Android事件驱动Handler-Message-Looper解析
前言
关于这方面的知识,网上已经有很多。为啥这里还要写呢?知其然,也要知其所以然,handler-message-looper的设计很巧妙,我们了解为啥要这么设计,对我们设计程序的时候也有裨益。这篇文章阐述怎么结合现象与原理分析事件驱动的本质,相信即使没看过相关知识的同学也能快速理解。
通过这篇文章你将知道:
1、如何进行线程切换
2、消息循环原理
3、子线程消息循环
4、链表实现栈和队列的
线程切换
- Q1 为什么需要线程切换
1、多线程能够提高并发效率,多线程的引入势必会有线程切换
2、多线程同时引入了线程安全问题,Android为了安全、简单地绘制UI,规定绘制UI操作只能在一个固定的线程里操作,该线程在app启动时创建,我们称之为UI线程(也称做主线城,后续简单起见,统一叫做主线城)。非主线程我们称之为子线程,当我们在子线程里进行耗时操作,并准备好需要展示的数据时,这时候需要切换到主线程更新UI
线程安全问题请移步真正理解Java Volatile的妙用
- Q2 如何切换线程
先看如何创建并启动一个线程
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
doTask1();
}
});
t1.start();
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
doTask2();
}
});
t2.start();
如上所示,t2需要等待t1执行完毕再执行,那么t2怎么知道t1完毕呢?有两种方式
1、t1主动告诉t2自己已执行完毕,属于等待通知方式(wait¬ify、condition await&signal)
2、t2不断去检测t1是否完毕,属于轮询方式
假设t1是子线程,t2是主线程,那么t1采用何种方式通知t2呢?采用第一种方式:等待-通知,通过Handler-Message-Looper实现等待-通知。
Handler发送Message
经典例子
Button button;
TextView tv;
private Handler handler = new Handler(Looper.getMainLooper(), new Handler.Callback() {
@Override
public boolean handleMessage(@NonNull Message msg) {
tv.setText(msg.arg1 + "");
return false;
}
});
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
button = findViewById(R.id.start_thread_one);
tv = findViewById(R.id.tv);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
new Thread(()->{
Message message = Message.obtain();
message.arg1 = 2;
handler.sendMessage(message);
}).start();
}
});
}
主线程里构造handler,子线程里构造message,并使用handler将message发送出去,在主线程里执行handleMessage方法就可以更新UI了。很明显,使用handler来切换线程我们只需要两步:
1、主线程里构造handler,重写回调方法
2、子线程里发送message告知主线程执行回调方法
看到此,你可能疑惑的是:主线程怎么就知道执行handleMessage方法?既然子线程发送了message,那么主线程应该有个地方接收到该message啊?看来信使是message,接下来进入源码一探究竟。Android Studio关联源码请移步:Android Studio关联Android SDK源码(Windows&Mac)
Message分析
既然message充当信使,那么其应当有必要的字段来存储携带的数据、区分收发双方等,实际上message不只有这些字段。上个例子里,我们通过静态方法获取message实例。
private static Message sPool;
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
sPool是静态变量,从名字可以猜测出是message存储池。obtain()作用是:先从存储池里找到可用的message,如果没有则创建新的message并返回,那什么时候将message放到存储池里呢?我们只需要关注sPoolSize增长的地方即可,搜索找到:
void recycleUnchecked() {
// Mark the message as in use while it remains in the recycled object pool.
// Clear out all other details.
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
message里有个message类型的next字段,熟悉链表的同学应该知道这是链表的基本操作,该字段用于指向链表里下一个节点的。现在要将一个message对象放入message存储池里:
将待存储的message next字段指向存储池的头部,此时该头部指向的是第一个元素,再将存储池的头指向待插入的message,最后将存储池里个数+1。这时候message已经放入存储池里,并且当作存储池的头。
我们再回过头来看看怎么从存储池里取出message:
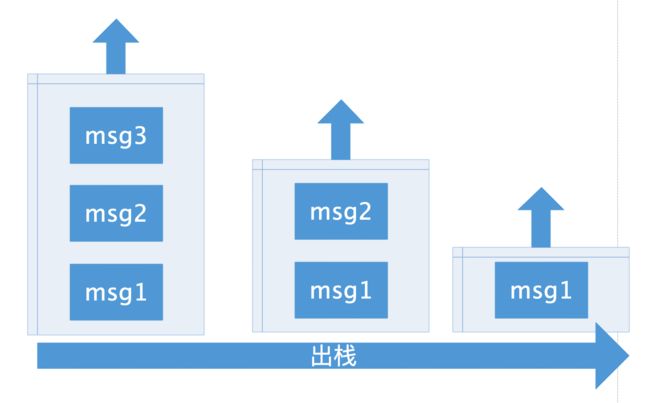
声明message引用,该引用指向存储池头部,将存储池头部指向链表下一个元素,并将message next置空,并将存储池里个数-1,这时候message已经从存储池里取出。
可以看出,每次将message放入链表头,取的时候从链表头取,这不就是我们熟悉的栈结构吗。也就是说,message对象存储池是通过栈来实现的。
问题1
至此,我们分析了message存储池的结构,还留了两个问题后面分析:
1、我们通过obtain()获取message,那么啥时候调用recycleUnchecked()放入存储池呢?
2、可以直接构造message吗?
MessageQueue
从handler.sendMessage(message)分析:
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
sendMessageAtTime()方法输入两个参数,一个是待发送的message对象,另一个是该message延迟执行的时间。这里引入了一个新的类型:MessageQueue,其声明了一个字段:mQueue。接着调用enqueueMessage,该方法里msg.target = this,target实际上指向了handler。最后调用queue.enqueueMessage(msg, uptimeMillis),我们来看看queue.enqueueMessage方法:
synchronized (this) {
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
//第一点
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
// Inserted within the middle of the queue. Usually we don't have to wake
// up the event queue unless there is a barrier at the head of the queue
// and the message is the earliest asynchronous message in the queue.
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
//第二点
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
// We can assume mPtr != 0 because mQuitting is false.
//第三点
if (needWake) {
nativeWake(mPtr);
}
}
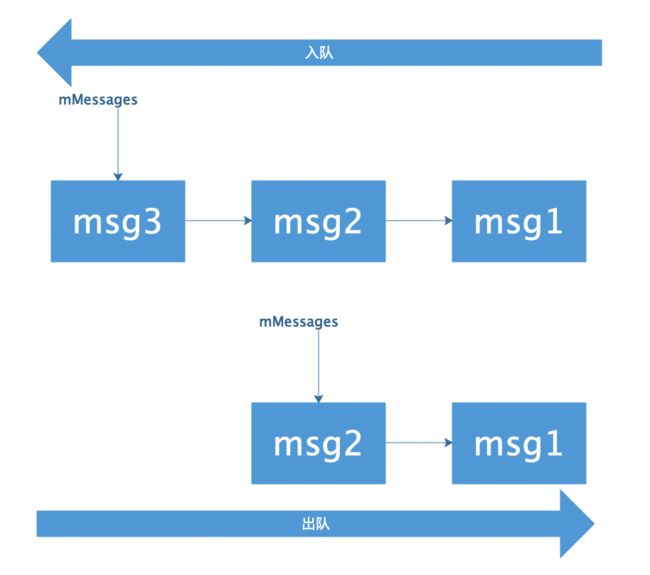
MessageQueue顾名思义:Message队列。它是怎样实现队列的呢?里有个Message类型的mMessages字段,看到这是不是想到了前面的message存储池(栈)呢?没错,MessageQueue是通过message链接成链表的,只不过该链表是实现了队列的,接下来我们看看怎么实现队列。
enqueueMessage源码里标记了第一点、第二点、第三点三个关键点。
第一点
队列为空、或者延迟时间为0、或者延迟时间小于队列头节点,那么将该message next字段指向队列头,并将队列头指向该message。此时该message已经插入enqueueMessage的队列头。
第二点
如果第一点不符合,那么message不能插入队列头,于是在队列里继续寻找,直至找到延迟时间大于message的节点或者到达队列尾,再将message插入队列。
从第一点和第二点可以看出,enqueueMessage实现了队列,并且是根据message延迟时间从小到大排序的,也就是说队列头的延迟时间是最小的,最先需要被执行的。
第三点
问题2
唤醒MessageQueue队列,后续分析。
什么时候取出message
至此,handler.sendMessage(message)发送message到MessageQueue流程已经分析完毕,那么MessageQueue里的message什么时候取出来呢?
既然MessageQueue里有入队方法enqueueMessage,试着找找是否存在出队方法,很遗憾没有。那么我们有理由相信可能在某个地方操作了MessageQueue mMessages字段,查找后发现引用的地方蛮多的,不好分析。换个思路,想想MessageQueue对象mQueue在哪里被引用了?
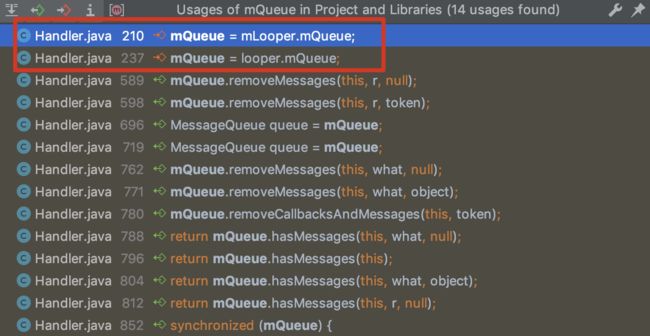
定位到Handler构造函数
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
我们发现mQueue指向了mLooper里的mQueue,而mLooper = Looper.myLooper()。现在我们将怀疑的目光瞥向了Looper,Looper是何方神圣呢,接下来继续分析。
Looper分析
从Looper.myLooper()开始分析
##Looper.java
@UnsupportedAppUsage
static final ThreadLocal sThreadLocal = new ThreadLocal();
/**
* Return the Looper object associated with the current thread. Returns
* null if the calling thread is not associated with a Looper.
*/
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
##ThreadLocal.java
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
可以看出,Looper对象存储在当前线程里,我们暂时不管ThreadLocal原理,看到get方法,我们有理由相信有set方法,果不其然。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
查找其引用,该方法引用的地方很多。既然ThreadLocal get方法在Looper.java里调用,那么ThreadLocal set方法是否也在Looper.java里调用呢?
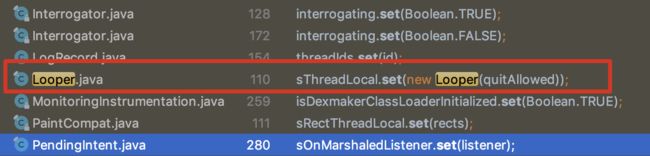 )
)
Looper.java
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
查找prepareMainLooper()方法引用
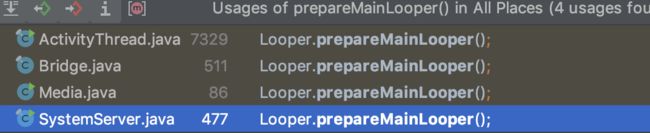 )
)
看到了我们熟悉的ActivityThread,也就是我们app启动main方法所在的类。
 )
)
已经追溯到源头了,我们现在从源头再回溯。
private static Looper sMainLooper; // guarded by Looper.class
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
在prepare方法里,构造了Looper对象。此刻我们看到了主角mQueue被构造出来了,也就是说主线程启动的时候就已经构造了Looper对象,并存储在静态变量sThreadLocal里。同时静态变量sMainLooper指向了新构建的Looper对象。
接着查找mQueue的引用,发现

final MessageQueue queue = me.mQueue,此处引用了mQueue,接着调用了MessageQueue里的next()方法,该方法返回message对象。
MessageQueue.java
next()方法
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
Message msg = mMessages,我们之前分析了handler发送message后最终是将message挂在mMessages上,也就是我们的message队列。而next方法后续操作是:从队列头取出message,并将该message从队列里移除。此时我们已经找到message队列入队时机与方式、message队列出队方式。那么message队列出队时机呢?也就是啥时候调用的。继续回溯分析上面提到的Looper loop()方法。
loop()方法简化一下
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} catch (Exception exception) {
if (observer != null) {
observer.dispatchingThrewException(token, msg, exception);
}
throw exception;
} finally {
ThreadLocalWorkSource.restore(origWorkSource);
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
msg.recycleUnchecked();
}
明显的看出,loop()方法里有个死循环,循环退出的时机是队列里没有消息或者其它异常。
msg.target.dispatchMessage(msg);msg.target就是我们之前提到的handler,也就是handler.dispatchMessage(msg)
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);(1)
} else {
if (mCallback != null) {
(2)
if (mCallback.handleMessage(msg)) {
return;
}
}
(3)
handleMessage(msg);
}
}
这方法里就是具体执行收到message的方法,我们发现里边还分了三个方法:
1、handleCallback()调用的是message里Runnable类型的callback字段,我们经常用的方法view.post(runnable)来获取view的宽高,此处runnable会赋值给callback字段。
2、handler mCallback字段,Callback是接口,接口里有handleMessage()方法,该方法的返回值决定是否继续分发此message。mCallback可选择是否实现,目的是如果不想重写handler handleMessage()方法,那么可以重写callback方法。
3、handleMessage,构造handler子类的时候需要重写该方法。
可能上述1、2、3点应用场合还造成一些疑惑,我们用例子来说明。
1、handleCallback()
//延时执行某任务
handler.postDelayed(new Runnable() {
@Override
public void run() {
}
}, 100);
//view 获取宽高信息
tv.post(new Runnable() {
@Override
public void run() {
}
});
此种方式,只是为了在某个时刻执行回调方法,message本身无需携带附加信息
2、mCallback.handleMessage(msg)
构造Handler匿名内部类实例
private Handler handler = new Handler(Looper.getMainLooper(), new Handler.Callback() {
@Override
public boolean handleMessage(@NonNull Message msg) {
tv.setText(msg.arg1 + "");
return false;
}
});
3、handleMessage(msg)
内部类继承Handler,重写handleMessage方法
class MyHandler extends Handler {
@Override
public void handleMessage(@NonNull Message msg) {
tv.setText(msg.arg1 + "");
}
}
MyHandler handler = new MyHandler();
此时,我们已经知道MessageQueue里的message执行时机。你可能还有疑惑,怎么就确保上述的runnable和handleMessage在主线程里执行呢?根据调用栈:
loop()->msg.target.dispatch()->runnable/handleMessage(),而loop是在main方法里调用的,该方法是app入口,是主线程。
我们还注意到loop()里有两条打印语句:
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
可以看到位于dispatchMessage()前后,这给我们提供了一个便利:通过监测语句的输出,计算主线程执行message耗时。
loop()里的msg.recycleUnchecked(),现在来回答问题1
1、message通过obtain()从存储池里获取实例,在loop()里message被使用后,调用msg.recycleUnchecked()放入存储池里(栈)。
2、message对象不仅可以通过obtain()获取,也可以直接构造。最终都会放入存储池里,推荐用obtain(),更好地复用message。
MessageQueue next()分析
前面我们简单过了一遍next()方法,该方法是从MessageQueue里取出message对象。loop()通过next调用获取message,如果message为空则loop()退出,假设这种情况出现,那么主线程就退出了,app就没法玩了。因此从设计上来说,next返回的message不能为空,那么它需要一直检测message直到获取到有效的message,所以next就有可能阻塞。实际上,next使用的一个for循环,确实可能会阻塞,我们来看看细节之处:
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//第一点
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
//第二点
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
//第三点
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
//第四点
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
//第五点
nextPollTimeoutMillis = -1;
}
// Process the quit message now that all pending messages have been handled.
if (mQuitting) {
dispose();
return null;
}
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
//第六点
mBlocked = true;
continue;
}
}
}
源码里标记了6个关键点,一一分析一下。
1、nativePollOnce(ptr, nextPollTimeoutMillis),查找native层MessageQueue是否有数据。nextPollTimeoutMillis=0 该方法立即返回;nextPollTimeoutMillis=-1;该方法一直阻塞直到被主动唤醒;nextPollTimeoutMillis>0;表示阻塞到特定时间后返回。现在我们来解答之前的问题2,当有message入队列的时候,调用如下代码:
if (needWake) {
nativeWake(mPtr);
}
而needWake=mBlocked,当阻塞的时候mBlocked=true,执行nativeWake(mPtr)后,nativePollOnce()被唤醒返回。这就是最初我们为什么说handler-looper 采用等待通知方式。
2、如果队头节点是屏障消息,那么遍历队列直到找到一条异步消息,否则继续循环直到nativePollOnce阻塞。此处的应用场景之一是:在对view进行invalidate时候,为了保证UI绘制能够及时,先插入一条屏障消息,屏障消息delayTime=0,因此插入队列头部(注意和普通消息插入不同的是:如果队列某个节点和待插入的延迟时间一致,那么待插入的节点排在已有节点的后面,而屏障消息始终插在前面)。插入屏障消息后,后续的刷新消息设置为异步,再插入队列,那么该条消息会被优先执行。
3、如果还未到执行时间,则设置阻塞超时时间。
4、取出message节点,并调整队列头。
5、队列里没有message,那么设置阻塞
6、设置阻塞标记位mBlocked=true,并继续循环
Handler线程切换本质
上面经handler发送message,到message被消费整个流程已经剖析完毕。为了更直观了解流程,使用流程图表示。
message对象存储池
入栈
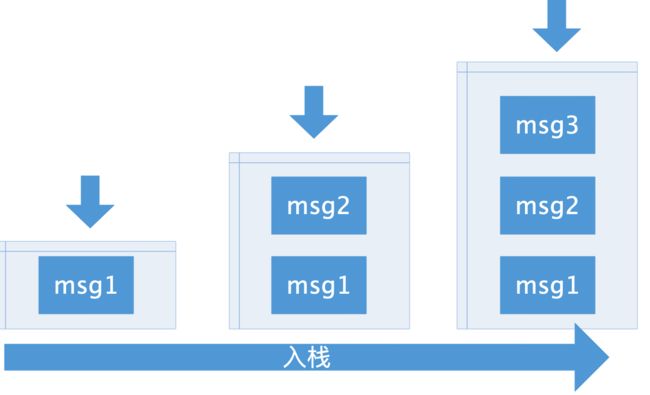
出栈
MessageQueue队列
出入队
调用栈
发送消息调用栈
handler.sendMessage(message)
sendMessage->sendMessageDelayed(msg, 0)->sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis)->enqueueMessage(queue, msg, uptimeMillis)->queue.enqueueMessage(msg, uptimeMillis)
取消息调用栈
msg = loop()->queue.next()
msg->dispatchMessage(msg)->handleCallback(msg)/handleMessage(msg)
将Handler、MessageQueue、Looper用图表示如下:
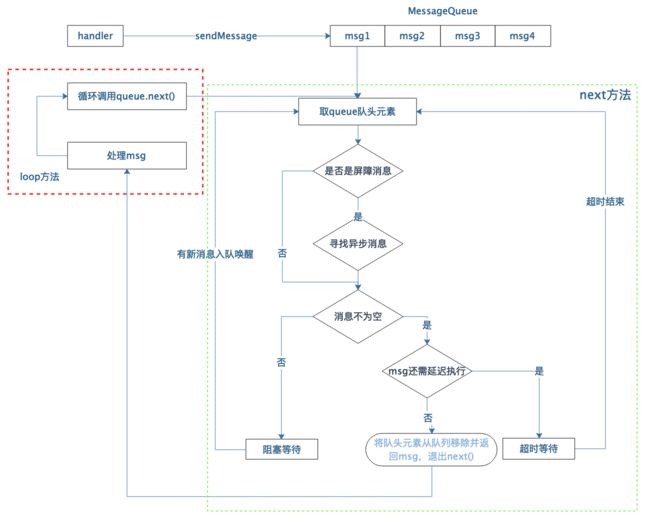
由于MessageQueue是线程间共享对象,因此对队列的操作(入队、出队)需要加锁。
Handler和Looper联系
怎么确保handleMessage(msg)在主线程执行呢?换句话说收到消息后是怎么切换到主线程的?
1、从取消息调用栈可知,执行loop()的线程就是执行handleMessage(msg)的线程,而loop()在main()方法里执行,因此这时候取出的消息就在主线程执行
2、Handler发送的message存储在Handler里的messagequeue,而此队列指向的是Looper的messagequeue,loop()方法从Looper的messagequeue里取消息。因此Handler和Looper共享同一个queue,handler负责发送(入队),Looper负责收取(出队),通过中间桥梁messagequeue实现了线程切换。
3、接着第二点,Handler和Looper是如何共享queue呢?在构建Handler的时候,会根据当前线程获取存储的looper并获取其messagequeue,而looper对象需要在同一线程里构造,并将该looper引用设置到当前线程。在app启动的时候,系统已经在主线程的looper并赋值给静态变量sMainLooper,我们可以通过getMainLooper()获取主线程的looper对象。
4、handler构造时,可以选择是否传入looper对象,若不传则默认从当前线程获取,若取不到则会抛出异常。这就是为什么在子线程里不能简单用消息循环的原因,因为handler没有和looper建立起关联。
子线程消息循环
以上,我们分析的是子线程发送消息,主线程在轮询执行。那我们能够在主线程(其它线程)发送消息,子线程轮询执行吗?这种场景是有现实需求的:
A线程不断从网络拉取数据,而数据分为好几种类型,拿到数据后需要分类处理,处理可能比较耗时。为了不影响A线程效率,需要另起B线程处理,B线程一直在循环处理A拉取回来的数据。
是不是似曾相识,我们想要B线程达到类似主线程的looper功能,接下来看看该怎么做。
Handler handlerB = null;
Thread b = new Thread(new Runnable() {
@Override
public void run() {
//子线程里创建looper对象,并保存引用到当前线程里
Looper.prepare();
//Handler构造方法默认获取当前线程的looper引用
handlerB = new Handler(new Callback() {
@Override
public boolean handleMessage(@NonNull Message msg) {
return false;
}
});
//子线程开启loop()循环
Looper.loop();
}
});
b.start();
Thread a = new Thread(()->{
//线程发送消息
handlerB.sendMessage(new Message());
});
a.start();
源码里已有注释,不再缀叙。
你可能会说,每次都这么麻烦吗?实际上Android系统开发者已经考虑了这情况,封装了HandlerThread类来实现子线程的消息循环,实现方式和上述类似。重点是将Handler和Looper关联起来。
总结
以上从源码和应用角度剖析了Handler、Message、Looper原理及其三者之间关系,三者简称消息循环。消息循环在Android开发中应用广泛,我们不仅要能够运用自如,也可以从源码中学习闪光的设计点。