Centos7 Ceph mimic 版部署实践(CephFS)
最小化配置需要1台ceph管理节点,三台物理机作为ceph节点
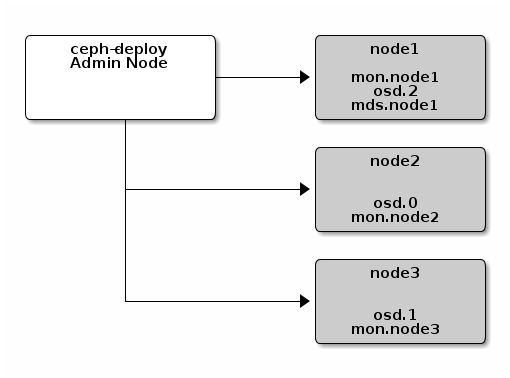 官方多集群扩容图
官方多集群扩容图
2 物理机配置team网络配置(主要讲述物理机网卡team聚合配置方式,如不需要做网卡聚合,可跳过)
a.查看所有的网络连接

b.创建 team 口 , 绑定网卡名team0
nmcli connection add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'说明:
按照下面的语法,用 nmcli 命令为网络组接口创建一个连接。
nmcli con add type team con-name CNAME ifname INAME [config JSON]CNAME 指代连接的名称,INAME 是接口名称,JSON (JavaScript Object Notation) 指定所使用的处理器(runner)。JSON语法格式如下:
'{"runner":{"name":"METHOD"}}'METHOD 是以下的其中一个:broadcast、activebackup、roundrobin、loadbalance 或者 lacp,若想改变team的模式可以编辑/etc/sysconfig/network-scripts/ifcfg-team0,在里面更改模式,改完之后我们要用nmcli connection reload 来识别,然后再重启以此网络服务 systemctl restart network 即可。
c.给team0 配置IP Gateway DNS
nmcli connection modify team0 ipv4.addresses "192.168.126.132/24"
nmcli connection modify team0 ipv4.gateway "192.168.126.1"
nmcli connection modify team0 ipv4.dns "192.168.126.1" #如没有内网dns可设置公网
nmcli connection modify team0 ipv4.method manuald.将 p3p1 p3p2 加入team0
nmcli connection add type team-slave con-name team0-port1 ifname p3p1 master team0
nmcli connection add type team-slave con-name team0-port2 ifname p3p2 master team0e.激活team0
nmcli connection up team0
nmcli connection up team0-port1
nmcli connection up team0-port2f.验证
nmcli connection show
teamdctl team0 state view
#执行down命令,确认ping命令是否有丢包,正常情况丢5~6个包,或不丢包
nmcli connection down team0-port1
3 ceph部署初始化工作
a.ceph机器系统配置
#每个节点修改主机名
hostnamectl set-hostname ceph-admin
hostnamectl set-hostname ceph-node1
hostnamectl set-hostname ceph-node2
hostnamectl set-hostname ceph-node3
#每个节点绑定主机名映射
# cat /etc/hosts
192.168.126.130 ceph-admin
192.168.126.132 ceph-node1
192.168.126.133 ceph-node2
192.168.126.131 ceph-node3
#每个节点确认连通性
ping -c 3 ceph-admin
ping -c 3 ceph-node1
ping -c 3 ceph-node2
ping -c 3 ceph-node3
#每个节点关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
#每个节点安装和配置NTP(官方推荐的是集群的所有节点全部安装并配置 NTP,需要保证各节点的系统时间一致。没有自己部署ntp服务器,就在线同步NTP)
yum install ntp ntpdate ntp-doc -y
systemctl restart ntpd
systemctl status ntpdb.ceph源配置
每个节点准备yum源
删除默认的源,国外的比较慢
yum clean all
mkdir /mnt/bak
#移除前确认wget命令已安装
mv /etc/yum.repos.d/* /mnt/bak/
#下载阿里云的base源和epel源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
添加ceph源(注意rpm-mimic确认是哪一个版本则用哪一个版本源)
vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
gpgcheck=0
priority =1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
gpgcheck=0
priority =1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS
gpgcheck=0
priority=1c.ceph免密配置
配置相互间的ssh信任关系
现在ceph-admin节点上产生公私钥文件,然后将ceph-admin节点的.ssh目录拷贝给其他节点
[cephuser@ceph-admin ~]$ ssh-keygen -t rsa #一路回车
[cephuser@ceph-admin ~]$ cd .ssh/
[cephuser@ceph-admin .ssh]$ ls
id_rsa id_rsa.pub
#分发秘钥
ssh-copy-id root@ceph-node1
ssh-copy-id root@ceph-node2
ssh-copy-id root@ceph-node34 ceph部署
a.ceph-deploy 部署
#ceph-admin节点上使用ceph-deploy快速部署
#安装ceph-deploy
sudo yum update -y && sudo yum install ceph-deploy -y
#创建cluster目录
cd root&&mkdir cluster
cd cluster/
#如果ceph-deploy new ceph-node1这步出现报错:
ImportError: No module named pkg_resources
wget -O /usr/local/src/distribute-0.7.3.zip https://files.pythonhosted.org/packages/5f/ad/1fde06877a8d7d5c9b60eff7de2d452f639916ae1d48f0b8f97bf97e570a/distribute-0.7.3.zip
cd /usr/local/src/
unzip distribute-0.7.3.zip
python setup.py install
#创建集群(后面填写monit节点的主机名,这里monit节点和管理节点是同一台机器,生产环境最好部署3个mon节点,在/root/cluster)
ceph-deploy new ceph-node1 ceph-node2 ceph-node3
#此时只是在/root/cluster 目录下生成了配置文件
vi /root/cluster/ceph.conf
[global]
fsid = f14af78b-2869-4e43-9184-57e8b63a0c89
mon_initial_members = ceph-node1, ceph-node2, ceph-node3
mon_host = 192.168.126.132,192.168.126.133,192.168.126.131
public_network= 192.168.126.0/24 #添加改配置
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
#安装ceph(过程有点长,需要等待一段时间....)
ceph-deploy install ceph-admin ceph-node1 ceph-node2 ceph-node3b.ceph mon节点部署
ceph-deploy mon create-initial
#完成上述操作后,当前目录里应该会出现这些密钥环:
[root@ceph-admin cluster]# ll *.keyring
-rw------- 1 root root 113 May 5 11:57 ceph.bootstrap-mds.keyring
-rw------- 1 root root 113 May 5 11:57 ceph.bootstrap-mgr.keyring
-rw------- 1 root root 113 May 5 11:57 ceph.bootstrap-osd.keyring
-rw------- 1 root root 113 May 5 11:57 ceph.bootstrap-rgw.keyring
-rw------- 1 root root 151 May 5 11:57 ceph.client.admin.keyring
-rw------- 1 root root 73 May 5 11:44 ceph.mon.keyring
#将相关配置文件以及key推送至各个节点
ceph-deploy admin ceph-admin ceph-node1 ceph-node2 ceph-node3
#mon节点部署成功后可以通过 ceph -s 命令查看集群状况
 集群状态显示
集群状态显示
c.ceph osd节点部署
#查看node节点的disk
ceph-deploy disk list ceph-node1 ceph-node2 ceph-node3
#依次创建 osd
ceph-deploy osd create ceph-node1 --data /dev/sdb
ceph-deploy osd create ceph-node2 --data /dev/sdb
ceph-deploy osd create ceph-node3 --data /dev/sdb
ceph-deploy osd create ceph-node1 --data /dev/sdc
ceph-deploy osd create ceph-node2 --data /dev/sdc
ceph-deploy osd create ceph-node3 --data /dev/sdc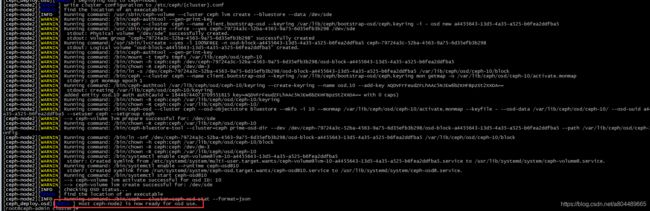 osd创建成功的显示
osd创建成功的显示
d.ceph mgr部署
ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
#集群ceph正常
[root@ceph-admin cluster]# ceph -s
cluster:
id: f14af78b-2869-4e43-9184-57e8b63a0c89
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node3,ceph-node1,ceph-node2
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
osd: 6 osds: 6 up, 6 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 24 GiB / 30 GiB availe.ceph mds部署
PG, Placement Groups。CRUSH先将数据分解成一组对象,然后根据对象名称、复制级别和系统中的PG数等信息执行散列操作,再将结果生成PG ID。可以将PG看做一个逻辑容器,这个容器包含多个对象,同时这个逻辑对象映射之多个OSD上,如果没有PG,在成千上万个OSD上管理和跟踪数百万计的对象的复制和传播是相当困难的。没有PG这一层,管理海量的对象所消耗的计算资源也是不可想象的。建议每个OSD上配置50~100个PG。
创建pool前的pg计算规则:
Ceph集群中的PG总数:
PG总数 = (OSD总数 * 100) / 最大副本数 #结果必须舍入到最接近的2的N次方幂的值
Ceph集群中的PG总数:
PG总数 = (OSD总数 * 100) / 最大副本数 #结果必须舍入到最接近的2的N次方幂的值
Ceph集群中每个pool中的PG总数:
存储池PG总数 = (OSD总数 * 100 / 最大副本数) / 池数
#创建元数据服务器(操作在/root/cluster 目录下进行)
ceph-deploy mds create ceph-node1 ceph-node2 ceph-node3
#创建pool
ceph osd pool create cephfs_data 64
ceph osd pool create cephfs_metadata 64
#创建cephFS
ceph fs new cephfs cephfs_metadata cephfs_data
#查看cephFS创建情况
[root@ceph-admin cluster]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@ceph-admin cluster]# ceph -s
cluster:
id: f14af78b-2869-4e43-9184-57e8b63a0c89
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node3,ceph-node1,ceph-node2
mgr: ceph-node1(active), standbys: ceph-node2, ceph-node3
mds: cephfs-1/1/1 up {0=ceph-node3=up:active}, 2 up:standby
osd: 6 osds: 6 up, 6 in
data:
pools: 2 pools, 128 pgs
objects: 22 objects, 2.2 KiB
usage: 6.0 GiB used, 24 GiB / 30 GiB avail
pgs: 128 active+clean
5 ceph挂载
#客户端创建挂载目录(使用内核挂载)
mkdir /mnt/cephfs
#手动创建 admin.secret 文件
[root@ceph-admin ceph]# cat admin.secret
AQAb5LBeLEYYBBAAY22iYiym8DYlLlvT7u6sJg==
[root@ceph-admin ceph]# cat ceph.client.admin.keyring
[client.admin]
key = ***客户端使用秘钥*******
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
#使用secretfile挂载
mount -t ceph 192.168.0.1:6789:/ /mnt/mycephfs -o name=admin,secretfile=/etc/ceph/admin.secret
6 开启ceph dashboard
ceph L版本以上有集成的DashBoard,开启后可以进行相关管理,官网参考链接:https://docs.ceph.com/docs/master/mgr/dashboard/。
ceph mgr module enable dashboard #开启dashboard模块
ceph config-key set mgr/dashboard/server_port 8080 #确定开启访问8080端口
ceph config-key set mgr/dashboard/server_addr $IP #确定访问的mgr ip不要设置为管理节点ip,需要设置在mgr进程的节点上
ceph config set mgr mgr/dashboard/ssl false #取消https访问,如果是内网,可以建议取消
#重启进程
ceph mgr module disable dashboard
ceph mgr module enable dashboard
#设置访问密码
ceph dashboard set-login-credentials 完成上述操作后可以打开http://$IP:8080即可访问dashboard。
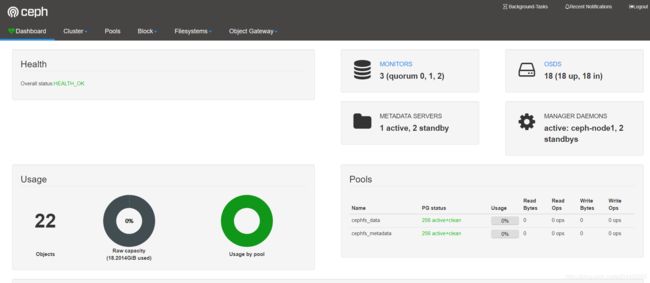 ceph Dashboard
ceph Dashboard
7 相关报错信息汇总
1 ceph12.2.5节点重装后创建osd报错:
stderr: Can't open /dev/sdb exclusively. Mounted filesystem?
处理方式:
dmsetup status #查看
ceph--1a5287f5--7797--4c89--bd42--71843d3569a2-osd--block--30491242--d118--4c0b--81f3--a35b28b276d2: 0 1953521664 linear
ceph--e364bd1c--9f46--40bc--9d38--dbe7f54a437d-osd--block--5bc54311--cc5f--4c4c--bda7--207fa1ecfd7f: 0 1953521664 linear
ll /dev/mapper/
total 0
lrwxrwxrwx 1 root root 7 Apr 26 09:58 ceph--1a5287f5--7797--4c89--bd42--71843d3569a2-osd--block--30491242--d118--4c0b--81f3--a35b28b276d2 -> ../dm-0
lrwxrwxrwx 1 root root 7 Apr 26 10:00 ceph--e364bd1c--9f46--40bc--9d38--dbe7f54a437d-osd--block--5bc54311--cc5f--4c4c--bda7--207fa1ecfd7f -> ../dm-1
crw------- 1 root root 10, 236 Apr 26 2018 control
#删除ceph的文件
dmsetup remove ceph--38c8c2c4--df3a--4522--8c81--6cf1ff8a174b-osd--block--77fe2629--e50b--4ad9--8c46--057995436e3b ceph--8a07121e--c010--473f--9a63--0e209ccc935d-osd--block--8085d377--5024--4848--b696--fa47334b2feb ceph--b3958863--98c0--4f38--be72--f4e8f8905440-osd--block--ca201fff--95eb--4ce8--9ddf--83ebfe44b8fa
mkfs.xfs -f /dev/sdb #这时格式化成功,可以重新创建osd节点了,一定要执行这个步骤2 在虚拟机做实验时,如果用作osd的磁盘过小,会报错 _read_fsid unparsable uuid(磁盘需要最小是5G)
3 创建ceph-deploy osd create ceph-node1 --data /dev/sdb 时如果出现以下错误,我们要手动清理掉硬盘的分区表 (当然如果硬盘是全新的, 这里应该就成功了).
 创建osd报错截图
创建osd报错截图
处理方式:
#手动清理
dd if=/dev/zero of=/dev/sdb bs=512K count=1
1+0 records in
1+0 records out
524288 bytes (524 kB) copied, 0.00109677 s, 478 MB/s
#清理后即可创建成功结语
官方建议cephFS生产环境不要部署多个MDS服务器,但是就笔者经验,如果不是特别大的IO压力,仅仅用作共享存储,建议部署多活MDS,否则MDS挂掉后数据恢复比较麻烦。