Python让Excel飞起来—批量处理行、列和单元格
目录
案例01 精确调整多个工作簿的行高和列宽
举一反三 精确调整一个工作簿中所有工作表的行高和列宽
案例02 批量更改多个工作簿的数据格式
举一反三 批量更改多个工作簿的外观格式
案例03 批量替换多个工作簿的行数据
举一反三 批量替换多个工作簿中的单元格数据
举一反三 批量修改多个工作簿中指定工作表的列数据
案例04 批量提取一个工作簿中所有工作表的特定数据
举一反三 批量提取一个工作簿中所有工作表的列数据
举一反三 在多个工作簿的指定工作表中批量追加行数据
案例05 对多个工作簿中指定工作表的数据进行分列
举一反三 批量合并多个工作簿中指定工作表的列数据
举一反三 将多个工作簿中指定工作表的列数据拆分为多行
案例06 批量提取一个工作簿中所有工作表的唯一 值
举一反三 批量提取一个工作簿中所有工作表的唯一值并汇总
案例01 精确调整多个工作簿的行高和列宽
- 代码文件:精确调整多个工作簿的行高和列宽.py
- 数据文件:销售表(文件夹)
除了前面讲解的工作簿和工作表的批量操作,Python还可以对工作表中的行、列和单元格等元素进行批量设置。例如,要调整行高和列宽,可以使用xlwings模块的 column_width 和 row_height属性,再加上 for 语句,就可以实现批量调整了。
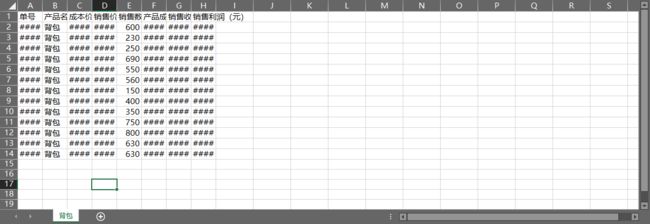
调整为:
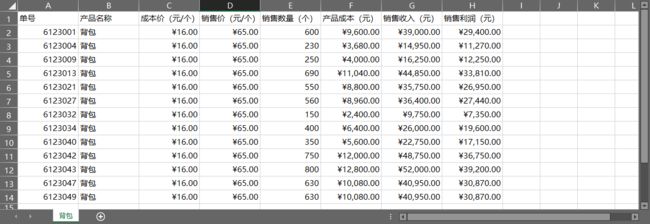 代码如下:
代码如下:
import os
import xlwings as xw
file_path=r'C:\Users\Administrator\Desktop\22\销售表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
value=j.range('A1').expand() #在工作表中选定要调整行高列宽的区域
value.column_width=12 #将列宽调整为可容纳12个字符的宽度
value.row_height=20 #将行高调整为20磅
workbook.save()
workbook.close()
app.quit() 知识延伸
第 13 行代码中的 column_width 是 xlwings模块中用于获取和设置列宽的属性。列宽的单位是字符数,取值范围是 0 ~255。这里的字符指的是英文字符,如果字符的字体是比例字体(每个字符的宽度不同),则以字符0的宽度为准。在用该属性设置列宽时,为该属性赋值即可。在用该属性获取列宽时,如果所选单元格区域中各列的列宽不同,则根据所选单元格区域位于包含数据单元格区域的内部或外部分别返回 None或第一列的列宽。
第 14 行代码中的 row_height 是 xlwings模块中用于获取和设置行高的属性。行高的单位是磅,取值范围是 0~409.5。在用该属性设置行高时,为该属性赋值即可。在用该属性获取行高时,如果所选单元格区域中各列的行高不同,则根据所选单元格区域位于包含数据单元格区域的内部或外部分别返回 None 或第一行的行高
举一反三 精确调整一个工作簿中所有工作表的行高和列宽
- 代码文件:精确调整一个工作簿中所有工作表的行高和列宽.py
- 数据文件:采购表.xlsx
import xlwings as xw
app=xw.App(visible=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
for i in workbook.sheets:
value=i.range('A1').expand()
value.column_width=12 #将列宽调整为可容纳12个字符的宽度
value.row_height=20 #将行高调整为20磅
workbook.save()
workbook.close()
app.quit()案例02 批量更改多个工作簿的数据格式
- 代码文件:批量更改多个工作簿的数据格式.py
- 数据文件:采购表(文件夹)
用 Excel 的功能将下左图中 A 列和 D列的数据格式更改为下图的效果。

import os
import xlwings as xw
file_path=r'C:\Users\Administrator\Desktop\22\采购表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
row_num=j['A1'].current_region.last_cell.row # 获取工作表中数据区域最后一行
j['A2:A{}'.format(row_num)].number_format='m/d' # 将A列的“采购日期”数据全部更改为“月/日
j['D2:D{}'.format(row_num)].number_format='¥#,##0.00' # 将D列的“采购金额”数据全部更改为带货币符号并保留2位小数
workbook.save()
workbook.close()
app.quit()代码解析
第 6 ~ 16 行代码用于逐个打开文件夹 “ 采购表 ”中的工作簿,完成所需的批量操作后保存并关闭。其中第 11 ~14行代码是实现批量操作的核心部分:在打开的工作簿中逐个选择工作表,并设置指定列的数据格式。第 13 行和第 14 行代码中的 A 列和 D列可以根据实际需求修改为其他列,数据格式 “m/d” 和 “#,##0.00” 也可以根据实际需求修改为其他格式。
知识延伸
- 第13行和第14行代码使用了第4章案例08中介绍的format()函数来拼接代表单元格区域的字符串。以'A2:A{}'.format(row_num)为例,假设当前工作表中数据区域最后一行的行号row_num为16,则'A2:A{}'.format(row_num)就相当于'A2:A16',代表单元格区域A2:A16。
- 拼接出单元格区域后,就可以使用xlwings模块中的number_format属性来设置单元格区域中数据的格式。该属性的取值为一个代表特定格式的字符串,与Excel的“设置单元格格式”对话框中“数字”选项卡下设置的格式对应。
举一反三 批量更改多个工作簿的外观格式
- 代码文件:批量更改多个工作簿的外观格式.py
- 数据文件:销售表(文件夹)
通过前面的学习,我们掌握了数据格式的批量更改,如果还想要批量更改字体、颜色、边框等外观格式,可以通过以下代码实现。
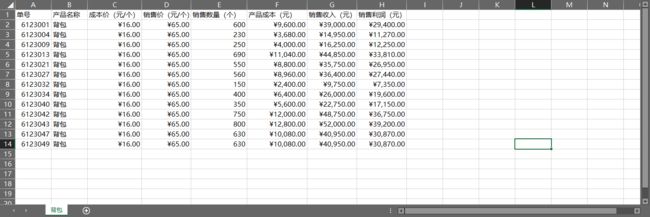
变成如下含格式的表:
import os
import xlwings as xw
file_path=r'C:\Users\MLoong\Desktop\22\销售表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
#设置标题的格式
j['A1:H1'].api.Font.Name='微软雅黑' #设置工作表标题行的字体为宋体
j['A1:H1'].api.Font.Size=10 #设置工作表标题行的字号为10磅
j['A1:H1'].api.Font.Bold=True #加粗
j['A1:H1'].api.Font.Color=xw.utils.rgb_to_int((255,255,255)) #字体颜色白色
j['A1:H1'].color=xw.utils.rgb_to_int((0,0,0)) #单元格背景色‘黑色’
j['A1:H1'].api.HorizontalAlignment=xw.constants.HAlign.xlHAlignCenter #水平居中
j['A1:H1'].api.VerticalAlignment=xw.constants.VAlign.xlVAlignCenter #垂直居中
#设置主体内容的格式
j['A2'].expand().api.Font.Name='微软雅黑' #设置工作表标题行的字体为宋体
j['A2'].expand().api.Font.Size=10 #设置工作表标题行的字号为10磅
j['A2'].expand().api.HorizontalAlignment=xw.constants.HAlign.xlHAlignLeft #水平靠左
j['A2'].expand().api.VerticalAlignment=xw.constants.VAlign.xlVAlignCenter #垂直居中
for cell in j['A1'].expand():
for b in range(7,12):
cell.api.Borders(b).LineStyle=1 #设置单元格边框的线条
cell.api.Borders(b).Weight=2 #设置单元格边框线条的粗细
workbook.save()
workbook.close()
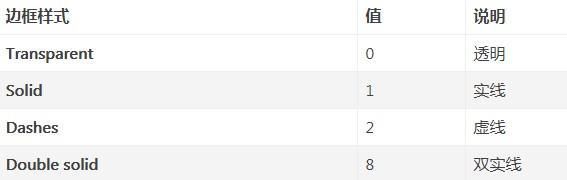
app.quit()- Borders() 里的参数如下:
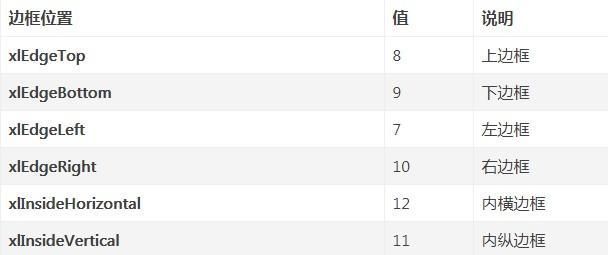
- LineStyle = 1,这里的 1 指的是边框为实线。
案例03 批量替换多个工作簿的行数据
- 代码文件:批量替换多个工作簿的行数据.py
- 数据文件:分部信息(文件夹)
import os
import xlwings as xw
file_path=r'C:\Users\Administrator\Desktop\22\分部信息'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
value=j['A2'].expand('table').value
for index,val in enumerate(value): # 按行遍历工作表数据
if val==['背包',16,65]: # 判断行数据是否为“背包”
value[index]=['双肩包',36,79] # 如果是,则将该行数据替换为新的数据
j['A2'].expand('table').value=value # 将完成替换的数据写 入工作表
workbook.save()
workbook.close()
app.quit() 知识延伸
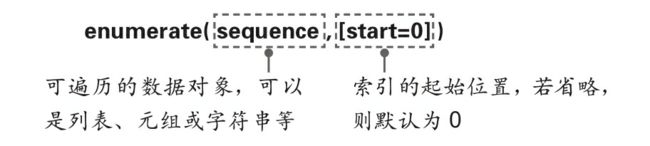
第 13 行代码中的 enumerate() 是Python的内置函数,用于将一个可遍历的数据对象(如列表、元组或字符串等)组合为一个索引序列,可同时得到数据对象的索引及对应的值,一般用在 for语句当中。该函数的语法格式和常用参数含义如下。
举一反三 批量替换多个工作簿中的单元格数据
- 代码文件:批量替换多个工作簿中的单元格数据.py
- 数据文件:分部信息(文件夹)
学会了替换多个工作簿的行数据,替换单个单元格的数据就可以用类似的思路来完成,具体代码如下。
import os
import xlwings as xw
file_path=r'C:\Users\Administrator\Desktop\22\分部信息'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
value=j['A2'].expand('table').value
for index,val in enumerate(value): # 按行遍历工作表数据
if val[0]=='背包': # 判断行数据是否为“背包”
val[0]='双肩包' # 如果是,则将该行数据替换为新的数据
value[index]=val
j['A2'].expand('table').value=value # 将完成替换的数据写 入工作表
workbook.save()
workbook.close()
app.quit()举一反三 批量修改多个工作簿中指定工作表的列数据
- 代码文件:批量修改多个工作簿中指定工作表的列数据.py
- 数据文件:分部信息(文件夹)
如果要修改多个工作簿中指定工作表的某一列数据,可以使用如下代码来实现。
例如,要将销售价格都上调5%,代码如下:
import os
import xlwings as xw
file_path=r'C:\Users\Administrator\Desktop\22\分部信息'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
worksheet=workbook.sheets['产品分类表'] #指定要修改的工作表
value=worksheet['A2'].expand('table').value
for index,val in enumerate(value):
val[2]=val[2]*(1+0.05)
value[index]=val #替换整行的数据
worksheet['A2'].expand('table').value=value #将完成替换的数据写入工作表
workbook.save()
workbook.close()
app.quit() 案例04 批量提取一个工作簿中所有工作表的特定数据
- 代码文件:批量提取一个工作簿中所有工作表的特定数据.py
- 数据文件:采购表.xlsx
import xlwings as xw
import pandas as pd
app=xw.App(visible=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
data=[] #用于存放数据
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value #读取sheet的数据,并DataFrame二维表格的形式展示
filtered=values[values['采购物品']=='复印纸'] #提取采购物品为复印纸的行数据
if not filtered.empty: #判断提取的行是否为空
data.append(filtered) #将提取的行数据追加到列表中
new_workbook=app.books.add()
new_worksheet=new_workbook.sheets.add('复印纸')
new_worksheet.range('A1').expand().value=pd.concat(data,ignore_index=False) #将提取的数字写入工作表中
new_workbook.save(r'C:\Users\Administrator\Desktop\22\复印纸.xlsx')
workbook.close()
app.quit()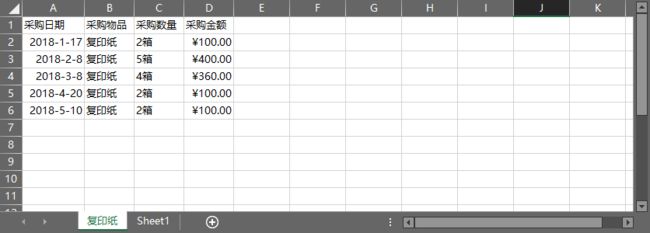
知识延伸
- 第8行代码中的DataFrame是pandas模块的一种数据结构,它类似Excel中的二维表格。3.5节已经详细介绍过DataFrame数据结构,这里不再赘述。
- 第14行代码中的concat()是pandas模块中的函数,可将数据根据不同的轴进行简单的拼接。在3.5.4节曾简单介绍过concat()函数的用法,这里再详细介绍一下该函数的语法格式和常用参数含义。
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False,copy=True)


举一反三 批量提取一个工作簿中所有工作表的列数据
- 代码文件:批量提取一个工作簿中所有工作表的列数据.py
- 数据文件:采购表.xlsx
如果要批量提取一个工作簿中所有工作表的列数据,可以使用以下代码来实现。
例如要将所有表里面的采购日期和采购金额提取出来,代码如下:
import xlwings as xw
import pandas as pd
app=xw.App(visible=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采购表.xlsx')
column=['采购日期','采购金额']
data=[]
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame,index=False).value
filtered=values[column] #根据前面指定的列标题提取数据
data.append(filtered)
new_workbook=xw.books.add()
new_worksheet=new_workbook.sheets.add('提取数据')
new_worksheet.range('A1').value=pd.concat(data,ignore_index=False).set_index(column[0])
new_worksheet.autofit()
new_workbook.save(r'C:\Users\Administrator\Desktop\22\提取表.xlsx')
workbook.close()
app.quit()举一反三 在多个工作簿的指定工作表中批量追加行数据
- 代码文件:在多个工作簿的指定工作表中批量追加行数据.py
- 数据文件:分部信息(文件夹)
如果要在多个工作簿的指定工作表中追加相同内容的行数据,可以使用以下代码来实现。
import os
import xlwings as xw
newContent=[['双肩包','64','110'],['腰包','23','58']] #给出要追加的行数据
app=xw.App(visible=False)
file_path=r'C:\Users\Administrator\Desktop\22\分部信息'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
worksheet=workbook.sheets['产品分类表'] #指定要追加行数的工作表
values=worksheet.range('A1').expand()
number=values.shape[0]
worksheet.range(number+1,1).value=newContent #件前面指定的行数据追加到原有数据的下方
workbook.save()
workbook.close()
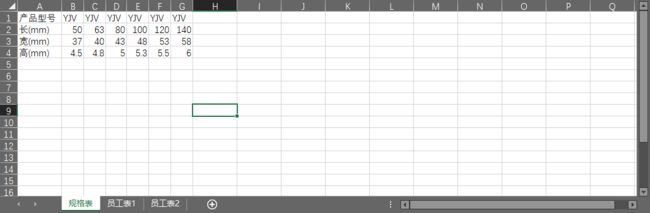
app.quit()案例05 对多个工作簿中指定工作表的数据进行分列
- 代码文件:对多个工作簿中指定工作表的数据进行分列.py
- 数据文件:产品记录表(文件夹)
如果要将下左图中的 “ 规格 ”列拆分为下图中的 “ 长 ”“ 宽 ”“ 高 ”3 列,应该怎么做呢?

import os
import xlwings as xw
import pandas as pd
file_path=r'C:\Users\Administrator\Desktop\22\产品记录表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
worksheet=workbook.sheets['规格表']
values=worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value #读取工作表中数据
new_values=values['规格'].str.split('*',expand=True)
values['长(mm)']=new_values[0]
values['宽(mm)']=new_values[1]
values['高(mm)']=new_values[2]
values.drop(columns=['规格'],inplace=True)
worksheet['A1'].options(index=False).value=values
worksheet.autofit()
workbook.save()
workbook.close()
app.quit() 知识延伸
第 14 行代码中的 split() 是 pandas 模块中Series对象的一个字符串函数,用于根据指定的分隔符拆分字符串。该函数的语法格式和常用参数含义如下:

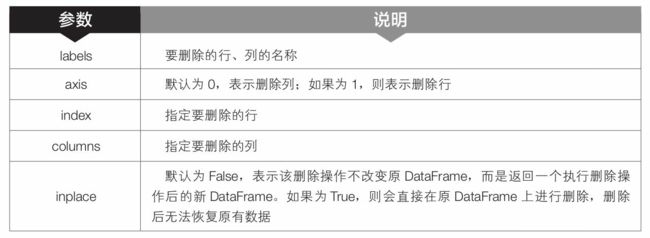
第 18 行代码中的 drop() 是 pandas 模块中 DataFrame对象的函数,用于删除 DataFrame 对象的某一行或某一列。在 3.5.3节中曾简单介绍过drop()函数的用法,这里再详细介绍一下该函数的语法格式和常用参数含义
DataFrame.drop(labels=None,axis=0,index=None,columns=None,inplace=False)
举一反三 批量合并多个工作簿中指定工作表的列数据
- 代码文件:批量合并多个工作簿中指定工作表的列数据.py
- 数据文件:产品记录表(文件夹)
如果需要批量将多个工作簿中指定工作表的某几列数据合并为一列,可以使用以下代码来实现。
import os
import xlwings as xw
import pandas as pd
file_path=r'C:\Users\Administrator\Desktop\22\产品记录表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
worksheet=workbook.sheets['规格表']
values=worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value #读取工作表中数据
#构造新列
values['规格']=values['长(mm)'].astype('str')+'*'+values['宽(mm)'].astype('str')+'*'+values['高(mm)'].astype('str')
#删除原来的列
values.drop(columns=['长(mm)'],inplace=True)
values.drop(columns=['宽(mm)'],inplace=True)
values.drop(columns=['高(mm)'],inplace=True)
worksheet.clear() #清除工作表中原有的数据
worksheet['A1'].options(index=False).value=values
worksheet.autofit()
workbook.save()
workbook.close()
app.quit()举一反三 将多个工作簿中指定工作表的列数据拆分为多行
- 代码文件:将多个工作簿中指定工作表的列数据拆分为多行.py
- 数据文件:产品记录表(文件夹)
如果想要将列数据拆分为多行,可以在数据分列后对行列进行转置操作,具体代码如下。

变成下面的形式:
import os
import xlwings as xw
import pandas as pd
file_path=r'C:\Users\Administrator\Desktop\22\产品记录表'
file_list=os.listdir(file_path)
app=xw.App(visible=False)
for i in file_list:
if i.startswith('~$'):
continue
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
worksheet=workbook.sheets['规格表']
values=worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value #读取工作表中数据
new_values=values['规格'].str.split('*',expand=True)
values['长(mm)']=new_values[0]
values['宽(mm)']=new_values[1]
values['高(mm)']=new_values[2]
values.drop(columns=['规格'],inplace=True)
values=values.T #转置数据
values.columns=values.iloc[0]
values.index.name=values.iloc[0].index.name
values.drop(values.iloc[0].index.name,inplace=True)
worksheet.clear()
worksheet['A1'].value=values
worksheet.autofit()
workbook.save()
workbook.close()
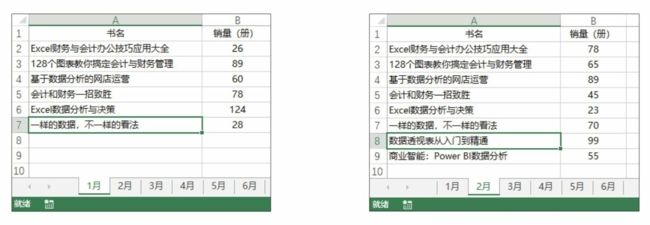
app.quit() 案例06 批量提取一个工作簿中所有工作表的唯一 值
- 代码文件:批量提取一个工作簿中所有工作表的唯一值.py
- 数据文件:上半年销售统计表.xlsx
如下左图和下下图所示,工作表 “1 月 ” 和 “2 月 ”中的书名有一部分是重复的,工作表 “3 月 ”“4 月 ”“5 月 ”“6 月 ” 同理,现在我想将这 6个工作表中的书名提取出来,但是不能有重复的书名。
import xlwings as xw
app=xw.App(visible=True)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\上半年销售统计表.xlsx')
data=[]
for i,worksheet in enumerate(workbook.sheets): #遍历工作簿中的工作表
values=worksheet['A2'].expand('down').value #提取工作表中书名数据
data=data+values
data=list(set(data)) #对列表中的书名数据进行去重操作
data.insert(0,'书名') #在去重后的书名数据前添加列标题,书名
new_workbook=app.books.add() #新建工作表
new_worksheet=new_workbook.sheets.add('书名')
new_worksheet['A1'].options(transpose=True).value=data #将处理好的书名数据写入新歌工作表中
new_worksheet.autofit()
new_workbook.save(r'C:\Users\MLoong\Desktop\22\书名.xlsx')
workbook.close()
app.quit()知识延伸
- 第8行代码中的set()函数在2.3.3节中曾介绍过,它原本的功能是将其他类型的序列对象(如列表)转换为集合,因为集合中不允许出现重复元素,转换过程中重复元素便会被自动去除,所以该函数也常用于数据的去重。第8行代码先用set()函数对数据进行去重,再用list()函数将去重操作获得的集合转换为列表,以便在第9行代码中使用列表的insert()函数添加元素。
- 第9行代码中的insert()是Python中列表对象的函数,用于在列表的指定位置插入元素。该函数的语法格式和常用参数含义如下。

举一反三 批量提取一个工作簿中所有工作表的唯一值并汇总
- 代码文件:批量提取一个工作簿中所有工作表的唯一值并汇总.py
- 数据文件:上半年销售统计表.xlsx
import os
import xlwings as xw
app=xw.App(visible=True)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\上半年销售统计表.xlsx')
data=list() #创建一个空列表用于存放书名和销量的明细数据
for i,worksheet in enumerate(workbook.sheets): #遍历工作簿中的工作表
values=worksheet['A2'].expand('table').value #提取工作表中书名数据
data=data+values
sales=dict()
for i in range(len(data)):
name=data[i][0]
sale=data[i][1]
if name not in sales:
sales[name]=sale
else:
sales[name]+=sale
dictlist=list()
for key,value in sales.items():
temp=[key,value]
dictlist.append(temp)
dictlist.insert(0,['书名','销量'])
new_workbook=app.books.add() #新建工作表
new_worksheet=new_workbook.sheets.add('销售统计')
new_worksheet['A1'].value=dictlist #将处理好的书名数据写入新歌工作表中
new_worksheet.autofit()
new_workbook.save(r'C:\Users\MLoong\Desktop\22\销售统计.xlsx')
workbook.close()
app.quit()参考文献 《超简单:用Python让Excel飞起来》
数据下载:
链接:https://pan.baidu.com/s/1KdI7u72sZIcG_C5Y9AtCJw
提取码:8888