一 SparkSQL 是什么
1.1 SparkSQL 的出现契机
数据分析的方式
数据分析的方式大致上可以划分为 SQL 和 命令式两种:
命令式
在前面的 RDD 部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算.
命令式的优点
-
操作粒度更细, 能够控制数据的每一个处理环节
-
操作更明确, 步骤更清晰, 容易维护
-
支持非结构化数据的操作
命令式的缺点
SQL
对于一些数据科学家, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以 SQL on Hadoop 是一个非常重要的方向.
SQL 的优点
- 表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段, 又比如说这段 - SQL 明显能看到是想查询年龄大于 10 岁的条目
SQL 的缺点
-
想想一下 3 层嵌套的 SQL, 维护起来应该挺力不从心的吧
-
试想一下, 如果使用 SQL 来实现机器学习算法, 也挺为难的吧
SQL 擅长数据分析和通过简单的语法表示查询, 命令式操作适合过程式处理和算法性的处理. 在 Spark 出现之前, 对于结构化数据的查询和处理, 一个工具一向只能支持 SQL 或者命令式, 使用者被迫要使用多个工具来适应两种场景, 并且多个工具配合起来比较费劲.
而 Spark 出现了以后, 统一了两种数据处理范式, 是一种革新性的进步.
Hive
解决的问题
Hive 实现了 SQL on Hadoop, 使用 MapReduce 执行任务
简化了 MapReduce 任务
新的问题
Hive 的查询延迟比较高, 原因是使用 MapReduce 做调度
Shark
解决的问题
以上两点使得 Shark 的查询效率很高
新的问题
-
Shark 重用了 Hive 的 SQL 解析, 逻辑计划生成以及优化, 所以其实可以认为 Shark 只是把 Hive 的物理执行替换为了 Spark 作业
-
执行计划的生成严重依赖 Hive, 想要增加新的优化非常困难
-
Hive 使用 MapReduce 执行作业, 所以 Hive 是进程级别的并行, 而 Spark 是线程级别的并行, 所以 Hive 中很多线程不安全的代码不适用于 Spark
由于以上问题, Shark 维护了 Hive 的一个分支, 并且无法合并进主线, 难以为继

1.2. SparkSQL 的适用场景
|
定义 |
特点 |
举例 |
结构化数据 |
有固定的 Schema |
有预定义的 Schema |
关系型数据库的表 |
半结构化数据 |
没有固定的 Schema, 但是有结构 |
没有固定的 Schema, 有结构信息, 数据一般是自描述的 |
指一些有结构的文件格式, 例如 JSON |
非结构化数据 |
没有固定 Schema, 也没有结构 |
没有固定 Schema, 也没有结构 |
指文档图片之类的格式 |
结构化数据
-
一般指数据有固定的 Schema, 例如在用户表中, name 字段是 String 型, 那么每一条数据的 name 字段值都可以当作 String 来使用
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
+----+--------------+---------------------------+-------+---------+
半结构化数据
-
一般指的是数据没有固定的 Schema, 但是数据本身是有结构的
{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"phoneNumber":
[
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
]
}
没有固定 Schema
-
指的是半结构化数据是没有固定的 Schema 的, 可以理解为没有显式指定 Schema
比如说一个用户信息的 JSON 文件, 第一条数据的 phone_num 有可能是 String, 第二条数据虽说应该也是 String, 但是如果硬要指定为 BigInt, 也是有可能的
因为没有指定 Schema, 没有显式的强制的约束
有结构
-
虽说半结构化数据是没有显式指定 Schema 的, 也没有约束, 但是半结构化数据本身是有有隐式的结构的, 也就是数据自身可以描述自身
例如 JSON 文件, 其中的某一条数据是有字段这个概念的, 每个字段也有类型的概念, 所以说 JSON 是可以描述自身的, 也就是数据本身携带有元信息
SparkSQL 处理什么数据的问题?
-
SparkSQL 相较于 RDD 的优势在哪?
-
-
SparkSQL 提供了更好的外部数据源读写支持
-
SparkSQL 提供了直接访问列的能力
二 SparkSQL 初体验
2.1 RDD 版本的 WordCount
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
sc.textFile("hdfs://node01:8020/dataset/wordcount.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect
2.2. 命令式 API 的入门案例
case class People(name: String, age: Int)
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleRDD: RDD[People] = spark.sparkContext.parallelize(Seq(People("zhangsan", 9), People("lisi", 15)))
val peopleDS: Dataset[People] = peopleRDD.toDS()
val teenagers: Dataset[String] = peopleDS.where('age > 10)
.where('age < 20)
.select('name)
.as[String]
teenagers.show()
SparkSQL 中有一个新的入口点, 叫做 SparkSession
SparkSQL 中有一个新的类型叫做 Dataset
SparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的


rdd.map { case Person(id, name, age) => (age, 1) }
.reduceByKey {case ((age, count), (totalAge, totalCount)) => (age, count + totalCount)}
df.groupBy("age").count("age")
2.2. SQL 版本 WordCount
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleRDD: RDD[People] = spark.sparkContext.parallelize(Seq(People("zhangsan", 9), People("lisi", 15)))
val peopleDS: Dataset[People] = peopleRDD.toDS()
peopleDS.createOrReplaceTempView("people")
val teenagers: DataFrame = spark.sql("select name from people where age > 10 and age < 20")
teenagers.show()
以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表

3. [扩展] Catalyst 优化器
3.1. RDD 和 SparkSQL 运行时的区别




3.2. Catalyst
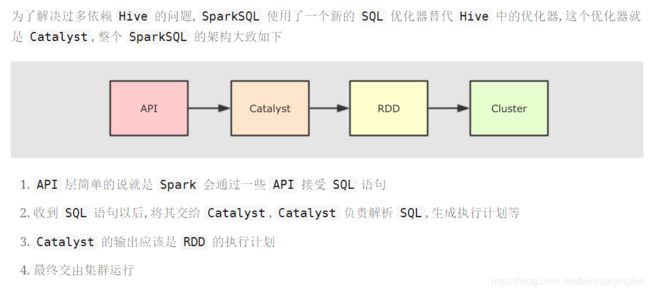






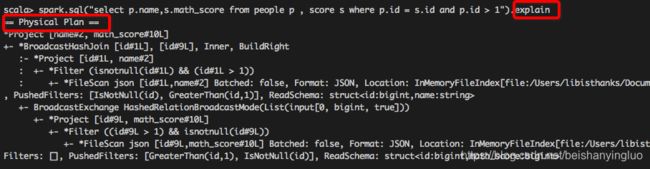


4. Dataset 的特点
Dataset 是什么?
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val dataset: Dataset[People] = spark.createDataset(Seq(People("zhangsan", 9), People("lisi", 15)))
dataset.filter(item => item.age > 10).show()
dataset.filter('age > 10).show()
dataset.filter("age > 10").show()

即使使用 Dataset 的命令式 API, 执行计划也依然会被优化
Dataset 具有 RDD 的方便, 同时也具有 DataFrame 的性能优势, 并且 Dataset 还是强类型的, 能做到类型安全.
scala> spark.range(1).filter('id === 0).explain(true)
== Parsed Logical Plan ==
'Filter ('id = 0)
+- Range (0, 1, splits=8)
== Analyzed Logical Plan ==
id: bigint
Filter (id#51L = cast(0 as bigint))
+- Range (0, 1, splits=8)
== Optimized Logical Plan ==
Filter (id#51L = 0)
+- Range (0, 1, splits=8)
== Physical Plan ==
*Filter (id#51L = 0)
+- *Range (0, 1, splits=8)
Dataset 的底层是什么?



5. DataFrame 的作用和常见操作
DataFrame 是什么?


val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleDF: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF()
peopleDF.groupBy('age)
.count()
.show()
通过隐式转换创建 DataFrame
这种方式本质上是使用 SparkSession 中的隐式转换来进行的
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val peopleDF: DataFrame = Seq(People("zhangsan", 15), People("lisi", 15)).toDF()

根据源码可以知道, toDF 方法可以在 RDD 和 Seq 中使用
通过集合创建 DataFrame 的时候, 集合中不仅可以包含样例类, 也可以只有普通数据类型, 后通过指定列名来创建
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val df1: DataFrame = Seq("nihao", "hello").toDF("text")
df1.show()
val df2: DataFrame = Seq(("a", 1), ("b", 1)).toDF("word", "count")
df2.show()
通过外部集合创建 DataFrame
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("hello")
.master("local[6]")
.getOrCreate()
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
df.show(10)
df.printSchema()
在 DataFrame 上可以使用的常规操作
需求: 查看每个月的统计数量




6. Dataset 和 DataFrame 的异同
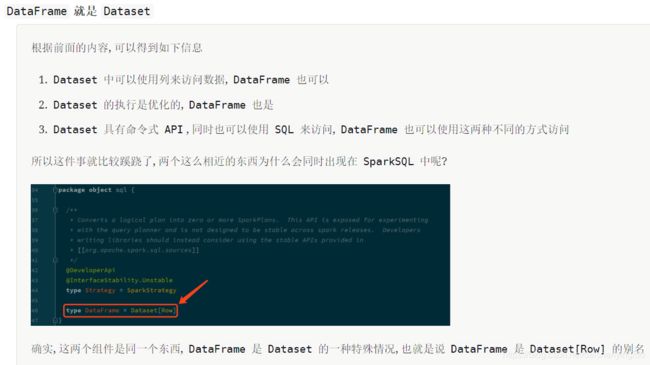
DataFrame 和 Dataset 所表达的语义不同




7. 数据读写
7.1. 初识 DataFrameReader

| 组件 |
解释 |
schema
|
结构信息, 因为 Dataset 是有结构的, 所以在读取数据的时候, 就需要有 Schema 信息, 有可能是从外部数据源获取的, 也有可能是指定的 |
option
|
连接外部数据源的参数, 例如 JDBC 的 URL, 或者读取 CSV 文件是否引入 Header 等 |
format
|
外部数据源的格式, 例如 csv, jdbc, json 等 |
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val spark: SparkSession = ...
val fromLoad: DataFrame = spark
.read
.format("csv")
.option("header", true)
.option("inferSchema", true)
.load("dataset/BeijingPM20100101_20151231.csv")
val fromCSV: DataFrame = spark
.read
.option("header", true)
.option("inferSchema", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
但是其实这两种方式本质上一样, 因为类似 csv 这样的方式只是 load 的封装


7.2. 初识 DataFrameWriter
对于 ETL 来说, 数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter
val spark: SparkSession = ...
val df = spark.read
.option("header", true)
.csv("dataset/BeijingPM20100101_20151231.csv")
val writer: DataFrameWriter[Row] = df.write
| 组件 |
解释 |
source
|
写入目标, 文件格式等, 通过 format 方法设定 |
mode
|
写入模式, 例如一张表已经存在, 如果通过 DataFrameWriter 向这张表中写入数据, 是覆盖表呢, 还是向表中追加呢? 通过 mode 方法设定 |
extraOptions
|
外部参数, 例如 JDBC 的 URL, 通过 options, option 设定 |
partitioningColumns
|
类似 Hive 的分区, 保存表的时候使用, 这个地方的分区不是 RDD 的分区, 而是文件的分区, 或者表的分区, 通过 partitionBy 设定 |
bucketColumnNames
|
类似 Hive 的分桶, 保存表的时候使用, 通过 bucketBy 设定 |
sortColumnNames
|
用于排序的列, 通过 sortBy 设定 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 |
字符串表示 |
解释 |
SaveMode.ErrorIfExists
|
"error"
|
将 DataFrame 保存到 source 时, 如果目标已经存在, 则报错 |
SaveMode.Append
|
"append"
|
将 DataFrame 保存到 source 时, 如果目标已经存在, 则添加到文件或者 Table 中 |
SaveMode.Overwrite
|
"overwrite"
|
将 DataFrame 保存到 source 时, 如果目标已经存在, 则使用 DataFrame 中的数据完全覆盖目标 |
SaveMode.Ignore
|
"ignore"
|
将 DataFrame 保存到 source 时, 如果目标已经存在, 则不会保存 DataFrame 数据, 并且也不修改目标数据集, 类似于 CREATE TABLE IF NOT EXISTS |

7.3. 读写 Parquet 格式文件

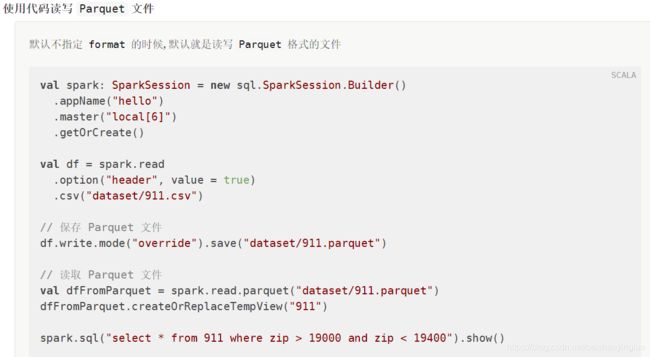





Table 1. SparkSession 中有关 Parquet 的配置
| 配置 |
默认值 |
含义 |
spark.sql.parquet.binaryAsString
|
false
|
一些其他 Parquet 生产系统, 不区分字符串类型和二进制类型, 该配置告诉 SparkSQL 将二进制数据解释为字符串以提供与这些系统的兼容性 |
spark.sql.parquet.int96AsTimestamp
|
true
|
一些其他 Parquet 生产系统, 将 Timestamp 存为 INT96, 该配置告诉 SparkSQL 将 INT96 解析为 Timestamp |
spark.sql.parquet.cacheMetadata
|
true
|
打开 Parquet 元数据的缓存, 可以加快查询静态数据 |
spark.sql.parquet.compression.codec
|
snappy
|
压缩方式, 可选 uncompressed, snappy, gzip, lzo |
spark.sql.parquet.mergeSchema
|
false
|
当为 true 时, Parquet 数据源会合并从所有数据文件收集的 Schemas 和数据, 因为这个操作开销比较大, 所以默认关闭 |
spark.sql.optimizer.metadataOnly
|
true
|
如果为 true, 会通过原信息来生成分区列, 如果为 false 则就是通过扫描整个数据集来确定 |

7.4. 读写 JSON 格式文件



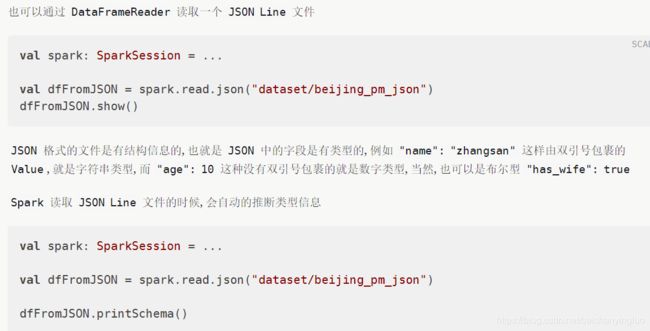



7.5. 访问 Hive
7.5.1. SparkSQL 整合 Hive
SparkSQL 内置的有一个 MetaStore, 通过嵌入式数据库 Derby 保存元信息, 但是对于生产环境来说, 还是应该使用 Hive 的 MetaStore, 一是更成熟, 功能更强, 二是可以使用 Hive 的元信息
SparkSQL 内置了 HiveSQL 的支持, 所以无需整合
为什么要开启 Hive 的 MetaStore
Hive 的 MetaStore 是一个 Hive 的组件, 一个 Hive 提供的程序, 用以保存和访问表的元数据, 整个 Hive 的结构大致如下


Hive 开启 MetaStore
Step 1: 修改 hive-site.xml
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>username</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value> //当前服务器
</property>
Step 2: 启动 Hive MetaStore
nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &

7.5.2. 访问 Hive 表
在 Hive 中创建表
第一步, 需要先将文件上传到集群中, 使用如下命令上传到 HDFS 中
hdfs dfs -mkdir -p /dataset
hdfs dfs -put studenttabl10k /dataset/
第二步, 使用 Hive 或者 Beeline 执行如下 SQL
CREATE DATABASE IF NOT EXISTS spark_integrition;
USE spark_integrition;
CREATE EXTERNAL TABLE student
(
name STRING,
age INT,
gpa string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/dataset/hive';
LOAD DATA INPATH '/dataset/studenttab10k' OVERWRITE INTO TABLE student;
通过 SparkSQL 查询 Hive 的表
查询 Hive 中的表可以直接通过 spark.sql(…) 来进行, 可以直接在其中访问 Hive 的 MetaStore, 前提是一定要将 Hive 的配置文件拷贝到 Spark 的 conf 目录
scala> spark.sql("use spark_integrition")
scala> val resultDF = spark.sql("select * from student limit 10")
scala> resultDF.show()
通过 SparkSQL 创建 Hive 表
通过 SparkSQL 可以直接创建 Hive 表, 并且使用 LOAD DATA 加载数据
val createTableStr =
"""
|CREATE EXTERNAL TABLE student
|(
| name STRING,
| age INT,
| gpa string
|)
|ROW FORMAT DELIMITED
| FIELDS TERMINATED BY '\t'
| LINES TERMINATED BY '\n'
|STORED AS TEXTFILE
|LOCATION '/dataset/hive'
""".stripMargin
spark.sql("CREATE DATABASE IF NOT EXISTS spark_integrition1")
spark.sql("USE spark_integrition1")
spark.sql(createTableStr)
spark.sql("LOAD DATA INPATH '/dataset/studenttab10k' OVERWRITE INTO TABLE student")
spark.sql("select * from student limit").show()
目前 SparkSQL 支持的文件格式有 sequencefile, rcfile, orc, parquet, textfile, avro, 并且也可以指定 serde 的名称
使用 SparkSQL 处理数据并保存进 Hive 表
前面都在使用 SparkShell 的方式来访问 Hive, 编写 SQL, 通过 Spark 独立应用的形式也可以做到同样的事, 但是需要一些前置的步骤, 如下
Step 1: 导入 Maven 依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
Step 2: 配置 SparkSession
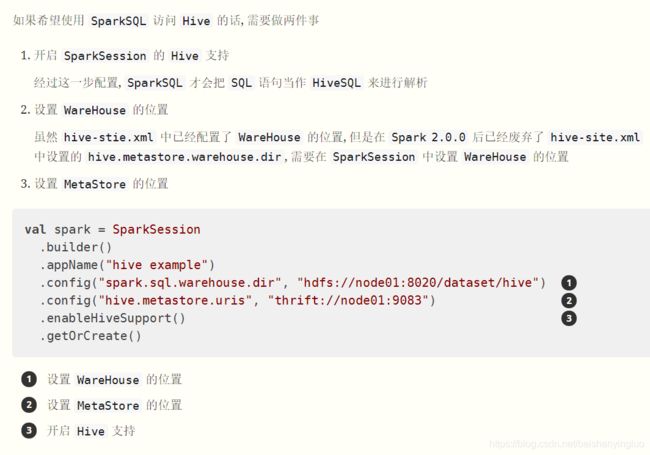
配置好了以后, 就可以通过 DataFrame 处理数据, 后将数据结果推入 Hive 表中了, 在将结果保存到 Hive 表的时候, 可以指定保存模式
val schema = StructType(
List(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gpa", FloatType)
)
)
val studentDF = spark.read
.option("delimiter", "\t")
.schema(schema)
.csv("dataset/studenttab10k")
val resultDF = studentDF.where("age < 50")
resultDF.write.mode(SaveMode.Overwrite).saveAsTable("spark_integrition1.student")
通过 mode 指定保存模式, 通过 saveAsTable 保存数据到 Hive
7.6. JDBC
准备 MySQL 环境
在使用 SparkSQL 访问 MySQL 之前, 要对 MySQL 进行一些操作, 例如说创建用户, 表和库等
Step 1: 连接 MySQL 数据库
在 MySQL 所在的主机上执行如下命令
mysql -u root -p
Step 2: 创建 Spark 使用的用户
登进 MySQL 后, 需要先创建用户
CREATE USER 'spark'@'%' IDENTIFIED BY 'Spark123!';
GRANT ALL ON spark_test.* TO 'spark'@'%';
Step 3: 创建库和表
CREATE DATABASE spark_test;
USE spark_test;
CREATE TABLE IF NOT EXISTS `student`(
`id` INT AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`age` INT NOT NULL,
`gpa` FLOAT,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
使用 SparkSQL 向 MySQL 中写入数据
其实在使用 SparkSQL 访问 MySQL 是通过 JDBC, 那么其实所有支持 JDBC 的数据库理论上都可以通过这种方式进行访问
在使用 JDBC 访问关系型数据的时候, 其实也是使用 DataFrameReader, 对 DataFrameReader 提供一些配置, 就可以使用 Spark 访问 JDBC, 有如下几个配置可用
| 属性 |
含义 |
url
|
要连接的 JDBC URL |
dbtable
|
要访问的表, 可以使用任何 SQL 语句中 from 子句支持的语法 |
fetchsize
|
数据抓取的大小(单位行), 适用于读的情况 |
batchsize
|
数据传输的大小(单位行), 适用于写的情况 |
isolationLevel
|
事务隔离级别, 是一个枚举, 取值 NONE, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, SERIALIZABLE, 默认为 READ_UNCOMMITTED |
val spark = SparkSession
.builder()
.appName("hive example")
.master("local[6]")
.getOrCreate()
val schema = StructType(
List(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gpa", FloatType)
)
)
val studentDF = spark.read
.option("delimiter", "\t")
.schema(schema)
.csv("dataset/studenttab10k")
studentDF.write.format("jdbc").mode(SaveMode.Overwrite)
.option("url", "jdbc:mysql://node01:3306/spark_test")
.option("dbtable", "student")
.option("user", "spark")
.option("password", "Spark123!")
.save()
运行程序
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
如果使用 Spark submit 或者 Spark shell 来运行任务, 需要通过 --jars 参数提交 MySQL 的 Jar 包, 或者指定 --packages 从 Maven 库中读取
bin/spark-shell --packages mysql:mysql-connector-java:5.1.47 --repositories http://maven.aliyun.com/nexus/content/groups/public/
从 MySQL 中读取数据
spark.read.format("jdbc")
.option("url", "jdbc:mysql://node01:3306/spark_test")
.option("dbtable", "student")
.option("user", "spark")
.option("password", "Spark123!")
.load()
.show()
默认情况下读取 MySQL 表时, 从 MySQL 表中读取的数据放入了一个分区, 拉取后可以使用 DataFrame 重分区来保证并行计算和内存占用不会太高, 但是如果感觉 MySQL 中数据过多的时候, 读取时可能就会产生 OOM, 所以在数据量比较大的场景, 就需要在读取的时候就将其分发到不同的 RDD 分区
| 属性 |
含义 |
partitionColumn
|
指定按照哪一列进行分区, 只能设置类型为数字的列, 一般指定为 ID |
lowerBound, upperBound
|
确定步长的参数, lowerBound - upperBound 之间的数据均分给每一个分区, 小于 lowerBound 的数据分给第一个分区, 大于 upperBound 的数据分给最后一个分区 |
numPartitions
|
分区数量 |
spark.read.format("jdbc")
.option("url", "jdbc:mysql://node01:3306/spark_test")
.option("dbtable", "student")
.option("user", "spark")
.option("password", "Spark123!")
.option("partitionColumn", "age")
.option("lowerBound", 1)
.option("upperBound", 60)
.option("numPartitions", 10)
.load()
.show()
有时候可能要使用非数字列来作为分区依据, Spark 也提供了针对任意类型的列作为分区依据的方法
val predicates = Array(
"age < 20",
"age >= 20, age < 30",
"age >= 30"
)
val connectionProperties = new Properties()
connectionProperties.setProperty("user", "spark")
connectionProperties.setProperty("password", "Spark123!")
spark.read
.jdbc(
url = "jdbc:mysql://node01:3306/spark_test",
table = "student",
predicates = predicates,
connectionProperties = connectionProperties
)
.show()
SparkSQL 中并没有直接提供按照 SQL 进行筛选读取数据的 API 和参数, 但是可以通过 dbtable 来曲线救国, dbtable 指定目标表的名称, 但是因为 dbtable 中可以编写 SQL, 所以使用子查询即可做到
spark.read.format("jdbc")
.option("url", "jdbc:mysql://node01:3306/spark_test")
.option("dbtable", "(select name, age from student where age > 10 and age < 20) as stu")
.option("user", "spark")
.option("password", "Spark123!")
.option("partitionColumn", "age")
.option("lowerBound", 1)
.option("upperBound", 60)
.option("numPartitions", 10)
.load()
.show()