数据结构—内部排序(下)
文章目录
- 8.内部排序(下)
-
- (6).归并排序
-
- #1.先做合并
- #2.再来排序
- #3.代码实现
- #4.稳定性与时间复杂度分析
- (7).快速排序
-
- #1.算法思想
- #2.代码实现
- #3.稳定性与时间复杂度分析
- (8).基数排序
-
- #1.算法思想
- #2.稳定性和时间复杂度分析
- 小结
8.内部排序(下)
(6).归并排序
那我们的时间复杂度还能不能更低一点呢?毕竟 O ( n 2 ) O(n^2) O(n2)的时间复杂度真的很高,一般在oj上,1秒差不多只能执行 1 0 8 10^8 108次运算,那么如果我想做一个 1 0 5 10^5 105规模的数据的排序, O ( n 2 ) O(n^2) O(n2)的排序方式就可能会超时了,所以我们得想办法突破一下
事实上,对于 O ( n 2 ) O(n^2) O(n2)的算法,我们总是会想能不能给它优化到 O ( n log n ) O(n\log{n}) O(nlogn),因此排序算法有没有机会来到这个时间复杂度呢?接下来我要介绍的归并排序和快速排序都能达到 O ( n log n ) O(n\log{n}) O(nlogn)的平均时间复杂度
#1.先做合并
第一个问题是,如果我有两个规模相似的有序数组a和b,我们要怎么把它们合并成一个数组呢?如果用我们前面提到的选择排序之类的思路,我们可以很轻松地写出一个 O ( n 2 ) O(n^2) O(n2)的算法,但这样就没意思了,我们能不能在线性的时间复杂度内完成这件事呢?当然可以,我们来看这么一个流程:

我们有i和j两个“指针”分别用来遍历a和b,我们每一次都比较i和j对应的值,如果 a [ i ] ≤ b [ j ] a[i] \leq b[j] a[i]≤b[j],则不断地把a中的元素放到c中,直到 a [ i ] > b [ j ] a[i] > b[j] a[i]>b[j],比如上面这张图中,两边分别指向第一个元素,然后开始比较,发现1比2小,于是把1放进c中,之后:
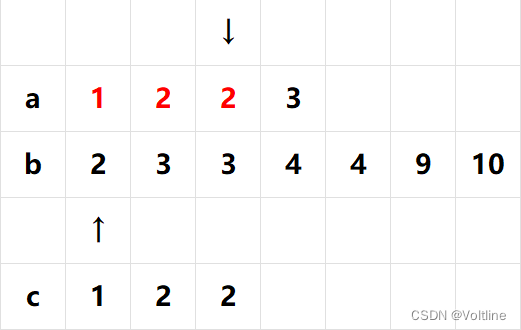
一直这么做,就把1,2,2一起放进c中了,接下来发现b对应的终于比a小了,这时候让b的指针往后跳一位: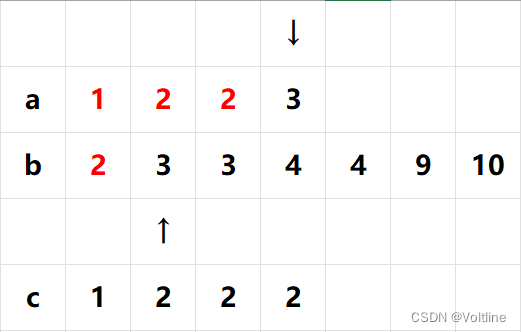
然后发现两个相等了,不过前面规则已经很清楚了, a [ i ] ≤ b [ j ] a[i]\leq b[j] a[i]≤b[j]的时候把a插入,所以我们再把a的3插入:
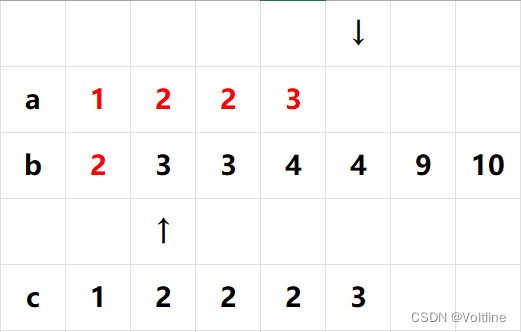
这时候我们发现a的指针已经跑完了,b还没跑完,怎么办呢?这简单,我们直接把b的所有值全都插到c的后面就好了:
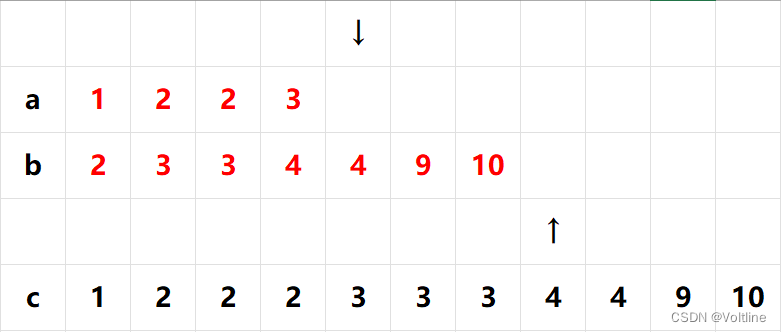
收工!我们顺利地合并了这两个有序序列,而且如果我们的a和b分别对应的是前面和后面的两个序列,那么经过这样一轮合并操作后,相同元素的先后顺序并没有改变,这保证了归并排序是一种稳定的排序方式。
所以今天在这里就可以给出代码了:
vector<int> Merge(vector<int>& a, vector<int>& b)
{
vector<int> c;
int i = 0, j = 0;
while (i < a.size() && j < b.size()) {
if (a[i] <= b[j]) {
c.push_back(a[i++]);
}
else {
c.push_back(b[j++]);
}
}
while (i < a.size()) {
c.push_back(a[i++]);
}
while (j < b.size()) {
c.push_back(b[j++]);
}
return c;
}
非常简单的想法!并且我们发现这个合并过程可以把两个基本有序的序列,合并成为一个更大的稳定有序序列,因此我们接下来就可以尝试一下完成这个排序的流程了。
#2.再来排序
既然有合,那就要分,归并排序的基础是将一个完整的序列依次二分,然后再依次合并,所以我们首先需要把Merge函数改成这个样子,我们得保证我们能够对于同一个数组内部的数据进行归并操作:
void Merge(vector<int>& a, int low, int mid1, int end)
{
int i = low, j = mid1 + 1, k = low;
vector<int> b(a.size());
while (i <= mid1 && j <= end) {
if (a[i] <= a[j]) {
b[k++] = a[i++];
}
else {
b[k++] = a[j++];
}
}
while (i <= mid1) {
b[k++] = a[i++];
}
while (j <= end) {
b[k++] = a[j++];
}
for (int u = low; u <= end; u++) {
a[u] = b[u];
}
}
然后排序的部分就简单得离谱了:
void MergeSort(vector<int>& a, int left, int right)
{
if (left >= right) return;
int mid = (left + right) / 2;
MergeSort(a, left, mid);
MergeSort(a, mid + 1, right);
Merge(a, left, mid, right);
}
没错,我们每次二分序列,对左右两个子序列排序,再合并,这就好了。
#3.代码实现
我们把前面两个部分的代码合在一起:
void Merge(vector<int>& a, int low, int mid1, int end)
{
int i = low, j = mid1 + 1, k = low;
vector<int> b(a.size());
while (i <= mid1 && j <= end) {
if (a[i] <= a[j]) {
b[k++] = a[i++];
}
else {
b[k++] = a[j++];
}
}
while (i <= mid1) {
b[k++] = a[i++];
}
while (j <= end) {
b[k++] = a[j++];
}
for (int u = low; u <= end; u++) {
a[u] = b[u];
}
}
void MergeSort(vector<int>& a, int left, int right)
{
if (left >= right) return;
int mid = (left + right) / 2;
MergeSort(a, left, mid);
MergeSort(a, mid + 1, right);
Merge(a, left, mid, right);
}
好了!归并排序就完成了
#4.稳定性与时间复杂度分析
稳定性前面已经分析过了,归并排序是稳定的排序方式,接下来简单分析一下时间复杂度: T ( n ) = 2 T ( n 2 ) + n T(n) = 2T(\frac{n}{2}) + n T(n)=2T(2n)+n
这个式子,有点眼熟,根据我们在线性表(下)最后提到的主定理,我们可以直接得到:
O ( T ( n ) ) = O ( n log n ) O(T(n))= O(n\log{n}) O(T(n))=O(nlogn)
很好!我们写出了第一个达到 O ( n log n ) O(n\log{n}) O(nlogn)时间复杂度的排序算法。
(7).快速排序
#1.算法思想
快速排序的想法其实和归并差不多,它采取了一种叫做分而治之(Divide and Conquer) 的思想,但是它比归并更加宽松一点,我们每次在待排序的序列中选取一个基准值(pivot),将比基准值大的放在基准值的右边,把比基准值小的放在左边,然后再对左右两个序列依次排序,好像跟归并有点像,也是把大问题分成若干子问题进行解决。

快速排序的过程差不多是这样,我们把序列不断切分,直到只有一个数据的情况下就不再切分,直接返回,最后得到的序列就是有序的了,快速排序的流程主要是保证了经过一轮排序的右边永远都是大于等于左边的,因此右边后续无论如何排序,都不会影响到整个序列的顺序,并且整个过程还是在逐渐变有序的。
#2.代码实现
void quick_sort(vector<int>& vec, int low, int high)
{
if (low >= high) return;
int i{ low }, j{ high }, t{ vec[low] };
while (i < j) {
while (i < j && vec[j] >= t) {
j--;
}
if (i < j) vec[i++] = vec[j];
while (i < j && vec[i] <= t) {
i++;
}
if (i < j) vec[j--] = vec[i];
}
vec[i] = t;
quick_sort(vec, low, j - 1);
quick_sort(vec, j + 1, high);
}
快速排序可以不借助辅助数组,完成原地排序,我们需要用到两个指针i和j,i从左往右走,j从右往左走,在二者相遇之前,只要遇到了比基准值大/小的,就进行交换,最后i和j相遇的位置正好就是基准值被放下的位置。
题外话,如果你用python写快排,这个写法会方便很多:
def quick_sort(l):
if len(l) <= 1:
return l
else:
pivot = l[0]
left, right, mid = [], [], []
for i in l:
if i < pivot:
left.append(i)
elif i > pivot:
right.append(i)
else:
mid.append(i)
return quick_sort(left) + mid + quick_sort(right)
因为python中的list构造很简单,所以写法也就对应的很简单了
#3.稳定性与时间复杂度分析
因为我们在双指针来回跳转,所以快速排序注定是一种不稳定的排序算法,接下来我们来分析一下快速排序的最优时间复杂度,快速排序最优情况就是每一次都恰好把序列分成两半,因此我们可以写出下面的表达式: T ( n ) = 2 T ( n 2 ) + n T(n) = 2T(\frac{n}{2}) + n T(n)=2T(2n)+n
哈,这好像跟归并一模一样嘛,所以快速排序的最优时间复杂度就是 O ( T ( n ) ) = O ( n log n ) O(T(n))=O(n\log{n}) O(T(n))=O(nlogn)
为什么这里强调是最优呢,因为基于pivot的选择,我们的快速排序会发生明显的退化,比如:[9, 8, 7, 6, 5, 4, 3, 2, 1],我们每次选取第一个元素作为pivot,那么第一次就是:[1, 8, 7, 6, 5, 4, 3, 2, 1],然后是[1, 8, 7, 6, 5, 4, 3, 2, 9],接下来是[1, 8, 7, 6, 5, 4, 3, 2],然后是[2, 7, 6, 5, 4, 3, 8],很好!我们的算法退化了!每一次挑出一个最小或者最大的,快速排序在完全顺序或完全逆序的情况下会退化为 O ( n 2 ) O(n^2) O(n2)。
不过这不影响我们用快速排序,在《算法导论》中有对于快速排序平均时间复杂度的证明,其平均时间复杂度为 O ( n log n ) O(n\log{n}) O(nlogn),碍于篇幅,这里就不再证明了。为了避免退化的情况发生,我们一般采取改进pivot选取以及结合插入排序两种方法来解决,前者可以从序列里随机挑选pivot,可能可以使得左序列和右序列的分配更加平均,而结合插入排序则是在数据的有序程度到达一定程度之后采取,这样可以将时间复杂度进一步下降,毕竟,快速排序最不擅长的基本有序恰恰是插入排序最擅长的部分。
所以我们在C++中使用的algorithm里的std::sort就是一种快速排序+插入排序的排序算法,它可以比较稳定地达到 O ( n log n ) O(n\log{n}) O(nlogn)的时间复杂度。
(8).基数排序
前面说的两种排序算法属于基于比较的排序算法,而接下来我们要说一种不基于比较的排序方法,而这种方法,顺利地将排序的时间复杂度降到了线性时间复杂度,伟大的进步!接下来我们来看看它是怎么做的吧!
#1.算法思想
基数排序的思想主要源自多关键字排序,比如对于一系列多位的整数,比较大小我们从低位到高位比较(LSD,最低位优先),也可以从高位到低位比较(MSD,最高位优先)。
我们这里以低位到高位为例,比如[49, 96, 80, 62, 100, 94, 67, 79, 87, 53],首先我们按照低位0~9分成几个子序列[[80], [62], [53], [94], [96], [67, 87], [49, 79]],之后顺着重新收集成序列[80, 62, 53, 94, 96, 67, 87, 49, 79],再按照十位排:[[49], [53], [62, 67], [79], [80, 87], [94, 96]],再收集起来得到[49, 53, 62, 67, 79, 80, 87, 94, 96],因为排序关键字只有个位和十位两个,因此我们的排序已经结束了,你发现,这简直快得离谱啊!
是的,我们只用了两轮操作就已经把整个序列排到有序了。
#2.稳定性和时间复杂度分析
基数排序的稳定性我们在前面是已经看到了的,我们根据排序关键字分组的过程以及后续收集的过程会严格依照原始序列的顺序进行,因此基数排序是稳定的排序。
基数排序的时间复杂度是线性的,假设排序关键字有n个,关键字对应有r个基,d为数据量,那么基数排序的时间复杂度即为 O ( d ( r + n ) ) O(d(r+n)) O(d(r+n)),那么对于我们前面提到的两位十进制数的排序,它的时间复杂度就是 O ( 12 d ) = O ( d ) O(12d)=O(d) O(12d)=O(d),也就是线性的时间复杂度,真的很快。
基数排序的时间复杂度相对比较高,并且代码实现比较复杂,在这里就不给出代码样例了,了解即可。
小结
排序的东西,其实看起来都不是很难,但是对于我们来说,排序算是基础的内容,因为我们总是在追求有序的东西,毕竟有序的东西总是会有很好的性质,下一篇中我们会开始介绍树的相关内容,预计会分成上下两篇发布。