_TO_NUM(args[0]), VALUE_TO_NUM(args[1])));
}
//返回小数部分
static bool primNumFraction(VM* vm UNUSED, Value* args) {
double dummyInteger;
RET_NUM(modf(VALUE_TO_NUM(args[0]), &dummyInteger));
}
//判断数字是否无穷大,不区分正负无穷大
static bool primNumIsInfinity(VM* vm UNUSED, Value* args) {
RET_BOOL(isinf(VALUE_TO_NUM(args[0])));
}
//判断是否为数字
static bool primNumIsInteger(VM* vm UNUSED, Value* args) {
double num = VALUE_TO_NUM(args[0]);
//如果是nan(不是一个数字)或无限大的数字就返回false
if (isnan(num) || isinf(num)) {
RET_FALSE;
}
RET_BOOL(trunc(num) == num);
}
//判断数字是否为nan
static bool primNumIsNan(VM* vm UNUSED, Value* args) {
RET_BOOL(isnan(VALUE_TO_NUM(args[0])));
}
//数字转换为字符串
static bool primNumToString(VM* vm UNUSED, Value* args) {
RET_OBJ(num2str(vm, VALUE_TO_NUM(args[0])));
}
//取数字的整数部分
static bool primNumTruncate(VM* vm UNUSED, Value* args) {
double integer;
modf(VALUE_TO_NUM(args[0]), &integer);
RET_NUM(integer);
}
//判断两个数字是否相等
static bool primNumEqual(VM* vm UNUSED, Value* args) {
if (!validateNum(vm, args[1])) {
RET_FALSE;
}
RET_BOOL(VALUE_TO_NUM(args[0]) == VALUE_TO_NUM(args[1]));
}
//判断两个数字是否不等
static bool primNumNotEqual(VM* vm UNUSED, Value* args) {
if (!validateNum(vm, args[1])) {
RET_TRUE;
}
RET_BOOL(VALUE_TO_NUM(args[0]) != VALUE_TO_NUM(args[1]));
}
//绑定num类方法
vm->numClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Num"));
//类方法
PRIM_METHOD_BIND(vm->numClass->objHeader.class, "fromString(_)", primNumFromString);
PRIM_METHOD_BIND(vm->numClass->objHeader.class, "pi", primNumPi);
//实例方法
PRIM_METHOD_BIND(vm->numClass, "+(_)", primNumPlus);
PRIM_METHOD_BIND(vm->numClass, "-(_)", primNumMinus);
PRIM_METHOD_BIND(vm->numClass, "*(_)", primNumMul);
PRIM_METHOD_BIND(vm->numClass, "/(_)", primNumDiv);
PRIM_METHOD_BIND(vm->numClass, ">(_)", primNumGt);
PRIM_METHOD_BIND(vm->numClass, ">=(_)", primNumGe);
PRIM_METHOD_BIND(vm->numClass, "<(_)", primNumLt);
PRIM_METHOD_BIND(vm->numClass, "<=(_)", primNumLe);
//位运算
PRIM_METHOD_BIND(vm->numClass, "&(_)", primNumBitAnd);
PRIM_METHOD_BIND(vm->numClass, "|(_)", primNumBitOr);
PRIM_METHOD_BIND(vm->numClass, ">>(_)", primNumBitShiftRight);
PRIM_METHOD_BIND(vm->numClass, "<<(_)", primNumBitShiftLeft);
//以上都是通过rules中INFIX_OPERATOR来解析的
//下面大多数方法是通过rules中'.'对应的led(callEntry)来解析,
//少数符号依然是INFIX_OPERATOR解析
PRIM_METHOD_BIND(vm->numClass, "abs", primNumAbs);
PRIM_METHOD_BIND(vm->numClass, "acos", primNumAcos);
PRIM_METHOD_BIND(vm->numClass, "asin", primNumAsin);
PRIM_METHOD_BIND(vm->numClass, "atan", primNumAtan);
PRIM_METHOD_BIND(vm->numClass, "ceil", primNumCeil);
PRIM_METHOD_BIND(vm->numClass, "cos", primNumCos);
PRIM_METHOD_BIND(vm->numClass, "floor", primNumFloor);
PRIM_METHOD_BIND(vm->numClass, "-", primNumNegate);
PRIM_METHOD_BIND(vm->numClass, "sin", primNumSin);
PRIM_METHOD_BIND(vm->numClass, "sqrt", primNumSqrt);
PRIM_METHOD_BIND(vm->numClass, "tan", primNumTan);
PRIM_METHOD_BIND(vm->numClass, "%(_)", primNumMod);
PRIM_METHOD_BIND(vm->numClass, "~", primNumBitNot);
PRIM_METHOD_BIND(vm->numClass, "..(_)", primNumRange);
PRIM_METHOD_BIND(vm->numClass, "atan(_)", primNumAtan2);
PRIM_METHOD_BIND(vm->numClass, "fraction", primNumFraction);
PRIM_METHOD_BIND(vm->numClass, "isInfinity", primNumIsInfinity);
PRIM_METHOD_BIND(vm->numClass, "isInteger", primNumIsInteger);
PRIM_METHOD_BIND(vm->numClass, "isNan", primNumIsNan);
PRIM_METHOD_BIND(vm->numClass, "toString", primNumToString);
PRIM_METHOD_BIND(vm->numClass, "truncate", primNumTruncate);
PRIM_METHOD_BIND(vm->numClass, "==(_)", primNumEqual);
PRIM_METHOD_BIND(vm->numClass, "!=(_)", primNumNotEqual);
primNumFromString将字符串args[1]转化为数字
PRIM_NUM_INFIX为宏,生成了大部分中缀运算符的原生方法,而中缀运算符的调用来自expression执行中缀运算符.led方法生成的指令。
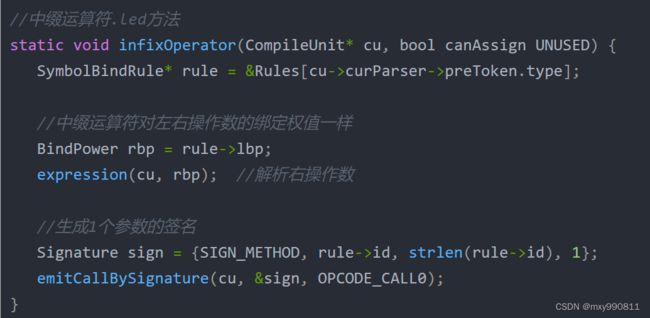
6 String类及其方法
6.1 String类用法举例

6.2 String类的基础函数
typedef struct {
ObjHeader objHeader;
uint32_t hashCode; //字符串的哈希值
CharValue value;
} ObjString;
typedef struct {
uint32_t length; //除结束'\0'之外的字符个数
char start[0]; //类似c99中的柔性数组
} CharValue; //字符串缓冲区
ObjString.value存储的是UTF-8流
//确认value是否为整数
static bool validateIntValue(VM* vm, double value) {
if (trunc(value) == value) {
return true;
}
SET_ERROR_FALSE(vm, "argument must be integer!");
}
//校验arg是否为整数
static bool validateInt(VM* vm, Value arg) {
//首先得是数字
if (!validateNum(vm, arg)) {
return false;
}
//再校验数值
return validateIntValue(vm, VALUE_TO_NUM(arg));
}
//校验参数index是否是落在"[0, length)"之间的整数
static uint32_t validateIndexValue(VM* vm, double index, uint32_t length) {
//索引必须是数字
if (!validateIntValue(vm, index)) {
return UINT32_MAX;
}
//支持负数索引,负数是从后往前索引
//转换其对应的正数索引.如果校验失败则返回UINT32_MAX
if (index < 0) {
index += length;
}
//索引应该落在[0,length)
if (index >= 0 && index < length) {
return (uint32_t)index;
}
//执行到此说明超出范围
vm->curThread->errorObj =
OBJ_TO_VALUE(newObjString(vm, "index out of bound!", 19));
return UINT32_MAX;
}
//验证index有效性
static uint32_t validateIndex(VM* vm, Value index, uint32_t length) {
if (!validateNum(vm, index)) {
return UINT32_MAX;
}
return validateIndexValue(vm, VALUE_TO_NUM(index), length);
}
//从码点value创建字符串
static Value makeStringFromCodePoint(VM* vm, int value) {
uint32_t byteNum = getByteNumOfEncodeUtf8(value);
ASSERT(byteNum != 0, "utf8 encode bytes should be between 1 and 4!");
//+1是为了结尾的'\0'
ObjString* objString = ALLOCATE_EXTRA(vm, ObjString, byteNum + 1);
if (objString == NULL) {
MEM_ERROR("allocate memory failed in runtime!");
}
initObjHeader(vm, &objString->objHeader, OT_STRING, vm->stringClass);
objString->value.length = byteNum;
objString->value.start[byteNum] = '\0';
encodeUtf8((uint8_t*)objString->value.start, value);
hashObjString(objString);
return OBJ_TO_VALUE(objString);
}
//用索引index处的字符创建字符串对象
static Value stringCodePointAt(VM* vm, ObjString* objString, uint32_t index) {
ASSERT(index < objString->value.length, "index out of bound!");
int codePoint = decodeUtf8((uint8_t*)objString->value.start + index,
objString->value.length - index);
//若不是有效的utf8序列,将其处理为单个裸字符
if (codePoint == -1) {
return OBJ_TO_VALUE(newObjString(vm, &objString->value.start[index], 1));
}
return makeStringFromCodePoint(vm, codePoint);
}
//fnv-1a算法
uint32_t hashString(char* str, uint32_t length) {
uint32_t hashCode = 2166136261, idx = 0;
while (idx < length) {
hashCode ^= str[idx];
hashCode *= 16777619;
idx++;
}
return hashCode;
}
//为string计算哈希码并将值存储到string->hash
void hashObjString(ObjString* objString) {
objString->hashCode =
hashString(objString->value.start, objString->value.length);
}
validateIndex:先调用validateNum保证索引必须是数字,再掉validateIndexValue保证索引必须是0到length的整数,其中validateIndexValue调用了validateIntValue确保索引是整数,正负均可。
makeStringFromCodePoint: value是unicode的码点,对value进行UTF-8编码,然后保存到ObjString,在生成ObjString的哈希码并返回ObjString。
stringCodePointAt:对某个字符串UTF-8流的index处的字节,先解析出对应的字符的码点,再调用makeStringFromCodePoint将码点变成UTF-8编码,创建ObjString,返回ObjString转Value。
//计算objRange中元素的起始索引及索引方向
static uint32_t calculateRange(VM* vm,
ObjRange* objRange, uint32_t* countPtr, int* directionPtr) {
uint32_t from = validateIndexValue(vm, objRange->from, *countPtr);
if (from == UINT32_MAX) {
return UINT32_MAX;
}
uint32_t to = validateIndexValue(vm, objRange->to, *countPtr);
if (to == UINT32_MAX) {
return UINT32_MAX;
}
//如果from和to为负值,经过validateIndexValue已经变成了相应的正索引
*directionPtr = from < to ? 1 : -1;
*countPtr = abs((int)(from - to)) + 1;
return from;
}
//以utf8编码从source中起始为startIndex,方向为direction的count个字符创建字符串
static ObjString* newObjStringFromSub(VM* vm, ObjString* sourceStr,
int startIndex, uint32_t count, int direction) {
uint8_t* source = (uint8_t*)sourceStr->value.start;
uint32_t totalLength = 0, idx = 0;
//计算count个utf8编码的字符总共需要的字节数,后面好申请空间
while (idx < count) {
totalLength += getByteNumOfDecodeUtf8(source[startIndex + idx * direction]);
idx++;
}
//+1是为了结尾的'\0'
ObjString* result = ALLOCATE_EXTRA(vm, ObjString, totalLength + 1);
if (result == NULL) {
MEM_ERROR("allocate memory failed in runtime!");
}
initObjHeader(vm, &result->objHeader, OT_STRING, vm->stringClass);
result->value.start[totalLength] = '\0';
result->value.length = totalLength;
uint8_t* dest = (uint8_t*)result->value.start;
idx = 0;
while (idx < count) {
int index = startIndex + idx * direction;
//解码,获取字符数据
int codePoint = decodeUtf8(source + index, sourceStr->value.length - index);
if (codePoint != -1) {
//再将数据按照utf8编码,写入result
dest += encodeUtf8(dest, codePoint);
}
idx++;
}
hashObjString(result);
return result;
}
//使用Boyer-Moore-Horspool字符串匹配算法在haystack中查找needle,大海捞针
static int findString(ObjString* haystack, ObjString* needle) {
//如果待查找的patten为空则为找到
if (needle->value.length == 0) {
return 0; //返回起始下标0
}
//若待搜索的字符串比原串还长 肯定搜不到
if (needle->value.length > haystack->value.length) {
return -1;
}
//构建"bad-character shift表"以确定窗口滑动的距离
//数组shift的值便是滑动距离
uint32_t shift[UINT8_MAX];
//needle中最后一个字符的下标
uint32_t needleEnd = needle->value.length - 1;
//一、 先假定"bad character"不属于needle(即pattern),
//对于这种情况,滑动窗口跨过整个needle
uint32_t idx = 0;
while (idx < UINT8_MAX) {
// 默认为滑过整个needle的长度
shift[idx] = needle->value.length;
idx++;
}
//二、假定haystack中与needle不匹配的字符在needle中之前已匹配过的位置出现过
//就滑动窗口以使该字符与在needle中匹配该字符的最末位置对齐。
//这里预先确定需要滑动的距离
idx = 0;
while (idx < needleEnd) {
char c = needle->value.start[idx];
//idx从前往后遍历needle,当needle中有重复的字符c时,
//后面的字符c会覆盖前面的同名字符c,这保证了数组shilf中字符是needle中最末位置的字符,
//从而保证了shilf[c]的值是needle中最末端同名字符与needle末端的偏移量
shift[(uint8_t)c] = needleEnd - idx;
idx++;
}
//Boyer-Moore-Horspool是从后往前比较,这是处理bad-character高效的地方,
//因此获取needle中最后一个字符,用于同haystack的窗口中最后一个字符比较
char lastChar = needle->value.start[needleEnd];
//长度差便是滑动窗口的滑动范围
uint32_t range = haystack->value.length - needle->value.length;
//从haystack中扫描needle,寻找第1个匹配的字符 如果遍历完了就停止
idx = 0;
while (idx <= range) {
//拿needle中最后一个字符同haystack窗口的最后一个字符比较
//(因为Boyer-Moore-Horspool是从后往前比较), 如果匹配,看整个needle是否匹配
char c = haystack->value.start[idx + needleEnd];
if (lastChar == c &&
memcmp(haystack->value.start + idx, needle->value.start, needleEnd) == 0) {
//找到了就返回匹配的位置
return idx;
}
//否则就向前滑动继续下一伦比较
idx += shift[(uint8_t)c];
}
//未找到就返回-1
return -1;
}
static ObjString* newObjStringFromSub(VM* vm, ObjString* sourceStr, int startIndex, uint32_t count, int direction):sourceStr是某字符串的一串UTF-8的流,该函数将sourceStr的startIndex起始的count个字符组成UTF-8流返回。注意,count代表的是UTF-8编码字节数,比如字符串"我w",这个字符串的count是3,因为汉字的unicode码点是2字节对应的UTF-8编码大概率也是两字节("我"的unicode码点具体我不知道,理解就行)
findString:Boyer-Moore Horspool 字符串匹配算法在 haystack 中查找 needle
6.3 String类的原生方法
//objString.fromCodePoint(_):从码点建立字符串
static bool primStringFromCodePoint(VM* vm, Value* args) {
if (!validateInt(vm, args[1])) {
return false;
}
int codePoint = (int)VALUE_TO_NUM(args[1]);
if (codePoint < 0) {
SET_ERROR_FALSE(vm, "code point can`t be negetive!");
}
if (codePoint > 0x10ffff) {
SET_ERROR_FALSE(vm, "code point must be between 0 and 0x10ffff!");
}
RET_VALUE(makeStringFromCodePoint(vm, codePoint));
}
//objString+objString: 字符串相加
static bool primStringPlus(VM* vm, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* left = VALUE_TO_OBJSTR(args[0]);
ObjString* right = VALUE_TO_OBJSTR(args[1]);
uint32_t totalLength = strlen(left->value.start) + strlen(right->value.start);
//+1是为了结尾的'\0'
ObjString* result = ALLOCATE_EXTRA(vm, ObjString, totalLength + 1);
if (result == NULL) {
MEM_ERROR("allocate memory failed in runtime!");
}
initObjHeader(vm, &result->objHeader, OT_STRING, vm->stringClass);
memcpy(result->value.start, left->value.start, strlen(left->value.start));
memcpy(result->value.start + strlen(left->value.start),
right->value.start, strlen(right->value.start));
result->value.start[totalLength] = '\0';
result->value.length = totalLength;
hashObjString(result);
RET_OBJ(result);
}
//objString[_]:用数字或objRange对象做字符串的subscript
static bool primStringSubscript(VM* vm, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
//数字和objRange都可以做索引,分别判断
//若索引是数字,就直接索引1个字符,这是最简单的subscript
if (VALUE_IS_NUM(args[1])) {
uint32_t index = validateIndex(vm, args[1], objString->value.length);
if (index == UINT32_MAX) {
return false;
}
RET_VALUE(stringCodePointAt(vm, objString, index));
}
//索引要么为数字要么为ObjRange,若不是数字就应该为objRange
if (!VALUE_IS_OBJRANGE(args[1])) {
SET_ERROR_FALSE(vm, "subscript should be integer or range!");
}
//direction是索引的方向,
//1表示正方向,从前往后.-1表示反方向,从后往前.
//from若比to大,即从后往前检索字符,direction则为-1
int direction;
uint32_t count = objString->value.length;
//返回的startIndex是objRange.from在objString.value.start中的下标
uint32_t startIndex = calculateRange(vm, VALUE_TO_OBJRANGE(args[1]), &count, &direction);
if (startIndex == UINT32_MAX) {
return false;
}
RET_OBJ(newObjStringFromSub(vm, objString, startIndex, count, direction));
}
//objString.byteAt_():返回指定索引的字节
static bool primStringByteAt(VM* vm UNUSED, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
uint32_t index = validateIndex(vm, args[1], objString->value.length);
if (index == UINT32_MAX) {
return false;
}
//故转换为数字返回
RET_NUM((uint8_t)objString->value.start[index]);
}
//objString.byteCount_:返回字节数
static bool primStringByteCount(VM* vm UNUSED, Value* args) {
RET_NUM(VALUE_TO_OBJSTR(args[0])->value.length);
}
//objString.codePointAt_(_):返回指定的CodePoint
static bool primStringCodePointAt(VM* vm UNUSED, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
uint32_t index = validateIndex(vm, args[1], objString->value.length);
if (index == UINT32_MAX) {
return false;
}
const uint8_t* bytes = (uint8_t*)objString->value.start;
if ((bytes[index] & 0xc0) == 0x80) {
//如果index指向的并不是utf8编码的最高字节
//而是后面的低字节,返回-1提示用户
RET_NUM(-1);
}
//返回解码
RET_NUM(decodeUtf8((uint8_t*)objString->value.start + index,
objString->value.length - index));
}
//objString.contains(_):判断字符串args[0]中是否包含子字符串args[1]
static bool primStringContains(VM* vm UNUSED, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
ObjString* pattern = VALUE_TO_OBJSTR(args[1]);
RET_BOOL(findString(objString, pattern) != -1);
}
//objString.endsWith(_): 返回字符串是否以args[1]为结束
static bool primStringEndsWith(VM* vm UNUSED, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
ObjString* pattern = VALUE_TO_OBJSTR(args[1]);
//若pattern比源串还长,源串必然不包括pattern
if (pattern->value.length > objString->value.length) {
RET_FALSE;
}
char* cmpIdx = objString->value.start +
objString->value.length - pattern->value.length;
RET_BOOL(memcmp(cmpIdx, pattern->value.start, pattern->value.length) == 0);
}
//objString.indexOf(_):检索字符串args[0]中子串args[1]的起始下标
static bool primStringIndexOf(VM* vm UNUSED, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
ObjString* pattern = VALUE_TO_OBJSTR(args[1]);
//若pattern比源串还长,源串必然不包括pattern
if (pattern->value.length > objString->value.length) {
RET_FALSE;
}
int index = findString(objString, pattern);
RET_NUM(index);
}
//objString.iterate(_):返回下一个utf8字符(不是字节)的迭代器
static bool primStringIterate(VM* vm UNUSED, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
//如果是第一次迭代 迭代索引肯定为空
if (VALUE_IS_NULL(args[1])) {
if (objString->value.length == 0) {
RET_FALSE;
}
RET_NUM(0);
}
//迭代器必须是正整数
if (!validateInt(vm, args[1])){
return false;
}
double iter = VALUE_TO_NUM(args[1]);
if (iter < 0) {
RET_FALSE;
}
uint32_t index = (uint32_t)iter;
do {
index++;
//到了结尾就返回false,表示迭代完毕
if (index >= objString->value.length) RET_FALSE;
//读取连续的数据字节,直到下一个Utf8的高字节
} while ((objString->value.start[index] & 0xc0) == 0x80);
RET_NUM(index);
}
//objString.iterateByte_(_): 迭代索引,内部使用
static bool primStringIterateByte(VM* vm UNUSED, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
//如果是第一次迭代 迭代索引肯定为空 直接返回索引0
if (VALUE_IS_NULL(args[1])) {
if (objString->value.length == 0) {
RET_FALSE;
}
RET_NUM(0);
}
//迭代器必须是正整数
if (!validateInt(vm, args[1])) {
return false;
}
double iter = VALUE_TO_NUM(args[1]);
if (iter < 0) {
RET_FALSE;
}
uint32_t index = (uint32_t)iter;
index++; //移进到下一个字节的索引
if (index >= objString->value.length) {
RET_FALSE;
}
RET_NUM(index);
}
//objString.iteratorValue(_):返回迭代器对应的value
static bool primStringIteratorValue(VM* vm, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
uint32_t index = validateIndex(vm, args[1], objString->value.length);
if (index == UINT32_MAX) {
return false;
}
RET_VALUE(stringCodePointAt(vm, objString, index));
}
//objString.startsWith(_): 返回args[0]是否以args[1]为起始
static bool primStringStartsWith(VM* vm UNUSED, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
ObjString* objString = VALUE_TO_OBJSTR(args[0]);
ObjString* pattern = VALUE_TO_OBJSTR(args[1]);
//若pattern比源串还长,源串必然不包括pattern,
//因此不可能以pattern为起始
if (pattern->value.length > objString->value.length) {
RET_FALSE;
}
RET_BOOL(memcmp(objString->value.start,
pattern->value.start, pattern->value.length) == 0);
}
//objString.toString:获得自己的字符串
static bool primStringToString(VM* vm UNUSED, Value* args) {
RET_VALUE(args[0]);
}
primStringIterate:迭代ObjString的UTF-8流的字符,返回字节索引,返回False表示迭代完毕
primStringIterateByte: 迭代ObjString的UTF-8流的字节,返回字节索引,返回False表示迭代完毕
primStringIteratorValue:
//字符串类
vm->stringClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "String"));
PRIM_METHOD_BIND(vm->stringClass->objHeader.class, "fromCodePoint(_)", primStringFromCodePoint);
PRIM_METHOD_BIND(vm->stringClass, "+(_)", primStringPlus);
PRIM_METHOD_BIND(vm->stringClass, "[_]", primStringSubscript);
PRIM_METHOD_BIND(vm->stringClass, "byteAt_(_)", primStringByteAt);
PRIM_METHOD_BIND(vm->stringClass, "byteCount_", primStringByteCount);
PRIM_METHOD_BIND(vm->stringClass, "codePointAt_(_)", primStringCodePointAt);
PRIM_METHOD_BIND(vm->stringClass, "contains(_)", primStringContains);
PRIM_METHOD_BIND(vm->stringClass, "endsWith(_)", primStringEndsWith);
PRIM_METHOD_BIND(vm->stringClass, "indexOf(_)", primStringIndexOf);
PRIM_METHOD_BIND(vm->stringClass, "iterate(_)", primStringIterate);
PRIM_METHOD_BIND(vm->stringClass, "iterateByte_(_)", primStringIterateByte);
PRIM_METHOD_BIND(vm->stringClass, "iteratorValue(_)", primStringIteratorValue);
PRIM_METHOD_BIND(vm->stringClass, "startsWith(_)", primStringStartsWith);
PRIM_METHOD_BIND(vm->stringClass, "toString", primStringToString);
PRIM_METHOD_BIND(vm->stringClass, "count", primStringByteCount);
7 List类及其方法
7.1 List类用法

7.2 ObjList结构
typedef struct {
ObjHeader objHeader;
ValueBuffer elements; //list中的元素
} ObjList; //list对象
ObjList* newObjList(VM* vm, uint32_t elementNum);
Value removeElement(VM* vm, ObjList* objList, uint32_t index);
void insertElement(VM* vm, ObjList* objList, uint32_t index, Value value);
#endif
//新建list对象,元素个数为elementNum
ObjList* newObjList(VM* vm, uint32_t elementNum) {
//存储list元素的缓冲区
Value* elementArray = NULL;
//先分配内存,后调用initObjHeader,避免gc无谓的遍历
if (elementNum > 0) {
elementArray = ALLOCATE_ARRAY(vm, Value, elementNum);
}
ObjList* objList = ALLOCATE(vm, ObjList);
objList->elements.datas = elementArray;
objList->elements.capacity = objList->elements.count = elementNum;
initObjHeader(vm, &objList->objHeader, OT_LIST, vm->listClass);
return objList;
}
//在objlist中索引为index处插入value, 类似于list[index] = value
void insertElement(VM* vm, ObjList* objList, uint32_t index, Value value) {
if (index > objList->elements.count - 1) {
RUN_ERROR("index out bounded!");
}
if (VALUE_IS_OBJ(value)) {
pushTmpRoot(vm, VALUE_TO_OBJ(value));
}
//准备一个Value的空间以容纳新元素产生的空间波动
//即最后一个元素要后移1个空间
ValueBufferAdd(vm, &objList->elements, VT_TO_VALUE(VT_NULL));
if (VALUE_IS_OBJ(value)) {
popTmpRoot(vm);
}
//下面使index后面的元素整体后移一位
uint32_t idx = objList->elements.count - 1;
while (idx > index) {
objList->elements.datas[idx] = objList->elements.datas[idx - 1];
idx--;
}
//在index处插入数值
objList->elements.datas[index] = value;
}
//调整list容量
static void shrinkList(VM* vm, ObjList* objList, uint32_t newCapacity) {
uint32_t oldSize = objList->elements.capacity * sizeof(Value);
uint32_t newSize = newCapacity * sizeof(Value);
memManager(vm, objList->elements.datas, oldSize, newSize);
objList->elements.capacity = newCapacity;
}
//删除list中索引为index处的元素,即删除list[index]
Value removeElement(VM* vm, ObjList* objList, uint32_t index) {
Value valueRemoved = objList->elements.datas[index];
if (VALUE_IS_OBJ(valueRemoved)) {
pushTmpRoot(vm, VALUE_TO_OBJ(valueRemoved));
}
//使index后面的元素前移一位,覆盖index处的元素
uint32_t idx = index;
while (idx < objList->elements.count) {
objList->elements.datas[idx] = objList->elements.datas[idx + 1];
idx++;
}
//若容量利用率过低就减小容量
uint32_t _capacity = objList->elements.capacity / CAPACITY_GROW_FACTOR;
if (_capacity > objList->elements.count) {
shrinkList(vm, objList, _capacity);
}
if (VALUE_IS_OBJ(valueRemoved)) {
popTmpRoot(vm);
}
objList->elements.count--;
return valueRemoved;
}
7.3 List类的原生方法
//objList.new():创建1个新的liist
static bool primListNew(VM* vm, Value* args UNUSED) {
RET_OBJ(newObjList(vm, 0));
}
//objList[_]:索引list元素
static bool primListSubscript(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
//数字和objRange都可以做索引,分别判断
//若索引是数字,就直接索引1个字符,这是最简单的subscript
if (VALUE_IS_NUM(args[1])) {
uint32_t index = validateIndex(vm, args[1], objList->elements.count);
if (index == UINT32_MAX) {
return false;
}
RET_VALUE(objList->elements.datas[index]);
}
//索引要么为数字要么为ObjRange,若不是数字就应该为objRange
if (!VALUE_IS_OBJRANGE(args[1])) {
SET_ERROR_FALSE(vm, "subscript should be integer or range!");
}
int direction;
uint32_t count = objList->elements.count;
//返回的startIndex是objRange.from在objList.elements.data中的下标
uint32_t startIndex = calculateRange(vm, VALUE_TO_OBJRANGE(args[1]), &count, &direction);
//新建一个list 存储该range在原来list中索引的元素
ObjList* result = newObjList(vm, count);
uint32_t idx = 0;
while (idx < count) {
//direction为-1表示从后往前倒序赋值
//如var l = [a,b,c,d,e,f,g]; l[5..3]表示[f,e,d]
result->elements.datas[idx] = objList->elements.datas[startIndex + idx * direction];
idx++;
}
RET_OBJ(result);
}
//objList[_]=(_):只支持数字做为subscript
static bool primListSubscriptSetter(VM* vm UNUSED, Value* args) {
//获取对象
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
//获取subscript
uint32_t index = validateIndex(vm, args[1], objList->elements.count);
if (index == UINT32_MAX) {
return false;
}
//直接赋值
objList->elements.datas[index] = args[2];
RET_VALUE(args[2]); //把参数2做为返回值
}
//objList.add(_):直接追加到list中
static bool primListAdd(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
ValueBufferAdd(vm, &objList->elements, args[1]);
RET_VALUE(args[1]); //把参数1做为返回值
}
//objList.addCore_(_):编译内部使用的,用于编译列表直接量
static bool primListAddCore(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
ValueBufferAdd(vm, &objList->elements, args[1]);
RET_VALUE(args[0]); //返回列表自身
}
//objList.clear():清空list
static bool primListClear(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
ValueBufferClear(vm, &objList->elements);
RET_NULL;
}
//objList.count:返回list中元素个数
static bool primListCount(VM* vm UNUSED, Value* args) {
RET_NUM(VALUE_TO_OBJLIST(args[0])->elements.count);
}
//objList.insert(_,_):插入元素
static bool primListInsert(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
//+1确保可以在最后插入
uint32_t index = validateIndex(vm, args[1], objList->elements.count + 1);
if (index == UINT32_MAX) {
return false;
}
insertElement(vm, objList, index, args[2]);
RET_VALUE(args[2]); //参数2做为返回值
}
//objList.iterate(_):迭代list
static bool primListIterate(VM* vm, Value* args) {
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
//如果是第一次迭代 迭代索引肯定为空 直接返回索引0
if (VALUE_IS_NULL(args[1])) {
if (objList->elements.count == 0) {
RET_FALSE;
}
RET_NUM(0);
}
//确保迭代器是整数
if (!validateInt(vm, args[1])) {
return false;
}
double iter = VALUE_TO_NUM(args[1]);
//如果迭代完了就终止
if (iter < 0 || iter >= objList->elements.count - 1) {
RET_FALSE;
}
RET_NUM(iter + 1); //返回下一个
}
//objList.iteratorValue(_):返回迭代值
static bool primListIteratorValue(VM* vm, Value* args) {
//获取实例对象
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
uint32_t index = validateIndex(vm, args[1], objList->elements.count);
if (index == UINT32_MAX) {
return false;
}
RET_VALUE(objList->elements.datas[index]);
}
//objList.removeAt(_):删除指定位置的元素
static bool primListRemoveAt(VM* vm, Value* args) {
//获取实例对象
ObjList* objList = VALUE_TO_OBJLIST(args[0]);
uint32_t index = validateIndex(vm, args[1], objList->elements.count);
if (index == UINT32_MAX) {
return false;
}
RET_VALUE(removeElement(vm, objList, index));
}
//List类
vm->listClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "List"));
PRIM_METHOD_BIND(vm->listClass->objHeader.class, "new()", primListNew);
PRIM_METHOD_BIND(vm->listClass, "[_]", primListSubscript);
PRIM_METHOD_BIND(vm->listClass, "[_]=(_)", primListSubscriptSetter);
PRIM_METHOD_BIND(vm->listClass, "add(_)", primListAdd);
PRIM_METHOD_BIND(vm->listClass, "addCore_(_)", primListAddCore);
PRIM_METHOD_BIND(vm->listClass, "clear()", primListClear);
PRIM_METHOD_BIND(vm->listClass, "count", primListCount);
PRIM_METHOD_BIND(vm->listClass, "insert(_,_)", primListInsert);
PRIM_METHOD_BIND(vm->listClass, "iterate(_)", primListIterate);
PRIM_METHOD_BIND(vm->listClass, "iteratorValue(_)", primListIteratorValue);
PRIM_METHOD_BIND(vm->listClass, "removeAt(_)", primListRemoveAt);
primListIterate对应objList.iterate(),primListIteratorValue对应objList.iteratorValue(),List和Map都属于可以被for循环迭代的序列seqence。详情可见第六篇博客第7、8小节
8. Map类及其原生方法
8.1 Map类用法举例


8.2 ObjMap结构
#define MAP_LOAD_PERCENT 0.8
typedef struct {
Value key;
Value value;
} Entry; //key->value对儿
typedef struct {
ObjHeader objHeader;
uint32_t capacity; //Entry的容量(即总数),包括已使用和未使用Entry的数量
uint32_t count; //map中使用的Entry的数量
Entry* entries; //Entry数组
} ObjMap;
ObjMap* newObjMap(VM* vm);
void mapSet(VM* vm, ObjMap* objMap, Value key, Value value);
Value mapGet(ObjMap* objMap, Value key);
void clearMap(VM* vm, ObjMap* objMap);
Value removeKey(VM* vm, ObjMap* objMap, Value key);
#endif
//创建新map对象
ObjMap* newObjMap(VM* vm) {
ObjMap* objMap = ALLOCATE(vm, ObjMap);
initObjHeader(vm, &objMap->objHeader, OT_MAP, vm->mapClass);
objMap->capacity = objMap->count = 0;
objMap->entries = NULL;
return objMap;
}
//计算数字的哈希码
static uint32_t hashNum(double num) {
Bits64 bits64;
bits64.num = num;
return bits64.bits32[0] ^ bits64.bits32[1];
}
//计算对象的哈希码
static uint32_t hashObj(ObjHeader* objHeader) {
switch (objHeader->type) {
case OT_CLASS: //计算class的哈希值
return hashString(((Class*)objHeader)->name->value.start,
((Class*)objHeader)->name->value.length);
case OT_RANGE: { //计算range对象哈希码
ObjRange* objRange = (ObjRange*)objHeader;
return hashNum(objRange->from) ^ hashNum(objRange->to);
}
case OT_STRING: //对于字符串,直接返回其hashCode
return ((ObjString*)objHeader)->hashCode;
default:
RUN_ERROR("the hashable are objstring, objrange and class.");
}
return 0;
}
//根据value的类型调用相应的哈希函数
static uint32_t hashValue(Value value) {
switch (value.type) {
case VT_FALSE:
return 0;
case VT_NULL:
return 1;
case VT_NUM:
return hashNum(value.num);
case VT_TRUE:
return 2;
case VT_OBJ:
return hashObj(value.objHeader);
default:
RUN_ERROR("unsupport type hashed!");
}
return 0;
}
//在entries中添加entry,如果是新的key则返回true
static bool addEntry(Entry* entries, uint32_t capacity, Value key, Value value) {
uint32_t index = hashValue(key) % capacity;
//通过开放探测法去找可用的slot
while (true) {
//找到空闲的slot,说明目前没有此key,直接赋值返回
if (entries[index].key.type == VT_UNDEFINED) {
entries[index].key = key;
entries[index].value = value;
return true; //新的key就返回true
} else if (valueIsEqual(entries[index].key, key)) { //key已经存在,仅仅更新值就行
entries[index].value = value;
return false; // 未增加新的key就返回false
}
//开放探测定址,尝试下一个slot
index = (index + 1) % capacity;
}
}
//使对象objMap的容量调整到newCapacity
static void resizeMap(VM* vm, ObjMap* objMap, uint32_t newCapacity) {
// 1 先建立个新的entry数组
Entry* newEntries = ALLOCATE_ARRAY(vm, Entry, newCapacity);
uint32_t idx = 0;
while (idx < newCapacity) {
newEntries[idx].key = VT_TO_VALUE(VT_UNDEFINED);
newEntries[idx].value = VT_TO_VALUE(VT_FALSE);
idx++;
}
// 2 再遍历老的数组,把有值的部分插入到新数组
if (objMap->capacity > 0) {
Entry* entryArr = objMap->entries;
idx = 0;
while (idx < objMap->capacity) {
//该slot有值
if (entryArr[idx].key.type != VT_UNDEFINED) {
addEntry(newEntries, newCapacity,
entryArr[idx].key, entryArr[idx].value);
}
idx++;
}
}
// 3 将老entry数组空间回收
DEALLOCATE_ARRAY(vm, objMap->entries, objMap->count);
objMap->entries = newEntries; //更新指针为新的entry数组
objMap->capacity = newCapacity; //更新容量
}
//在objMap中查找key对应的entry
static Entry* findEntry(ObjMap* objMap, Value key) {
//objMap为空则返回null
if (objMap->capacity == 0) {
return NULL;
}
//以下开放定址探测
//用哈希值对容量取模计算槽位(slot)
uint32_t index = hashValue(key) % objMap->capacity;
Entry* entry;
while (true) {
entry = &objMap->entries[index];
//若该slot中的entry正好是该key的entry,找到返回
if (valueIsEqual(entry->key, key)) {
return entry;
}
//key为VT_UNDEFINED且value为VT_TRUE表示探测链未断,可继续探测.
//key为VT_UNDEFINED且value为VT_FALSE表示探测链结束,探测结束.
if (VALUE_IS_UNDEFINED(entry->key) && VALUE_IS_FALSE(entry->value)) {
return NULL; //未找到
}
//继续向下探测
index = (index + 1) % objMap->capacity;
}
}
//在objMap中实现key与value的关联:objMap[key]=value
void mapSet(VM* vm, ObjMap* objMap, Value key, Value value) {
//当容量利用率达到80%时扩容
if (objMap->count + 1 > objMap->capacity * MAP_LOAD_PERCENT) {
uint32_t newCapacity = objMap->capacity * CAPACITY_GROW_FACTOR;
if (newCapacity < MIN_CAPACITY) {
newCapacity = MIN_CAPACITY;
}
resizeMap(vm, objMap, newCapacity);
}
//若创建了新的key则使objMap->count加1
if (addEntry(objMap->entries, objMap->capacity, key, value)) {
objMap->count++;
}
}
//从map中查找key对应的value: map[key]
Value mapGet(ObjMap* objMap, Value key) {
Entry* entry = findEntry(objMap, key);
if (entry == NULL) {
return VT_TO_VALUE(VT_UNDEFINED);
}
return entry->value;
}
//回收objMap.entries占用的空间
void clearMap(VM* vm, ObjMap* objMap) {
DEALLOCATE_ARRAY(vm, objMap->entries, objMap->count);
objMap->entries = NULL;
objMap->capacity = objMap->count = 0;
}
//删除objMap中的key,返回map[key]
Value removeKey(VM* vm, ObjMap* objMap, Value key) {
Entry* entry = findEntry(objMap, key);
if (entry == NULL) {
return VT_TO_VALUE(VT_NULL);
}
//设置开放定址的伪删除
Value value = entry->value;
entry->key = VT_TO_VALUE(VT_UNDEFINED);
entry->value = VT_TO_VALUE(VT_TRUE); //值为真,伪删除
if (VALUE_IS_OBJ(value)) {
pushTmpRoot(vm, VALUE_TO_OBJ(value));
}
objMap->count--;
if (objMap->count == 0) { //若删除该entry后map为空就回收该空间
clearMap(vm, objMap);
} else if (objMap->count < objMap->capacity / (CAPACITY_GROW_FACTOR) * MAP_LOAD_PERCENT &&
objMap->count > MIN_CAPACITY) { //若map容量利用率太低,就缩小map空间
uint32_t newCapacity = objMap->capacity / CAPACITY_GROW_FACTOR;
if (newCapacity < MIN_CAPACITY) {
newCapacity = MIN_CAPACITY;
}
resizeMap(vm, objMap, newCapacity);
}
if (VALUE_IS_OBJ(value)) {
popTmpRoot(vm);
}
return value;
}
8.3 Map类的原生方法
//校验key合法性
static bool validateKey(VM* vm, Value arg) {
if (VALUE_IS_TRUE(arg) ||
VALUE_IS_FALSE(arg) ||
VALUE_IS_NULL(arg) ||
VALUE_IS_NUM(arg) ||
VALUE_IS_OBJSTR(arg) ||
VALUE_IS_OBJRANGE(arg) ||
VALUE_IS_CLASS(arg)) {
return true;
}
SET_ERROR_FALSE(vm, "key must be value type!");
}
//objMap.new():创建map对象
static bool primMapNew(VM* vm, Value* args UNUSED) {
RET_OBJ(newObjMap(vm));
}
//objMap[_]:返回map[key]对应的value
static bool primMapSubscript(VM* vm, Value* args) {
//校验key的合法性
if (!validateKey(vm, args[1])) {
return false; //出错了,切换线程
}
//获得map对象实例
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
//从map中查找key(args[1])对应的value
Value value = mapGet(objMap, args[1]);
//若没有相应的key则返回NULL
if (VALUE_IS_UNDEFINED(value)) {
RET_NULL;
}
RET_VALUE(value);
}
//objMap[_]=(_):map[key]=value
static bool primMapSubscriptSetter(VM* vm, Value* args) {
//校验key的合法性
if (!validateKey(vm, args[1])) {
return false; //出错了,切换线程
}
//获得map对象实例
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
//在map中将key和value关联
//即map[key]=value
mapSet(vm, objMap, args[1], args[2]);
RET_VALUE(args[2]); //返回value
}
//objMap.addCore_(_,_):编译器编译map字面量时内部使用的,
//在map中添加(key-value)对儿并返回map自身
static bool primMapAddCore(VM* vm, Value* args) {
if (!validateKey(vm, args[1])) {
return false; //出错了,切换线程
}
//获得map对象实例
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
//在map中将key和value关联
//即map[key]=value
mapSet(vm, objMap, args[1], args[2]);
RET_VALUE(args[0]); //返回map对象自身
}
//objMap.clear():清除map
static bool primMapClear(VM* vm, Value* args) {
clearMap(vm, VALUE_TO_OBJMAP(args[0]));
RET_NULL;
}
//objMap.containsKey(_):判断map即args[0]是否包含key即args[1]
static bool primMapContainsKey(VM* vm, Value* args) {
if (!validateKey(vm, args[1])) {
return false; //出错了,切换线程
}
//直接去get该key,判断是否get成功
RET_BOOL(!VALUE_IS_UNDEFINED(mapGet(VALUE_TO_OBJMAP(args[0]), args[1])));
}
//objMap.count:返回map中entry个数
static bool primMapCount(VM* vm UNUSED, Value* args) {
RET_NUM(VALUE_TO_OBJMAP(args[0])->count);
}
//objMap.remove(_):删除map[key] map是args[0] key是args[1]
static bool primMapRemove(VM* vm, Value* args) {
if (!validateKey(vm, args[1])) {
return false; //出错了,切换线程
}
RET_VALUE(removeKey(vm, VALUE_TO_OBJMAP(args[0]), args[1]));
}
//objMap.iterate_(_):迭代map中的entry,
//返回entry的索引供keyIteratorValue_和valueIteratorValue_做迭代器
static bool primMapIterate(VM* vm, Value* args) {
//获得map对象实例
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
//map中若空则返回false不可迭代
if (objMap->count == 0) {
RET_FALSE;
}
//若没有传入迭代器,迭代默认是从第0个entry开始
uint32_t index = 0;
//若不是第一次迭代,传进了迭代器
if (!VALUE_IS_NULL(args[1])) {
//iter必须为整数
if (!validateInt(vm, args[1])) {
//本线程出错了,返回false是为了切换到下一线
return false;
}
//迭代器不能小0
if (VALUE_TO_NUM(args[1]) < 0) {
RET_FALSE;
}
index = (uint32_t)VALUE_TO_NUM(args[1]);
//迭代器不能越界
if (index >= objMap->capacity) {
RET_FALSE;
}
index++; //更新迭代器
}
//返回下一个正在使用(有效)的entry
while (index < objMap->capacity) {
//entries是个数组, 元素是哈希槽,
//哈希值散布在这些槽中并不连续,因此逐个判断槽位是否在用
if (!VALUE_IS_UNDEFINED(objMap->entries[index].key)) {
RET_NUM(index); //返回entry索引
}
index++;
}
//若没有有效的entry了就返回false,迭代结束
RET_FALSE;
}
//objMap.keyIteratorValue_(_): key=map.keyIteratorValue(iter)
static bool primMapKeyIteratorValue(VM* vm, Value* args) {
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
uint32_t index = validateIndex(vm, args[1], objMap->capacity);
if (index == UINT32_MAX) {
return false;
}
Entry* entry = &objMap->entries[index];
if (VALUE_IS_UNDEFINED(entry->key)) {
SET_ERROR_FALSE(vm, "invalid iterator!");
}
//返回该key
RET_VALUE(entry->key);
}
//objMap.valueIteratorValue_(_):
//value = map.valueIteratorValue_(iter)
static bool primMapValueIteratorValue(VM* vm, Value* args) {
ObjMap* objMap = VALUE_TO_OBJMAP(args[0]);
uint32_t index = validateIndex(vm, args[1], objMap->capacity);
if (index == UINT32_MAX) {
return false;
}
Entry* entry = &objMap->entries[index];
if (VALUE_IS_UNDEFINED(entry->key)) {
SET_ERROR_FALSE(vm, "invalid iterator!");
}
//返回该key
RET_VALUE(entry->value);
}
//map类
vm->mapClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Map"));
PRIM_METHOD_BIND(vm->mapClass->objHeader.class, "new()", primMapNew);
PRIM_METHOD_BIND(vm->mapClass, "[_]", primMapSubscript);
PRIM_METHOD_BIND(vm->mapClass, "[_]=(_)", primMapSubscriptSetter);
PRIM_METHOD_BIND(vm->mapClass, "addCore_(_,_)", primMapAddCore);
PRIM_METHOD_BIND(vm->mapClass, "clear()", primMapClear);
PRIM_METHOD_BIND(vm->mapClass, "containsKey(_)", primMapContainsKey);
PRIM_METHOD_BIND(vm->mapClass, "count", primMapCount);
PRIM_METHOD_BIND(vm->mapClass, "remove(_)", primMapRemove);
PRIM_METHOD_BIND(vm->mapClass, "iterate_(_)", primMapIterate);
PRIM_METHOD_BIND(vm->mapClass, "keyIteratorValue_(_)", primMapKeyIteratorValue);
PRIM_METHOD_BIND(vm->mapClass, "valueIteratorValue_(_)", primMapValueIteratorValue);
这里大家看到了我们所支持的 key包括true false null num objString objRange Class
9 Range类及其原生方法
9.1 Range类用法举例


9.2 Range类的原生方法
typedef struct {
ObjHeader objHeader;
int from; //范围的起始
int to; //范围的结束
} ObjRange; //range对象
ObjRange* newObjRange(VM* vm, int from, int to);
#endif
//新建range对象
ObjRange* newObjRange(VM* vm, int from, int to) {
ObjRange* objRange = ALLOCATE(vm, ObjRange);
initObjHeader(vm, &objRange->objHeader, OT_RANGE, vm->rangeClass);
objRange->from = from;
objRange->to = to;
return objRange;
}
//objRange.from: 返回range的from
static bool primRangeFrom(VM* vm UNUSED, Value* args) {
RET_NUM(VALUE_TO_OBJRANGE(args[0])->from);
}
//objRange.to: 返回range的to
static bool primRangeTo(VM* vm UNUSED, Value* args) {
RET_NUM(VALUE_TO_OBJRANGE(args[0])->to);
}
//objRange.min: 返回range中from和to较小的值
static bool primRangeMin(VM* vm UNUSED, Value* args) {
ObjRange* objRange = VALUE_TO_OBJRANGE(args[0]);
RET_NUM(fmin(objRange->from, objRange->to));
}
//objRange.max: 返回range中from和to较大的值
static bool primRangeMax(VM* vm UNUSED, Value* args) {
ObjRange* objRange = VALUE_TO_OBJRANGE(args[0]);
RET_NUM(fmax(objRange->from, objRange->to));
}
//objRange.iterate(_): 迭代range中的值,并不索引
static bool primRangeIterate(VM* vm, Value* args) {
ObjRange* objRange = VALUE_TO_OBJRANGE(args[0]);
//若未提供iter说明是第一次迭代,因此返回range->from
if (VALUE_IS_NULL(args[1])) {
RET_NUM(objRange->from);
}
//迭代器必须是数字
if (!validateNum(vm, args[1])) {
return false;
}
//获得迭代器
double iter = VALUE_TO_NUM(args[1]);
//若是正方向
if (objRange->from < objRange->to) {
iter++;
if (iter > objRange->to) {
RET_FALSE;
}
} else { //若是反向迭代
iter--;
if (iter < objRange->to) {
RET_FALSE;
}
}
RET_NUM(iter);
}
//objRange.iteratorValue(_): range的迭代就是range中从from到to之间的值
//因此直接返回迭代器就是range的值
static bool primRangeIteratorValue(VM* vm UNUSED, Value* args) {
ObjRange* objRange = VALUE_TO_OBJRANGE(args[0]);
double value = VALUE_TO_NUM(args[1]);
//确保args[1]在from和to的范围中
//若是正方向
if (objRange->from < objRange->to) {
if (value >= objRange->from && value <= objRange->to) {
RET_VALUE(args[1]);
}
} else { //若是反向迭代
if (value <= objRange->from && value >= objRange->to) {
RET_VALUE(args[1]);
}
}
RET_FALSE;
}
//range类
vm->rangeClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "Range"));
PRIM_METHOD_BIND(vm->rangeClass, "from", primRangeFrom);
PRIM_METHOD_BIND(vm->rangeClass, "to", primRangeTo);
PRIM_METHOD_BIND(vm->rangeClass, "min", primRangeMin);
PRIM_METHOD_BIND(vm->rangeClass, "max", primRangeMax);
PRIM_METHOD_BIND(vm->rangeClass, "iterate(_)", primRangeIterate);
PRIM_METHOD_BIND(vm->rangeClass, "iteratorValue(_)", primRangeIteratorValue);
10 System类及其原生方法
10.1 System类用法举例

10.2 System类的原生方法
//获取文件全路径
static char* getFilePath(const char* moduleName) {
uint32_t rootDirLength = rootDir == NULL ? 0 : strlen(rootDir);
uint32_t nameLength = strlen(moduleName);
uint32_t pathLength = rootDirLength + nameLength + strlen(".sp");
char* path = (char*)malloc(pathLength + 1);
if (rootDir != NULL) {
memmove(path, rootDir, rootDirLength);
}
memmove(path + rootDirLength, moduleName, nameLength);
memmove(path + rootDirLength + nameLength, ".sp", 3);
path[pathLength] = '\0';
return path;
}
//读取模块
static char* readModule(const char* moduleName) {
//1 读取内建模块 先放着
//2 读取自定义模块
char* modulePath = getFilePath(moduleName);
char* moduleCode = readFile(modulePath);
free(modulePath);
return moduleCode; //由主调函数将来free此空间
}
//输出字符串
static void printString(const char* str) {
//输出到缓冲区后立即刷新
printf("%s", str);
fflush(stdout);
}
//导入模块moduleName,主要是把编译模块并加载到vm->allModules
static Value importModule(VM* vm, Value moduleName) {
//若已经导入则返回NULL_VAL
if (!VALUE_IS_UNDEFINED(mapGet(vm->allModules, moduleName))) {
return VT_TO_VALUE(VT_NULL);
}
ObjString* objString = VALUE_TO_OBJSTR(moduleName);
const char* sourceCode = readModule(objString->value.start);
ObjThread* moduleThread = loadModule(vm, moduleName, sourceCode);
return OBJ_TO_VALUE(moduleThread);
}
//在模块moduleName中获取模块变量variableName
static Value getModuleVariable(VM* vm, Value moduleName, Value variableName) {
//调用本函数前模块已经被加载了
ObjModule* objModule = getModule(vm, moduleName);
if (objModule == NULL) {
ObjString* modName = VALUE_TO_OBJSTR(moduleName);
//24是下面sprintf中fmt中除%s的字符个数
ASSERT(modName->value.length < 512 - 24, "id`s buffer not big enough!");
char id[512] = {'\0'};
int len = sprintf(id, "module \'%s\' is not loaded!", modName->value.start);
vm->curThread->errorObj = OBJ_TO_VALUE(newObjString(vm, id, len));
return VT_TO_VALUE(VT_NULL);
}
ObjString* varName = VALUE_TO_OBJSTR(variableName);
//从moduleVarName中获得待导入的模块变量
int index = getIndexFromSymbolTable(&objModule->moduleVarName,
varName->value.start, varName->value.length);
if (index == -1) {
//32是下面sprintf中fmt中除%s的字符个数
ASSERT(varName->value.length < 512 - 32, "id`s buffer not big enough!");
ObjString* modName = VALUE_TO_OBJSTR(moduleName);
char id[512] = {'\0'};
int len = sprintf(id, "variable \'%s\' is not in module \'%s\'!",
varName->value.start, modName->value.start);
vm->curThread->errorObj = OBJ_TO_VALUE(newObjString(vm, id, len));
return VT_TO_VALUE(VT_NULL);
}
//直接返回对应的模块变量
return objModule->moduleVarValue.datas[index];
}
//System.clock: 返回以秒为单位的系统时钟
static bool primSystemClock(VM* vm UNUSED, Value* args UNUSED) {
RET_NUM((double)time(NULL));
}
//System.gc(): 启动gc
static bool primSystemGC(VM* vm, Value* args) {
startGC(vm);
RET_NULL;
}
//System.importModule(_): 导入并编译模块args[1],把模块挂载到vm->allModules
static bool primSystemImportModule(VM* vm, Value* args) {
if (!validateString(vm, args[1])) { //模块名为字符串
return false;
}
//导入模块name并编译 把模块挂载到vm->allModules
Value result = importModule(vm, args[1]);
//若已经导入过则返回NULL_VAL
if (VALUE_IS_NULL(result)) {
RET_NULL;
}
//若编译过程中出了问题,切换到下一线程
if (!VALUE_IS_NULL(vm->curThread->errorObj)) {
return false;
}
//回收1个slot空间
vm->curThread->esp--;
ObjThread* nextThread = VALUE_TO_OBJTHREAD(result);
nextThread->caller = vm->curThread;
vm->curThread = nextThread;
//返回false,vm会切换到此新加载模块的线程
return false;
}
//System.getModuleVariable(_,_): 获取模块args[1]中的模块变量args[2]
static bool primSystemGetModuleVariable(VM* vm, Value* args) {
if (!validateString(vm, args[1])) {
return false;
}
if (!validateString(vm, args[2])) {
return false;
}
Value result = getModuleVariable(vm, args[1], args[2]);
if (VALUE_IS_NULL(result)) {
//出错了,给vm返回false以切换线程
return false;
}
RET_VALUE(result);
}
//System.writeString_(_): 输出字符串args[1]
static bool primSystemWriteString(VM* vm UNUSED, Value* args) {
ObjString* objString = VALUE_TO_OBJSTR(args[1]);
ASSERT(objString->value.start[objString->value.length] == '\0', "string isn`t terminated!");
printString(objString->value.start);
RET_VALUE(args[1]);
}
//system类
Class* systemClass = VALUE_TO_CLASS(getCoreClassValue(coreModule, "System"));
PRIM_METHOD_BIND(systemClass->objHeader.class, "clock", primSystemClock);
PRIM_METHOD_BIND(systemClass->objHeader.class, "gc()", primSystemGC);
PRIM_METHOD_BIND(systemClass->objHeader.class, "importModule(_)", primSystemImportModule);
PRIM_METHOD_BIND(systemClass->objHeader.class, "getModuleVariable(_,_)", primSystemGetModuleVariable);
PRIM_METHOD_BIND(systemClass->objHeader.class, "writeString_(_)", primSystemWriteString);
每次import导入模块,会先调用importModule加载模块于vm->allModules并编译,编译生成的指令保存在新创建的线程的第一个框架的闭包中,然后将该线程保存在vn->curThread中return false切换该线程并调用executeInstruction执行该线程的指令