数据结构复习 树&二叉树
//又到考试周了,得肝了!!!
目录
树
树的定义
基本术语
树的存储结构
双亲表示法
孩子表示法
孩子兄弟表示法
二叉树
二叉树的逻辑结构
定义
基本性质
二叉树的遍历
二叉树的存储结构
顺序存储结构
二叉链表
三叉链表
森林
树转换为二叉树
森林转换为二叉树
二叉树转换为树或森林
最优二叉树
哈夫曼算法
哈夫曼编码
线索链表
树
树结构比线性结构复杂,适合描述层次关系的数据。
树的定义
结点:树中的数据元素
树:n个结点(n>=0)的有限集合。
空树:n=0
任一非空树满足的条件:
1.有且仅有一个根结点。
2.结点不属于多个子树,子树之间不能有关系。
基本术语
1.结点的度:某结点所用的子树的个数
树的度:结点度的最大值。
2.叶子结点:度为0的结点。 (终端结点)
分支结点:度不为0的结点。(非终端节点)
3.孩子结点:某结点的子树的根结点。
双亲结点:孩子节点所属子树的根节点。
兄弟结点:同一个双亲的孩子结点。
4.路径:结点n1按次序到结点nk (树中路径唯一)
路径长度:路径上经过的边数
5.祖先:结点x到结点y有一条路径,x为y的祖先
子孙:以某结点为根的子树中任一结点都为该结点的的子孙
6.层数: 根节点的层数=1;第k层结点的层数=k+1
深度:树中所有结点最大层数
宽度:每一层结点个数的最大值
树的抽象数据类型定义:
初始化、销毁、前序遍历、中序遍历、后序遍历、层序遍历
树的存储结构
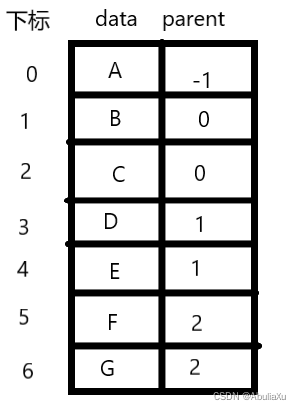
双亲表示法
时间复杂度O(1)
树中每一个结点都有且仅有一个双亲结点。
所以可以用一维数组存储树的各个结点(一般为层序),数组中一个元素对应树的一个结点,数组元素包括树中结点的数据信息以及该结点的双亲都保存在树中的下标。
数组元素的结构体包含数据信息和双亲
parent =-1 表示为根节点
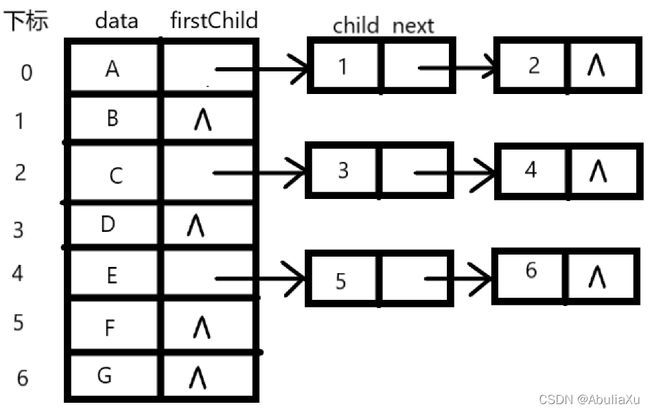
孩子表示法
时间复杂度O(n)
基于链表
线性表+单链表存储
n个结点共有n个孩子链表
叶子节点的孩子链表为空
n个孩子链表共有n个头指针
n个头指针构成一个线性表(顺序存储) 表头数组
两类结点:孩子结点&表头结点
孩子兄弟表示法
二叉链表表示法
链表中每个结点除数据域外,还设置了两个指针分别指向该节点的第一个孩子和右兄弟。

二叉树
二叉树的逻辑结构
二叉树是一种最简单的树结构,任何树都可以简单地转换为对应的二叉树。
定义
二叉树:n个结点的有限集合。
二叉树要么为空要么由一个根节点和两颗互不相交的左子树和右子树的二叉树构成。
特点:
1.每个结点中最多有两棵子树,二叉树中不存在度大于2的结点。
2.二叉树的左右子树不能任意颠倒,若某结点只有一棵子树,一定要有左子树和右子树之分。
特殊二叉树:
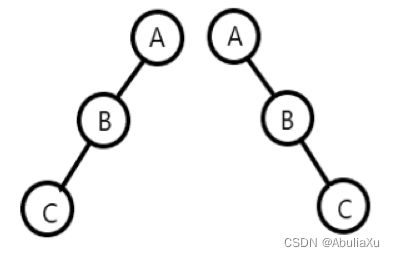
1.斜树
左斜树:所有结点只有左子树的二叉树
右斜树:所有结点只有右子树的二叉树
特点:每一层只有一个基点,斜树的结点个数=深度
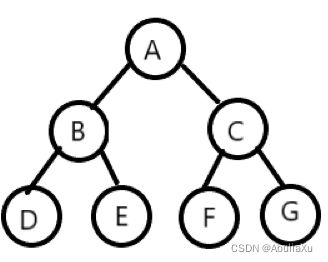
2.满二叉树
所有分支节点都存在左子树和右子树,并且所有叶子节点都在同一层上的二叉树。
特点:叶子只在最下一层、只有度为0和度为2的结点
3.完全二叉树
满二叉树必定是完全二叉树。
特点:深度为k的完全二叉树在k-1层为完全二叉树、叶子结点只出现在最下两层且最下层的叶子结点都集中在左侧连续的位置,若有度为1的结点只可能有1个且该结点只有左孩子

基本性质

二叉树的遍历
前序遍历:
1.访问根结点
2.前序遍历根结点的左子树
3.前序遍历根结点的右子树
中序遍历:
1.中序遍历根结点的左子树
2.访问根结点
3.中序遍历根结点的右子树
后序遍历:
1.后序遍历根结点的左子树
2.后序遍历根结点的右子树
3.访问根结点
层序遍历:
从根结点开始,从上至下逐层遍历,同一层从左到右的顺序对结点逐个访问。
任意一颗二叉树的遍历序列是唯一的,前序、中序和后续遍历中任一个都不能唯一缺点这颗二叉树。
二叉树的存储结构
顺序存储结构
一维数组存储二叉树结点,结点的下标表示节点之间父子关系,按照完全二叉树进行层序编号,再用一维数组顺序存储。(一般仅适合存储完全二叉树)
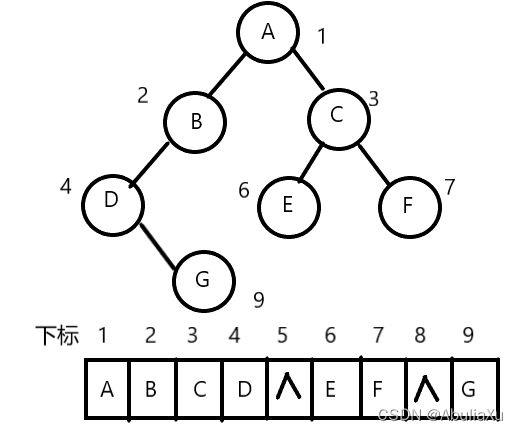
二叉链表
二叉树一般采用二叉链表存储。
基本思想:
令二叉树的每一个结点对于一个链表结点,链表结点除了存放二叉树结点的数据信息外海存放指示左右孩子的指针。
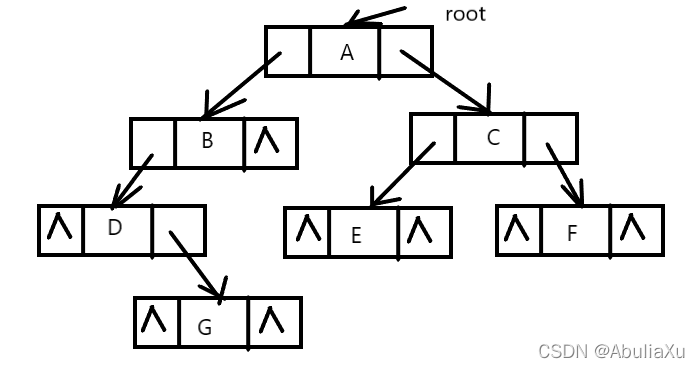
n个结点 n+1个空指针。
找孩子方便!
三叉链表
每个结点四个域,parent:指向双亲结点的指针。
既便于找孩子结点,又便于找双亲结点。 但是相对二叉链表而言增加了空间开销。

森林
森林:m颗互不相交的树的集合。
任何一棵树,删去根结点就变成了森林。
若增加一个根结点,将森林中的每一棵树作为这个根结点的子树,则森林就变成了一棵树。
通常用前序遍历和后序遍历遍历整个森林。
树、森林、二叉树的转换:
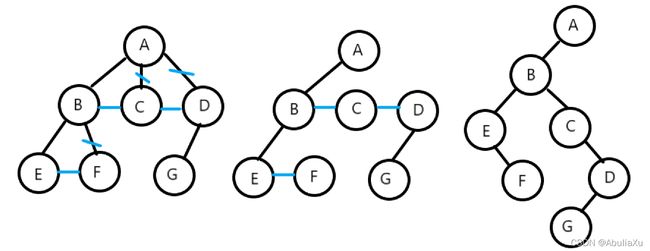
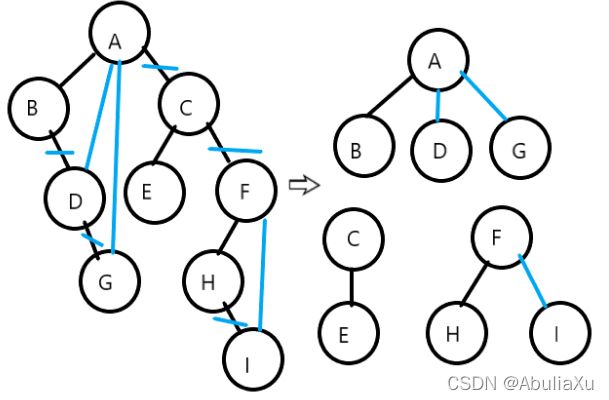
树转换为二叉树
1.加线:树中所有相邻兄弟结点之间加一条线。
2.去线:对树中的每个结点,只保留它与第一个孩子之间的连线,删去与其他孩子的连线。
3.层次调整:按照二叉树结点之间的关系进行层次调整。
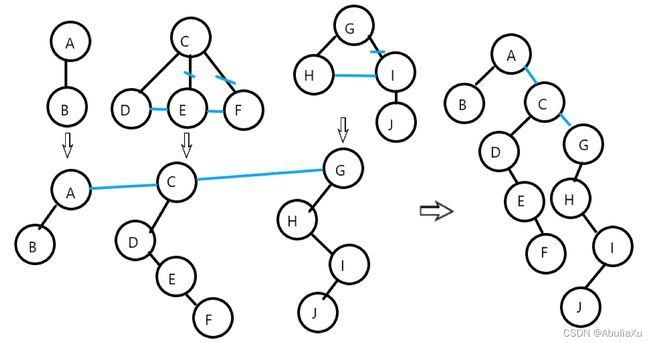
森林转换为二叉树
1.森林的每棵树转换为二叉树
2.每个树的根结点视为兄弟,在所有根结点之间加上连线。
3.按照二叉树结点之间的关系进行层次调整。
二叉树转换为树或森林
1.加线:若某结点x是其双亲的左孩子,则把结点x的右孩子,右孩子的右孩子...与结点y连线。
2.去线:删去原二叉树中所有双亲结点与右孩子结点的连线。
3.层次调整
最优二叉树
哈夫曼算法
叶子结点的权值:对叶子结点赋予的一个有意义的数值量。
带权路径长度:设二叉树具有n个带权值的叶子结点,从根结点到各个叶子结点的路径长度与相应叶子结点权值的乘积之和。
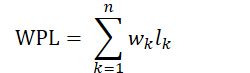
最优二叉树:带权路径最小的二叉树
根据哈夫曼的定义,一棵二叉树使其带权路径长度最小,必须使权值越大的叶子结点靠近根结点,而权值越小的叶子结点远离根结点。
哈夫曼编码
编码:给字符集中每一个字符赋予一个二进制位串。
等长编码:编码等长,表示n个不同字符需要 log2n(向下取整)。
不等长编码:根据使用频率高低构造的。
前缀(无歧义)编码:如果一组编码中任一编码都不是其他任何一个编码的前缀的一组编码。 保证解码时没有多种可能。
哈夫曼编码:哈夫曼树+0对应左子树,1对应右子树
从根节点到叶子结点所经过的路径组成的0和1的序列。
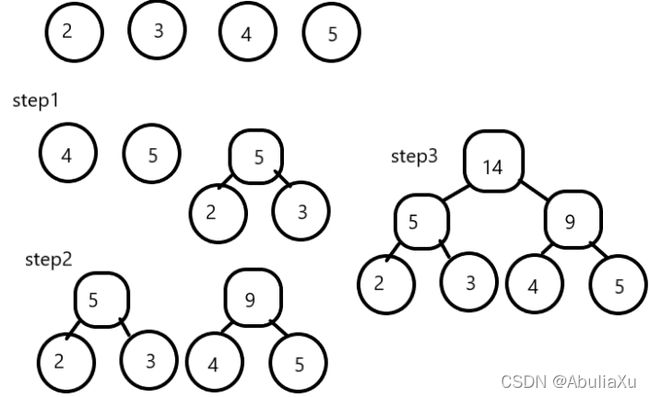
线索链表
线索:指向前驱和后继的指针。
线索链表:加上线索的二叉链表。
在线索链表中,对任意节点,若左指针域为空,则用左指针域存放该节点的前驱线索,
若右指针域为空,则存放该结点的后继线索。为区分某结点指针域存放的是指向孩子的指针还是
指向前驱或后继的线索,每个结点再增设两个标志位 ltag&rtag。
由于二叉树的遍历次序有四种,所以有四种意义下的前驱和后继,所以有四种线索链表。
ltag = 0:lchild指向该结点的左孩子 rtag = 0:rchild指向该结点的右孩子
ltag = 1:lchild指向该结点的前驱 rtag = 1:rchild指向该结点的后继
使用书籍:《数据结构——从概念到C++实现(第三版)》清华大学出版社