SparkSQL 源码解析 SparkPlanner
文章目录
-
- 物理计划转换过程
- SparkPlan
-
- 分类
-
- LeafExecNode
- UnaryExecNode
- BinaryExecNode
- 其他类型的 SparkPlan
- SparkPlanner
-
- PlanLater
- plan
-
- SparkStrategy.apply
- collectPlaceholders
- placeholders解析
- prunePlans
- 总结
物理计划转换过程
从 Optimized LogicalPlan传入到 SparkSQL物理 计划提交并执行,主要经过 3 个阶段,这 3 个阶段分别产生 Iterator[PhysicalPlan]、 SparkPlan 和 Prepared SparkPlan,其中 Prepared SparkPlan 可以直接提交并执行(注:这里的 “PhysicalPlan”和“SparkPlan”均表示物理计划) 。

具体来讲,这 3 个阶段所做的工作分别如下:
- 由 SparkPlanner 将各种物理计划策略(Strategy)作用于对应的 LogicalPlan 节点上,生 成 SparkPlan 列表(注: 一个 LogicalPlan 可能产生多种 SparkPlan) 。
- 选取最佳的 SparkPlan,在 Spark2.l 版本中的实现较为简单,在候选列表中直接用 next() 方法获取第一个。
- 提交前进行准备工作,进行一些分区排序方面的处理,确保 SparkPlan 各节点能够正确 执行,这一步通过 prepareForExecution()方法调用若干规则(Rule)进行转换。
SparkPlan
在 SparkSQL 中,物理计划用 SparkPlan表示。在物理算子树中,叶子类 型的 SparkPlan 节点负责呗无到有”地创建 RDD,每个非叶子类型的 SparkPlan 节点等价于在 RDD 上进行一次 Transformation,即通过调用 execute()函数转换成新的 RDD,最终执行 collect() 操作触发计算,返回结果给用户。
SparkPlan 在对 RDD 做 Transformation 的过程中除对数据进行操作外,还可 能对 RDD 的分区做调整。 此外, SparkPlan 除实现 execute 方法外,还有一种情况是直接执行 executeBroadcast 方法,将数据广播到集群上。
具体来看, SparkPlan 的主要功能可以划分为 3 大块。:
- 每个 SparkPlan 节点必不可少地 会记录其元数据(Metadata)与指标(Metric)信息,这些信息以 Key-Value 的形式保存在 Map 数 据结构中,统称为 SparkPlan 的 Metadata 与 Metric 体系。
- 在对 RDD 进行 Transformation 操 作时,会涉及数据分区(Partitioning)与排序(Ordering)的处理,称为 SparkPlan 的 Partitioning与 Ordering 体系;
- 最后, SparkPlan 作为物理计划,支持提交到 Spark Core 去执行,即 SparkPlan 的执行操作部分,以 execute 和 executeBroadcast 方法为主。
分类
Spark SQL 大约包含 65 种具体的 SparkPlan 实现,涉及数据源 RDD 的 创建和各种数据处理等。 根据 SparkPlan 的子节点数目,可以大致将其分为 4 类。 如图 6.3 所示, 分别为 LeafExecNode、 UnaryExecNode、 BinaryExecNode 和其他不属于这 3 种子节点的类型。
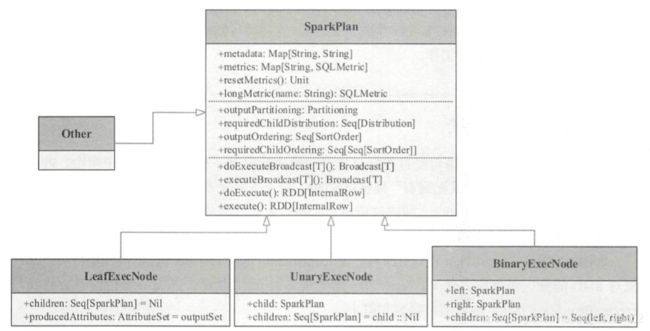
LeafExecNode
叶子节点类型的物理执行计划不存在子节点。物理执行计划中与数据源相关的节点都属 于该类型。 在 Spark SQL 中,叶子节点类型的物理执行计划共有 13 种,如图 6.4 所示。 其中, DataSourceScanExec 作为基类,具体的实现包括 FileSourceScanExec 和 RawDataSourceScanExec 两种。
LeafExecNode 类型的 SparkPlan 负责对初始 RDD 的创建。 例如, RangeExec 会利用 SparkContext 中的 parallelize 方法生成给定范围内的 64位数据的 RDD, HiveTableScanExec 会根据 Hive 数据表存储的 HDFS 信息直接生成 HadoopRDD, FileSourceScanExec 根据数据表所在的源文件 生成 FileScanRDD。
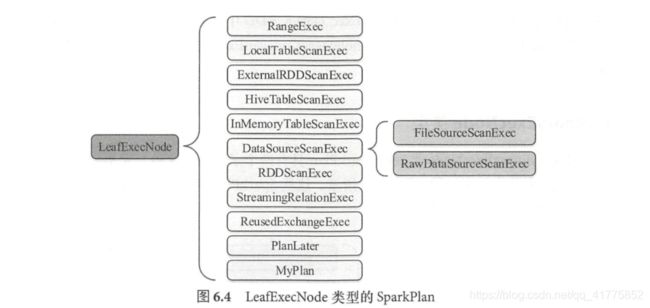
UnaryExecNode
UnaryExecNode 类型的物理执行计划的节点是一元的, 意味着只包含 1 个子节点。 在 Spark 2.1 版本中, UnaryExecNode 类型的物理执行计划共有 37 种。 实际上, UnaryExecNode 类型的物理计划也是数量最多的类型。
UnaryExecNode 节点的作用主要是对 RDD 进行转换操作。例如 ProjectExec 和 FilterExec 分别对子节点产生的 RDD 进行列剪裁与行过滤操作。Exchange 负责对数据进行重分区, SampleExec 对输入 RDD 中的数据进行采样, SortExec 按照一 定条件对输入 RDD 中数据进行排序, WholeStageCodegenExec 类型的 SparkPlan 将生成的代码整合成单个 Java 函数。
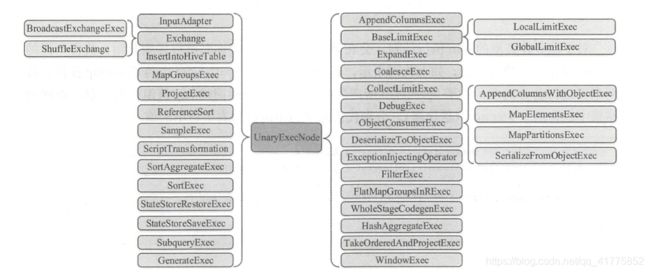
BinaryExecNode
BinaryExecNode 类型的 SparkP!an 具有两个子节点,这种二元类型的物理执行计 划在 SparkSQL 中共定义了 6 种。 这些 SparkP!an 中除 CoGroupExec 外,其余的 5 种都是不同类型的 Join 执行计划。
其他类型的 SparkPlan
除上述 3 种类型的 SparkP!an 外, SparkSQL 中还有 11 个其他类型的物理执行计划。 这 10 种 SparkPlan 中除 CodeGenSupport 和 UnionExec 外,其他几种用到的场景并不多见。

SparkPlanner
SparkPlanner 继承自 SparkStrategies 类,而 SparkStrategies 类则继承自 QueryPlanner基类,重要的 plan() 方法实现就在 QueryPlanner 类中。 SparkStrategies 类本身不提供任何方法,而是在内部提供一 批 SparkPlanner 会用到的各种策略(Strategy)实现。 最后,在 SparkPlanner 层面将这些策略整 合在一起,通过 plan()方法进行逐个应用。

类似逻辑计划阶段的 Anaylzer 和 Optimizer, SparkPlanner 本身只是一个逻辑的驱动, 各种策略的 apply 方法把逻辑执行计划算子映射成物理执行计划算子。
PlanLater
在 SparkPlanner 的调用逻辑和 各种策略中, PlanLater 随处可见。 根据其实现, PlanLater 本身也是 SparkPlan 的一种,区别在于 doExecute()方法没有实现,表示不支持执行,所起到的作用仅仅是占位,等待后续步骤处理。

plan
SparkPlanner的plan(plan: LogicalPlan): Iterator[PhysicalPlan]方法继承于QueryPlanner,其作用是将SparkPlanner和SparkStrategies内定义的SparkStrategy应用于逻辑算子树LogicalPlan,返回一系列物理算子树(不同策略对于LogicalPlan有多种转换方法)。
 首先调用val candidates = strategies.iterator.flatMap(_(plan))
首先调用val candidates = strategies.iterator.flatMap(_(plan))
将strategies中的所有strategy分别应用到plan上,返回各个strategy的应用结果集合candidates。
_(plan)代表调用SparkStrategy :def apply(plan: LogicalPlan) = Seq[SparkPlan]函数,其返回SparkStrategy策略应用到LogicalPlan逻辑计划生成的Seq[SparkPlan]物理计划集。
SparkStrategy.apply
我们选取object BasicOperators extends Strategy为例,其apply函数如下:



由于这个这个模式匹配非常长,所以这里直截取了一部分。apply方法对传入的LogicalPlan进行模式匹配。可以看到对于不同类型的LogicalPlan会利用LogicalPlan的构造参数创建生成对应类型的SparkPlan返回。
可以明显的看到生成的大部分SparkPlan的构造函数中都出现了planLater函数。
![]()
planLater函数是将LogicalPlan作为参数,生成占位符式的SparkPlan,代表需要之后在进行解析。planLater函数的作用是将当前LogicalPlan的子LogicalPlan包装成PlanLater,作为创建生成的SparkPlan的子SparkPlan。
所以可以看出apply(plan:LogicalPlan)函数只将SparkStrategy应用于传入的参数LogicalPlan,但是对于LogicalPlan的子LogicalPlan节点却不会应用,而是生成占位符PlanLater,作为返回结果的子SparkPlan(对于多个子LogicalPlan节点生成多个子SparkPlan)。
collectPlaceholders
当讲所有的strategies分别应用于LogicalPlan之后,获得了候选物理计划列表candidates 。对于其中的每一个候选物理计划,执行collectPlaceholders函数,获取所有的占位符PlanLater。

物理计划plan调用collect函数(其函数继承自TreeNode,会将后面的后面的函数应用于树中的所有节点,将结果放在一个数组中)。所以collectPlaceholders返回SparkPlan子节点中的所有(占位符PlanLater,其包含的逻辑计划LogicalPlan)元组,即placeholders。
placeholders解析
如果placeholders为空,则说明物理算子树中已经全部经过转换了,没有占位符PlanLater。
如果不为空,则说明有占位符PlanLater,需要继续进行逻辑计划转换。

遍历placeholders,传入候选物理计划candidate参数,使用foldLeft函数:
利用plan()方法,转换占位符PlanLater中包含的LogicalPlan,返回解析转换之后的物理计划集合。然后要将候选物理计划candidatesWithPlaceholders(在这个局部中candidate重新命名为candidatesWithPlaceholders)中相应的占位符PlanLater替换成已经解析成物理计划的chidPlan。
由于一个逻辑计划logicalPlan解析生成了多个物理计划childPlans 。所以要将childPlans中的所有物理计划都使用一次。对于candidatesWithPlaceholders中的每一个candidateWithPlaceholders,对其调用transformUp函数,将物理算子树中的对应的PlanLater替换成chidPlan。即一个candidatesWithPlaceholders需要尝试每一个childPlan去替换树中的PlanLater。
prunePlans
经过上一步的placeholders解析,将物理算子树中的所有占位符PlanLater转换成SparkPlan,生成了物理计划集plans。接着调用prunePlans,但是spark-2.4.4中并没有实现该函数。

总结
逻辑算子树转换成物理算子树的过程:
- SparkPlanner调用plan(plan: LogicalPlan): Iterator[PhysicalPlan],传入逻辑算子树的根节点,最后返回物理计划集。
- plan函数中,首先将所有定义的SparkStrategy分别应用于LogicalPlan。每一个单独的SparkStrategy应用都会返回Seq[SparkPlan]。最后合并组成候选物理计划集。
- 但是在2中SparkStrategy应用,只会将当前LogicalPlan转换为SparkPlan,其子LogicalPlan节点不会应用SparkStrategy转换,而封装成PlanLater作为子SparkPlan等待之后的转换。
- 使用collectPlaceholders获取候选物理计划的所有占位符PlanLater。提取PlanLater中的LogicalPlan,利用plan函数,将其转换为子物理计划集。
- 由于一个逻辑计划可以转换为多个物理计划。所以需要尝试使用所有生成的子物理计划,去替代候选物理计划中的PlanLater占位符,得到多个新的候选物理计划。
- 当对collectPlaceholders中的所有占位符PlanLater进行提取、转换、替换之后,候选物理计划集中的SparkPlan中已经没有占位符PlanLater。逻辑计划全部转换为物理计划。生成物理计划集。