微服务技术栈学习
微服务案例
父工程依赖
UTF-8
UTF-8
1.8
Hoxton.SR10
5.1.47
2.1.1
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
mysql
mysql-connector-java
${mysql.version}
org.mybatis.spring.boot
mybatis-spring-boot-starter
${mybatis.version}
org.projectlombok
lombok
微服务远程调用
注册RestTemplate对象bean (org.springframework.web.client.RestTemplate)
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}RestTemplate使用
//远程调用
String url = "http://localhost:8081/user/" + order.getUserId();
User user = restTemplate.getForObject(url, User.class);
order.setUser(user);消费者与提供者
一个服务既可以是提供者, 也可以是消费者(相对于具体业务).
Eureka注册中心
角色: 1.EurekaServer:服务端, 注册中心. 作用:记录服务信息, 监控心跳.
2.EurekaClient:客户端, 服务提供者或消费者.
搭建EurekaServer
1.依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-server
2.配置类开启(@EnableEurekaServer注解)
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}3.yml配置
server:
port: 10086
spring:
application:
name: eurekaserver #服务名称
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka #地址信息eureka服务注册
1.依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
2.配置文件
spring:
application:
name: userservice #服务名称
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka #地址信息服务拉取
1.url改成服务名称
String url = "http://userservice/user/" + order.getUserId();2. RestTemplate对象bean上加@LoadBalanced注解(负载均衡)
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}Ribbon负载均衡
策略

自定义负载均衡规则
方式一: 配置类注入Irule接口的bean (作用于全局)
@Bean
public IRule randomRule(){
return new RandomRule();
}方式二: 配置文件 (针对某个微服务)
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则 饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true #开启饥饿加载
clients:
- userserviceNacos注册中心
服务注册到Nacos
nacos管理依赖
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2.2.5.RELEASE
pom
import
nacos客户端依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
客户端配置
spring:
cloud:
nacos:
server-addr: localhost:8848Nacos服务分级存储模型
配置
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: SH根据集群负载均衡
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 根据权重负载均衡
nacos服务端网址设置

环境隔离-namespace
配置
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: b2d3c641-14d0-4ccd-a404-1ba97abe4198 #dev环境注:
①每个namespace都有唯一id.
②服务设置namespace时要写id而不是名称.
③不同namespace下的服务互相不可见.
临时实例和非临时实例
配置
cloud:
nacos:
server-addr: localhost:8848
discovery:
ephemeral: false #是否是临时实例nacos与eureka异同
Nacos配置管理
依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
配置bootstrap.yaml文件(引导文件, 优先级比application.yml高)
spring:
application:
name: userservice
profiles:
active: dev
cloud:
nacos:
server-addr: localhost:8848
config:
file-extension: yaml
namespace: b2d3c641-14d0-4ccd-a404-1ba97abe4198配置热更新
方式一
@RefreshScope注解加类上
方式二
定义属性类
@ConfigurationProperties
@Data
@Component
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}多环境共享配置
微服务启动时会从nacos读取多个配置文件:
无论profile如何变化,[spring.application.name].yaml这个文件一定会加载,因此多环境共享配置可以写入这个文件
优先级: 环境配置 > 环境共享配置 > 本地配置
Nacos集群搭建
资源资料详细文档.
基于Feign远程调用
依赖
org.springframework.cloud
spring-cloud-starter-openfeign
开启feign
配置类加@EnableFeignClients
接口声明
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}使用
ser user = userClient.findById(order.getUserId());注: feigh内部继承了负载均衡.
自定义Feigh的配置

配置方式:
1.配置
feign:
client:
config:
default:
loggerLevel: FULL2.java代码
全局有效(启动类注解加defaultConfiguration属性)
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)局部配置(具体client接口上注解加configuration属性)
@FeignClient(value = "userservice", configuration = FeignClientConfiguration.class) Feigh的性能优化
使用连接池代替默认的URLConnection
依赖
io.github.openfeign
feign-httpclient
配置
feign:
httpclient:
enabled: true
max-connections: 200
max-connections-per-route: 50Feign的最佳实践
方式一(继承):给消费者的FeignClient和提供者的controller定义统一的父接口作为标准.
方式二(抽取):将FeignClient抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用.
统一网关Gateway
功能
1.身份认证和权限校验
2.服务路由、负载均衡
3.请求限流
搭建网关服务
依赖
org.springframework.cloud
spring-cloud-starter-gateway
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
配置
server:
port: 10010
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848
gateway:
routes:
- id: user-service #路由标识, 必须唯一
uri: lb://userservice #路由的目标地址
predicates: #路由断言, 判断请求是否符合规则
- Path=/user/**
- id: order-service
uri: lb://orderservice
predicates:
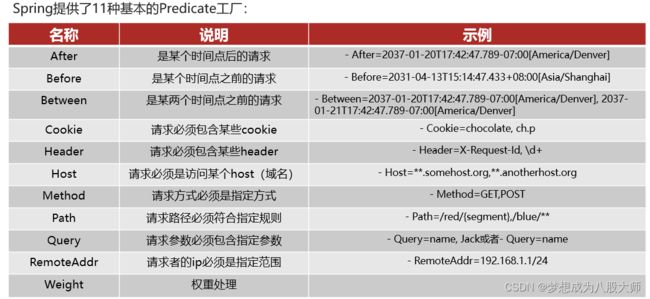
- Path=/order/**路由断言工厂
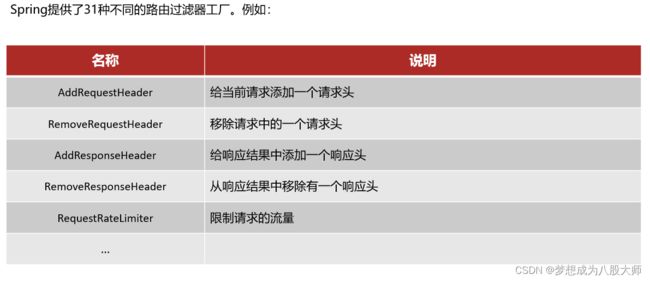
路由过滤器
作用: GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理.
普通过滤器(只对一个路由生效)
filters:
- AddRequestHeader=Truth, hard to get!默认过滤器(对所有路由生效)
default-filters:
- AddRequestHeader=Truth, hard to get!全局过滤器
作用: 完全自定义处理逻辑
//@Order(-1) //过滤器顺序, 数字越小优先级越高, 执行顺序越靠前
@Component
public class AuthorizeFilter implements GlobalFilter, Ordered {
@Override
public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
MultiValueMap params = request.getQueryParams();
String auth = params.getFirst("authorization");
if ("admin".equals(auth))
return chain.filter(exchange);
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
@Override
public int getOrder() {
return -1;
}
} 过滤器执行顺序
每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前
GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
跨域问题处理
解决方案:CORS
网关配置
spring:
cloud:
gateway:
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "http://www.leyou.com"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期Docker
原理
Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
Docker应用运行在容器中,使用沙箱机制,相互隔离
镜像和容器
镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器做隔离,对外不可见。
基本操作
镜像相关
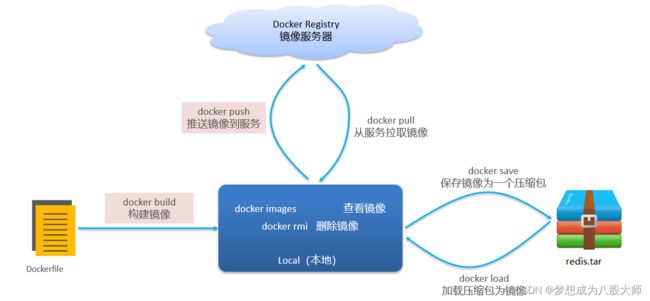
容器相关

数据卷
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
挂载数据卷

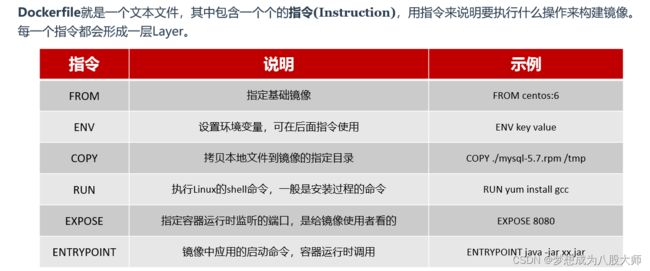
自定义镜像
Dockerfile
DockerCompose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
Docker镜像仓库
见ppt
MQ
入门程序(原生写法)
依赖
org.springframework.boot
spring-boot-starter-amqp
publisher
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.174.131");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();consumer
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.174.131");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");SpringAMQP
依赖
org.springframework.boot
spring-boot-starter-amqp
配置
spring:
rabbitmq:
host: 192.168.174.131
port: 5672
username: itcast
password: 123321
virtual-host: /使用(发消息)
String queueName = "simple.queue";
String message = "hello, spring amqp!";
rabbitTemplate.convertAndSend(queueName, message);consumer
配置
spring:
rabbitmq:
host: 192.168.174.131
port: 5672
username: itcast
password: 123321
virtual-host: /监听
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg){
System.out.println("消费者接收到simple.queue消息: " + msg);
}
}work queue

修改application.yml文件,设置preFetch这个值,可以控制预取消息的上限:
spring:
rabbitmq:
host: 192.168.174.131
port: 5672
username: itcast
password: 123321
virtual-host: /
listener:
simple:
prefetch: 1 #每次只能获取一条消息,处理完成才能获取下一个消息发布( Publish )、订阅( Subscribe )

Fanout Exchange

声明绑定
@Configuration
public class FanoutConfig {
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("itcast.fanout");
}
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
@Bean
public Binding fanoutBinding(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder
.bind(fanoutQueue1)
.to(fanoutExchange);
}
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
@Bean
public Binding fanoutBinding2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder
.bind(fanoutQueue2)
.to(fanoutExchange);
}
}监听
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg){
System.out.println("消费者接收到fanout.queue1消息: " + msg);
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg){
System.out.println("消费者接收到fanout.queue2消息: " + msg);
}DirectExchange
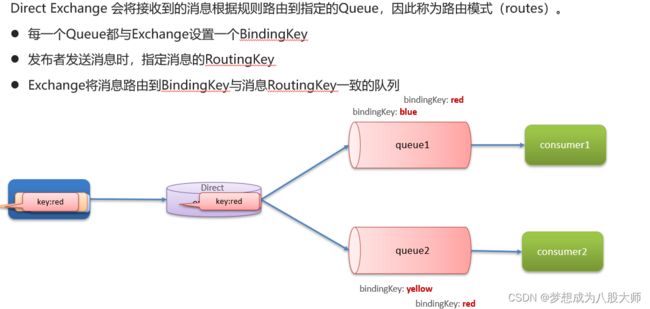
@RabbitListener注解 声明绑定(消费者)
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue(String msg){
System.out.println("消费者接收到direct.queue1的消息: " + msg);
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息: " + msg);
}TopicExchange

@RabbitListener注解 声明绑定(消费者)
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者接收到topic.queue1的消息: " + msg);
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者接收到topic.queue2的消息: " + msg);
}消息转换器
Spring的对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter来处理的。而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。
如果要修改只需要定义一个MessageConverter 类型的Bean即可。推荐用JSON方式序列化,
依赖
com.fasterxml.jackson.core
jackson-databind
配置消息转换器
@Bean
public MessageConverter messageConverter(){
return new Jackson2JsonMessageConverter();
}注:
SpringAMQP中消息的序列化和反序列化是怎么实现的?
•利用MessageConverter实现的,默认是JDK的序列化
•注意发送方与接收方必须使用相同的MessageConverter
elasticsearch (ES)
正向索引和倒排索引
elasticsearch采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语
概念对比

架构
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
IK分词器
扩展词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
IK Analyzer 扩展配置
ext.dic
然后在名为ext.dic的文件中,添加想要拓展的词语即可
停用词库
要禁用某些敏感词条,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件
IK Analyzer 扩展配置
ext.dic
stopword.dic
然后在名为stopword.dic的文件中,添加想要拓展的词语即可.
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
创建索引库
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
查看、删除索引库
查看
GET /索引库名
删除
DELETE /索引库名
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
添加文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
查看,删除文档
查看
GET /索引库名/_doc/文档id
删除
DELETE /索引库名/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
RestClient操作索引库
mapping
1.ES中支持两种地理坐标数据类型:
2.字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段。示例:
"all": {
"type": "text",
"analyzer": "ik_max_word"
},
"brand": {
"type": "keyword",
"copy_to": "all"
}
初始化JavaRestClient
依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.12.1
初始化
private RestHighLevelClient client;
@Test
void testInit(){
System.out.println(client);
}
@BeforeEach
void SetUp(){
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.174.131:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}创建索引库
//1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
//2.准备DSL语句
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
//3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);删除索引库
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request, RequestOptions.DEFAULT);查询索引库是否存在
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);RestClient操作文档
新增文档
Hotel hotel = hotelService.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);查询文档
Hotel hotel = hotelService.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);局部更新文档
UpdateRequest request = new UpdateRequest("hotel", "36934");
request.doc(
"price", "999999999",
"starName", "四钻"
);
client.update(request, RequestOptions.DEFAULT);删除文档
DeleteRequest request = new DeleteRequest("hotel", "36934");
client.delete(request, RequestOptions.DEFAULT);批量导入文档
BulkRequest request = new BulkRequest();
List hotels = hotelService.list();
for (Hotel hotel : hotels) {
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
client.bulk(request, RequestOptions.DEFAULT); 分布式搜索
DSL Query基本语法
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
查询所有
GET /hotel/_search
{
"query": {
"match_all": {}
}
}全文检索查询
单个字段
GET /hotel/_search
{
"query": {
"match": {
"all": "如家外滩"
}
}
}多个字段
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "如家外滩",
"fields": ["brand", "name", "business"]
}
}
}精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
term
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "杭州"
}
}
}
}range
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
}地理查询
geo_distance:查询到指定中心点小于某个距离值的所有文档
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance": "15km",
"location": "31.21, 121.5"
}
}
}复合查询 fuction score
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序

GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}复合查询 Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}搜索结果处理
排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段和排序方式ASC、DESC
}
]
}
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
深度分页问题
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from = 990,size =10的数据:
如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上限是10000
深度分页解决方案
针对深度分页,ES提供了两种解决方案,官方文档:
高亮
高亮:就是在搜索结果中把搜索关键字突出显示。
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name":{
"require_field_match": "false"
}
}
}
}RestClient查询文档
快速入门
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共" + total);
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
System.out.println(response);全文检索查询
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all", "如家"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共" + total);
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
System.out.println(response);复合查询
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);排序和分页
int page = 1, size = 5;
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
request.source().sort("price", SortOrder.ASC);
request.source().from((page - 1) * size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);高亮
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("all", "如家"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);案例
@Service
public class HotelService extends ServiceImpl implements IHotelService {
@Autowired
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
buildBasicQuery(params, request);
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
String location = params.getLocation();
if (location != null && !location.equals("")){
request.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint(location))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS));
}
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildBasicQuery(RequestParams params, SearchRequest request) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
String key = params.getKey();
if (key == null || "".equals(key)){
boolQuery.must(QueryBuilders.matchAllQuery());
}else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
if (params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
if (params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
if (params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
if (params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//算分控制
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(
//原始查询
boolQuery,
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
//一个function score元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//过滤条件
QueryBuilders.termQuery("isAD", true),
//算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
private PageResult handleResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
SearchHit[] hits = searchHits.getHits();
List hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
Object[] sortValues = hit.getSortValues();
if (sortValues.length > 0) {
Object sortValue = sortValues[0];
hotelDoc.setDistance(sortValue);
}
hotels.add(hotelDoc);
}
return new PageResult(total, hotels);
}
}
聚合
DSL实现Bucket聚合
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以修改结果排序方式:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
DSL实现Metrics 聚合
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
RestAPI实现聚合
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(10)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brandAgg");
List buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}自动补全
拼音分词器
见文档..
自定义分词器
我们可以在创建索引库时,通过settings来配置自定义的analyzer(分词器:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "pinyin"
}
}
}
}
}
注:拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
因此字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器;
completion suggester查询
1.参与补全查询的字段必须是completion类型。
2.字段的内容一般是用来补全的多个词条形成的数组。
// 创建索引库PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
查询
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
RestAPI实现自动补全
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("sd")
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List options = suggestions.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
System.out.println(text);
} 数据同步


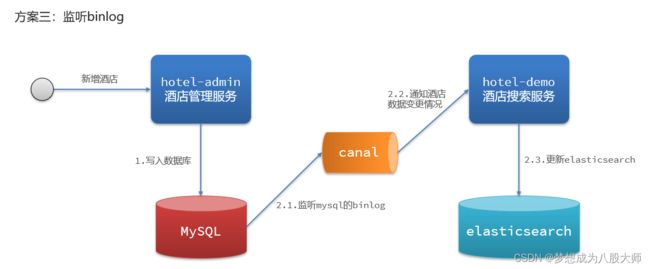
方式一:同步调用
方式二:异步通知
方式三:监听binlog
微服务保护
雪崩问题
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
雪崩解决
1.超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待.
2.舱壁模式:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。
3.熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
4.流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。
Sentinel
整合
依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
配置
sentinel:
transport:
dashboard: localhost:8080流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
链路
Sentinel默认只标记Controller中的方法为资源,如果要标记其它方法,需要利用@SentinelResource注解,示例:
@SentinelResource("goods")
public void queryGoods(){
System.err.println("查询商品");
}Sentinel默认会将Controller方法做context整合,导致链路模式的流控失效,需要修改application.yml,添加配置:
web-context-unify: false流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
warm up
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 threshold / coldFactor,持续指定时长后,逐渐提高到threshold值。
排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
注: 热点参数限流对默认的SpringMVC资源无效.
隔离降级
Feign整合Sentinel
1.修改OrderService的application.yml文件,开启Feign的Sentinel功能
feign:
sentinel:
enabled: true2.给FeignClient编写失败后的降级逻辑
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
log.error("查询用户异常", throwable);
return new User();
}
};
}
} 3.在feing-api项目中的DefaultFeignConfiguration类中将UserClientFallbackFactory注册为一个Bean:
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}4.在feing-api项目中的UserClient接口中使用UserClientFallbackFactory:
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)线程隔离
线程隔离有两种方式实现:

熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。

熔断策略-慢调用
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
熔断策略-异常比例
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
授权规则
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
编写授权规则
@Component
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
String origin = request.getHeader("origin");
if (StringUtils.isEmpty(origin)){
origin = "blank";
}
return origin;
}
}自定义异常结果
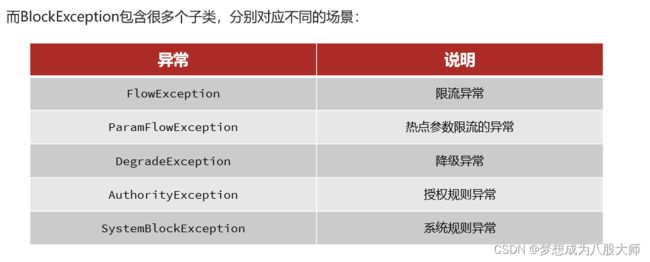
规则持久化
原始模式:控制台配置的规则直接推送到Sentinel客户端,也就是我们的应用。然后保存在内存中,服务重启则丢失
pull模式:控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
push模式:控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。
push实现
依赖
com.alibaba.csp
sentinel-datasource-nacos
配置
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules
groupId: SENTINEL_GROUP
rule-type: flow # 还可以是:degrade、authority、param-flow分布式事务
CAP定理
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标:
Eric Brewer 说,分布式系统无法同时满足这三个指标。
这个结论就叫做 CAP 定理。
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝
Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
Seata
Seata事务管理中有三个重要的角色:
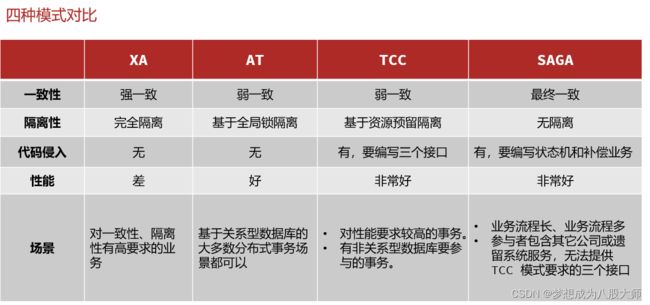
Seata提供了四种不同的分布式事务解决方案:
微服务集成seata
依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
io.seata
seata-spring-boot-starter
io.seata
seata-spring-boot-starter
${seata.version}
配置
seata:
registry:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
namespace: ""
group: DEFAULT_GROUP
application: seata-tc-server
username: nacos
password: nacos
tx-service-group: seata-demo
service:
vgroup-mapping:
seata-demo: SH注: jdk用1.8, 17会报错
XA模式


配置
data-source-proxy-mode: XA注解
@GlobalTransactionalAT模式
阶段一RM的工作:
阶段二提交时RM的工作:
阶段二回滚时RM的工作:
AT模式写隔离

TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:

TCC的空回滚和业务悬挂
当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。
对于已经空回滚的业务,如果以后继续执行try,就永远不可能confirm或cancel,这就是业务悬挂。应当阻止执行空回滚后的try操作,避免悬挂.
实现
声明
TCC的Try、Confirm、Cancel方法都需要在接口中基于注解来声明,语法如下:
@LocalTCC
public interface AccountTCCService {
@TwoPhaseBusinessAction(name = "deduct", commitMethod = "confirm", rollbackMethod = "cancel")
void deduct(@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money") int money);
boolean confirm(BusinessActionContext ctx);
boolean cancel(BusinessActionContext ctx);
}编写逻辑
@Slf4j
@Service
public class AccountTCCServiceImpl implements AccountTCCService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper freezeMapper;
@Override
@Transactional
public void deduct(String userId, int money) {
String xid = RootContext.getXID();
AccountFreeze oldFreeze = freezeMapper.selectById(xid);
if (oldFreeze != null){
return;
}
accountMapper.deduct(userId, money);
AccountFreeze freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(money);
freeze.setState(AccountFreeze.State.TRY);
freeze.setXid(xid);
freezeMapper.insert(freeze);
}
@Override
public boolean confirm(BusinessActionContext ctx) {
String xid = ctx.getXid();
int count = freezeMapper.deleteById(xid);
return count == 1;
}
@Override
public boolean cancel(BusinessActionContext ctx) {
String xid = ctx.getXid();
String userId = ctx.getActionContext("userId").toString();
AccountFreeze freeze = freezeMapper.selectById(xid);
if (freeze == null){
freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(0);
freeze.setState(AccountFreeze.State.CANCEL);
freeze.setXid(xid);
freezeMapper.insert(freeze);
return true;
}
if (freeze.getState() == AccountFreeze.State.CANCEL){
return true;
}
accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney());
freeze.setFreezeMoney(0);
freeze.setState(AccountFreeze.State.CANCEL);
int count = freezeMapper.updateById(freeze);
return count == 1;
}
}Saga模式
Saga模式是SEATA提供的长事务解决方案。也分为两个阶段:
Saga模式优点:
缺点:
没有锁,没有事务隔离,会有脏写
总结
MQ高级
消息可靠性问题
生产者确认机制
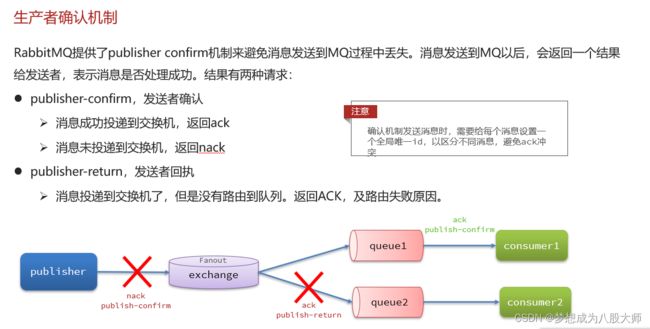
SpringAMQP实现生产者确认
配置

代码
@Slf4j
@Configuration
public class CommonConfig implements ApplicationContextAware {
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.error("消息发送到队列失败, 响应码: {}, 失败原因: {}, 交换机: {}, 路由key: {}, 消息: {}",
replyCode, replyText, exchange, routingKey, message);
});
}
}@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
correlationData.getFuture().addCallback(result -> {
if (result.isAck()){
log.debug("消息成功投递到交换机! 消息ID: {}", correlationData.getId());
}else {
log.error("消息投递到交换机失败! 消息ID: {}", correlationData.getId());
}
}, ex -> {
log.error("消息发送失败!", ex);
});
String message = "hello, spring amqp!";
rabbitTemplate.convertAndSend("amq.topic", "a.simple.test", message, correlationData);
}消息持久化
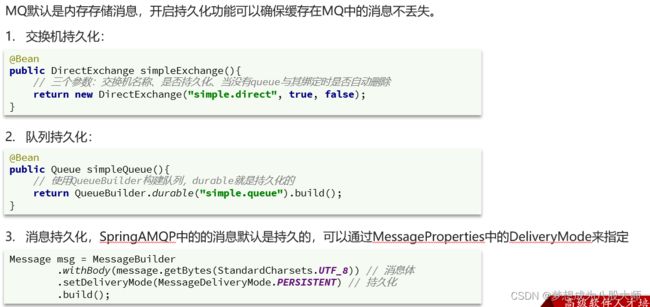
消费者消息确认

消费者失败重试
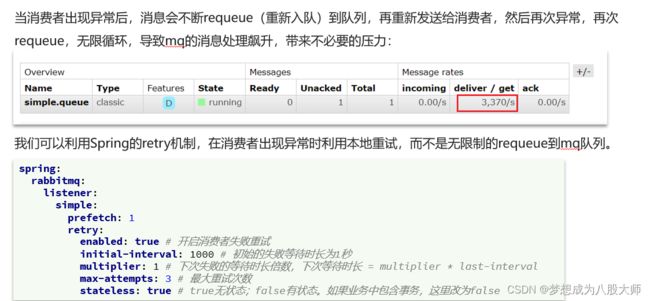
消费者失败消息处理策略
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
代码
@Configuration
public class ErrorMessageConfig {
@Bean
public DirectExchange errorMessageExchange(){
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){
return new Queue("error.queue");
}
@Bean
public Binding errorMessageBinding(){
return BindingBuilder.bind(errorQueue()).to(errorMessageExchange()).with("error");
}
@Bean
public MessageRecoverer republishMessageRecover(RabbitTemplate rabbitTemplate){
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
}总结
如何确保RabbitMQ消息的可靠性?
死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
如果该队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,简称DLX)。
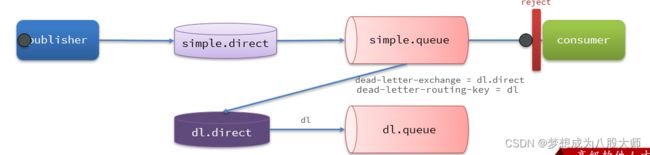
@Bean
public Queue ttlQueue(){
return QueueBuilder.durable("ttl.queue")
.ttl(10000)
.deadLetterExchange("dl.direct")
.deadLetterRoutingKey("dl")
.build();
}
TTL
TTL,也就是Time-To-Live。如果一个队列中的消息TTL结束仍未消费,则会变为死信,ttl超时分为两种情况:
给队列设置TTL
@Bean
public Queue ttlQueue(){
return QueueBuilder.durable("ttl.queue")
.ttl(10000)
.deadLetterExchange("dl.direct")
.deadLetterRoutingKey("dl")
.build();
}给消息设置TTL
Message message = MessageBuilder
.withBody("hello, ttl message".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
.setExpiration("5000")
.build();
rabbitTemplate.convertAndSend("ttl.direct", "ttl", message);延迟队列
利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
延迟队列插件: 因为延迟队列的需求非常多,所以RabbitMQ的官方也推出了一个插件,原生支持延迟队列效果。
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "delay.queue", durable = "true"),
exchange = @Exchange(value = "delay.direct", delayed = "true"),
key = "delay"
))
public void listenDelayExchange(){
log.info("消费者接收到了delay.queue的延迟消息");
}
@Test
public void testSendDelayMessage() throws InterruptedException {
Message message = MessageBuilder
.withBody("hello, ttl message".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
.setHeader("x-delay", 5000)
.build();
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend("delay.direct", "delay", message, correlationData);
log.info("发送消息成功!");
}消息堆积及惰性队列
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。最早接收到的消息,可能就会成为死信,会被丢弃,这就是消息堆积问题。
惰性队列的特征如下:
@Bean
public Queue lazyQueue(){
return QueueBuilder.durable("lazy.queue")
.lazy()
.build();
}总结:
惰性队列的优点有哪些?
惰性队列的缺点有哪些?
MQ集群
普通集群
镜像集群
镜像集群:本质是主从模式,具备下面的特征:
仲裁队列
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列,具备下列特征: