【注意力机制】学习
文章目录
- 前言
- 一、Encoder-Decoder
-
- (一)作用
- (二)实现框架
-
- Encoder:
- Decoder
- (三) 基于seq2seq模型的编码与解码
-
- 方法1
-
- 弊端:
- 方法2
- 以上两种方式的弊端
- 二、Attention Model是什么?
-
- (一)应用场景
- (二)原理
-
- 阶段1:计算相似性
- 阶段2:归一化
- 阶段3:计算Attention值
- (三)Self-Attention
-
- 优点
- 三、Transformer模型
-
- (一)整体结构
- 2.读入数据
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
为了更有效地实现多对比度下的MRI超分辨率学习,多源信息需要利用注意力机制进行筛选和融合,因此需要利用注意力机制。本文学习的步骤为:从编码-解码框架到Attention再到最后的Transformer框架
参考文章:https://blog.csdn.net/Tink1995/article/details/105012972
提示:以下是本篇文章正文内容,下面案例可供参考
一、Encoder-Decoder
(一)作用
输入一个序列,生成一个序列的问题,这两个序列可以分别是任意长度
(二)实现框架
seq2seq模型和Transformer模型
示例
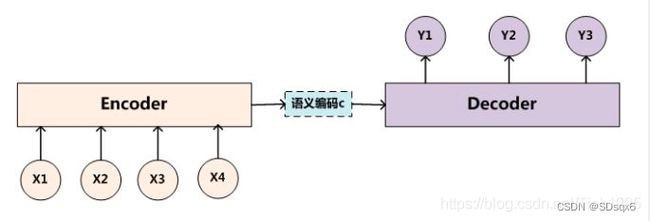
Encoder:
编码器,对于输入的序列
**编码方式:**RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU
Decoder
解码器,根据输入的语义编码C然后将其解码成序列数据
解码方式:RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU,Decoder和Encoder的编码解码方式可以任意组合.
(三) 基于seq2seq模型的编码与解码
方法1
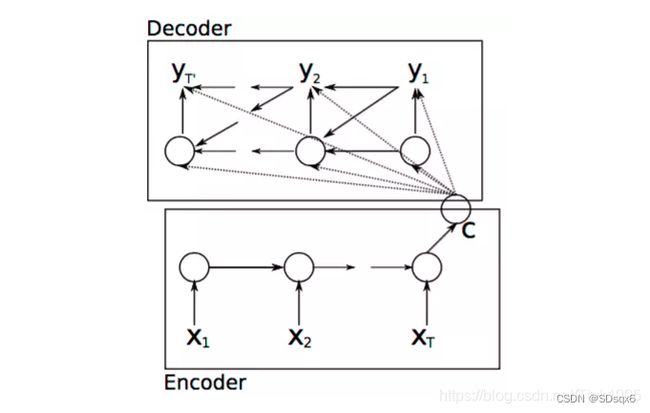
Ecoder-Decoder均是使用RNN,语义编码C包含了整个输入序列的信息,所以在解码的每一步都引入C。文中,在计算每一时刻的输出yt时,都输入语义编码C,即ht=f(ht-1,yt-1,C),p(yt)=f(ht,yt−1,C)。ht为当前t时刻的隐藏层的值,yt-1为上一时刻的预测输出,作为t时刻的输入,每一时刻的语义编码C是相同的。
弊端:
每一时刻的输出如上式所示,从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的语义编码C都是一样的,没有任何区别。而语义编码C是由输入序列X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实输入序列X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)
方法2
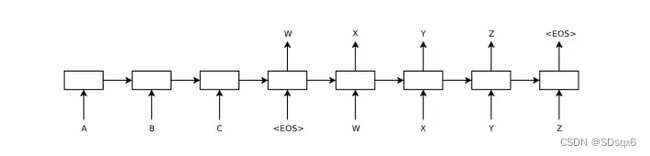
Decoder的初始输入引入语义编码C,将语义编码C作为隐藏层状态值h0的初始值,p(yt)=f(ht,yt−1)。
以上两种方式的弊端
将整个序列的信息压缩在了一个语义编码C中,用一个语义编码C来记录整个序列的信息,序列较短还行,如果序列是长序列,比如是一篇上万字的文章,我们要生成摘要,那么只是用一个语义编码C来表示整个序列的信息肯定会损失很多信息,而且序列一长,就可能出现梯度消失问题,这样将所有信息压缩在一个C里面显然就不合理。
既然一个C不行,就需要用多个C,基于Encoder-Decoder的attention model就出现了。
二、Attention Model是什么?
(一)应用场景
人在看到一个图片或者其它东西时,第一眼会根据自己的需要或者喜好放在事物不同的位置上,因此可以根据信息的重要性,赋予深度模型选择的能力,这种性能需要依靠给网络添加注意力机制来实现。
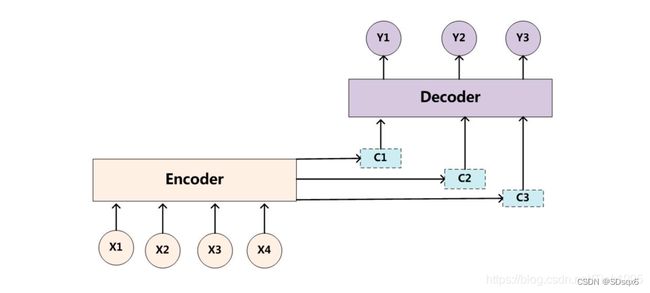
可以看到使用注意力机制之后只有一个单一的语义编码C,而是有多个C1,C2,C3这样的编码。当我们在预测Y1时,可能Y1的注意力是放在C1上,那咱们就用C1作为语义编码,当预测Y2时,Y2的注意力集中在C2上,那咱们就用C2作为语义编码,以此类推,就模拟了人类的注意力机制。
那么现在的问题就是怎么计算出C1,C2,C3…Cn,Ci代表输入中不同元素的注意力分配的概率分布
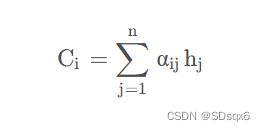
其中hj为输入各元素经过隐藏层的输出h,下面求权重aij
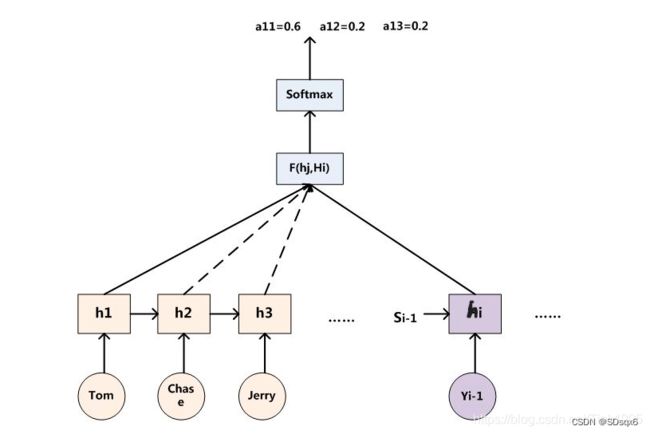
decoder上一时刻的输出值Yi-1与上一时刻传入的隐藏层的值Si-1通过RNN生成hi,然后计算hi与h1,h2,h3…hm的相关性,得到相关性评分[f1,f2,f3…fm],然后对Fi进行softmax就得到注意力分配αij。
(二)原理
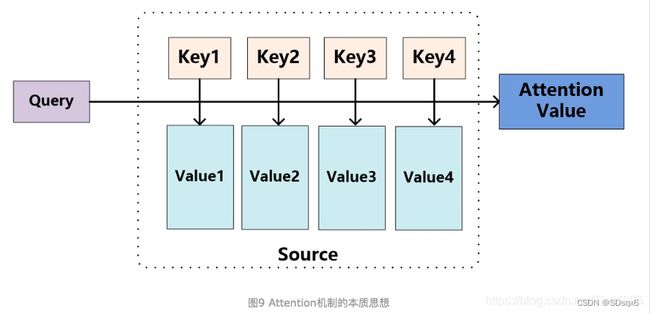
将Source中的构成元素想象成是由一系列的
![]()
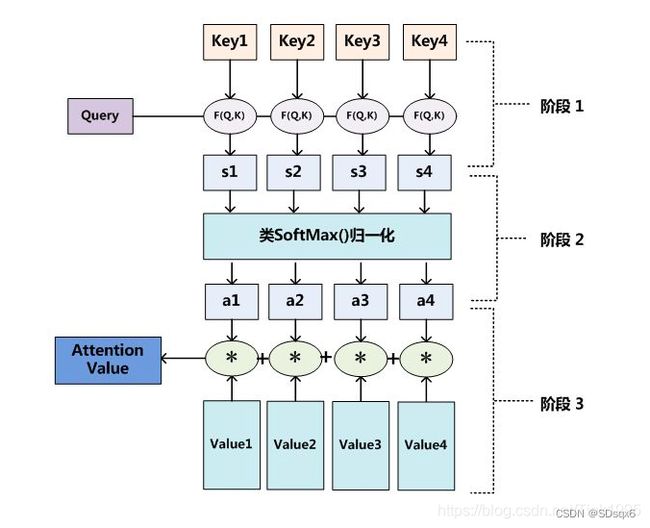
阶段1:计算相似性
其中,Transformer中的相似性使用点积的方法计算,即

阶段2:归一化
计算出Query和Keyi的相似性后,第二阶段引入类似SoftMax的计算方式对第一阶段的相似性得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
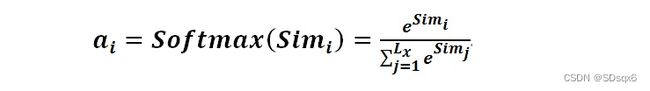
阶段3:计算Attention值

(三)Self-Attention
顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是Query=Key=Value,计算过程与attention一样
优点
如此引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self Attention逐渐被广泛使用的主要原因。
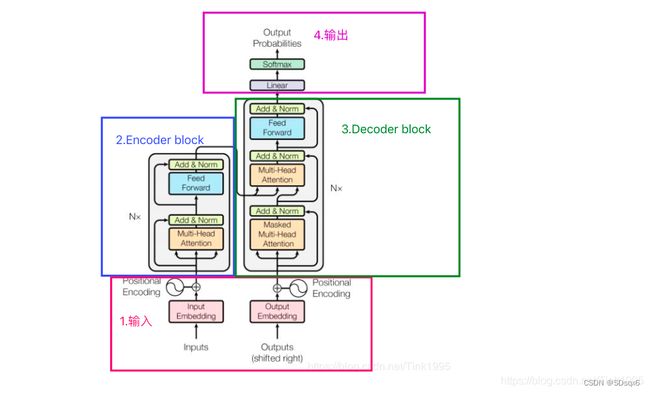
三、Transformer模型
(一)整体结构
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。