读书笔记《计算机是怎样跑起来的》
本书介绍
作者:矢泽久雄 译者:胡屹
本书以计算机的三大原则为开端,相继介绍了计算机的结构、手工汇编、程序流程、算法、数据结构、面向对象编程、数据库、TCP/IP网络、数据加密、XML、计算机系统开发以及SE的相关知识。
本书关键字

个人读后感觉
1. 内容偏于基础类,有计算机导论的基础就可以作为计算机基础进阶来阅读,内容软硬件都有涉猎,不过还是偏软件多一些。
2. 硬件类的偏少,但也都是常见的基础知识
3. 软件类推荐重点阅读软件编程中的算法和网络部分的描述
4. 我因为行业的原因, 接触数据库较少,所以数据库篇幅只是作为内容了解,没有细读。
5. 总的来说,本书还是值得一读的(七成推荐值),尤其是对刚刚入门的计算机专业的朋友比较友好。
一、计算机的三大原则
1. 计算机是执行输入、运算、输出的机器
从硬件上来看,可以说计算机是执行输入、运算、输出三种操作的机器

2.程序是指令和数据的集合
软件是指令和数据的集合。所谓指令,就是控制计算机进行输入、运算、输出的命令。在程序设计中,会为一组指令赋予一个名字,可以称之为“函数”“语句”“方法”“子例程”“子程序”等。程序中的数据分为两类,一类是作为指令执行对象的输入数据,一类是从指令的执行结果得到的输出数据。在编程时程序员会为数据赋予名字,称其为“变量”。
3.计算机的处理方式有时与人们的思维习惯不同
计算机有计算机的处理方法,计算机本身只不过是为我们处理特定工作的机器。对计算机来说什么都是数字。用数字表示所有信息,这就是一个很具有代表性的计算机式的处理方法,这一点也正是和人类的思维习惯最不一样的地方。
二、硬件和软件
1. 计算机的硬件有三个基本要素:CPU、内存和I/O
CPU负责解释、执行程序,从内存或I/O输入数据,在内部进行运算,再把运算结果输出到内存或I/O。内存中存放着程序,程序是指令和数据的集合。I/O中临时存放着用于与周边设备进行输入输出的数据。CPU配合着由时钟发生器发出的滴答滴答的时钟信号,从内存中读出指令,然后再依次对其进行解释和执行。
CPU中有各种各样的各司其职的寄存器。其中有一个被称为PC (Program Counter,程序计数器)的寄存器,负责存储内存地址,该地址指向下一条即将执行的指令。每解释执行完一条指令,PC寄存器的值就会自动被更新为下一条指令的地址。
机器语言是唯一一种CPU能直接理解的编程语言。
2. 程序的执行
程序的三种流程正像是河流本身。从高山的泉眼中涌出的清泉形成了河流的源头(程序执行的起点)。水流从山中缓缓流下,有时向着一个方向流淌(顺序执行),有时中途分出了支流(条件分支),还有时由于地势卷起了漩涡(循环)。
程序的流程总共有三种。除了顺序执行以外,还有“条件分支”和“循环”。
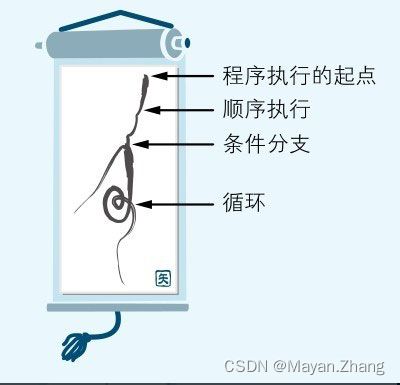
3. 结构化程序设计
结构化程序设计是由学者戴克斯特拉提倡的一种编程风格。
所谓结构化程序设计就是“为了把程序编写得具备结构性,仅使用顺序执行、条件分支和循环表示程序的流程即可,而不再使用跳转指令”。“仅用顺序执行、条件分支和循环表示程序的流程”这一点是不言自明的,需要请诸位注意的是“不使用跳转指令”这一点。
4. 两种特殊的程序流程
中断处理
中断处理是指计算机使程序的流程突然跳转到程序中的特定地方,这样的地方被称为中断处理例程(Routine)或是中断处理程序(Handler),而这种跳转是通过CPU所具备的硬件功能实现的。人们通常把中断处理比作是接听电话。假设诸位都正坐在书桌前处理文件,这时突然来电话了,诸位就不得不停下手头的工作去接电话,接完电话再回到之前的工作。像这样由于外部的原因使正常的流程中断,中断后再返回到之前流程的过程就是中断处理流程。
中断处理以从硬件发出的请求为条件,计算机具有硬件上处理中断的能力;
事件驱动(Event Driven)
程序员们经常用事件驱动的方式编写那些工作在GUI(Graphical User Inteface,图形用户界面)环境中的应用程序,例如Windows操作系统中的应用程序。事件驱动是一种适用于GUI环境的编程风格,在这种环境中用户可以通过鼠标和键盘来操作应用程序,通常把用户在应用程序中点击鼠标或者敲击键盘这样的操作称作“事件”(Event)。
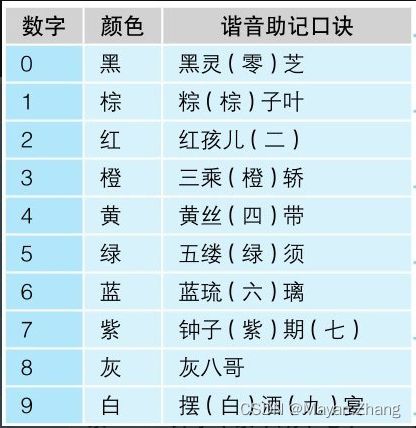
5. 电阻阻值计算方法

上面带有4种颜色的色环,从左侧开始数,第3位的数字是几就表示是10的几次方
电阻颜色代码的谐音助记口诀
三、软件编程
1. 算法
算法的定义是:被明确定义的有限个规则的集合,用于根据有限的步骤解决问题。
用通俗易懂的语言来说,算法就是“把解决问题的步骤无一遗漏地用文字或图表示出来”。要是把这里的“用文字或图表示”替换为“用编程语言表达”,算法就变成了程序。而且请诸位注意这样一个条件,那就是“步骤必须是明确的并且步骤数必须是有限的”。
计算不能自发地思考,因此计算机所执行的由程序表示的算法必须是由机械的步骤所构成。所谓“机械的步骤”,就是不用动任何脑筋,只要按照这个步骤做就一定能完成的意思。众多的学者和前辈程序员们已经发明创造出了很多机械地解决问题的步骤,这些步骤并不依赖人类的直觉。由此所构成的算法被称为“典型算法”。
算法效率:解决一个问题的算法未必只有一种。在考量用于解决同一个问题的多种算法的优劣时,可以认为转化为程序后,执行时间较短的算法更为优秀。
所有的信息都可以用数字表示——这是计算机的特性之一。因此为了构造算法,经常会利用到存在于数字间的规律。
例如:石头剪刀布游戏胜负的算法。如果把石头、剪刀、布分别用数字0、1、2表示,把玩家A做出的手势用变量A表示,玩家B做出的手势用变量B表示,那么变量A和B中所存储的值就是这三个数中的某一个

如果使用数字技巧可以发现:
● 如果变量A和B相等就是“平局”
● 如果用B+1除以3得到的余数与变量A相等就是“玩家B获胜”
● 其余的情况都是“玩家A获胜

2. 数据结构
计算机所处理的数据都存储在了被称为内存的IC(Integrated Circuit,集成电路)中。在一般的个人计算机中,内存内部被分割成了若干个数据存储单元,每个单元可以存储8比特的数据(8比特 = 1字节)。为了区分各个单元,每个单元都被分配了一个编号,这个编号被称为“地址”或是“门牌号码”。
内存的物理结以及它和程序的关系

数组
数组实际上是为了存储多个数据而在内存上集中分配出的一块内存空间,并且为这块空间整体赋予了一个名字。数组是一种直接利用内存物理结构(计算机的特性)的最基本的数据结构。
数组反映了内存物理结构本身

栈(stack)
数据的使用顺序与堆积顺序是相反的。通常把这种存取方式称为LIFO(Last In First Out,后进先出),即最后被存入的数据是最先被处理的。在那些作为程序处理对象的实际业务中,可以用栈来模拟诸如堆积在桌子上的文件等场景。既然无法马上处理,就暂且先都堆放在栈里吧。
队列(queue)
队列与栈正相反, FIFO(First In First Out,先进先出),即最先被存入的数据也是最先被处理的。
结构体
所谓结构体,就是把若干个数据项汇集到一处并赋予其名字后所形成的一个整体。
struct TestResult
{
char Chinese; /*语文成绩*/
char Math; /*数学成绩*
char English; /*英语成绩*
}
一旦定义完结构体,就可以把结构体当作是一种数据类型,用它来定义变量。
结构体数组的示意图:

3. 面向对象编程
面向对象编程(OOP, Object Oriented Programming)是一种编写程序的方法,旨在提升开发大型程序的效率,使程序易于维护
面向对象编程是一种基于以下思路的程序设计方法:将关注点置于对象(Object)本身,对象的构成要素包含对象的行为及操作,以此为基础进行编程。这种方法使程序易于复用,软件的生产效率因而得以提升。其中所使用的主要编程技巧有继承、封装、多态三种。
在面向对象编程中,使用了一种称为“类”的要素,通过把若干个类组装到一起构建一个完整的程序。从这一点来看,可以说类就是程序的组件(Component)。面向对象编程的关键在于能否灵活地运用类。
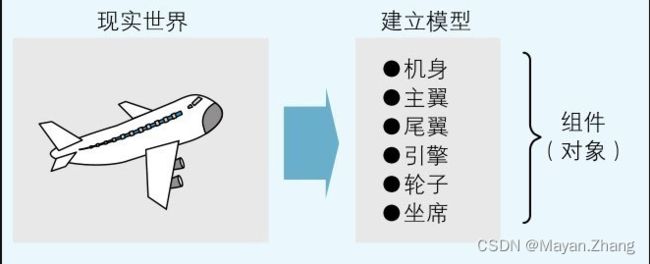
在面向对象编程中,可以通过“这个是由什么样的对象构成的呢?”这样的观点来分析即将转换成程序的现实世界。这种分析过程叫作“建模”。在实际建模的过程中,要进行“组件化”和“省略化”这两步。所谓组件化,就是将可看作是由若干种对象构成的集合的现实世界分割成组件。因为并不需要把现实世界100%地搬入到程序中,所以就可以忽略掉其中的一部分事物。
举例来说,假设要为巨型喷射式客机建模,那么就可以从飞机上抽象归类出机身、主翼、尾翼、引擎、轮子和座席等组件(如图7.3所示)。而像是卫生间这样的组件,不需要的话就可以省略。
“继承”(Inheritance)、“封装”(Encapsulation)和“多态”(Polymorphism,也称为多样性或多义性)被称为面向对象编程的三个基本特性。
继承:指的是通过继承已存在的类所拥有的成员而生成新的类。
封装:指的是在类所拥有的成员中,隐藏掉那些没有必要展现给该类调用者的成员。
多态:指的是针对同一种消息,不同的对象可以进行不同的操作。
类和对象的区别
在面向对象编程中,类和对象被看作是不同的概念而予以区别对待。类是对象的定义,而对象是类的实例(Instance)。经常有教材这样说明二者之间的关系:类是做饼干的模具,而用这个模具做出来的饼干就是对象。虽然这是个有趣的比喻,但是如果这样类比的话,就有可能无法看清二者在实际编程中的关系。

其实是需要先要创建一个个的对象然后才能使用类中定义的成员,举例来说,假设我们定义了一个表示企业中雇员的类Employee。如果仅仅是定义完就可以立刻使用类Employee中的成员,那么程序中实际上就只能存在一名雇员。而如果规定了要先创建类Employee的对象才能使用,那么就可以需要多少就创建多少雇员了(通过在内存上创建出类Employee的副本)
四、数据库
所谓数据库(Database)就是数据(Data)的基地(Base)
适合存储大规模数据的是关系型数据库(Relational Database)。在关系型数据库中,数据被拆分整理到多张表中,同时表与表之间的关系也可以被记录下来。
1. 数据文件、DBMS和数据库应用程序
为了编写数据库应用程序(即为了便于操作数据库而编写的程序)还是会借助称作DBMS的软件。Microsoft Access、Oracle、SQL Server、DB2等。
数据库的实质虽然是某种数据文件,但是诸位编写的应用程序并不是直接去读写这些数据文件,而是以DBMS作为中介间接地读写(如图所示)。DBMS不但可以使应用程序轻松地读写数据文件,而且还具有一致并且安全地存储数据的功能。

数据库系统的构成要素包括“数据文件”“DBMS”“应用程序”三部分。
小型系统:
把三个要素全部部署在一台计算机上,称作“独立型系统”

中型系统:
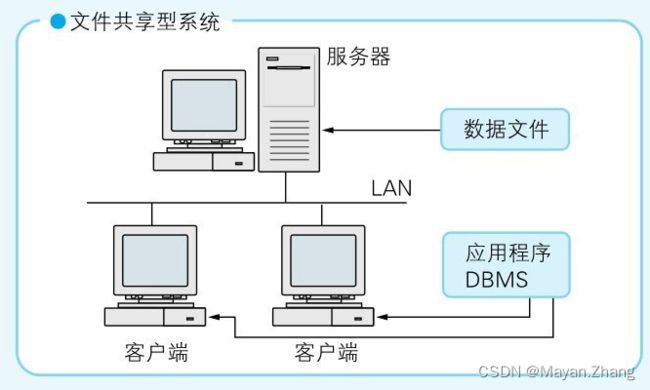
把数据文件部署在一台计算机上,并且使数据文件被部署了DBMS和应用程序的多台计算机共享,这样的系统被称为“文件共享型系统”
大型系统:
把数据文件和DBMS部署在一台(或者多台)计算机上,然后用户从另外一些部署着应用程序的计算机上访问,这样的系统被称作“客户端/服务器型系统”。其中部署着数据文件和DBMS的计算机是服务器(Server),即服务的提供者;部署着应用程序的计算机是客户端(Client),即服务的使用者。如果把服务器和客户端之间用互联网联结起来,就形成了Web系统。在Web系统中,一般情况下应用程序也是部署在服务器中的,在客户端只部署Web浏览器。

2. 主键和外键
在表间建立关系的时候,就必须加入能够反映表与表之间关系的字段,为此所添加的新字段就被称为键(Key)。
主键(Primary Key)该字段的值能够唯一地标识表中的一条记录。主键存储的是能够唯一标识一条记录的ID(Identification,识别码)。正因为这种特性,在主键上绝不能存储相同的值。如果试图录入在主键上含有相同值的记录,DBMS就会产生一个错误通知,这就是DBMS所具备的一种一致并且安全地存储数据的机制。
外键(Foreign Key)如果一个实体的某个字段指向另一个实体的主键,就称为外键。
3. 索引
在表的各个字段上设置索引(Index)能够提升数据的检索速度。
索引和键是两个不同的概念,索引仅仅是提升数据检索和排序速度的内部机制。一旦在字段上设置了索引,DBMS就会自动为这个字段创建索引表。索引表是一种数据结构,存储着字段的值以及字段所对应记录的位置。
一旦设置了索引,每次向表中插入数据时,DBMS都必须更新索引表。提升数据检索和排序速度的代价,就是插入或更新数据速度的降低。因此,只有对那些要频繁地进行检索和排序的字段,才需要设置索引。
4. 数据库操作
对数据库进行的操作的种类通常称为CRUD(增查改删)。CRUD由以下四种操作的英文名称的首字母组成,即记录的插入(CREATE)、获取(REFER)、更新(UPDATE)、删除(DELETE)。
五、网络
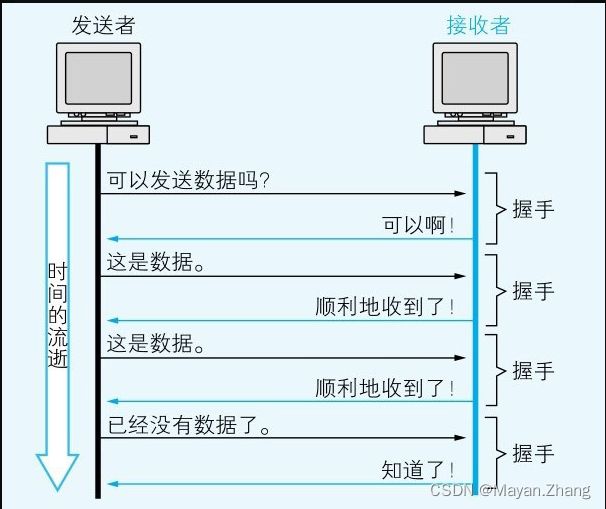
1. TCP/IP网络
TCP/IP 是 Transmission Control Protocol/Internet Protocol(传输控制协议和网际协议)的缩略语
把通过连接多台计算机所组成的、可用于交换信息的系统称为“网络”(Network),因为信息可以以电信号的形式在网线中传播,所以计算机彼此之间就能够进行信息交换。但为了交换信息,还必须在发送者和接收者之间事先确定发送方式。这种对信息发送方式的规定或约束就称为“协议”(Protocol)。
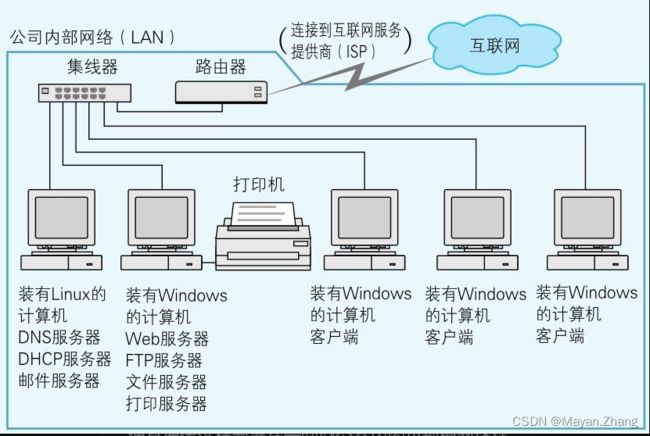
以太网中的每台计算机都需要先确认一件事:在网线上有没有其他的计算机正在传输电信号,也就是说要先确保没有人在占用网络,然后才能发送自己想传输的电信号。谁先抢到了网线的使用权,谁就先发送。万一遇到了多台计算机同时都想发送电信号的情况,只需要让这些计算机等待一段长度随机的时间后再重新发送相同的电信号即可。这套机制叫作CSMA/CD(Carrier Sense Multiple Access with Collision Detection,带冲突检测的载波监听多路访问)。所谓载波监听(Carrier Sense),指的是这套机制会去监听(Sense)表示网络是否正在使用的电信号(Carrier)。而多路复用(Multiple Access)指的是多个(Multiple)设备可以同时访问(Access)传输介质。带冲突检测(with Collision Detection)则表示这套机制会去检测(Detection)因同一时刻的传输而导致的电信号冲突(Collision)。可以用被称作MAC(Media Access Control)地址的编号来指定电信号的接收者。在每一块网卡所带有的ROM(Read Only Memory,只读存储器)中,都预先烧录了一个唯一的MAC地址。网卡的制造厂商负责确定这个MAC地址是什么。因为MAC地址是由制造厂商的编号和产品编号两部分组成的,所以世界上的每一个MAC地址都是独一无二的。
DHCP的全称是Dynamic Host Configuration Protocol(动态主机设置协议)。
DNS服务器可以把主机名解析成IP地址,在互联网中,难以记忆的IP地址使用起来很麻烦。于是人们就发明出了DNS服务器,这样只需要使用FQDN, DNS服务器就可以自动地把它解析为IP地址了(这个过程叫作“域名解析”)。DNS服务器通常被部署在各个LAN中,里面记录着FQDN和IP地址的对应关系表。世界范围内的DNS服务器是通过相互合作运转起来的。如果一台DNS服务器无法解析域名,它就会去询问其他的DNS服务器。
用于实现由IP地址到MAC地址的转换,这种功能被称作ARP(Address Resolution Protocol,地址解析协议)。
IP协议用于指定数据发送目的地的IP地址以及通过路由器转发数据。而TCP协议则用于通过数据发送者和接收者相互回应对方发来的确认信号,可靠地传输数据。