【网安AIGC专题10.25】9 LIBRO方法(ICSE2023顶会自动化测试生成):提示工程+查询LLM+选择、排序、后处理(测试用例函数放入对应测试类中,并解决执行该测试用例所需的依赖)
Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction
- 写在最前面
-
- 对之后论文的一些学习借鉴
- 摘要
- 介绍
- 动机
- 方案
-
- A.提示工程Prompt Engineering
- B.查询LLM Querying an LLM
- C.测试后处理Test Postprocessing
- D.选择和排序Selection and Ranking
- 评估
-
- RQs
- 实验结果Experimental Results
- 优点和缺点
- 课堂讨论
-
- 工作量在CD上,C.测试后处理Test PostprocessingD.选择和排序Selection and Ranking
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
万传浩同学分享了软件工程顶级会议ICSE2023文章,来自韩国科学技术院大学的Shin Yoo团队的Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction《大型语言模型是少样本测试器:探索基于llm的通用Bug复制》
论文:https://arxiv.org/pdf/2209.11515.pdf
arXiv 2022.9.23
分享时PPT纯英文的,英文表达地道专业,学到了很多确切的表达方式End of the share!Thanks
过渡很自然比较好理解
还是要趁着有印象把笔记给写了,当时有一些想法,现在没啥印象了
对之后论文的一些学习借鉴
这篇论文为自动化测试生成领域:
-
使用大型语言模型(LLM): 探索 LLM 在软件测试中的应用潜力。
-
后处理步骤和排名: 改进自动生成测试方法的方法。
-
语义目标: 生成测试以重现错误报告的重要性。不仅仅是代码覆盖率或探索性测试,未来的研究可以尝试解决更多复杂的语义目标,以提高自动生成测试的质量和效率。
-
实际应用: Defects4J 基准测试中的性能。 最终关注的是如何提高开发人员的效率。
摘要
主要内容:测试生成技术、软件缺陷重要性、已有技术的局限性以及LIBRO方法的应用和有效性。
-
测试生成技术:
-
提高测试覆盖率Increase coverage
-
生成探索性输入Generate exploratory inputs
-
-
未能满足更多的语义目标,如生成用于复现特定bug报告的测试用例 fall short of achieving more semantic objectives, e.g., generating tests to reproduce a given bug report
-
软件bug的重要性:28%的测试套件大小与问题相关
-
已有复现技术:主要用于处理程序崩溃,不适用于所有bug报告 Existing reproduction techniques: deal with program crashes, not all bug reports
-
LIBRO方法:LLMs, post-process steps, rank produced tests by validity
- 利用LLMs进行测试用例生成
- 包括后处理步骤
- 通过有效性对生成的测试用例进行排序
-
有效性:
- 在Defects4J基准测试中,33%的案例成功生成有效测试用例,共251个(在总计750个案例中)
- 在未知数据上测试,32%的31个缺陷报告获得有效测试用例
介绍
-
从bug报告中生成用于复现bug的测试是一种被低估但具有重大影响的自动测试编写方式。the generation of bug reproducing tests from bug reports is an under-appreciated yet impactful way of automatically writing tests for developers.
-
根据研究,bug报告所导致的测试用例占测试套件大小的中位数约28%。tests as a result of bug reports account for median 28% test suite size
-
bug报告到测试用例的问题:bug report-to-test problem
-
缺乏自动化技术来实现这一目标。Lack of automated technique
-
这种技术的缺失可能使开发人员难以使用自动化调试技术。allow developers use automated debugging techniques
-
-
初步尝试:
- 探索大型语言模型(LLM)的能力,从bug报告中生成测试用例。
- 确定何时可以依赖LLM生成的测试用例。
-
LIBRO(LLM诱发的缺陷复现)- Codex:
- 生成测试用例。
- 处理生成的结果。
- 提出解决方案。
-
经验性实验:
- 在Defects4J基准测试中,至少为251个bug生成了一个可复现的测试用例,占所有研究的bug报告的33.5%。
- bug报告数据集中,32.2%的bug可被复现。
动机

两个观察的简洁分析:
-
测试用例在bug报告中很少可用:
-
bug报告中提供的测试用例很少见。tests are rarely available given a bug report
-
这反映了一种挑战,即从bug报告中生成测试用例的需求。report-to-test problem is under-stressed but important
-
-
缺陷报告到测试用例问题被低估但重要
解决这个问题需要深刻理解自然语言和编程语言solving this problem requires good understanding of both natural and programming language,以便充分发挥预训练的大型语言模型(LLMs)的能力。需要关注以下几个方面:
-
理解自然和编程语言:
-
利用预训练的LLMs的能力: harness(利用) the capabilities of pretrained Large Language Models (LLMs)
-
确定在一份报告中LLMs可以复现多少bug: how many bugs LLMs can reproduce given a report.
- 确定何时信任和使用LLMs的结果: when we should believe and use the LLM results
- 重要的是要确定在什么情况下可以信任和使用LLMs生成的测试用例。
- 需要建立可信的标准或评估方法,以确定LLMs结果的质量和适用性。
- 确定何时信任和使用LLMs的结果: when we should believe and use the LLM results
这些方面需要更深入的研究,以充分利用LLMs来解决报告到测试用例的问题。
方案

A.提示工程Prompt Engineering
LIBRO基于缺陷报告构建提示信息,利用的信息包括缺陷报告的标题和描述信息。
此外,LIBRO还在提示信息中加入测试用例实例引导大模型生成测试用例。
1)不同数量的例子
a varying number of examples
2)提供堆栈跟踪
Provide stack traces

B.查询LLM Querying an LLM
将之前构造的提示信息输入大模型,大模型将输出一个测试用例生成的结果。
LIBRO使用的大模型是基于GPT-3的CodeX模型。LIBRO构造的提示信息末尾是“public void test”,引导大模型生成一段测试用例代码。
此外,LIBRO通过加权随机采样(weighted random sampling)来提升大模型查询效果,并生成多个测试用例作为备选测试用例。
生成测试方法
Generate to span the test method
设置温度为0.7
Set temperature to 0.7
生成多个候选复现测试
Generate multiple candidate reproducing tests

融入
Integrate into
测试套件
Test suite
可执行的
executable
C.测试后处理Test Postprocessing

LIBRO对大模型生成的测试用例的后处理指:
将测试用例函数放入对应测试类中,并解决执行该测试用例所需的依赖。
LIBRO首先根据测试类与测试用例函数的文本相似度来计算测试类和测试函数的映射关系。该策略在业界主流数据集中能够成功匹配89%的测试类与测试函数的关系,是一种有效的匹配策略。
为了解决测试用例函数的依赖问题,LIBRO首先解析生成的测试用例函数,并识别变量类型以及引用的类名/构造函数/异常。
然后,LIBRO通过在测试类中与现有import语句进行词法匹配,并过滤掉已经导入的类名。
将llm生成的测试注入到现有的测试类中(第1行)
Inject LLM-generated tests into existing test classes(line 1)
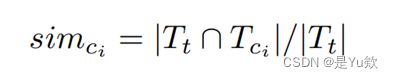
-
在词法上与生成的测试最相似的测试类(算法1,第1行)
the test class that is lexically most similar to the generated test (Algorithm 1, line 1) -
T t T_t Tt和 T c i T_{ci} Tci是生成的测试方法和第i个测试类中的token集合
T t T_t Tt and T c i T_{ci} Tci are the set of tokens in the generated test method and the ith test class

-
解决剩余依赖(2-10):
Resolving remaining dependencies(2-10):-
1)解析变量类型和引用的类名/构造函数/异常
parse variable types and referenced class names/constructors/exceptions -
2)过滤“已经导入”的类名
2) filter “already imported” class names -
3)找到公共类,添加import语句
3) find public classes, add import statement -
4)无匹配或多匹配:在项目中查找以目标类名结尾的导入语句——最常见的是
4) no or multiple matching: looks for import statements ending with the target class name within the project -> most common
-
D.选择和排序Selection and Ranking
一个能够重现缺陷的测试用例指,当且仅当测试用例因为缺陷报告中说明的缺陷而执行失败。
换而言之,LIBRO生成能够重现缺陷的 必要条件 是:该测试用例在被测程序的错误版本中编译成功,但是执行失败。该研究工作将这类测试用例称为FIB(Fail In the Buggy program)。
LIBRO对大模型生成的若干测试用例进行选择和排序,从而优先推荐质量更高的生成结果。
LIBRO的选择和排序算法主要包括三种 启发式策略:
(1)如果测试用例执行失败信息和/或显示了在缺陷报告中提到的行为(比如异常或输出值),那么该测试用例可能是重现缺陷的测试用例。
(2)LIBRO根据选择测试用例的集合大小来观察大模型生成的测试用例之间的一致性。直觉上,如果大模型生成大量相似的测试用例,那么说明大模型认为这类测试用例具有更高的可信度。即,这类测试用例是大模型达成的共识。
(3)LIBRO根据测试用例的长度来决定它们的 优先级,原因是短的测试用例更便于用户理解。
-
Bug Reproducing Test (BRT):
- 缺陷复现测试the test fails due to the bug specified in the report
-
FIB (Fail In the Buggy program):
- 在有缺陷的程序中失败-必要条件the test compiles and fails in the buggy program - necessary condition
-
FIB ≠ BRT
-
Two issues两个问题:
-
如何确定是否成功复现了缺陷? How to tell whether bug reproduction has succeeded or not?
-
何时建议一个测试以及建议哪个测试? when to suggest a test and which test to suggest
-

-
决定是否向开发者显示任何结果(选择,1-10) decides whether to show the developer any results(selection, 1-10)
-
1.1 查找所有的FIBs(1-5)
-
1.2 将具有相同失败输出(相同的错误类型和错误消息)的FIBs分组
group FIBs with same failure output (the same error type and error message) -
1.3 比较 m a x o u t p u t c l u s s i z e max_output_clus_size maxoutputclussize 与 T h r Thr Thr
compare m a x o u t p u t c l u s s i z e max_output_clus_size maxoutputclussize with T h r Thr Thr
-
-
排名测试(11-23)
-
2.1 仅保留句法上唯一的测试(11) reserve only syntactically unique tests
-
2.2 按照三种启发式方法排序(15、16):sort by three heuristics
- a) 失败消息与缺陷报告匹配(12)fail message matches the bug report
- b) 通过output_clus_size生成的测试之间的“一致性”(13)‘agreement’ between generated tests by output_clus_size
- c) 测试长度(令牌数)(14)test length(tokens)
-
2.3 在簇内进行排序(17-18)inner-cluster sorting(17-18)
-
2.4 从每个簇中迭代选择第i个排名的测试select ith ranked test from each cluster iteratively
-
评估
-
数据集 (Dataset):
-
Defects4J 2.0: 来自17个Java项目的真实bug,与bug报告配对,750个质量保证的bug, 60个JCrashPack中的bug与崩溃重现技术进行比较
Defects4J 2.0: real-world bugs from 17 Java projects, paired to bug report, 750 bugs qualitity-ensured left, 60 bugs in JCrashPack comparing against crash reproduction techniques -
GHRB (GitHub最近的bug): 31个可重现的bug以及来自17个使用JUnit的GitHub仓库的bug报告。GHRB(GitHub Recent Bugs): 31 reproducible bugs and their bug reports from 17 GitHub repositories3 that use JUnit
-
-
度量 (Metric):
-
BRT (Bug Reproducing Test): 包含bug的版本失败,没有bug的版本通过
bug-contained version fails, bug-free version passes -
比较 (Comparison): - EvoCrash进行比较。
-
LIBRO对实际BRT的排名能力 (the capability of LIBRO to rank the actual BRTs):
- 使用acc@n和acc@n/所有选定的bug的数量等指标。
-
开发人员检查排名测试所需的努力程度 (the degree of effort required from developers to inspect the ranked tests):
- 使用wef和wef@n。wef, the number of incorrect tests ranked higher than any perfect one, wef@n
-
RQs
RQ1: Efficacy
-
RQ1-1: LIBRO可以生成多少个bug重现测试? (How many bug reproducing tests can LIBRO generate?)
- 讨论LIBRO生成bug重现测试的效能。
-
RQ1-2: LIBRO与其他技术相比如何? (How does LIBRO compare to other techniques?)
- 比较LIBRO与其他技术在生成bug重现测试方面的性能和效果。
RQ2: 效率 (Efficiency)
-
RQ2-1: 需要多少次Codex 查询? (How many Codex queries are required?)
- 探讨使用LIBRO时需要进行多少Codex 查询,以评估其效率。
-
RQ2-2: LIBRO需要多少时间? (How much time does LIBRO need?)
- 分析LIBRO的时间开销,以了解其效率。
-
RQ2-3: 开发人员应该检查多少个测试? (How many tests should the developer inspect?)
- 探究在使用LIBRO时,开发人员需要检查多少测试,以评估其效率。
RQ3: 实用性 (Practicality for GHRB dataset)
-
RQ3-1: LIBRO在复现bug的频率是多少? (How often can LIBRO reproduce bugs in the wild?)
- 研究LIBRO在实际场景中复现bug的频率,特别是在GHRB数据集中。
-
RQ3-2: LIBRO的选择和排序技术有多可靠? (How reliable are the selection and ranking techniques of LIBRO?)
- 评估LIBRO的选择和排序技术的可靠性,以了解其在实际应用中的实用性。
-
RQ3-3: 复制的成功和失败是什么样的? (What does reproduction success and failure look like?)
- 描述LIBRO在复制bug时的成功和失败情况,以了解其实际应用的特点。
实验结果Experimental Results
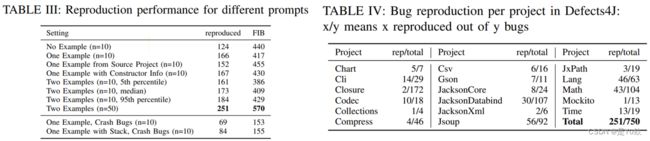
对RQ1-1的回答:可以自动复制大量(251)个bug,这些bug复制到不同的项目组中。
Answer to RQ1-1: A large (251) number of bugs can be replicated automatically, with bugs replicated over a diverse group of projects.
此外,提示中的示例数量和尝试生成的数量对性能有很大影响
Further, the number of examples in the prompt and the number of generation attempts have a strong effect on performance
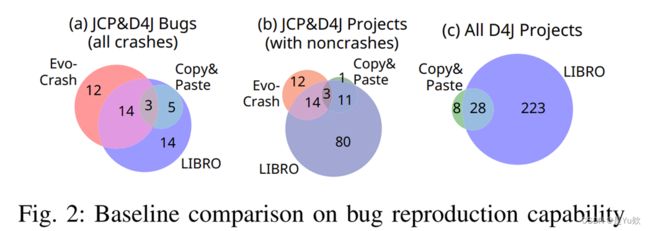
对RQ1-2的回答:与之前的工作相比,LIBRO有能力复制一个庞大而独特的bug组
Answer to RQ1-2: LIBRO is capable of replicating a large and distinct group of bugs relative to prior work

对RQ2-1的回答:复制的bug数量与生成的测试数量呈对数增长,没有性能稳定的迹象。
Answer to RQ2-1: The number of bugs reproduced increases logarithmically to the number of tests generated, with no sign of performance plateauing.

对RQ2-2的回答:我们的时间测量表明,LIBRO并不比其他方法花费更长的时间。
Answer to RQ2-2: Our time measurement suggests that LIBRO does not take a significantly longer time than other methods to use.

RQ2-3的答案:LIBRO可以减少必须检查的bug和测试的数量:33%的bug被安全地丢弃,同时保留87%成功复制的bug。
Answer to RQ2-3: LIBRO can reduce both the number of bugs and tests that must be inspected: 33% of the bugs are safely discarded while preserving 87% of the successful bug reproduction.
在所选的bug集中,80%的重复bug可以在5次检查中被发现。
Among selected bug sets, 80% of all bug reproductions can be found within 5 inspections.

对RQ3-1的回答:LIBRO能够生成bug重现测试,即使是最近的数据,这表明它不是简单地记住它训练过的内容。
Answer to RQ3-1: LIBRO is capable of generating bug reproducing tests even for recent data, suggesting it is not simply remembering what it trained with.
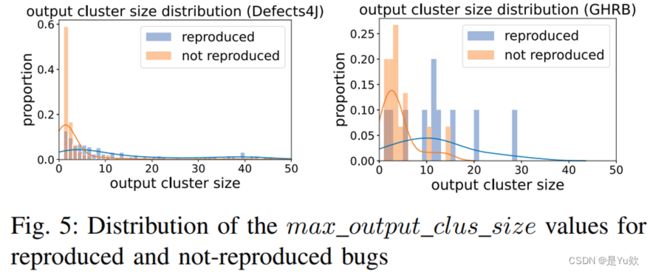
对RQ3-2的回答:我们发现,用于LIBRO排序和选择的因素一致地预测了现实世界数据中的bug复制。
Answer to RQ3-2: We find that the factors used for the ranking and selection of LIBRO consistently predict bug reproduction in real-world data.

优点和缺点
优点 (Pros):
-
专注于被忽视但重要的问题 Focus on ignored but important problem
-
综合实验 Comprehensive experiments
- 描述该技术或方法进行了广泛的实验,有助于验证其有效性和可行性。
缺点 (Cons):
-
提示没有充分利用 Prompts not fully tapped
-
应用范围有限,只有Java
Limited scope of application, only Java
课堂讨论
工作量在CD上,C.测试后处理Test PostprocessingD.选择和排序Selection and Ranking
生成目的是复现代码
同一个样例进去,都经过后面的用例测试
llm单次查询,查询之间是独立的
依赖解析