YOLOv8改进 | SAConv可切换空洞卷积(附修改后的C2f+Bottleneck)

论文地址:官方论文地址
代码地址:官方代码地址

一、本文介绍
本文给大家带来的改进机制是可切换的空洞卷积(Switchable Atrous Convolution, SAC)是一种创新的卷积网络机制,专为增强物体检测和分割任务中的特征提取而设计。SAC的核心思想是在相同的输入特征上应用不同的空洞率进行卷积,并通过特别设计的开关函数来融合这些不同卷积的结果。这种方法使得网络能够更灵活地适应不同尺度的特征,从而更准确地识别和分割图像中的物体。 通过本文你能够了解到:可切换的空洞卷积的基本原理和框架,能够在你自己的网络结构中进行添加(值得一提的是一个SAConv大概可以降低0.3GFLOPs)。
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
实验效果对比->
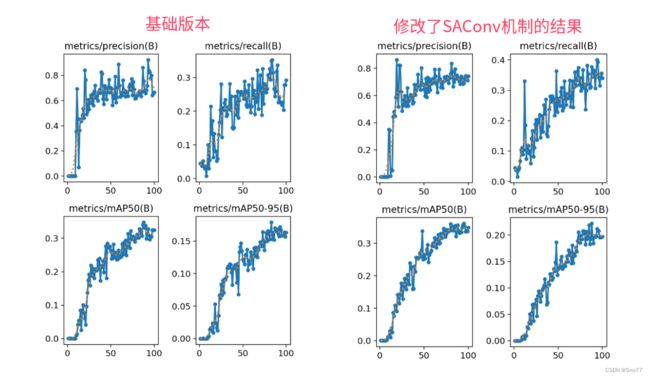
因为资源有限我发的文章都要做对比实验所以本次实验我只用了一百张图片检测的是安全帽训练了一百个epoch,该结果只能展示出该机制有效,但是并不能产生决定性结果,因为具体的效果还要看你的数据集和实验环境所影响。
下图分析->这个SAConv精度提升是有一定效果的,但是其主要的优势我在于是可以减少参数量和轻量化的作用。
目录
一、本文介绍
二、SAConv的机制原理介绍
三、SAConv代码复现
3.1 SAConv
3.2 替换SAConv的C2f和Bottleneck
四、手把手教你添加SAConv
4.1 SAConv的添加教程
4.2 SAConv的yaml文件和训练截图
5.2.1 SAConv的yaml文件
5.2.2 SAConv的训练过程截图
五、SAConv可添加的位置
5.1 推荐SAConv可添加的位置
5.2图示LSKAttention可添加的位置
六、本文总结
二、SAConv的机制原理介绍
可切换的空洞卷积(Switchable Atrous Convolution,简称SAC)是一种高级的卷积机制,用于在物体检测和分割任务中增强特征提取。以下是SAC的主要原理和机制:
1. 不同空洞率的应用: SAC的核心思想是对相同的输入特征应用不同的空洞率进行卷积。空洞卷积通过在卷积核中引入额外的空间(即空洞),扩大了感受野,而不增加参数数量或计算量。SAC利用这一点来捕获不同尺度的特征。
2. 开关函数的使用: SAC的另一个关键特点是使用开关函数来组合不同空洞率卷积的结果。这些开关函数是空间依赖的,意味着特征图的每个位置可能有不同的开关来控制SAC的输出,从而使网络对于特征的大小和尺度更加灵活。
3. 转换机制: SAC能够将传统的卷积层转换为SAC层。这是通过在不同空洞率的卷积操作中使用相同的权重(除了一个可训练的差异)来实现的。这种转换机制包括一个平均池化层和一个1x1卷积层,以实现开关功能。
4. 结构设计: SAC的架构包括三个主要部分:两个全局上下文模块分别位于SAC组件的前后。这些模块有助于更全面地理解图像内容,使SAC组件能够在更宽泛的上下文中有效地工作。
总结:SAC通过这些创新的设计和机制,提高了网络在处理不同尺度和复杂度的特征时的适应性和准确性,从而在物体检测和分割领域显示出显著的性能提升。
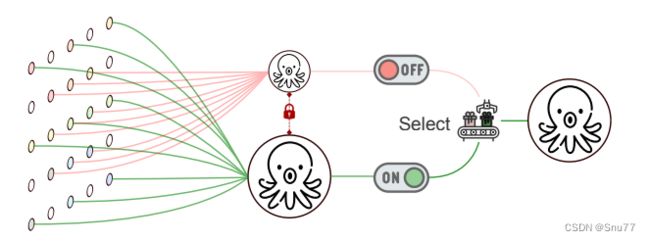
上图我们能看到其中的关键点如下->
-
双重观察机制: SAC特别设计了一种机制,它能够对输入特征进行两次观察,但每次使用不同的空洞率。这意味着,同一组输入特征会被两种不同配置的卷积核处理,其中每种配置对应一种特定的空洞率。这样做可以捕获不同尺度的特征信息,从而更全面地理解和分析输入数据。
-
开关函数的应用: 不同空洞率得到的输出结果随后通过开关函数结合在一起。这些开关决定了如何从两次卷积中选择或融合信息,从而生成最终的输出特征。开关的运作方式可能依赖于特征本身的特性,如其空间位置等。
总结:SAC通过这种“双重观察并结合”的策略,能够有效地处理复杂的特征模式,特别是在尺度变化较大的情况下。这种方法不仅提高了特征提取的灵活性和适应性,而且还提升了物体检测和分割任务中的准确性和效率。
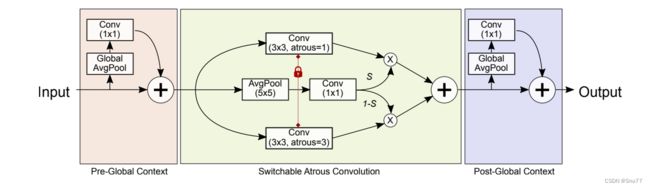
在上图中展示了可切换的空洞卷积(Switchable Atrous Convolution, SAC)的具体实现方式。这里的关键点包括:
-
转换传统卷积层为SAC: 他们将骨干网络ResNet中的每一个3x3卷积层都转换为SAC。这种转换使得卷积计算可以在不同的空洞率之间软切换。
-
权重共享与训练差异: 重要的一点是,尽管SAC在不同的空洞率间进行切换,但所有这些操作共享相同的权重,只有一个可训练的差异。这种设计减少了模型复杂性,同时保持了灵活性。
-
全局上下文模块: SAC结构还包括两个全局上下文模块,这些模块为特征添加了图像级的信息。全局上下文模块有助于网络更好地理解和处理图像的整体内容,从而提高特征提取的质量和准确性。
总结:SAC通过这些机制,允许网络在不同的空洞率之间灵活切换,同时通过全局上下文模块和共享权重的策略,有效地提升了特征的提取和处理能力。这些特性使得SAC在物体检测和分割任务中表现出色。
下面是部分的检测效果图->
三、SAConv代码复现
3.1 SAConv
import torch
import torch.nn as nn
from ultralytics.nn.modules.conv import autopad, Conv
class ConvAWS2d(nn.Conv2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias)
self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))
self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))
def _get_weight(self, weight):
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
weight = weight / std
weight = self.weight_gamma * weight + self.weight_beta
return weight
def forward(self, x):
weight = self._get_weight(self.weight)
return super()._conv_forward(x, weight, None)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
self.weight_gamma.data.fill_(-1)
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
if self.weight_gamma.data.mean() > 0:
return
weight = self.weight.data
weight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
self.weight_beta.data.copy_(weight_mean)
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
self.weight_gamma.data.copy_(std)
class SAConv2d(ConvAWS2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
s=1,
p=None,
g=1,
d=1,
act=True,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=s,
padding=autopad(kernel_size, p, d),
dilation=d,
groups=g,
bias=bias)
self.switch = torch.nn.Conv2d(
self.in_channels,
1,
kernel_size=1,
stride=s,
bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
self.pre_context = torch.nn.Conv2d(
self.in_channels,
self.in_channels,
kernel_size=1,
bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels,
self.out_channels,
kernel_size=1,
bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
self.bn = nn.BatchNorm2d(out_channels)
self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
# pre-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# switch
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# sac
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# post-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))
3.2 替换SAConv的C2f和Bottleneck
class Bottleneck_SAConv(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = SAConv2d(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_SAConv(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_SAConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
# y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))四、手把手教你添加SAConv
4.1 SAConv的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
这个卷积也可以放在C2f和Bottleneck中进行使用可以即插即用,个人觉得放在Bottleneck中效果比较好。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.2 SAConv的yaml文件和训练截图
5.2.1 SAConv的yaml文件
下面的是放在Neck部分的截图,参数我以及设定好了,无需进行传入会根据模型输入自动计算,帮助大家省了一些事。
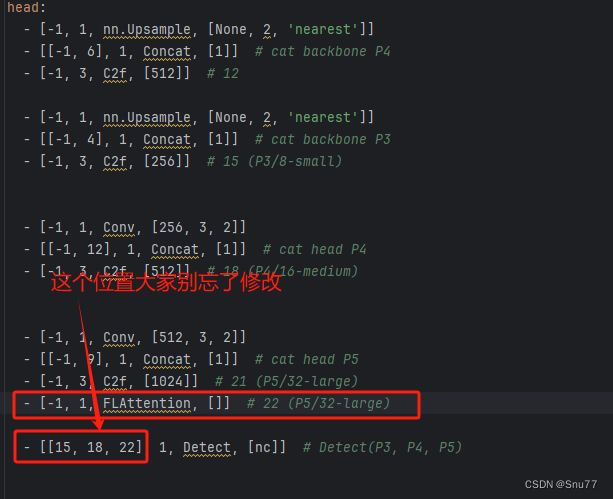
下面的是放在C2f中的yaml配置。

5.2.2 SAConv的训练过程截图
下面是添加了SAConv的训练截图。
下面的是将SAConv机制添加到了C2f和Bottleneck。
五、SAConv可添加的位置
5.1 推荐SAConv可添加的位置
SAConv可以是一种即插即用的卷积,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入SAConv
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的C2f和SAConv可以帮助模型更有效地融合不同层次的特征。
检测头中的卷积:在最终的输出层前加入SAConv可以使模型在做出最终预测之前,更加集中注意力于最关键的特征。
文字大家可能看我描述不太懂,大家可以看下面的网络结构图中我进行了标注。
5.2图示LSKAttention可添加的位置
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备