Groutine详解:为什么大规模并发式应用偏爱Go语言
By nuaa shaoyang(仅供参考,研究报告请勿照搬)
Go(又称Golang)是Google开发的一种静态强类型、编型、并发型,并具有垃圾回收功能的编程语言。Go语言 2.0没有泛型、异常处理与模块对于 Golang 发展造成很大的阻碍。Golang 的垃圾回收机制一直被人诟病,直到 Golang 1.8 版本垃圾回收的功能才较为稳定。然而尽管如此,Golang 的垃圾回收还是远远落后 JVM 的 G1 和 ZGB,且容易卡顿。
但是Google设计Go,目的在于提高在多核、网络机器、大型代码库的情况下的开发效率,在应对高性能的网络和多进程方面具有很大的优势。
Go语言最大的特色就是从语言层面支持并发,如一个简单的网页服务器,只需要仅仅几行代码就能完成。
package main
import (
"io"
"net/http"
)
func simExample(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "It’a a easy example!")
}
func main() {
http.HandleFunc("/", simExample)
http.ListenAndServe(":8088", nil)
}
可以看到代码中并没有像C或者java中使用专门的多进程或多线程创建函数(pthread_create),但是却可以支持多用户登录网页服务器查看内容,这其实是Go语言的最大优势,从语言层面直接支持并发,而不需要用户单独定义。
这种易于使用的并行设计,叫做Goroutine,透过Goroutine能够让程序以异步的方式执行,而不需要担心一个函数导致程序中断,因此Go也非常地适合网络服务。这种Goroutine方式类似于线程,不过开销更小,更易于编程实现,属于轻量级线程,也可以看成轻型协程,本质为协程。例如,有一个简单网络服务器的函数。
func Server(){
//your codes
}
func main(){
while 1{
//receive clients codes
if connect{
//通过go可以把这个函数同步执行
//这样就不会阻塞主程序执行
go Server()
}
}
}
线程分为用户线程与内核线程,属于系统层面,通常来说创建一个新的线程会消耗较多的资源且管理不易,当线程函数内部数据很多时,栈开销会非常大,相对于进程没有明显优势。而协程的主要作用是提供在一个线程内的并发性,却不能利用多个处理器线程。而 Goroutine就像轻量级的线程,一个Go程序可以执行超过数万个 Goroutine,并且这些性能都是原生级的,随时都能够关闭、结束,且运行在多个处理器线程上。一个核心里面可以有多个Goroutine,透过GOMAXPROCS参数你能够限制Gorotuine可以占用几个系统线程来避免失控。
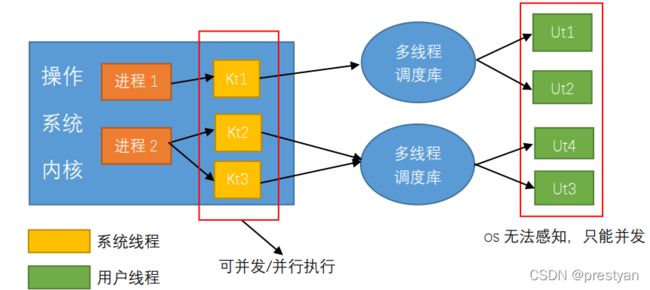
如上图所示,是传统的多线程调度模型,Goroutine主要在多线程调度与用户线程方面做了改进。Goroutine占用资源非常小,每个Gorouine栈的大小默认是2k字节。Goroutine调度的切换也不用在操作系统内核中完成,代价很低。所以一个Go程序可以创建成千上万个并发的Goroutine,而把这些Goroutine按照一定算法放到cpu上执行的程序,就是Goroutine调度器。
一个Go程序运行起来,在操作系统看来就是一个用户程序,Goroutine调度器对于操作系统是透明的。Goroutine的调度完全靠GO自己完成,操作系统要做的工作就是将Goroutine调度好的线程分配CPU时间进行并发或并行执行。
目前Go语言使用的成熟的调度器是基于任务窃取的 Go 语言调度器,其使用了沿用至今的 G-M-P 模型,查阅Go语言文档,可以查阅到任务窃取调度器刚被实现时的源代码,调度器的runtime.schedule:779c45a 代码实现并不复杂。
static void schedule(void) {
G *gp;
top:
if runtime·gcwaiting {
gcstopm();
goto top;
}
gp = runqget(m->p);
if gp == nil
gp = findrunnable();
...
execute(gp);
}
当前处理器本地的运行队列中不包含 Goroutine 时,调用runtime.findrunnable:779c45a 会触发工作窃取,从其它的处理器的队列中随机获取一些 Goroutine。Goroutine还支持抢占式调度,一旦某个G中出现死循环的代码逻辑,编译器会在调用函数前插入 runtime.morestack,配合系统监控这种解决方案可以局部解决“饿死”问题。
在Goroutine调度器中还实现并且应用了G-M-P模型,这也是Go语言对于传统用户线程部分以及多线程调度方式的重要更新。其中,G、P、M分别表示:
G — 表示 Goroutine,它是一个待执行的任务。
M — 表示操作系统的线程,它由操作系统的调度器调度和管理。
P — 表示处理器,它可以被看做运行在线程上的本地调度器。
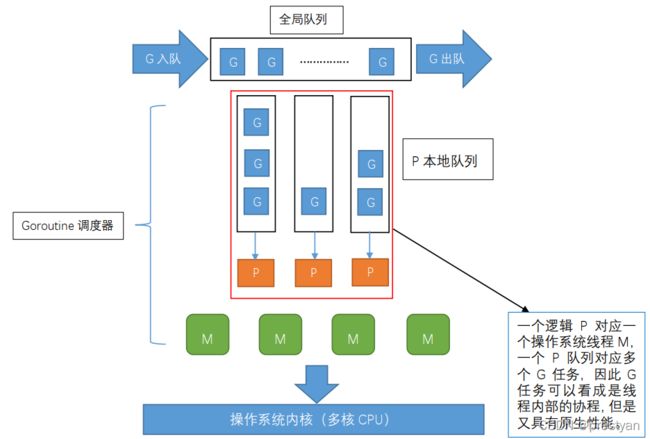
P是一个“逻辑处理器”,每个G要想真正运行起来,都需要被分配到一个P,即进入到P的本地运行队列中,P的数量决定了系统内最大可并行的G的数据。对于G来说,P就是运行它的“CPU”,在G看来只有P。但从调度器的角度看,真正的“CPU”是M,只有将P和M绑定才能让P中的G真正的运行起来。这样的P与M的关系,类似Linux操作系统中用户线程和内核线程的对应关系。M是真正执行计算的资源。在绑定有效的P后,一个调度循环开始;而调度循环的机制是从各种队列、P的本地运行队列中获取G,切换到G的执行栈上并行执行G的函数,调用goexit做清理工作,然后回到M。这样反复,G保存Goroutine的执行栈信息、Goroutine状态以及Goroutine的任务函数等,而M并不保存G的状态,这是G可以跨M调度的基础。在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,虽然调度器可以创建非常多的线程,但大多数都会被系统调用占用。
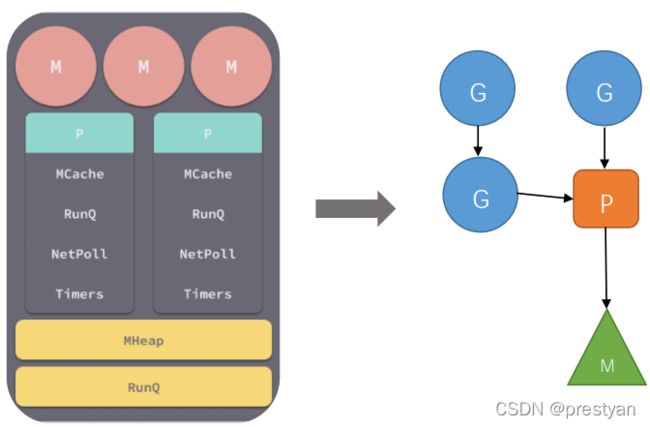
在Go语言最新的提案当中,堆栈、全局运行队列和线程池会按照 NUMA 节点进行分区,网络轮询器和计时器会由单独的处理器持有。这种方式虽然能够利用局部性提高调度器的性能,但是本身的实现过于复杂。不过这一方案仍旧没有脱离Goroutine经典架构。
此外,操作系统是按时间片调度线程的,Go并没有时间片的概念。只要G调用函数,Go运行时就有了抢占G的机会(上文所提到的runtime.morestack)。GO程序启动的时候,运行时会启动一个名为sysmon的M的监控协程,该M特殊之处就是其无需绑定P即可运行(以g0的形式),向长时间运行的G任务发出抢占调度并强制执行垃圾处理。
Go语言会使用私有结构体 runtime.m 表示操作系统线程,操作系统只关系两个Groutine,一个是当前线程M上运行的用户G,一个是g0。
type m struct {
g0 *g
curg *g
...
}
在G的整个生命周期中,最常见的状态有Goroutine 的状态有等待中、可运行、运行中,运行期间会在这三种状态来回切换。
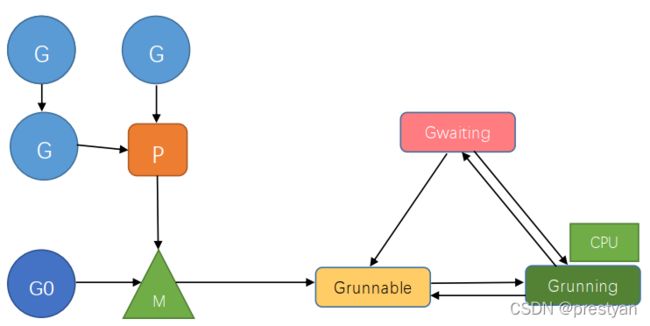
因此,Grouting的实现架构及基本原理如上图所示。当用户想要启动一个新的Goroutine来执行任务时,就如上文代码所示(go Server())需要使用Go语言的go关键字,编译器会通过 cmd/compile/internal/gc.state.stmt 和 cmd/compile/internal/gc.state.call 两个方法将该关键字转换成runtime.newproc函数调用,它会构建新的Groutine结构体,并初始化函数指针、调用方程序计数器等信息,将传入的参数移到 Goroutine的栈上,然后将此G任务加入待处理的全局队列,等待P本地运行队列通过工作窃取等手段将其拉入自己的队列,并等待分配M线程,获取CPU执行时间进行执行。在执行过程中如果触发系统调用、发起IO操作或者抢占式调度器发出抢占指令将其踢出运行状态,则会转移到Gwaiting状态,等待之后分配新的运行时间。
综上所属,Go语言中从语言层面支持并发的Groutine相对于其他高级语言具很大的优势:
- 创建一个Groutine的消耗非常小,大概在2kb左右,所以可以创建百万计的Groutine,而普通线程无法做到。
- 具有合理的CPU分配与抢占式调度,可以保证每一个G任务都得到相对公平的执行时间。
- 具有可增长的分段堆栈,可以根据需要按需使用,大大节省使用内存。
创建goroutine只需在函数调用语句前添加go关键字,就可以创建并发执行单元。开发人员无需了解任何执行细节,调度器会自动将其安排到合适的系统线程上执行。goroutine比thread(Windows/Linux提供的函数库)更易用、更高效、更轻便。
我的Groutine机制学习参考链接
https://segmentfault.com/a/1190000039052089 https://segmentfault.com/a/1190000039052089
https://segmentfault.com/a/1190000039052089
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/