kafka介绍
目录
一、kafka介绍
1.kafka简单介绍
2.kafka使用场景
3.kafka基本概念
4.kafka的安装
5.java实现消息的生产和消费
优秀的程序架构设计需要遵循的守则:低耦合,高内聚。
一、kafka介绍
1.kafka简单介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
2.kafka使用场景
1,日志收集:可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
2,消息系统:解耦生产和消费者,缓存消息。
3,用户活动追踪:kafka可以记录webapp或app用户的各种活动,如浏览网页,点击等活动,这些活动可以发送到kafka,然后订阅者通过订阅这些消息来做监控。
4,运营指标:可以用于监控各种数据。
3.kafka基本概念
kafka是一个分布式的分区的消息,提供消息系统应该具备的功能。
| 名称 | 解释 |
|---|---|
| broker | 消息中间件处理节点,一个broker就是一个kafka节点,多个broker构成一个kafka集群。 |
| topic | kafka根据消息进行分类,发布到kafka的每个消息都有一个对应的topic |
| producer | 消息生产(发布)者 |
| consumer | 消息消费(订阅)者 |
| consumergroup | 消息订阅集群,一个消息可以被多个consumergroup消费,但是一个consumergroup只有一个consumer可以消费消息。 |
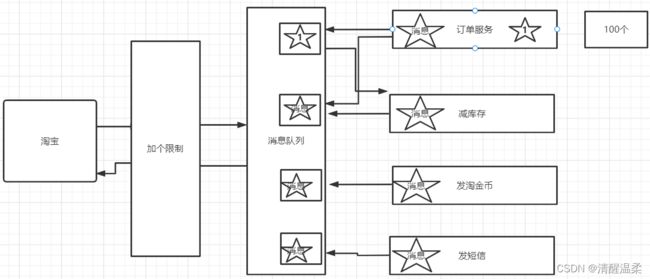
比如我们1号消息只能被我们订单服务的订阅集群消费,
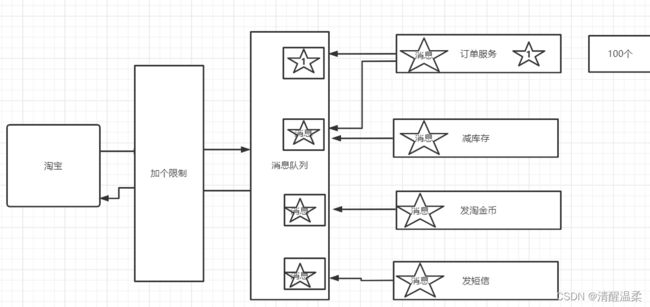
如果减库存的也订阅了,减库存的也能收到1号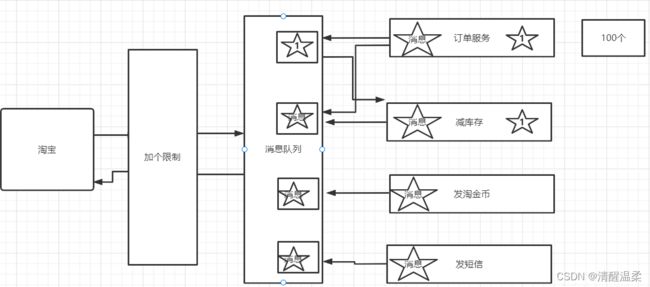
但是两个集群中只能有一个服务去消费1号。
4.kafka的安装
#下载安装包并解压
tar -xzvf
#修改配置文件
#默认端口号
#修改日志位置
#zk地址
#启动
./kafka-server-start.sh -daemon ../config/server.properties首先进到服务器里面:(我这里已经安装好了)
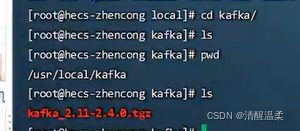
cd /cd /usr/local
lsmkdir kafka
ls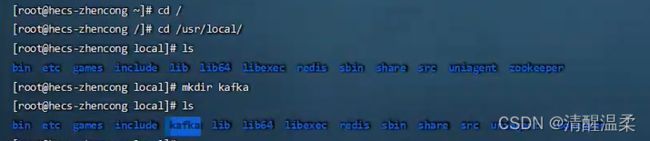
cd kafka/
ls
pwd第一步、将kafka的包放入服务器里。
第二步、解压
tar -xzvf kafka_2.11-2.4.0.tgz解压完成![]()
进入里面
cd kafka_2.11-2.4.0
ls
进入bin目录里面
cd bin/
ls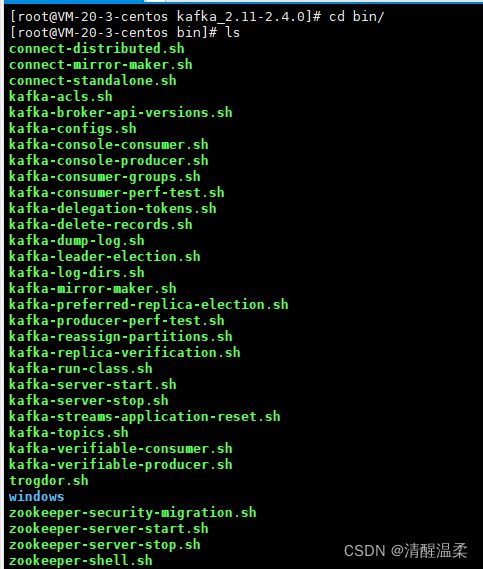
很多sh命令(脚本)
退出去
看一下condig 里面也有很多配置文件
cd ../
cd config/
ls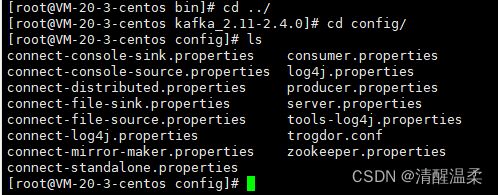
进入
vim server.properties编辑状态, broker.id=0 代表一个集群
找到listeners放开 端口号要监听哪个,监听本机的,所以改成本机的。
listeners=PLAINTEXT://127.0.0.1:9092
找到这个 即修改文件日志 改为 log.dirs=/usr/local/kafka/kafka-logs //用自己的
找到 zookeeper.connect=116.63.178.139:2181 //配置zookeeper
然后保存一下(:wq)。
之后进入bin里
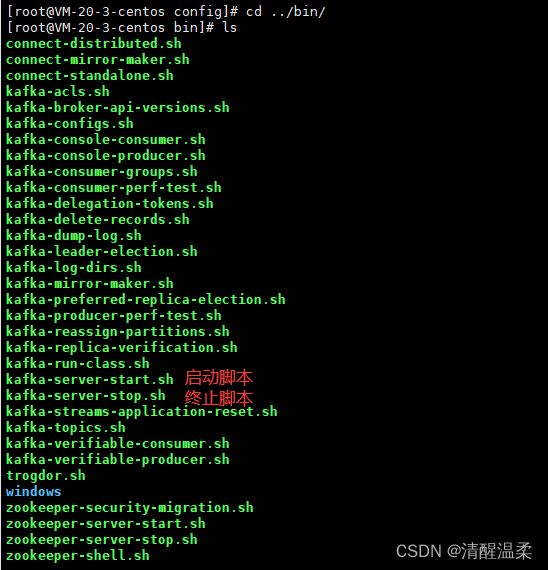
以守护线程运行
./kafka-server-start.sh -daemon ../config/server.properties
或者进到config里
咱们刚刚已经改了9092端口,查看端口是否打开 (lsof -i:9092)

5.java实现消息的生产和消费
引入maven依赖
org.apache.kafka
kafka-clients
2.1.0
生产者代码
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* @author zhencong
* @title: Kafkapro
* @projectName kafkapro
* @description: TODO
* @date 2022/3/24下午 02:55
*/
public class Kafkapro {
public static void main(String[] s){
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.129.129:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = null;
try {
producer = new KafkaProducer<>(properties);
for (int i = 0; i < 100; i++) {
String msg = "Message " + i;
producer.send(new ProducerRecord<>("test", msg));
System.out.println("Sent:" + msg);
}
producer.send(new ProducerRecord<>("test", "msg"));
System.out.println("Sent:" + "msg");
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}
消息生产成功
消费者代码
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author zhencong
* @title: Kafkacus
* @projectName kafkacus
* @description: TODO
* @date 2022/3/24下午 03:07
*/
public class Kafkacus {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.129.129:9092");
properties.put("group.id", "group-1");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("test"));
while (true) {
ConsumerRecords records = kafkaConsumer.poll(10000);
for (ConsumerRecord record : records) {
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
}
} 消息消费成功