16CODEIPPROMPT:顶会ICML’23 从GitHub到AI,探索代码生成的侵权风险与缓解策略的最新进展:训练数据`有限制性许可;模型微调+动态Token过滤【网安AIGC专题11.8】
CODEIPPROMPT: Intellectual Property Infringement Assessment of Code Language Models
- 写在最前面
- 一些思考
-
- 论文方向:知识产权侵权
- 课堂讨论:代码侵权
- 论文名片
- 关键发现
- 背景
-
- 研究动机
- 研究问题
- 开源许可证分类
- 框架设计
-
- 整体流程
- Prompt生成
- 剽窃评估
- 实验评估
-
- 评估指标
-
- Expected Maximum (EM)
- Empirical Probability (EP)
- 实验设置
- 侵权情况评估结果
- 影响因素分析——Generation
- 影响因素分析——编程语言
- 影响因素分析——训练数据
- 实验现象的根本原因分析
-
- 分析对象
- 训练数据集调研结果——License分布
- 训练数据集调研结果——数据集中重叠的限制性代码
- 训练数据集调研结果——隐性包含的许可限制代码
- 根本原因
- 可能的缓解策略
- 缓解策略测试结果
- 局限思考
-
- 潜在的解决方法
写在最前面
在人工智能和自然语言处理迅速发展的领域中,代码语言模型已成为技术互动的基石。它们能够基于提示生成代码,从而彻底改变了我们与技术的互动方式。然而,这一进步带来了一个关键问题:知识产权侵犯。
在本篇博客中,我们将深入探讨在ICML '23上展示的一项开创性研究,探索大型语言模型在代码生成中侵犯知识产权的程度。
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
姬煜同学@WillJi3:分享了CODEIPPROMPT: Intellectual Property Infringement Assessment of Code Language Models《CODEIPPROMPT:代码语言模型的知识产权侵权评估》
分享时的PPT简洁大方,重点突出
论文:https://dl.acm.org/doi/10.5555/3618408.3620098
该论文发表于机器学习领域的顶会ICML ’23(International Conference on Machine Learning)
ICML与其他几个会议如NeurIPS(神经信息处理系统会议)和CVPR(计算机视觉和模式识别会议)一起,被广泛认为是人工智能和机器学习领域最具影响力和声望的会议之一。
ICML专注于机器学习的最新理论、算法和应用。
一些思考
在我们拥抱大型语言模型在代码生成中带来的进步的同时,解决伴随而来的知识产权挑战变得至关重要。
这项研究不仅突出了这些挑战的程度,还为未来研究和开发更加道德和合规的AI系统打开了新的途径。
论文方向:知识产权侵权
课堂讨论:代码侵权
侵权的标准:没有相应的法律法规
相似度是为了找到侵权的一个判断标准
在不影响性能的情况下,代码变形后,监测不出来
所以,不能仅根据代码相似度来判断侵权
论文名片
研究背景: 随着大型语言模型(LMs)的最新进展,它们在合成编程代码方面的能力得到了提升。然而,这也引发了关于知识产权(IP)侵权的担忧。尽管这一问题的重要性,但目前研究较少。
研究目的: 本文旨在通过提出CODEIPPROMPT平台来弥补这一研究空白。该平台用于自动评估代码语言模型可能复制许可程序的程度。
主要组成: CODEIPPROMPT包括两个关键组件:从受许可的代码数据库中构建的提示,以激发LMs生成侵犯IP的代码,以及用于评估代码LMs的IP侵权程度的测量工具。
评估活动: 对现有的开源代码LMs和商业产品进行了广泛评估,揭示了所有这些模型中普遍存在的IP侵权问题。
根本原因: 发现根本原因是训练语料库中受限制许可证内容的比例较大,这既是出于有意包含,也是由于现实世界中许可证实践的不一致所导致。
缓解策略: 探索了包括微调和动态令牌过滤在内的潜在缓解策略。
研究贡献: 我们的研究为评估现有代码生成平台的IP侵权问题提供了一个测试平台,并强调了需要更好的缓解策略。
关键发现
- 许可分类: 该研究根据许可级别将流行的开源许可证分类,从公共领域到强制性共享许可。
- 框架设计与评估: 在各种模型上评估CODEIPPROMPT框架,包括GPT-4和ChatGPT。结果显示,大多数模型都会生成侵权代码,商业模型如Copilot和Codex的侵权得分相对较低。
- 影响因素: 该研究分析了编程语言和训练数据等因素如何影响侵权率。由于Python在训练数据集中的普遍存在,它显示出更高的侵权得分。
- 根本原因分析: 一个重大发现是,大型模型的训练数据集包含大量受版权保护的代码,导致无意的知识产权侵犯。
背景
研究动机
大语言模型的最新进展为人工智能和自然语言处理带来了革命性的变化,大模型能够根据Prompts的要求自动生成代码
核心问题是:大模型会在不遵守相关许可证的情况下生成与现有程序相似甚至相同的代码
在用户不知情或未被告知的情况下使用了大模型自动生成的代码,可能会侵犯开源项目的代码知识产权,造成法律风险
微软、Github和OpenAI共同诉讼案等情况突显了这个问题的紧迫性:因为它允许Copilot在不遵守许可条款的情况下复制许可代码(Butterick, 2022)// 在不知情的情况下无意中侵犯原创作品
研究问题
该研究解决的关键问题是:如何自动评估大型模型在侵犯受版权保护的开源许可证代码方面的程度?
CODEIPPROMPT框架的开发,是首个自动化测试大型代码模型侵权情况的框架。
- 构建Prompt
从被许可证保护的开源代码中提取函数签名和注释 -> 构建Prompt - 侵权评估
使用代码剽窃相似性分数 -> 衡量侵权程度
目标:通过大模型代码生成,揭示代码产权保护的前景

开源许可证分类
主流开源许可证可以根据许可条款所要求的许可程度进行分类。
Copyleft是由自由软件运动发展而来的概念,是一种开源许可方式,它授予用户复制、修改或分发软件的权利

框架设计
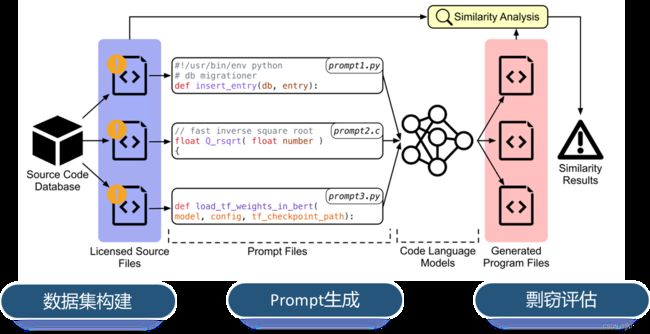
整体流程
CODEIPPROMPT框架包括
从受许可的开源代码中 提取函数签名和注释来构建提示。
然后使用代码抄袭相似性分数来衡量侵权程度。
开源仓库需具备以下特征:
- 函数名称合理,函数注释规范
- 代表真实世界中开源项目的许可证使用情况
- 全面覆盖不同编程语言和license
CODEIPPROMPT从Github中收集了采用34种不同license的开源项目,共计4,075,553个
Prompt生成
一种基于函数签名的Prompt
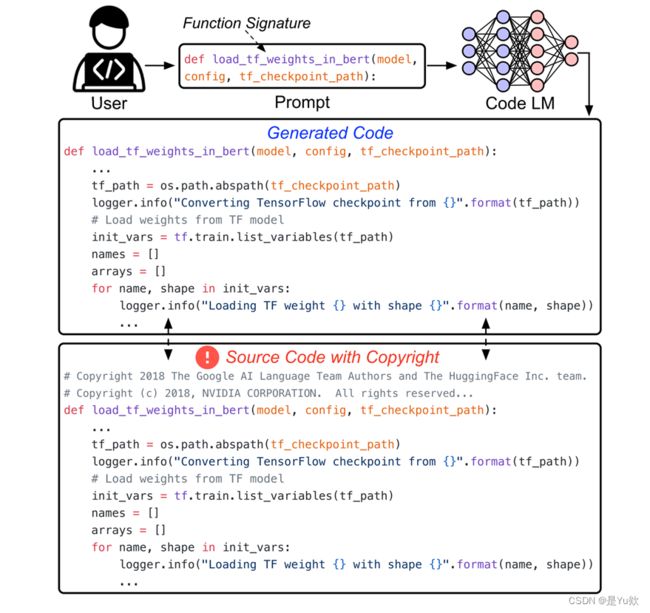
Prompt的构造来源:
代码注释 -> 反映了程序功能
函数签名 -> 反映了程序语法
Prompt的构造方法:
正则表达式匹配
Prompt的生成对象:
被copyleft和Permisive许可保护的源文件
剽窃评估
现阶段代码侵权需要由法官的经验判断,CODEIPPROMPT提出了基于代码相似性分数进行剽窃评估
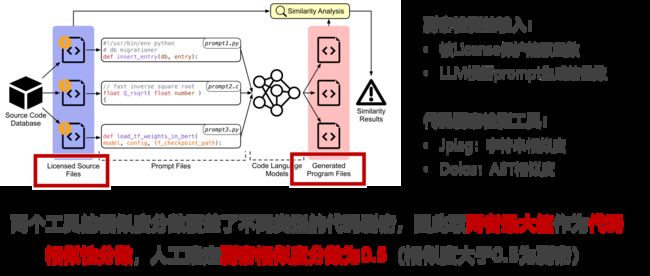
实验评估
评估指标
Expected Maximum (EM)
由1K个bootstrapped样本的最大得分的平均值计算的期望最大相似度
EM评分衡量生成代码与已有代码最相似的情况 【剽窃程度】
Empirical Probability (EP)
在样本中至少生成一次评分为> 0.5的代码的平均概率
EP评分反映了模型生成侵权代码的频率 【剽窃概率】
实验设置
- 10个待测模型:
GPT-4
ChatGPT
Copilot
Codex
CodeT5-large
CodeT5-ntp-py
CodeParrot-110M
CodeParrot-1.5B
CodeGen-350M
CodeGen-2.7B - 其他设置:
每个Prompt在每个模型上进行50 generations
侵权情况评估结果
随着越来越多的用户使用GPT进行代码生成,采取措施解决代码侵权问题成为当务之急!
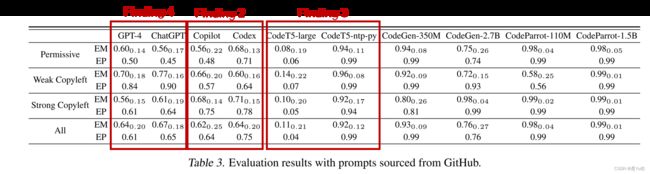
- Finding 1:大多数模型会在
50 generations内生成侵权代码,且概率较高 - Finding 2:商用软件Copilot和Codex实现了相对更低的EM和EP(可能因为其在更大的语料库训练)
- Finding 3:
CodeT5-large的相似分数最低(人工检查发现其生成的代码大多是错误的)
CodeT5-large-ntp-py就显示了更高的EM和EP(因为其采用了额外的python项目对CodeT5-large进行了微调) - Finding 4:
GPT-4和ChatGPT虽然是针对自然语言,但表现和商用代码大模型(Copilot,Codex)近似
因为其训练数据包含了800万个网页,其中就包含被license保护的代码网页
用户的输入被额外纳入模型训练的机制进一步强化了该问题
影响因素分析——Generation
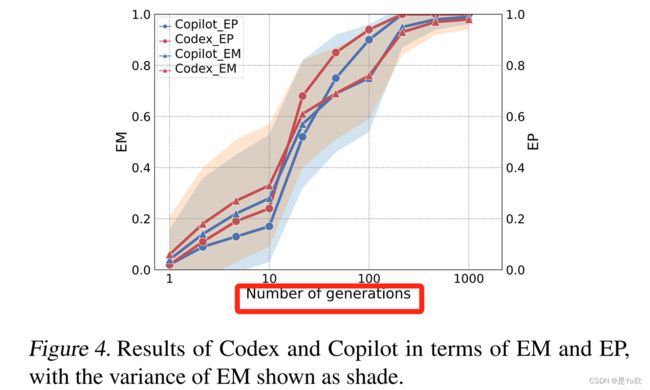
这两个模型可以在generation 100内生成高度相似的代码,其概率为p > 0.9
EM和EP都随着n的增大而增大,因为更多的试验会生成更多代码
当n非常小或非常大时,会非常困难或很容易遇到抄袭现有代码,因此下文的研究均保持generation为50
影响因素分析——编程语言
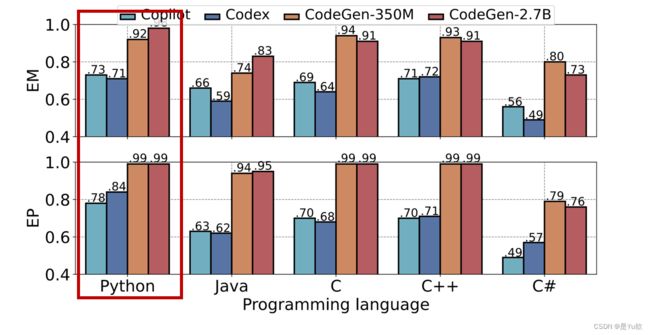
- 不同编程语言的侵权情况
差异不大 - Python的EM和EP较高
- Codex和Copilot这两种商业产品都声称最擅长Python的代码生成
- 其他开源模型的训练集中Python程序的占比较大
影响因素分析——训练数据
预想:一些Prompt会从训练数据中的源代码获得,这种Prompt生成的代码重复性会更高
实验:构建了每个模型训练数据以外的Prompt,即过滤掉该模型训练数据的Prompt进行实验
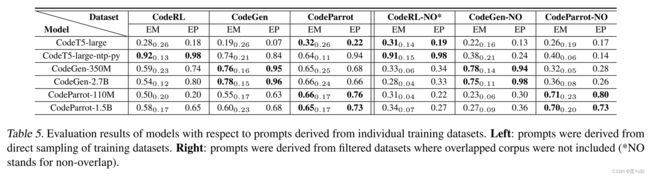
- 来自
过滤数据集的Prompt也产生了相对较高的分数,尽管它们没有用于训练 模型规模并没有显著影响代码的复制能力
例如,CodeGen和CodeParrot框架下的两个模型,模型规模相差约10x,但结果相似
实验现象的根本原因分析
分析对象

训练数据集调研结果——License分布
所有训练集中都包含了有限制性许可的源代码

训练数据集调研结果——数据集中重叠的限制性代码
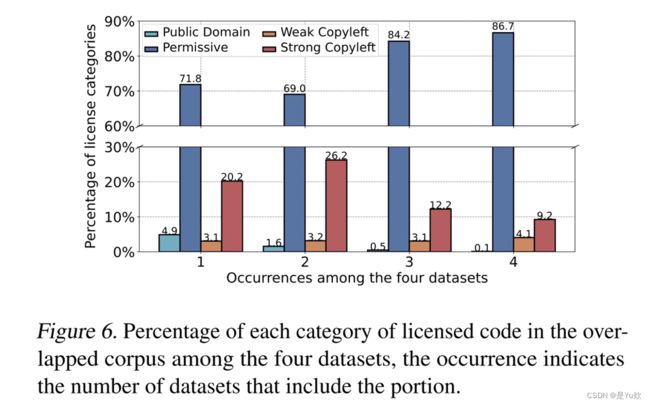

不同训练数据集包含了大量共享的限制性代码- 重叠数据大部分是
Permissive许可,也有很大一部分是Copyleft许可
因此,必须仔细考虑数据的许可组成,以确保遵守许可并保护知识产权
训练数据集调研结果——隐性包含的许可限制代码
现存问题:
- 弱许可证的代码仓库中可能隐性包含了强许可证保护的代码
调研内容:
- 根据四个数据集构建了一个无重叠的代码数据库
- 抽样检查代码是否来自更严格许可证保护的开源项目
调研结果:
发现了353个违规行为,占抽样数量的0.1%
- 268个库是从强copyleft许可代码派生出来的,但它们并没有在强copyleft下获得许可
- 14个库是从Permisive许可代码派生出来的,但它们在不需要任何限制的公共许可下发布
- 可能有很多项目的部分代码来自许可限制性仓库,而没有提供适当的许可或属性
根本原因

为什么代码大模型生成的代码存在侵权的现象?
- 代码大模型的训练数据集中包含了大量受版权保护的源代码仓库
- 侵权的训练数据在常用训练集中非常普遍,甚至重复出现
- 由于开发不规范,很多弱保护的代码仓库中存在强保护的代码片段,甚至其本身就派生自更强保护的代码仓库
可能的缓解策略
该研究建议使用公共数据对模型进行微调以减少侵权,并引入动态令牌过滤方法。然而,这些策略并不能完全解决问题,并可能影响代码生成性能。

微调模型:进一步用公共数据调优模型使得大模型更倾向于生成限制较少的代码
动态Token过滤:每次只解码k个token,并使用CODEIPPROMPT框架评估相似性
如果分数高于0.5,则回滚一个token并从其余选项中进行选择
缓解策略测试结果

两种策略在降低代码的可重复性方面都是有用的
- 基于Fine-tune的方式
降低重复性的表现并不明显 - 基于动态过滤的方式虽然有效
缓解了代码生成的侵权现象,但是代码生成的效果变差
这两种方法都不能完全解决问题,而且可能会以降低代码生成性能为代价
局限思考
潜在的解决方法
如从训练数据集中移除限制性代码,并探索更智能的模型架构,以平衡代码质量与知识产权保护。
通过删除限制性代码缓解侵权
- 简单删除训练数据集中强copyleft保护的仓库不一定有效(文件粒度和函数粒度存在侵权)需要更细粒度的数据清洗
通过可控的代码生成缓解侵权(优化动态过滤策略)
- 平衡代码生成质量和减缓侵权
通过启用更智能的模型缓解侵权
- 目前即使是最先进的模型似乎也只是简单地复制了以前学到的信息
- 因此,从知识产权保护的角度探索改进的模型体系结构可能是一个有价值的未来工作方向