客观题测试-第3章栈和队列
详解版
有问题或有错误欢迎交流与指正
第1关: 栈和队列客观题测试(一)
1、栈和队列具有相同的()。
A、抽象数据类型
B、逻辑结构
C、存储结构
D、运算
解:逻辑结构主要包含集合、线性结构、树形结构和图形结构。栈和队列是两种常见的数据结构,它们在逻辑结构上是一致的,都属于线性结构。线性结构是一种数据结构,它包含的元素之间有一对一的关系,这种数据结构可以看作是一条线,一头有一个端点,另一头也可以有一个端点。栈和队列都符合这个定义。但是,栈和队列在操作方式上有所不同。栈遵循后进先出(LIFO)的原则,也就是说最后一个进入栈的元素会第一个出来。而队列遵循先进先出(FIFO)的原则,也就是说第一个进入队列的元素会第一个出来。这就是它们的主要区别。此外,栈和队列的存储结构也可以不同,可以选择不同的实现方式,比如数组或链表等。但这些存储结构的不同并不会影响它们的逻辑结构,即它们都是线性结构。
2、栈和队列的主要区别在于()。
A、存储结构不同
B、逻辑结构不同
C、插入、删除规则不同
D、所含元素不同
3、()不是栈的基本操作。
A、删除栈顶元素
B、判断栈是否为空
C、将栈置为空栈
D、返回栈底元素
解:栈的基本操作包括:push(入栈)、pop(出栈)、top(返回栈顶元素)、isEmpty(判断栈是否为空)和clear(将栈置为空栈)。而返回栈底元素不是栈的基本操作,因为栈是一种后进先出(LIFO)的数据结构,无法直接返回栈底元素。
4、链栈不同于顺序栈的优势之处在于()。
A、插入操作更容易实现
B、删除操作更容易实现
C、通常不会出现栈满的情况
D、通常不会出现栈空的情况
解:链栈不同于顺序栈的优势之处在于它不会出现栈满的情况。链栈是通过链表实现的,其空间可以动态分配,因此不会像顺序栈那样受到固定空间的限制。所以,链栈可以有效地利用空间,避免出现栈满的情况。因此,正确答案是C、通常不会出现栈满的情况。
5、顺序栈存放在数组a[n]中,top指向栈顶,top= -1表示栈空。在栈不满的情况下,元素x进栈的操作为()。
A、a[top--]=x
B、a[--top]=x
C、a[top++]=x
D、a[++top]=x
解:栈是一种后进先出(LIFO)的数据结构,通常使用数组来实现。top是指向栈顶元素的指针,当top等于-1时,表示栈为空。在进栈操作中,需要将元素插入到数组的top位置,然后将top指针加1,以便指向下一个待插入的元素。由于top指针是整型变量,因此需要使用前缀++运算符来将其加1。因此,正确的操作应该是a[++top]=x。所以,正确答案是D、a[++top]=x。
6、一个空顺序栈的栈顶指针为top= -1,执行Push、Push、Pop、Push、Push、Pop、Pop、Push、Push操作后,栈顶指针的值为()。
A、3
B、2
C、1
D、0
7、链栈的结点表示为(data, next),top指向栈顶。则插入结点x的操作为()。
A、top->next=x
B、x->next=top; top=x
C、x->next=top; top=top->next
D、x->next=top->next;top->next=x
8、链栈的结点表示为(data, link),top指向栈顶,若想删除栈顶结点,并将删除结点的值保存到x中,则应执行操作()。
A、x = top -> data; top = top -> link
B、top = top -> link; x = top -> link
C、x = top; top = top -> link
D、x = top -> link
9、若一个栈以向量V[1,…,n]存储,初始栈顶指针top设为n+1,则元素x进栈的正确操作是( )。
A、top++; V[top]=x;
B、V[top]=x; top++;
C、top--; V[top]=x;
D、V[top]=x;top--;
10、已知入栈序列为1,2,3,…,n,输出序列为p1,p2,p3,…,pn。若p1=n,则pi为()。
A、i-1
B、n-i+1
C、n-i
D、不确定
第2关: 栈和队列客观题测试(二)
1、设a,b,c,d,e,f依次进栈,且进栈时允许出栈。则不可能得到的出栈序列是()。
A、fedcba
B、dbcafe
C、dcebaf
D、bacfed
2、用P表示进栈操作,用D表示出栈操作。进栈顺序是abcd,为了得到bcda的出栈顺序,相应的P和D的操作序列为()。
A、PDPPDPDD
B、PPPDPDDD
C、PPDDPDPD
D、PPDPDPDD
3、入栈顺序为P1, P2,…, Pn,出栈顺序为1,2,3,…,n,如果P3=1,则P1的值()。
A、一定是3
B、一定是2
C、可能是2
D、不可能是2
4、4 个不同元素依次进栈,能得到()种不同的出栈序列。
A、16
B、15
C、14
D、13
5、在递归过程调用时,为了保存返回地址,实际参数和局部变量,要求使用一种称为()的数据结构。
A、队列
B、向量
C、栈
D、字符串
6、()算法设计策略与递归技术的联系最弱。
A、回溯法
B、贪心法
C、分治法
D、减治法
解:贪心算法是一种基于贪心策略的算法,它通常在每个步骤中选择局部最优解,以期望最终得到全局最优解。贪心算法通常不使用递归技术,而是使用迭代方式实现。因此,贪心算法与其他三种算法设计策略(回溯法、分治法、减治法)相比,与递归技术的联系最弱。
7、现有16枚外形相同的硬币,其中有一枚比真币的重量轻的假币,若采用分治法找出这枚假币,需至少比较()次。
A、6
B、5
C、4
D、3
8、设一个递归算法如下:
int func(int n){
if ( n == 1 || n == 2 ) return 1;
else return func( n – 1 ) + func( n – 2 );
}则计算func(4)时需要计算func函数( )次。
A、6
B、5
C、4
D、3

9、对表达式求值时,使用运算数栈S来辅助计算。设S只有2个存储单元,则不会发生溢出的表达式是()。
A、(a+b)/c-d
B、a-b*(c+d)
C、a*(b-c*d)
D、(a-b)*(c-d)

10、一个递归算法必须包括()。
A、递归部分
B、终止条件和递归部分
C、迭代部分
D、终止条件和迭代部分
第3关:栈和队列客观题测试(三)
1、已知程序如下:
int func(int x) {
return (x <= 0) ? func( x + 1 ) + x : 0;
}
void main() {
cout << func(0);
}程序运行时使用栈来保存调用过程信息。则自栈底到栈顶保存的信息依次为( )。
A、main() -> func(1) -> func(0)
B、main() -> func(0) -> func(1)
C、func(0) -> func(1) -> main()
D、func(1) -> func(0) -> main()
2、求整数n(n>=0)阶乘的算法如下,其时间复杂度为()。
func(int n){
if( n <= 1 ) return 1;
else return ( n * func( n – 1 ) );
}A、O(log2n)
B、O(nlog2n)
C、O(n)
D、O(n2)
3、设栈的初始状态为空,当字符序列"mp3"作为栈的输入时,输出长度为3,且可以用作C语言标识符的序列有()个。
A、3
B、4
C、5
D、6
4、元素a,b,c,d,e依次入栈。在所有可能的出栈序列中,以d开头的序列个数是()。
A、3
B、4
C、5
D、6
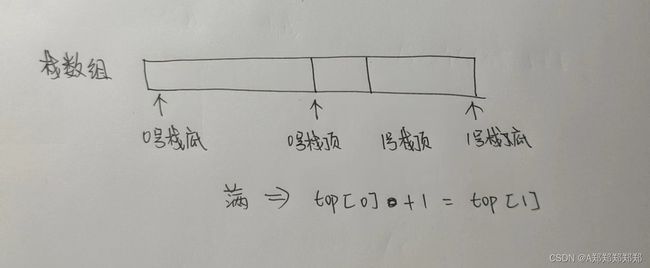
5、将编号为0和1的两个栈存放于同一个数组空间v[m]中,栈底分别处于数组的两端。0号栈的栈顶top[0]=-1时栈空;1号栈的栈顶top[1]=m时栈空。则判断此共享栈已满的条件是()。
A、top[0]==top[1]
B、top[0]+top[1]==m
C、top[0]==top[1]+1
D、top[0]==top[1]-1
6、()是队列的基本操作。
A、取出最近入队的元素
B、删除队头元素
C、在队列元素之间插入元素
D、对队列中的元素排序

7、链式存储的队列在进行删除运算时()。
A、只需要修改尾指针
B、只需要修改头指针
C、头尾指针可能都要修改
D、头尾指针一定都要修改
8、最不适合存放队列的链表是()。
A、只带队首指针的循环双链表
B、只带队尾指针的循环双链表
C、只带队首指针的普通双链表
D、只带队尾指针的循环单链表
解:在队列的基本操作中,主要涉及两种操作:入队和出队。对于链表实现的队列,通常需要保持链表的头部作为队首,以便于进行出队操作。同时,为了方便入队操作,我们通常也需要能够快速访问到链表的尾部。
A选项中的只带队首指针的循环双链表,可以方便地进行出队和入队操作。循环双链表的结构使得我们可以通过队首指针访问到链表的尾部,从而在O(1)的时间复杂度内完成入队和出队操作。
B选项中的只带队尾指针的循环双链表,同样可以方便地进行出队和入队操作。由于是循环双链表,我们可以通过队尾指针访问到链表的头部,从而在O(1)的时间复杂度内完成入队和出队操作。
C选项中的只带队首指针的普通双链表,虽然可以方便地进行出队操作,但在入队时需要遍历整个链表来找到尾部,时间复杂度为O(n)。这使得这种结构不适合作为队列的实现。
D选项中的只带队尾指针的循环单链表,可以方便地进行出队和入队操作。循环单链表的结构使得我们可以通过队尾指针访问到链表的头部,从而在O(1)的时间复杂度内完成入队和出队操作。
9、设栈S和队列Q的初始状态为空,元素a,b,c,d,e,f依次进入栈S,各元素出栈后即进入队列Q。若出队序列为c,e,d,f,b,a,则栈S的容量至少为()。
A、2
B、3
C、4
D、5
10、数组a[0…n]用来存放循环队列,则入队时的操作是()。
A、rear = rear + 1
B、rear = (rear + 1) mod (n - 1)
C、rear = (rear + 1) mod n
D、rear = (rear + 1) mod (n + 1)
第4关: 栈和队列客观题测试(四)
1、循环队列存放在数组Q[n]中。h指向头元素,t指向队尾元素的后一个位置。设队列中元素个数小于n,则队列中一共有()个元素。
A、t-h
B、(n+h-t)%n
C、(n+t-h)%n
D、n+t-h
2、循环队列存放在数组a[15]中,front指向队头元素的前一个位置,rear指向队尾元素。当front=8, rear=3时,队列的长度为()。
A、5
B、6
C、10
D、11
3、循环队列存放在数组a[0…10]中。当前rear=3,front=9。则从队列中删除2个元素,再加入1个元素后,rear和front的值为()。
A、2和7
B、4和0
C、5和10
D、5和0

4、循环队列存放在数组a[0…n]中。队列非空时front指向队头元素,rear指向队尾元素。初始时队列为空,要求第一个入队的元素存放在a[0]处,则front和rear的初始值为()。
A、0,0
B、0,n-1
C、0,n
D、n,n
解:队头和队尾
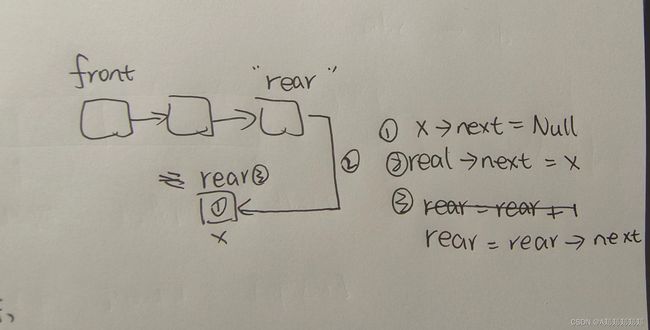
5、链队中队头指针为front,队尾指针为rear,则将指针x指向的结点插入队列需要执行的操作是()。
A、front -> next = x; front = front -> next; x -> next = NULL
B、rear -> next = x; rear = rear -> next
C、x -> next = NULL; rear -> next = x; rear = rear -> next;
D、x -> next = rear -> next; rear = x;
6、循环队列存放在数组a[0…m]中。end1指向队头元素,end2指向队尾元素的后一个位置。设队列两端都可以进行入队出队操作,且初始时为空。则判断队空和队满的条件是()。
A、队空:end1 == end2; 队满:end1 == (end2 + 1) mod m;
B、队空:end1 == end2; 队满:end1 == (end2 + 1) mod (m + 1);
C、队空:end2 == (end1 + 1) mod m; 队满:end1 == (end2 + 1) mod m;
D、队空:end1 == (end2 + 1) mod m; 队满:end2 == (end1 + 1) mod (m + 1);
7、某队列允许在其两端进行入队操作,但仅允许在一端进行出队操作,若元素a,b,c,d,e依次入此队列后再进行出队操作,则不可能得到的出队序列是()。
A、b,a,c,d,e
B、d,b,a,c,e
C、d,b,c,a,e
D、e,c,b,a,d

8、栈的应用不包括()。
A、递归调用
B、子程序调用
C、表达式求值
D、打印机缓冲区
解:栈是一种后进先出(LIFO)的数据结构,其应用包括递归调用、子程序调用和表达式求值等。而打印机缓冲区是先进先出(FIFO)的数据结构,因此不属于栈的应用。
9、设有如图所示的火车车轨,入口到出口之间有n条隧道,列车的行进方向均为从左至右。列车可以驶入任意一条轨道。现有编号1-9的9辆列车,驶入次序依次是8,3,4,2,9,5,7,6,1。若期望列车驶出的顺序依次为1-9,则n至少是( )。

A、2
B、3
C、4
D、5
10、有队列Q和栈S,初始时,Q中元素从头开始依次为1,2,3,4,5,6,S为空。若仅允许以下三种操作: (1)出队并输出出队元素 (2)出队并将出队元素入栈 (3)出栈并输出出栈元素 则不能得到的输出序列为( )。
A、6,5,4,3,2,1
B、2,3,4,5,6,1
C、1,2,4,3,5,6
D、4,5,6,1,2,3
第5关: 栈和队列客观题测试(五)
1、栈和队列具有相同的逻辑结构。
A、对
B、错
解:例如它们都是线性结构,都只允许在表的一端进行插入和删除操作。不过哈,它们在数据的排列顺序和存取方式上有着根本的区别。
2、栈和队列的主要区别是插入和删除操作的限制不同。
A、对
B、错
解:栈和队列的主要区别在于插入和删除操作的限制不同。栈是一种后进先出(LIFO)的数据结构,只能在栈顶进行插入和删除操作。而队列是一种先进先出(FIFO)的数据结构,只能在队尾进行插入操作,在队头进行删除操作。因此,它们的操作方式有很大的不同。
3、栈和队列都是线性结构。
A、对
B、错
4、栈是限制存取点的非线性结构。
A、对
B、错
5、栈的基本操作有判断栈是否为空、删除栈底元素、将栈置为空栈等。
A、对
B、错
解:栈的基本操作通常包括:判断栈是否为空、删除栈顶元素(出栈)、添加元素至栈顶(入栈),而不包括删除栈底元素或将栈置为空栈等操作。这是因为栈是后进先出(LIFO)的数据结构,只关注顶部元素,不关注底部元素。
6、链栈与顺序栈相比,更容易实现插入操作。
A、对
B、错
解:链栈与顺序栈相比,插入操作其实是一样的复杂度。因为无论是链栈还是顺序栈,插入操作都需要分配空间、复制元素。只是链栈通过链表连接每个元素,而顺序栈是在数组中连续存放元素。因此,链栈并不比顺序栈更容易实现插入操作。
7、采用非递归方式对递归程序进行改写时,必须使用栈。
A、对
B、错
解:采用非递归方式对递归程序进行改写时不一定需要使用栈。在某些情况下,可以通过循环和条件语句来模拟递归过程,而不需要使用栈。
8、函数调用时,系统使用栈来保存必要信息。
A、对
B、错
9、只要确定了入栈顺序,就可以确定出栈顺序。
A、对
B、错
解:可以出栈
10、栈是一种受限制的线性表,只允许在一端进行操作。
A、对
B、错
第6关: 栈和队列客观题测试(六)
1、队列的"先进先出"特性是指每次从队列中删除的总是最早插入的元素。
A、对
B、错
2、队列可以进行的操作有删除队头元素、向队列元素之间插入元素、对队列中元素排序等。
A、对
B、错
3、用单链表表示链式队列的队头在链表的链头位置。
A、对
B、错
4、用链式存储的队列在进行删除操作时,只需要修改尾指针。
A、对
B、错
5、在循环队列中进行插入和删除时,无须移动队列中元素的位置。
A、对
B、错
6、解决同一个问题时,使用递归算法的效率一般高于非递归算法。
A、对
B、错
解:在一些情况下,递归算法可能比非递归算法更简洁和易于实现,但在一些情况下,递归算法可能会导致大量的函数调用和额外的内存开销,从而降低算法的效率。因此,不能简单地说递归算法的效率一定高于非递归算法。
7、调用函数时,其局部变量一般存放在栈中。
A、对
B、错
8、消除递归只能使用栈。
A、对
B、错
9、对同一输入序列进行两组不同的入栈出栈组合操作,得到的输出序列也相同。
A、对
B、错
解:消除递归可以使用栈来模拟递归过程中的调用栈,以实现非递归的执行方式。但是,消除递归并不意味着只能使用栈。除了使用栈之外,还可以使用循环和条件语句等其他方式来实现非递归的执行方式。
10、栈可以用于解决迷宫求解问题。
A、对
B、错