azure模型训练_如何在Azure Machine Learning Studio上开发K-Means模型
azure模型训练
In this article, we will discuss the k-means algorithm and how can we develop a k-means model on Azure Machine Learning Studio.
在本文中,我们将讨论k-means算法以及如何在Azure Machine Learning Studio上开发k-means模型。
Machine learning is an area of artificial intelligence that helps us develop relationships between data and predict the future. There are many secrets that are hidden in the data. To discover these secrets, we need Machine Learning algorithms. Machine learning plays the key role in leveraging existing data to exploit business opportunities.
机器学习是人工智能的一个领域,可帮助我们发展数据之间的关系并预测未来。 数据中隐藏了许多秘密。 要发现这些秘密,我们需要机器学习算法。 机器学习在利用现有数据来利用商机方面发挥着关键作用。
In this paragraph, we will discuss about the K-Means algorithm definition and how it works. The K-Means algorithm is one of the simple, unsupervised (As per Wikipedia : Unsupervised machine learning is the machine learning task of inferring a function to describe hidden structure from “unlabeled” data “a classification or categorization is not included in the observations”.) machine learning algorithms that solves the clustering problem. The K-means algorithm helps us to divide groups of our datasets which hold similar attributes or properties. These groups show the characteristics of the dataset and identify abnormal character data.
在这一段中,我们将讨论K-Means算法的定义及其工作方式。 K-Means算法是一种简单的,无监督的算法( 如Wikipedia所述 :无监督的机器学习是一种机器学习任务,可以从“未标记的”数据中推断出一种描述隐藏结构的功能,“观察中不包括分类或分类”。 。)解决聚类问题的机器学习算法。 K均值算法可帮助我们划分具有相似属性或属性的数据集组。 这些组显示数据集的特征并识别异常字符数据。
In short, the algorithm works like this, cluster centers (aka centroids) are determined at the beginning of algorithm. Then we calculate the distance between each object and each centroid. After this step, each object will be assigned to the nearest centroid. When the assignment is completed, algorithm recalculates the cluster centers and reassigns the data to the new centroid. If the cluster centers don’t change algorithm stop works.
简而言之,算法像这样工作,在算法开始时就确定了聚类中心(又名质心) 。 然后,我们计算每个对象与每个质心之间的距离。 完成此步骤后,会将每个对象分配给最近的质心。 分配完成后,算法将重新计算聚类中心并将数据重新分配给新的质心。 如果群集中心不更改,算法将停止工作。
The main steps in the k-means algorithm are:
k均值算法的主要步骤是:
- Define centroids (the k letter defines how many centroids will be selected) 定义质心(k字母定义将选择多少个质心)
- Assign samples 分配样品
- Re-calculate centroids 重新计算质心
- Re-assign samples 重新分配样品

实验 ( Experiment)
First, we will login into Azure Machine Learning Studio. Azure Machine Learning Studio has different types of subscriptions. You can use any one of them. I will use a free account. We will use countries protein consumption statistics csv dataset. This data set includes how to countries meet their protein needs.
首先,我们将登录到Azure Machine Learning Studio 。 Azure Machine Learning Studio具有不同类型的订阅。 您可以使用其中任何一个。 我将使用一个免费帐户。 我们将使用国家蛋白质消费统计数据csv 数据集 。 该数据集包括各国如何满足其蛋白质需求。
This experiment will demonstrate how to model K-Means algorithm in Azure Machine Learning. Our goal in this experiment is to group the countries which have similar eating habits. Especially we want to determine which countries white meat and red meat eating habits are similar.
该实验将演示如何在Azure机器学习中为K-Means算法建模。 我们在此实验中的目标是将饮食习惯相似的国家/地区分组。 特别是我们要确定哪个国家的白肉和红肉的饮食习惯相似。
The key point is to group the data that may be related to each other. For example, shoe size may be related to gender, but there is no relationship between shoe size and eye color.
关键是对可能彼此相关的数据进行分组。 例如,鞋子的尺码可能与性别有关,但是鞋子的尺码和眼睛的颜色之间没有关系。
In first step we will load a csv dataset. We will select Datasets tab and add new dataset.
第一步,我们将加载一个csv数据集。 我们将选择“数据集”选项卡并添加新的数据集。

After this step we will load protein.csv file.
完成此步骤后,我们将加载protein.csv文件。


Now we will create a new experiment.
现在,我们将创建一个新实验。


In the right side of the canvas screen, we can find all of the statistical functions, data transformation, and similar components. We can find SAVE, SAVE AS and RUN button below of screen. We can also find clicked component properties. Now, we will create an empty experiment and then add protein.csv dataset.
在画布屏幕的右侧,我们可以找到所有统计功能,数据转换和类似组件。 我们可以在屏幕下方找到SAVE,SAVE AS和RUN按钮。 我们还可以找到单击的组件属性。 现在,我们将创建一个空实验,然后添加protein.csv数据集。

In this screen, we are able to look at the dataset and analyze main statistic values of columns
在此屏幕中,我们可以查看数据集并分析列的主要统计值


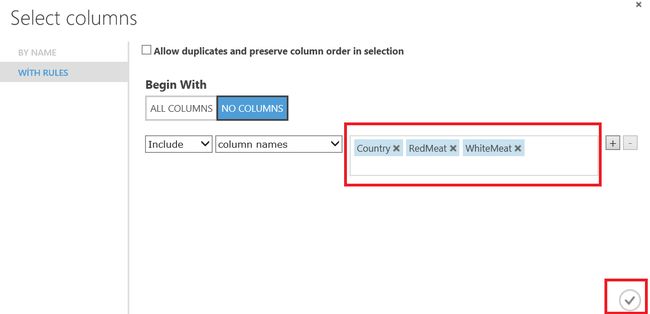
In the next step, we will add Select columns in dataset component and we will chose the columns which we think related to each other. This component will help us to limit columns or reduce the size of dataset. In this example we will chose country, redmeat and whitemeat columns.
在下一步中,我们将在数据集组件中添加选择列,然后选择我们认为彼此相关的列。 该组件将帮助我们限制列数或减少数据集的大小。 在此示例中,我们将选择country , redmeat和whitemeat列。


We will add the Train clustering model component and K-means clustering model components and then we will select columns for our k-means algorithm model on the train cluster model
我们将添加Train聚类模型组件和K-means聚类模型组件,然后在火车聚类模型上为k-means算法模型选择列

The Azure Machine Learning k-means clustering model offers many properties about the k-means algorithm.
Azure机器学习k均值群集模型提供了有关k均值算法的许多属性。
If we select a single parameter model, we can set the number of centroids. This value defines how many clusters we want to create. But how do we choose our k parameter? Azure Machine learning consists a helper component for this which is named “Sweep Clustering”. This component can help us to find the optimal parameters for our clustering model. We will learn the usage of this component at the end of the article.
如果选择单个参数模型,则可以设置质心数。 该值定义了我们要创建的集群数量。 但是我们如何选择k参数呢? Azure机器学习为此包含一个帮助程序组件,该组件称为“ 扫描群集 ”。 该组件可以帮助我们为聚类模型找到最佳参数。 我们将在本文结尾处学习该组件的用法。
The initialization parameter defines different types of k-means algorithms. The Iterations value defines how many times the k-means algorithm assigns values to clusters.
初始化参数定义了不同类型的k均值算法。 迭代值定义k均值算法将值分配给群集的次数。
In this example, we will use default parameters. When we run our model we must have all components checked green. It means our model has worked successfully.
在此示例中,我们将使用默认参数。 运行模型时,必须将所有组件检查为绿色。 这意味着我们的模型已经成功运行。

In this next step, we analyze our model result. When we right click the Train clustering model we are able to see a cluster separation diagram. In our example, we will see two clusters.
在下一步中,我们分析模型结果。 当我们右键单击Train聚类模型时,我们可以看到一个聚类分离图。 在我们的示例中,我们将看到两个群集。

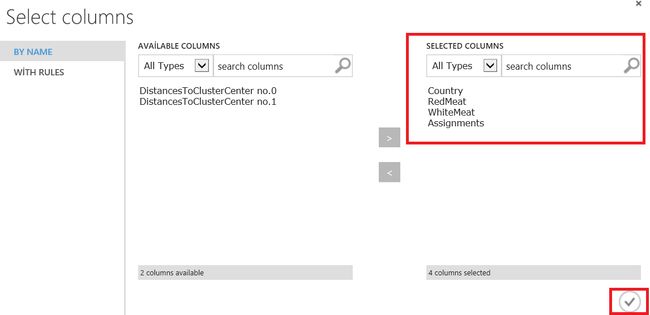
But this diagram is not enough to analyze our dataset, it only defines how many times the dataset has been separated. Now we will add Select columns in the dataset and connect it to the Train clustering model results dataset. After that, we will select columns and assignment of rows.
但是此图不足以分析我们的数据集,它仅定义了数据集被分离了多少次。 现在,我们将在数据集中添加“ 选择”列 ,并将其连接到Train聚类模型结果数据集。 之后,我们将选择列和行分配。

Now we run our model and look at the results of our model.
现在,我们运行我们的模型,并查看模型的结果。

In the below chart, we can see the assignment of dataset rows.
在下图中,我们可以看到数据集行的分配。
In this part of our example, we will examine our k-means algorithm. Now we will add Edit metadata and connect it to our Train clustering model result dataset. Then we will add columns for the Edit metadata.
在示例的这一部分,我们将研究k-means算法。 现在,我们将添加“编辑”元数据并将其连接到我们的Train聚类模型结果数据集。 然后,我们将为“ 编辑”元数据添加列。


Next, we will right-click Edit metadata and visualize. We will compare White Meat and assignments and it will create a plot box graphic.
接下来,我们将右键单击“ 编辑元数据并进行可视化”。 我们将比较白肉和任务,它将创建一个绘图框图形。

When we look at the above chart, it demonstrates the main idea of our k-means algorithm. The K-means algorithm separates white meat consumption into two clusters. We can see this clusters in the plot box chart it shows two (“0”, “1”) values in x axis.
当我们看上图时,它展示了我们的k均值算法的主要思想。 K-means算法将白肉的消费分为两个类。 我们可以在绘图框图中看到该群集,它在x轴上显示了两个(“ 0”,“ 1”)值。
When we compare to the country column to assignments our chart will be changed.
当我们将“国家/地区”列与分配进行比较时,我们的图表将被更改。

When we look at the above chart, we can see countries cluster assignments. The goal of the experiment is to predict the closest outputs to the real. For this reason, we will add sweep clustering component to our model and make some changes for more accuracy. We will hook up K-Means algorithm to sweep clustering and change k-means clustering property of creating trainer mode to parameter range.
当我们查看上图时,我们可以看到国家/地区群集分配。 实验的目的是预测最接近真实值的输出。 因此,我们将扫描聚类组件添加到模型中,并进行一些更改以提高准确性。 我们将使用K-Means算法进行扫描聚类,并将创建训练器模式的k-means聚类属性更改为参数范围。
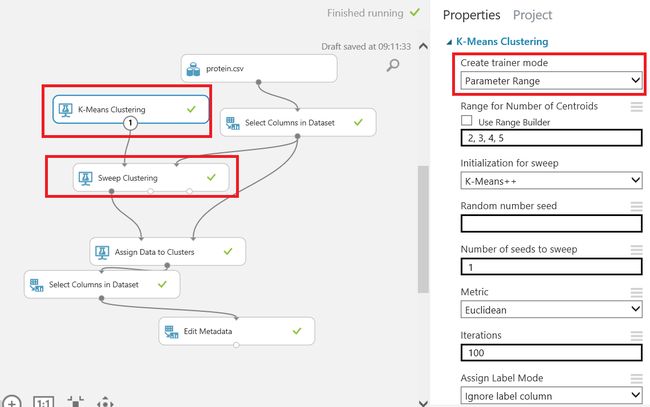
And we will connect sweep clustering best training output to assign clusters because we want get more accuracy about our dataset. When we look at the assign data clusters to it will create three clusters.
我们将把扫描聚类的最佳训练输出连接到分配聚类,因为我们希望获得有关数据集的更多准确性。 当我们查看分配数据集群时,将创建三个集群。

So we have seen that the optimal number of groups for our data set is three. Because sweep clustering component tests some iterations and decide the optimal parameter.
因此,我们已经看到,针对我们的数据集的最佳组数为3。 因为扫描聚类组件会测试一些迭代并确定最佳参数。
结论 (Conclusion)
In this article, we learned K-Means algorithm and usage in Azure Machine Learning. We created a very simple example. On Azure Machine Learning side we have seen that it is not too difficult to use some basic machine learning algorithms.
在本文中,我们学习了Azure机器学习中的K-Means算法及其用法。 我们创建了一个非常简单的示例。 在Azure机器学习方面,我们已经看到使用一些基本的机器学习算法并不太困难。
翻译自: https://www.sqlshack.com/develop-k-means-model-azure-machine-learning-studio/
azure模型训练