【UCAS自然语言处理作业二】训练FFN, RNN, Attention机制的语言模型,并计算测试集上的PPL
文章目录
- 前言
- 前馈神经网络
-
- 数据组织
- Dataset
- 网络结构
- 训练
- 超参设置
- RNN
-
- 数据组织&Dataset
- 网络结构
- 训练
- 超参设置
- 注意力网络
-
- 数据组织&Dataset
- 网络结构
-
- Attention部分
- 完整模型
- 训练部分
- 超参设置
- 结果与分析
-
- 训练集Loss
- 测试集PPL
前言
本次实验主要针对前馈神经网络,RNN,以及基于注意力机制的网络学习语言建模任务,并在测试集上计算不同语言模型的PPL
- PPL计算:我们采用
teacher forcing的方式,给定ground truth context,让其预测next token,并将这些token的log probability进行平均,作为文本的PPL。 CrossEntropyLoss:可以等价于PPL的计算,因此,我们将交叉熵损失作为ppl,具体原理可参考本人博客:如何计算文本的困惑度perplexity(ppl)_ppl计算_长命百岁️的博客-CSDN博客- 我们将数据分为训练集和测试集(后1000条)
- 分词采用
bart-base-chinese使用的tokenizer,词表大小为21128。当然,也可以利用其他分词工具构建词表 - 本文仅对重要的实验代码进行说明
前馈神经网络
数据组织
我们利用前馈神经网络,训练一个2-gram语言模型,即每次利用两个token来预测下一个token
def get_n_gram_data(self, data, n):
res_data = []
res_label = []
if len(data) < n:
raise VallueError("too short")
start_idx = 0
while start_idx + n <= len(data):
res_data.append(data[start_idx: start_idx + n - 1])
res_label.append(data[start_idx + n - 1])
start_idx += 1
return res_data, res_label
- 该函数的输入是一个分词后的
token_ids列表,输出是将这个ids分成不同的data, label对
def get_data(path, n):
res_data = []
res_label = []
tokenizer = BertTokenizer.from_pretrained('/users/nishiyu/ict/Models/bart-base-chinese')
with open(path) as file:
data = file.readlines()
for sample in data:
sample_data, sample_label = get_n_gram_data(tokenizer(sample, return_tensors='pt')['input_ids'][0], n)
for idx in range(len(sample_data)):
res_data.append(sample_data[idx])
res_label.append(sample_label[idx])
return res_data, res_label
- 该函数对数据集中的每条数据进行分词,并得到对应的
data, label对 - 值得注意的是,这样所有的输入/输出都是等长的,因此可以直接组装成batch
Dataset
class NGramDataset(Dataset):
def __init__(self, data_path, window_size=3):
self.data, self.label = get_data(data_path, window_size)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i], self.label[i]
- 通过
window_size来指定n-gram - 每次访问返回
data,label
网络结构
class FeedForwardNNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, window_size, hidden_dim):
super(FeedForwardNNLM, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.e2h = nn.Linear((window_size - 1) * embedding_dim, hidden_dim)
self.h2o = nn.Linear(hidden_dim, vocab_size)
self.activate = F.relu
def forward(self, inputs):
embeds = self.embeddings(inputs).reshape([inputs.shape[0], -1])
hidden = self.activate(self.e2h(embeds))
output = self.h2o(hidden)
return output
- 网络流程:
embedding层->全连接层->激活函数->线性层词表映射
训练
class Trainer():
def __init__(self, args, embedding_dim, hidden_dim):
self.args = args
self.model = FeedForwardNNLM(self.args.vocab_size, embedding_dim, args.window_size, hidden_dim)
self.train_dataset = NGramDataset(self.args.train_data, self.args.window_size)
self.train_dataloader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True)
self.test_dataset = NGramDataset(self.args.test_data, self.args.window_size)
self.test_dataloader = DataLoader(self.test_dataset, batch_size=args.batch_size, shuffle=False)
def train(self):
self.model.train()
device = torch.device('cuda')
self.model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(self.model.parameters(), lr=5e-5)
for epoch in range(args.epoch):
total_loss = 0.0
for step, batch in enumerate(self.train_dataloader):
input_ids = batch[0].to(device)
label_ids = batch[1].to(device)
logits = self.model(input_ids)
loss = criterion(logits, label_ids)
loss.backward()
optimizer.step()
self.model.zero_grad()
total_loss += loss
print(f'epoch: {epoch}, train loss: {total_loss / len(self.train_dataloader)}')
self.evaluation()
- 首先调用
dataset和dataloader对数据进行组织 - 然后利用
CrossEntropyLoss,Adam优化器(lr=5e-5)进行训练 - 评估测试集效果
超参设置
def get_args():
parser = argparse.ArgumentParser()
# 添加命令行参数
parser.add_argument('--vocab_size', type=int, default=21128)
parser.add_argument('--train_data', type=str)
parser.add_argument('--test_data', type=str)
parser.add_argument('--window_size', type=int)
parser.add_argument('--epoch', type=int, default=50)
parser.add_argument('--batch_size', type=int, default=4096)
args = parser.parse_args()
return args
embedding_dim=128hidden_dim=256epoch= 150
RNN
数据组织&Dataset
RNN的数据组织比较简单,就是每一行作为一个输入就可以,不详细展开
网络结构
class RNNLanguageModel(nn.Module):
def __init__(self, args, embedding_dim, hidden_dim):
super(RNNLanguageModel, self).__init__()
self.args = args
self.embeddings = nn.Embedding(self.args.vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
self.linear = nn.Linear(hidden_dim, self.args.vocab_size)
def forward(self, inputs):
embeds = self.embeddings(inputs)
output, hidden = self.rnn(embeds)
output = self.linear(output)
return output
- 网络流程:
embedding->rnn网络->线性层词表映射 - 这里
RNN模型直接调用API
训练
自回归模型的训练是值得注意的
class Trainer():
def __init__(self, args, embed_dim, head_dim):
self.args = args
self.tokenizer = BertTokenizer.from_pretrained('/users/nishiyu/ict/Models/bart-base-chinese')
self.model = RNNLanguageModel(args, embed_dim, head_dim)
self.train_dataset = AttenDataset(self.args.train_data)
self.train_dataloader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True)
self.test_dataset = AttenDataset(self.args.test_data)
self.test_dataloader = DataLoader(self.test_dataset, batch_size=args.batch_size, shuffle=False)
def train(self):
self.model.to(self.args.device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(self.model.parameters(), lr=5e-5)
for epoch in range(args.epoch):
self.model.train()
total_loss = 0.0
for step, batch in enumerate(self.train_dataloader):
tokens = self.tokenizer(batch, truncation=True, padding=True, max_length=self.args.max_len, return_tensors='pt').to(self.args.device)
input_ids = tokens['input_ids'][:, :-1]
label_ids = tokens['input_ids'][:, 1:].clone()
pad_token_id = self.tokenizer.pad_token_id
label_ids[label_ids == pad_token_id] = -100
logits = self.model(input_ids)
loss = criterion(logits.view(-1, self.args.vocab_size), label_ids.view(-1))
loss.backward()
optimizer.step()
self.model.zero_grad()
total_loss += loss
print(f'epoch: {epoch}, train loss: {total_loss / len(self.train_dataloader)}')
self.evaluation()
-
与FFN不同的是,我们在需要数据的时候才进行分词
-
注意到,数据集中不同数据的长度是不同的,我们想要将这些数据组织成batch,进行并行化训练,需要加padding。在训练过程中我们选择右padding
input_ids = tokens['input_ids'][:, :-1] label_ids = tokens['input_ids'][:, 1:].clone() pad_token_id = self.tokenizer.pad_token_id label_ids[label_ids == pad_token_id] = -100- 这四句是训练的核心代码,决定是否正确,从上往下分别是:
- 组织输入:因为我们要预测下一个token,因此,输入最多就进行到倒数第二个token,所以不要最后一个
- 组织label:因为我们要预测下一个token,因此作为label来说,不需要第一个token
- 组织loss:对于padding部分的token,是不需要计算loss的,因此我们将padding部分对应的label_ids设置为-100,这是因为,损失函数默认id为-100的token为pad部分,不进行loss计算
- 这四句是训练的核心代码,决定是否正确,从上往下分别是:
超参设置
embedding_dim=512hidden_dim=128epoch=30batch_size=12
注意力网络
数据组织&Dataset
与RNN完全相同,不进行介绍
网络结构
因为此网络比较重要,我之前也BART, GPT-2等模型的源码,因此我们选择自己写一个一层的decoder-only模型
- 我们主要实现了自注意力机制
- 对
dropout,layerNorm,残差链接等操作并没有关注
Attention部分
class SelfAttention(nn.Module):
def __init__(
self,
args,
embed_dim: int,
num_heads: int,
bias = True
):
super(SelfAttention, self).__init__()
self.args = args
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scaling = self.head_dim**-0.5
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(self, hidden_states: torch.Tensor):
"""Input shape: Batch x seq_len x dim"""
bsz, tgt_len, _ = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz) # bsz, heads, seq_len, dim
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape) # bsz_heads, seq_len, dim
key_states = key_states.reshape(*proj_shape)
value_states = value_states.reshape(*proj_shape)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2)) # bsz*head_num, tgt_len, src_len
src_len = key_states.size(1)
# causal_mask
mask_value = torch.finfo(attn_weights.dtype).min
matrix = torch.ones(bsz * self.num_heads, src_len, tgt_len).to(self.args.device)
causal_mask = torch.triu(matrix, diagonal=1)
causal_weights = torch.where(causal_mask.byte(), mask_value, causal_mask.double())
attn_weights += causal_weights
# do not need attn_mask
attn_probs = nn.functional.softmax(attn_weights, dim=-1)
# get output
attn_output = torch.bmm(attn_probs, value_states)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output
- 首先我们定义了
embed_dim, 多少个头,以及K,Q,V的映射矩阵 - forward函数的输入是一个batch的embedding,流程如下
- 将输入分别映射为
K, Q, V, 并将尺寸转换为多头的形式,shape(bsz*num_heads, seq_len, dim) - 进行
casual mask- 首先定义一个当前数据个数下的最小值,当一个数加上这个值再进行softmax,概率基本为0
- 根据
K, Q, V,得到一个分数矩阵attn_weights - 然后定义一个大小为
bsz * self.num_heads, src_len, tgt_len的全1矩阵 - 将该矩阵变成一个上三角矩阵,其中为1的地方,代表着当前位置需要进行mask,其他位置都是0
- 对于矩阵中为1的地方,我们用定义的最小值来替换、
- 将分数矩阵与mask矩阵相加,就实现了一个causal 分数矩阵
- 然后进行
softmax,通过V得到目标向量
- 为什么没有对padding进行mask?
- 因为不需要,我们进行的是右padding,所以causal mask已经对后面的padding进行了mask
- 另外,当真正的输入输出算完后,对于后面padding位置对应的输出,是不统计loss的,因此padding没有影响
- 将输入分别映射为
完整模型
class AttentionModel(nn.Module):
def __init__(self, args, embed_dim, head_num):
super(AttentionModel, self).__init__()
self.args = args
self.embeddings = nn.Embedding(self.args.vocab_size, embed_dim)
self.p_embeddings = nn.Embedding(self.args.max_len, embed_dim)
self.attention = SelfAttention(self.args, embed_dim, head_num)
self.output = nn.Linear(embed_dim, self.args.vocab_size)
def forward(self, input_ids, attn_mask):
embeddings = self.embeddings(input_ids)
position_embeddings = self.p_embeddings(torch.arange(0, input_ids.shape[1], device=self.args.device))
embeddings = embeddings + position_embeddings
output = self.attention(embeddings, attn_mask)
logits = self.output(output)
return logits
- 我们不仅做了embedding,还实现了position embedding
训练部分
训练阶段与RNN一直,也是组织输入,输出,以及loss
超参设置
embed_dim=512num_head=8epoch=30batch_size=12
结果与分析
训练集Loss
-
FFN loss(最小值4.332110404968262)
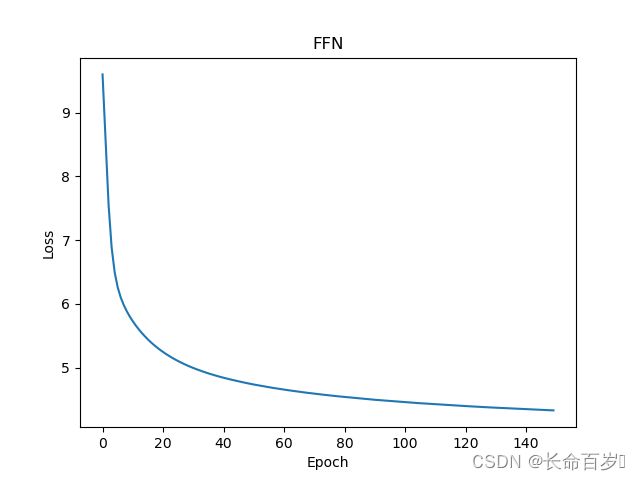
-
RNN loss(最小值4.00740385055542)
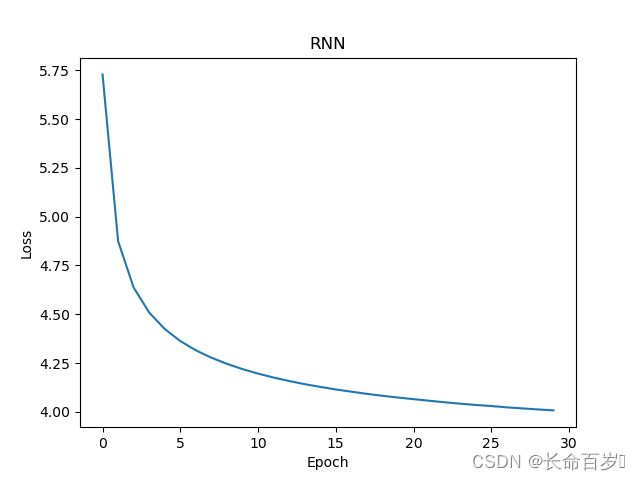
-
Attention loss(最小值3.7037367820739746)

测试集PPL
-
FFN(最小值4.401318073272705)

-
RNN(最小值4.0991902351379395)
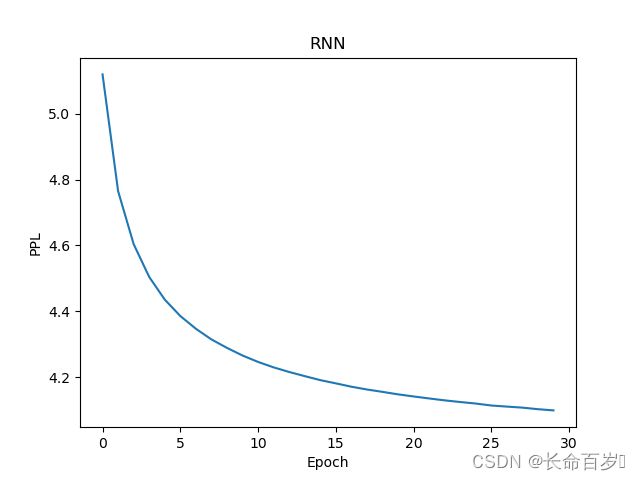
-
Attention(最小值3.9784348011016846)

从结果来看,无论是train loss, 还是test ppl,均有FFN>RNN>Attention的关系,且我们看到后两个模型还未完全收敛,性能仍有上升空间。
- 尽管FFN的任务更简单,其性能仍最差,这是因为其模型结构过于简单
- RNN与Attention任务一致,但性能更差
- Attention性能最好,这些观察均符合基本认识
代码可见:ShiyuNee/Train-A-Language-Model-based-on-FFN-RNN-Attention (github.com)