背景:
产品有个通过正则表达式验证用户输入电话号码是否合法的功能(没有约束输入号码的长度),研发人员写的正在表达式(java代码):regexp="^[+]?(\\d+)((-?|\\s?)\\d+)*$",被别人测出来存在正则表达式回溯的漏洞,即输入很长一段字符,触发正则回溯后,导致CPU占用达到200%。搜了下相关资料,梳理下这个漏洞的发生原因如下。
1. 正则表达式引擎
说起回溯陷阱,要先从正则表达式的引擎说起。正则引擎主要可以分为基本不同的两大类:一种是DFA(确定型有穷自动机),另一种是NFA(不确定型有穷自动机)。简单来讲,NFA 对应的是正则表达式主导的匹配,而 DFA 对应的是文本主导的匹配。
DFA从匹配文本入手,从左到右,每个字符不会匹配两次,它的时间复杂度是多项式的,所以通常情况下,它的速度更快,但支持的特性很少,不支持捕获组、各种引用等等;而NFA则是从正则表达式入手,不断读入字符,尝试是否匹配当前正则,不匹配则吐出字符重新尝试,通常它的速度比较慢,最优时间复杂度为多项式的,最差情况为指数级的。但NFA支持更多的特性,因而绝大多数编程场景下(包括java,js),我们面对的是NFA。以下面的表达式和文本为例,
- text = ‘after tonight’ regex = ‘to(nite|nighta|night)’
在NFA匹配时候,是根据正则表达式来匹配文本的,从t开始匹配a,失败,继续,直到文本里面的第一个t,接着比较o和e,失败,正则回退到 t,继续,直到文本里面的第二个t,然后 o和文本里面的o也匹配,继续,正则表达式后面有三个可选条件,依次匹配,第一个失败,接着二、三,直到匹配。
而在DFA匹配时候,采用的是用文本来匹配正则表达式的方式,从a开始匹配t,直到第一个t跟正则的t匹配,但e跟o匹配失败,继续,直到文本里面的第二个 t 匹配正则的t,接着o与o匹配,n的时候发现正则里面有三个可选匹配,开始并行匹配,直到文本中的g使得第一个可选条件不匹配,继续,直到最后匹配。
可以看到,DFA匹配过程中文本中的字符每一个只比较了一次,没有吐出的操作,应该是快于NFA的。另外,不管正则表达式怎么写,对于DFA而言,文本的匹配过程是一致的,都是对文本的字符依次从左到右进行匹配,所以,DFA在匹配过程中是跟正则表达式无关的,而 NFA 对于不同但效果相同的正则表达式,匹配过程是完全不同的。
2. 回溯
说完了引擎,我们来看看什么是回溯。先来看个例子:
Round 1
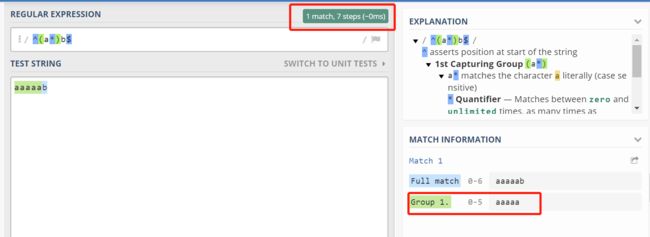
假设有正则表达式 /^(a*)b$/ 和字符串 aaaaab。如果用该正则匹配这个字符串会得到什么呢?
答案很简单。两者匹配,且捕获组捕获到字符串 aaaaa。
Round 2
这次让我们把正则改写成 /^(a*)ab$/。再次和字符串 aaaaab 匹配。结果如何呢?
两者依然匹配,但捕获组捕获到字符串 aaaa。因为捕获组后续的表达式占用了 1 个 a 字符。但是你有没有考虑过这个看似简单结果是经过何种过程得到的呢?
让我们一步一步来看:
- 匹配开始
(a*)捕获尽可能多的字符a。 (a*)一直捕获,直到遇到字符b。这时(a*)已经捕获了aaaaa。- 正则表达式继续执行
(a*)之后的ab匹配。但此时由于字符串仅剩一个b字符。导致无法完成匹配。 (a*)从已捕获的字符串中“吐”出一个字符a。这时捕获结果为aaaa,剩余字符串为ab。- 重新执行正则中
ab的匹配。发现正好与剩余字符串匹配。整个匹配过程结束。返回捕获结果aaaa。
从第3,4步可以看到,暂时的无法匹配并不会立即导致整体匹配失败。而是会从捕获组中“吐出”字符以尝试。这个“吐出”的过程就叫回溯。
回溯并不仅执行一次,而是会一直回溯到另一个极端。对于 * 符号而言,就是匹配 0 次的情况。
Round 3
这次我们把正则改为 /^(a*)aaaab$/。字符串依然为 aaaaab。根据前边的介绍很容易直到。此次要回溯 4 次才可以完成匹配。具体执行过程不再赘述。
悲观回溯
了解了回溯的工作原理,再来看悲观回溯就很容易理解了。
Round 4
这次我们的正则改为 /^(a*)b$/。但是把要匹配的字符串改为 aaaaa。去掉了结尾的字符 b。
让我们看看此时的执行流程:
(a*)首先匹配了所有aaaaa。- 尝试匹配
b。但是匹配失败。 - 回溯 1 个字符。此时剩余字符串为
a。依然无法匹配字符b。 - 回溯一直进行。直到匹配 0 次的情况。此时剩余字符串为
aaaaa。依然无法匹配b。 - 所有的可能性均已尝试过,依然无法匹配。最终导致整体匹配失败。
可以看到,虽然我们可以一眼看出二者无法匹配。但正则表达式在执行时还要“傻傻的”逐一回溯所有可能性,才能确定最终结果。这个“傻傻的”回溯过程就叫悲观回溯。
3. 贪婪、懒惰与独占
我们再来看一下究竟什么是贪婪模式。
下面的几个特殊字符相信大家都知道它们的用法:
i. ?: 告诉引擎匹配前导字符0次或一次。事实上是表示前导字符是可选的。
ii. +: 告诉引擎匹配前导字符1次或多次。
iii. *: 告诉引擎匹配前导字符0次或多次。
iv. {min, max}: 告诉引擎匹配前导字符min次到max次。min和max都是非负整数。如果有逗号而max被省略了,则表示max没有限制;如果逗号和max都被省略了,则表示重复min次。
默认情况下,这个几个特殊字符都是贪婪的,也就是说,它会根据前导字符去匹配尽可能多的内容。这也就解释了为什么在第3部分的例子中,第3步以后的事情会发生了。
在以上字符后加上一个问号(?)则可以开启懒惰模式,在该模式下,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串。在上例中,如果将正则换为
- ab{1,3}?c
则匹配过程变成了下面这样(橙色为匹配,黄色为不匹配),

由此可见,在非贪婪模式下,第2步正则中的b{1,3}?与文本b匹配之后,接着去用c与文本中的c进行匹配,而未发生回溯。
如果在以上四种表达式后加上一个加号(+),则会开启独占模式。同贪婪模式一样,独占模式一样会匹配最长。不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。我们以下面的表达式为例,
- ab{1,3}+bc
如果我们用文本"abbc"去匹配上面的表达式,匹配的过程如下图所示(橙色为匹配,黄色为不匹配),

可以发现,在第2和第3步,b{1,3}+会将文本中的2个字母b都匹配上,结果文本中只剩下一个字母c。那么在第4步时,正则中的b和文本中的c进行匹配,当无法匹配时,并不进行回溯,这时候整个文本就无法和正则表达式发生匹配。如果将正则表达式中的加号(+)去掉,那么这个文本整体就是匹配的了。
把以上三种模式的表达式列出如下,
| 贪婪 |
懒惰 |
独占 |
| X? |
X?? |
X?+ |
| X* |
X*? |
X*+ |
| X+ |
X+? |
X++ |
| X{n} |
X{n}? |
X{n}+ |
| X{n,} |
X{n,}? |
X{n,}+ |
| X{n,m} |
X{n,m}? |
X{n,m}+ |
4. 总结
现在再回过头看看研发人员写的那个电话号码的正则表达式
- regexp="^[+]?(\\d+)((-?|\\s?)\\d+)*$"
如果这里我们输入很长的一串字符“123123123123123123123……………………89a”,先匹配^[+]与第一个数字1,没有匹配到,在匹配(\d+)与第一个数字1,因为贪婪匹配,一直要匹配到最后的字母a,\d+不在匹配上。
第一次回溯:
这时候就要把这时候把a前面的数字“9”吐出来,前面的所有数字“123123123123123123123……………………8”匹配了正则表达式的前半部分"^[+]?(\\d+)”,剩下的就是“9a”与“((-?|\\s?)\\d+)”进行匹配,“9”可以与后面的“\d+”匹配,剩下"a"又没有匹配。
第二次回溯:
把8也吐出来,同样前面的所有数字“123123123123123123123……………………”匹配了正则表达式的前半部分"^[+]?(\\d+)”,剩下的就是"89a"与正则表达式的后半部分就行匹配,“\d+”贪婪匹配,匹配到“89”,剩余“a”,没有匹配到。这时候需要注意啦,后半部分的正则也要进行回溯啦。也就是“89”要做一次回溯,“8”与“((-?|\\s?)\\d+)”的“\d+”匹配,剩余"9a"没法匹配,所以其实第二次回溯进行了2次。
以此类推,
第三次回溯:
实际回溯了3次
以此类推……
一共回溯了(1+N)*N/2,当N=500的时候,一共回溯了12万5千多次。所以一旦发生回溯,计算量将是巨大的,所以导致CUP占用超过200%。
因此,在自己写正则表达式的时候,一定不能大意,在实现功能的情况下,还要仔细考虑是否会带来性能隐患。