python并发编程(多线程)
文章目录
-
-
- 前言
- 一、什么是CPU密集型计算、IO密集型计算?
-
- CPU密集型
- IO密集型
- 二、多线程、多进程、多协程的对比
-
- 多进程
- 多线程
- 多协程
- 三、线程
-
- 1、理解多任务
- 2、并发、并行
- 3、线程
- 4、查看当前线程运行时的线程
- 5、自定义类创建线程
- 四、队列(Queue)
-
- 1、队列Queue
- 2、堆栈Queue
- 3、优先级Queue
- 五、python线程安全问题(互斥锁lock)
-
- 1、线程之间贡献全局变量
- 2、lock用法解决线程安全问题
-
- 使用with模式
- 使用acquire
- 六、多进程(multiprocessing)
-
- 1、理解
- 2、进程不共享全局变量
- 3、进程之间通信
- 4、多进程知识梳理(对比多线程)
- 七、线程池(ThreadPollExecutor)
-
- 线程的生命周期:
- 使用线程池的好处:
-
- 用法1
- 用法2
- 八、进程池
-
前言
第一次编写博客有很多不足的地方希望指正。这些都是我在视频上学习之后总结的一些笔记,大家可以进行参考,希望对大家有帮助。
一、什么是CPU密集型计算、IO密集型计算?
CPU密集型
也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
如:压缩解压缩、加密解密、正则表达式搜索
IO密集型
IO密集型是指系统运作大部分时间都在等待I/O(硬盘/内存)的读/写操作,CPU占用率仍然较低。
如:文件处理程序、网络爬虫程序、读写数据库程序
二、多线程、多进程、多协程的对比
一个进程中可以启动多个线程,一个线程中可以启动多个协程。
多进程
- 优点:可以利用多核CPU并行运算
- 缺点:占用资源最多,可启动数目比线程少
- 适用于:CPU密集型计算
多线程
- 优点:相比进程,更轻量级、占用资源少
- 缺点:
- 相比进程:多线程只能并发执行,只能同时使用一个CPU
- 相比协程:启动数目限制,占用内存资源,有线程切换开销
- 适用于:IO密集型计算、同时运行的任务数目要求不多
多协程
- 优点:内存开销最小、启动协程数量最多
- 缺点:支持的库有限制(aiohttp vs request)、代码实现复杂
- 适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
三、线程
1、理解多任务
一个CPU默认可以执行一个任务,如果想要多个程序一起执行,理论上将需要多个CPU,操作系统为了让多个程序,都能够得到执行的集合,采用了一系列的方案来实现,如:时间片调度。将每个任务交给CPU处理很少的时间,然后就去处理另外一个任务。实现了多个任务看上去是一起执行的。
2、并发、并行
- 并发:是一个对假的多任务的描述,意思是CPU处理不够,通过某种方法进行一起执行任务
- 并行:是真的多任务的描述,意思是CPU数处理任务够了(往往很少)
3、线程
- 当一个程序运行时,默认有一个线程,这个线程我们称为主线程。
- 多任务可以理解为让你的代码在运行过程中额外创建一些线程,让这些线程取 执行代码。
- 如果想在一个程序中有多个任务一起运行,那么,就想办法创建多Thread对象。
- 在创建Thread对象是target执行的函数的代码执行完后,意味着这个子线程结束。
- 虽然主线程没有了代码,但它依然等着所有子线程结束之后它才真正的结束。
- 多线程执行顺序是不确定的。
4、查看当前线程运行时的线程
通过threading.enumerate()来查看进程。
5、自定义类创建线程
class Task(threading.Thread):
def run(self) -> None:
while True:
print("111")
# run方法中调用其他方法
self.xx()
# 创建一个对象
t = Task()
# 因为继承,可以直接使用父类的start方法,并且会运行run方法
t.start()
def xx():
pass
- 可以自己定义一个类,但是这个类要继承Thread
- 一定要实现run方法,既要定义一个run方法,并且实现线程需要执行的代码
- 当调用自己编写的类创造出来的实例对象run方法时,会创建新的线程,并且线程会自动调用run方法
- 如果除了run方法之外还定义了其他方法XX,那么这些方法需要在run方法中自己去调用。线程它不会自动调用
四、队列(Queue)
1、队列Queue
queue.Queue()
- FIFO(先进先出)
- 可以存储不同的数据类型,例如整数、字符串、字典
- 使用put放数据
- 使用get取数据(如果当前队列中没有数据,此时会堵塞)
2、堆栈Queue
queue.LifoQueue()
- LIFO(后进先出)
- 可以存储不同的数据类型
- 使用put放数据
- 使用get取数据(如果当前队列中没有数据,此时会堵塞)
3、优先级Queue
queue.PriorityQueue()
- 根据优先级来确定当前要获取的数据
- 使用put放数据
- 将一个元组放在里面
- 第一个元素是:优先级,数字越小级别越高
- 第二个元素是:要存放的数据
- 使用get取数据(如果当前队列中没有数据,此时会堵塞)
五、python线程安全问题(互斥锁lock)
1、线程之间贡献全局变量
- 如果一个程序有多个线程,每个线程可以单独执行自己的任务
- 如果多个线程之间需要数据共享,最简单的方式就是通过全局变量来实现
线程安全指某个函数、函数库在多线程环境中被调用时。能够正确的处理多个线程之间的共享变量,使程序功能正确完成。
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全。如,银行取钱。
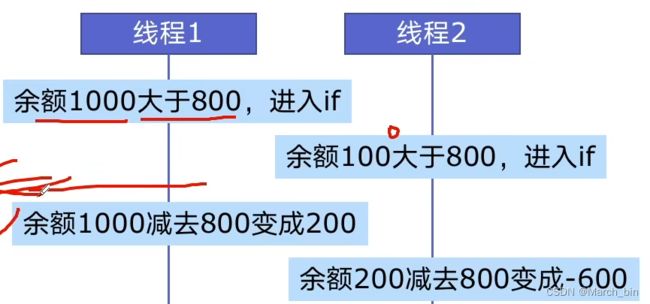
2、lock用法解决线程安全问题
使用with模式
import threading
lock = threading.Lock()
def draw(account,amount : int):
with lock:
if account.balance >= amount:
# time.sleep(0.1)
print(threading.current_thread().name,'取钱成功')
account.balance -= amount
print(threading.current_thread().name,'余额:',account.balance)
else:
print(threading.current_thread().name,'取钱失败')
使用acquire
将代码放在互斥锁上锁和解锁之间
import threading
lock = threading.Lock()
# 上锁
lock.acquire()
pass
# 解锁
lock.release()
六、多进程(multiprocessing)
1、理解
-
程序:一段代码,这个代码规定了将来运行时程序执行的流程
-
进程:一个程序运行起来后,代码+用到的资源(CPU、内存、网络等)
-
如果遇到CPU密集型计算,多线程反而会降低执行速度。
-
multiprocessing模块就是为了python解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并发执行。
2、进程不共享全局变量
- 当创建一个子进程的时候,会复制父进程的很多东西(全局变量等)
- 子进程和主进程是单独的两个进程,不是一个(当一个进程结束时,不会对其他的进程产生影响)
3、进程之间通信
进程之间是独立的,所有的数据各自用各自的,因此为了能够让这些进程之间共享数据,不能使用全局变量,可以使用Linux (Unix)给出的解决方法︰
-
进程间通信(IPC)
- 管道
- socket(重点)∶能够实现多台电脑上的进程间通信
-
为了更加简单的实现进程间的通信,可以使用队列Queue
import multiprocessing q = multiprocessing.Queue()
4、多进程知识梳理(对比多线程)

七、线程池(ThreadPollExecutor)
线程的生命周期:
新建的线程处于不动的状态,线程的运行需要调用start()方法系统进行就绪。然后系统进行调度让线程获得了CPU的资源,使其运行状态。
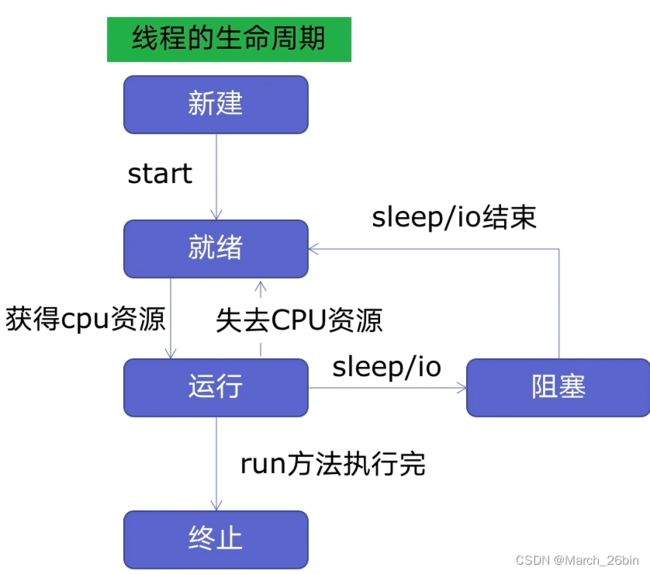
新建线程系统需要分配资源、终止线程系统需要回收资源。
如果可以重用线程,则可以减去新建和终止的开销。于是就有了线程池。
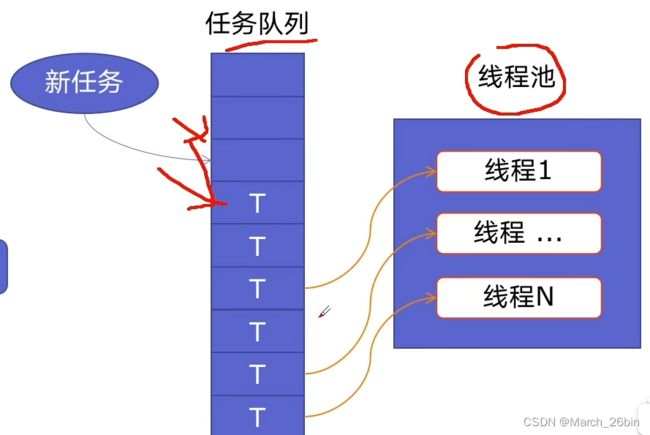
使用线程池的好处:
- 提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源
- 适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
- 防御功能:能有效避免系统因为创建线程过多,而导致负荷过大相应变慢等问题
- 代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
from concurrent.futures import ThreadPoolExecutor, as_completed
用法1
map函数,注意map的结果和入参是顺序对应的
with ThreadPoolExecutor() as pool:
results = pool.map('func','list')
for result in results:
print(result)
用法2
future模式,注意如果是用as_completed顺序是不定的,但是谁先进行完谁先进行返回
with ThreadPoolExecutor() as pool:
futures = [pool.submit('func',url) for url in urls]
for future in futures:
print(future.result())
for future in as_completed(futures):
print(future.result())
八、进程池
当需要创建的子进程数量不多时﹐可以直接利用multiprocessing中的Prcoss动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以拖定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
from multiprocessing import Pool
import os
import random
import time
def worker(num):
for i in range(5):
print('===pid=%d==num=%d=' % (os.getpid(), num))
time.sleep(1)
# 3表示进程池中最多有三个进程一起执行
pool=Pool(3)
for i in range(10):
print('---%d---' % i)
# 向进程中添加任务
# 注意:如果添加的任务数量超过了进程池中进程的个数的话﹔那么就不会接着往进程池中添加
# 如果还没有执行的话﹐他会等待前面的进程结束﹐然后在往进程池中添加新进程
pool.apply_async(worker, (i,))
pool.close() # 关闭进程池
pool.join() # 主进程在这里等待﹐只有子进程全部结束之后,在会开后主线程