集合概述,Collection集合的体系特点
目录
1.集合类体系结构
1.集合:
2.Collection集合体系:
3.Collection集合特点:
4.List集合系列特点验证:
5.Set集合系列特点验证:
6.集合都是支持泛性的,可以在编译阶段约束集合只能操作某种数据集合:
2.Collection集合常用API
1.Collection集合:
2.Collection API如下:
3.Collection集合的遍历方式
1.迭代器
2.Collection集合获取迭代器
3.Iterator中的常用方法
4.迭代器的默认位置在哪里:
5.迭代器如果去除元素越界会出现什么问题:
6.foreach/增强for循环
7.增强for可以遍历那些容器:
8.Lambda表达式:
9.Collection结合Lambda遍历API
4.Collection集合存储自定义类型的对象
1.集合中存储的是元素的什么信号:
5.常见的数据结构
1.数据结构列概述:
2.常见的数据结构:
3.数组:
3.链表:
3.二叉树,二叉查找树:
4.平衡二叉树:
5.红黑树:
6.List系列集合:
1、List集合特点,特有API:
2.List集合的遍历方式小结:
3.ArrayList集合的底层逻辑:
4、LinkedList集合的底层原理
7.补充知识:集合的并发修改异常问题:
1、问题的引出:
2、那些遍历存在问题?
3.那种遍历且删除元素不出问题:
8.补充知识:泛性深入
1.泛性的概述和优势:
2.自定义泛性类:
3.自定义泛型方法:
4.自定义泛型接口:
5.泛型统配符,上下限:
1.集合类体系结构
1.集合:
1、Collection单列集合:单列集合每个元素(数据)只包含一个值。
2、Map双列集合:每个元素包含两个值(键值对)。
3、注意:前期先掌握Collection集合体系的使用
2.Collection集合体系:
1.Collection是祖宗接口
2.List和Set是子接口
3.ArrayList、LinkedList是List的实现类,HashSet、TreeSet是Set的实现类
Collection
List
ArrayList
LinkedList
Set
HashSet
LinkedHashSet
TreeSet
3.Collection集合特点:
1、List系列集合:添加的元素是有序的,可重复,有索引。
ArrayList、LinkedList:添加的元素是有序的,可重复,有索引。
2、Set系列集合:添加的元素是无序的,不重复,无索引。
HashSet:添加的元素是无序的,不重复,无索引。
LinkedHashSet:添加的元素是有序的,不重复,无索引。
TreeSet:按照大小默认升序排序,不重复,无索引。
4.List集合系列特点验证:
//有序、可重复、有索引
Collection list=new ArrayList();
list.add("Java");
list.add("java");
list.add("Mybadatis");
list.add(23);
list.add(23);
list.add(false);
list.add(false);
System.out.println(list);
//[Java, java, Mybadatis, 23, 23, false, false]5.Set集合系列特点验证:
//无序、不重复,无索引
Collection list1=new HashSet();
list1.add("Java");
list1.add("Java");
list1.add("Mybadatis");
list1.add(23);
list1.add(23);
list1.add(false);
list1.add(false);
System.out.println(list1);
//[Java, false, 23, Mybadatis]6.集合都是支持泛性的,可以在编译阶段约束集合只能操作某种数据集合:
1、Collection
lists = new ArrayList (); 2、Collection
lists = new ArrayList<>();//JDK1.7开始后面的泛性类型申明可以省略不写 3、注意:集合和泛型都只能支持引用数据类型,不支持基本数据类型,所以集合中存储的元素 都认为是对象。
1、集合的代表是:Collection接口
2、Collection集合分了那两大常用的集合体系:
List系列集合:添加的元素是有序,可重复,有索引;
Set系列集合:添加的元素是无序,不重复,无索引;
3、如何约定集合存储数据类型,需要注意什么:
集合支持泛性;
集合和泛性不支持基本类型,只支持引用数据类型。
2.Collection集合常用API
1.Collection集合:
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用
2.Collection API如下:
public boolean add(E e) 把给定的对象添加到当前集合中
public void clean() 清空集合中的所有元素
public boolean remove(E e) 把给定的对象在当前集合中删除
public boolean contains(Object obj) 判断当前集合中是否包含给定的对象
public boolean isEmpty() 判断当前集合是否为空
public int size() 返回集合中元素的个数
public Object[] toArray() 把集合中的元素,存储到数组中
//Collection方法的使用:
//ArrayList:添加的元素有序、可重复、有索引
Collection list = new ArrayList();
//add方法添加元素,添加成功返回true
list.add("Java");
list.add("HTML");
System.out.println(list.add("HTML")); //true
list.add("MYSQL");
list.add("Java");
list.add("人人");
System.out.println(list); //[Java, HTML, HTML, MYSQL, Java, 人人]
//HashSet:添加的元素是无序,不重复,无索引
Collection list1 = new HashSet();
list1.add("HTML");
System.out.println(list1.add("HTML")); //false
//判断集合是否为空,是空返回true,非空返回false
System.out.println(list.isEmpty()); //false
//获取集合的大小
System.out.println(list.size()); //6
//判断是否包含某个元素
System.out.println(list.contains("Java")); //true
System.out.println(list.contains("java")); //false
//删除某个元素,如果有多个重复元素默认删除前面的第一个
System.out.println(list.remove("java")); //false
System.out.println(list); //[Java, HTML, HTML, MYSQL, Java, 人人]
System.out.println(list.remove("Java")); //true
System.out.println(list); //[HTML, HTML, MYSQL, Java, 人人]
//把集合转化成数组
Object[] arr=list.toArray();
System.out.println("数组:"+Arrays.toString(arr));
//数组:[HTML, HTML, MYSQL, Java, 人人]
Collection list2 = new ArrayList();
list2.add(" ");
//把list元素拷贝到list2集合中去
list2.addAll(list);
System.out.println(list2); //[ , HTML, HTML, MYSQL, Java, 人人]
System.out.println(list); //[HTML, HTML, MYSQL, Java, 人人]
//清空集合中的元素
list.clear();
System.out.println(list); //[]3.Collection集合的遍历方式
1.迭代器
1、遍历就是一个一个的把容器中的元素访问一便
2、迭代器在Java中的代表是iterator,迭代器是集合的专用遍历方式
2.Collection集合获取迭代器
Iterator
iterator() 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的0索引
3.Iterator中的常用方法
boolean hasNext() 询问当前位置是否有元素存在,存在返回true,不存在返回false
E next() 获取当前位置的元素,并同时将迭代器对象移向下一个位置,注意:防止取出越界
ArrayList lists = new ArrayList<>();
lists.add("赵敏");
lists.add("小昭");
lists.add("素素");
lists.add("灭绝");
lists.add("灰太狼");
System.out.println(lists); //[赵敏, 小昭, 素素, 灭绝, 灰太狼]
//1.得到当前集合的迭代器对象
Iterator it = lists.iterator();
//2.定义while循环
while (it.hasNext()) {
String ele = it.next();
System.out.print(ele + ",");
} //赵敏,小昭,素素,灭绝,灰太狼, 4.迭代器的默认位置在哪里:
Iterator
iterator():得到迭代器对象,默认指向当前的集合的索引0
5.迭代器如果去除元素越界会出现什么问题:
会出现NoSuchElementException异常
ArrayList lists = new ArrayList<>();
lists.add("赵敏");
lists.add("小昭");
lists.add("素素");
lists.add("灭绝");
lists.add("灰太狼");
System.out.println(lists);
//1、得到当前集合的迭代器对象
Iterator it = lists.iterator();
String ele = it.next();
System.out.println(ele); //赵敏
System.out.println(it.next()); //小昭
System.out.println(it.next()); //素素
System.out.println(it.next()); //灭绝
System.out.println(it.next()); //灰太狼
System.out.println(it.next()); //NoSuchElementException异常 6.foreach/增强for循环
增强for循环:
1、增强for循环:既可以遍历集合也可以遍历数组;
2、它是JDK5之后出现的,其内部原理是一个Iterator迭代器,遍历集合相当于是迭代器的简 写法
3、实现Iterable接口的类才可以使用迭代器和增强for,Collection接口已经实现了Iterable接 口
4、格式: for(元素数据类型 变量名:数组或者Collection集合){
//在此处使用变量即可,该变量就是元素
}
ArrayListlists = new ArrayList<>(); lists.add("赵敏"); lists.add("小昭"); lists.add("素素"); lists.add("灭绝"); lists.add("灰太狼"); for (String ele:lists){ System.out.print(ele+" ");//赵敏 小昭 素素 灭绝 灰太狼 }
7.增强for可以遍历那些容器:
既可以遍历集合也可以遍历数组
8.Lambda表达式:
得益于JDK8开始的新技术Lambda表达式,提供了一种更简单,更直接的遍历集合的方式
9.Collection结合Lambda遍历API
default void forEach(Consumer action): 结合lambda遍历集合
ArrayList lists = new ArrayList<>();
lists.add("赵敏");
lists.add("小昭");
lists.add("素素");
lists.add("灭绝");
lists.add("灰太狼");
lists.forEach(new Consumer() {
@Override
public void accept(String s) {
System.out.print(s + " "); //赵敏 小昭 素素 灭绝 灰太狼
}
});
System.out.println();
lists.forEach(s -> System.out.print(s + " ")); //赵敏 小昭 素素 灭绝 灰太狼 4.Collection集合存储自定义类型的对象
1.集合中存储的是元素的什么信号:
集合中存储的是元素对象的地址
//创建Movies类
public class Movies {
private String name;
private double score;
private String actor;
@Override
public String toString() {
return "Movies{" +
"name='" + name + '\'' +
", score=" + score +
", actor='" + actor + '\'' +
'}';
}
public Movies() {
}
public Movies(String name, double score, String actor) {
this.name = name;
this.score = score;
this.actor = actor;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
}
public class TestDemo {
public static void main(String[] args) {
//1.定义一个电影类
//2.定义一个集合对象存储3部电影对象
Collection movies=new ArrayList<>();
movies.add(new Movies("《你好,李焕英》",9.5,"张小斐、贾玲、沈腾、陈赫"));
movies.add(new Movies("《唐人街探杆》",8.5,"王宝强,刘昊然,美女"));
movies.add(new Movies("《刺杀小说家》",8.6,"雷佳音,杨幂"));
System.out.println(movies);
//3.遍历集合容器中的每个电影对象
for (Movies movie : movies) {
System.out.println("片名:"+movie.getName());
System.out.println("得分:"+movie.getScore());
System.out.println("角色:"+movie.getActor());
}
}
}
5.常见的数据结构
1.数据结构列概述:
1、数据结构是计算机底层存储,组织数据的方式。是指数据相互之间是以什么方式排列在一起的。
2、通常情况下,精心选择的数据结构可以带来更高的运行或则存储效率
2.常见的数据结构:
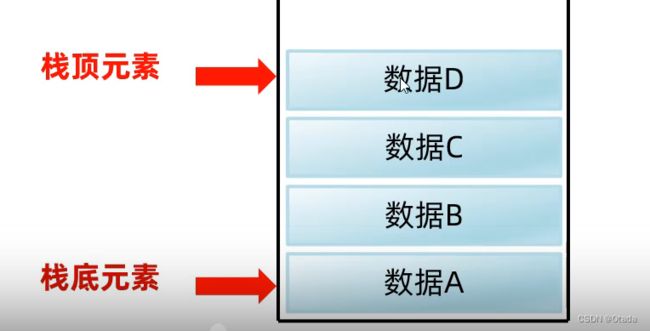
栈:
数据结构执行的特点:后进先出,先进后出。
数据进入栈模型的过程称为:压栈或进栈。
数据离开栈模型的过程称为:弹栈或出栈。
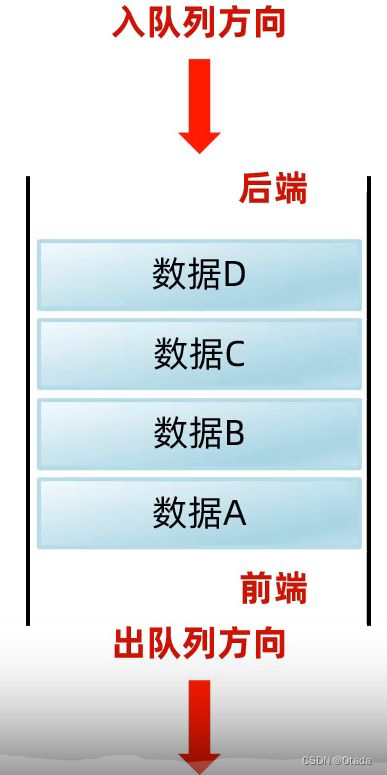
队列:
数据结构执行的特点:先进先出,后进后出。
数据从后端进入队列模型的过程称为:入队列。
数据从前端离开队列模型的过程称为:出队列。
3.数组:
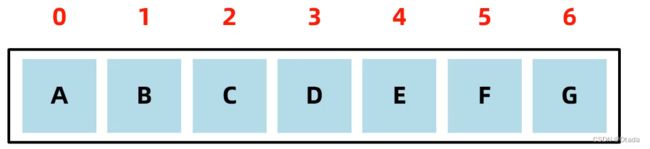
数组是一种查询快,增删慢的模型:
1.查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中是连续存储的)
2.删除效率低:要将原始数据删除,同时后面每个数据前移。
3.添加效率极低:添加位置后的每个数据后移,再添加元素。
3.链表:
1.链表中的元素是在内存中不连续存储的,每个元素节点包含数据值和下一个元素的地址
2.链表查询慢,无论查询那个数据都要从头开始找
3.链表增删相对快
链表种类:单向链表,双向链表
结论:数组根据索引查元素最快,双链表增删首尾元素最快。

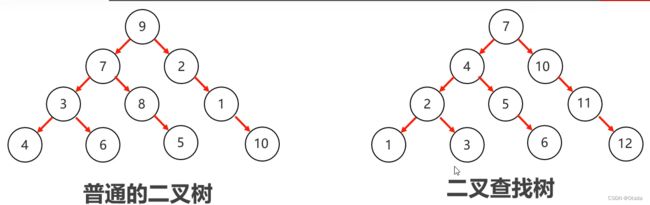
3.二叉树,二叉查找树:
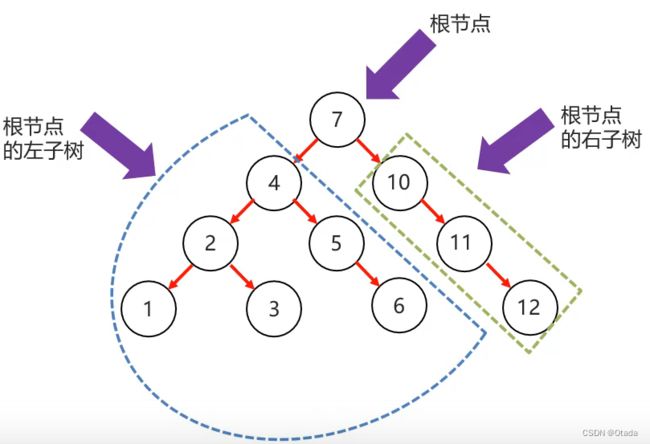
二叉树特点:
1、只能有一个根节点,每个节点最多支持2个直接子节点。
2、节点的度:节点拥有的子树的个数,二叉树的度不大于2,叶子节点度为0的节点,也称之为终端节点。
3.高度:叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高。
4.层:根节点在第一层,以此类推。
5.兄弟节点:拥有共同父节点的节点互称为兄弟节点。
二叉查找树:
1、二叉查找树又称二叉排序树或者二叉搜索树
2、特点:
1、每一个节点上最多有两个子节点;
2、左子树上所有节点的值都小于根节点的值
3、右子树上所有节点的值都大于根节点的值
3、目的:提高检索数据的性能。
4、规则:小的存左边,大的存右边,一样的不存。
5、二叉查找树是增删改查都挺快的数据结构
4.平衡二叉树:
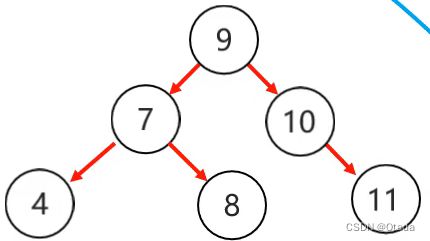
1.二叉树存在的问题:
7 10 11 12 13
将上面的节点按照二叉查找树的规则存入(称为瘸子现象)
问题:出现瘸子现象,导致查询的性能与单链表一样,查询速度变慢。
2.平衡二叉树:
1.平衡二叉树是在满足查找二叉树的大小规则下,让树尽量可能矮小,以此提高查数据的性能。
2.平衡二叉树的要求:任意节点的左右两个子树的高度差不超过1,任意节点的左右两个子树都是一颗平衡二叉树。
3.平衡二叉树在添加元素后可能导致不平衡:
基本策略是进行左旋,或者右旋保持平衡
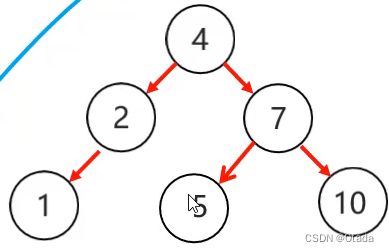
4.平衡二叉树-旋转的四种情况:
1.左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡:
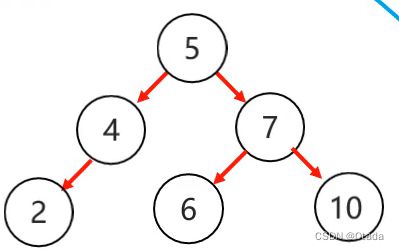
2.左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡:

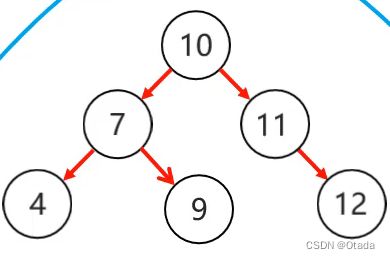
3.右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡:
4.右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡:
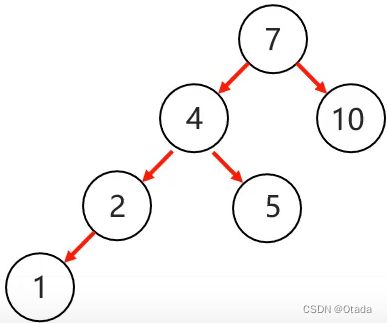
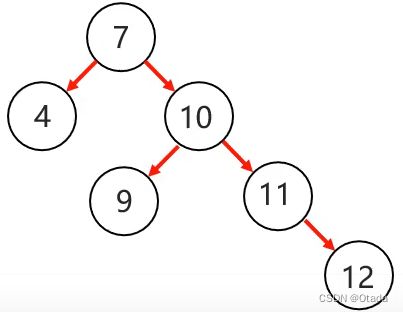

5.红黑树:
1、红黑树是一种自平衡二叉查找树,是计算机科学中用到的一种数据结构。
2、1972年出现,当时被称之为平衡二叉B树。1978年被修改为如今的“红黑树”。
3、每一个节点可以是红或者黑;红黑树不是通过高度平衡的,它的平衡是通过“红黑规则”进 行实现的。
1.红黑规则:
1、每一个节点或是红色的,或者是黑色的,根节点必须是黑色。
2、如果一个节点没有子节点或者是父节点,则该节点相应的指针属性值为Nil,这些Nil视为 叶子节点,叶节点是黑色的。
3、如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情 况)
4、对每一个节点,从该节点到其所有后代叶节点的简单路劲上,均包含相同数目的黑色节 点。

2.添加节点:
1、添加的节点的颜色,可以是红色,也可以是黑色的。
2、默认使用红色效率高
红黑树总结:红黑树增删查改性能都很好。
各种数据结构的特点和作用:
1、队列:先进先出,后进后出。
2、栈:后进先出,先进后出。
3、数组:内存连续区域,查询快,增删慢。
4、链表:元素是游离的,查询慢,首尾操作极快。
5.二叉树:永远只有一个根节点,每个节点不超过两个子节点的树。
6.查找二叉树:小的左边,大的右边,但是可能树很高,查询性能变差。
7.平衡查找二叉树:让树的高度不大于1,增删改查都提高了。
8.红黑树(就是基于红黑规则实现了自平衡的排序二叉树)。
6.List系列集合:
1、List集合特点,特有API:
1、List系列集合特点:
1、ArrayList、LinekdList:有序,可重复,有索引。
2、有序:存储和取出的元素顺序一致。
3、有索引:可以通过索引操作元素。
4、可重复:存储的元素可以重复。
2、List集合特有方法:
List集合因为支持索引,所以多了很多索引操作的独特api,其他Collection的功能List也继承了。
方法名称: 说明:
void add(int index,E element) 在此集合中的指定位置插入指定元素
E remove(int index) 删除指定索引处的元素,返回被删除的元素。
E set(int index,E element) 修改指定索引处的元素,返回被修改的元素
E get(int index) 返回指定索引处的元素
//1、创建一个ArrayList集合对象
//List:有序,可重复,有索引
List list = new ArrayList<>();//一行经典代码就诞生了
list.add("Java");
list.add("Java");
list.add("MySQL");
list.add("MySQL");
//2.在某个索引位置插入元素。
list.add(2, "HTML");
System.out.println(list); //[Java, Java, HTML, MySQL, MySQL]
//3.根据索引删除元素,返回被删除元素
System.out.println(list.remove(2));//HTML
System.out.println(list); //[Java, Java, MySQL, MySQL]
//4.根据索引获取元素:public E get(int index):返回集合中指定位置的元素。
System.out.println(list.get(2)); //MySQL
//5.修改索引位置处的元素:public E set(int index,E element)
//返回修改前的数据
System.out.println(list.set(1, "高斯林")); //Java
System.out.println(list); //[Java, 高斯林, MySQL, MySQL] List总结:
1、List系列集合特点:
ArrayList、LinekdList:有序,可重复,有索引。
2、List的实现类的底层原理:
ArrayList底层是基于数组实现的,根据查询元素快,增删相对慢。
LinkedList底层基于双链表实现的,查询元素慢,增删首尾元素是非常快的。
2.List集合的遍历方式小结:
1、List集合遍历方式有几种:
1、迭代器 2、增强for循环 3、Lambda表达式 4、for循环(因为List集合存在索引)
List lists = new ArrayList<>();
lists.add("java1");
lists.add("java2");
lists.add("java3");
//1、for循环遍历 可以知道遍历的位置
for (int i = 0; i < lists.size(); i++) {
String ele = lists.get(0);
System.out.print(ele + " "); //java1 java1 java1
}
//2、迭代器
System.out.println();
Iterator it = lists.iterator();
while (it.hasNext()) {
String ele = it.next();
System.out.print(ele + " "); //java1 java1 java1
}
//3、foreach
System.out.println();
for (String ele : lists) {
System.out.print(ele + " "); //java1 java1 java1
}
//JDK1.8开始之后的Lambda表达式
System.out.println();
lists.forEach(s -> {
System.out.print(s + " "); //java1 java1 java1
}); 3.ArrayList集合的底层逻辑:
1、ArrayList集合底层原理:
1、ArrayList底层是基于数组实现的:根据索引定位元素快,增删需要做元素的移位操作。
2、第一次创建集合并添加第一个元素的时候,在底层创建一个默认长度为10的数组。
4、LinkedList集合的底层原理
1、LinkedList的特点:
1、底层数据结构是双链表,查询慢,首尾操作的速度是极快的,所以多了很多首尾操作的特有API
2、LinkedList集合的特有功能:
方法名称: 说明:
public void addFirst(E e) 在该列表开头插入指定的元素
public void addLast(E e) 将指定的元素追加到此列表的末尾
public E getFirst() 返回此列表中的第一个元素
public E getLast() 返回此列表中的最后一个元素
public E removeFirst() 从此列表中删除并返回第一个元素
public E removeLast() 从此列表中删除并返回最后一个元素
//1.LinkedList可以完成队列结构,和栈结构(双链表)
//栈
LinkedList stack = new LinkedList<>();
//压栈,入栈
stack.addFirst("第1颗子弹");
stack.addFirst("第2颗子弹");
stack.addFirst("第3颗子弹");
stack.addFirst("第4颗子弹");
System.out.println(stack); //[第4颗子弹, 第3颗子弹, 第2颗子弹, 第1颗子弹]
//出栈,入栈
System.out.println(stack.removeFirst());//第4颗子弹
System.out.println(stack); //[第3颗子弹, 第2颗子弹, 第1颗子弹]
//队列
LinkedList queue = new LinkedList<>();
//入队
queue.addLast("1号");
queue.addLast("2号");
queue.addLast("3号");
queue.addLast("4号");
System.out.println(queue); //[1号, 2号, 3号, 4号]
//出队
System.out.println(queue.removeFirst()); //1号 7.补充知识:集合的并发修改异常问题:
1、问题的引出:
1. 当我们从集合中找出某个元素并删除的时候可能出现一种并发的修复异常。
2、那些遍历存在问题?
1.迭代器遍历集合且直接用集合删除元素的时候可能出现。
2.增强for循环遍历集合且直接用集合删除元素的时候可能出现。
//准备数据
LinkedList list = new LinkedList<>();
list.add("黑马");
list.add("黑马");
list.add("Java");
list.add("Java");
list.add("赵敏");
list.add("赵敏");
list.add("素素");
System.out.println(list);//[黑马, 黑马, Java, Java, 赵敏, 赵敏, 素素]
//需求:删除全部的Java信息
//1、迭代器遍历删除
Iterator it = list.iterator();
while (it.hasNext()) {
String ele = it.next();
if ("Java".equals(ele)) {
it.remove();//删除当前元素,并且不会后移
}
}
System.out.println(list);//[黑马, 黑马, 赵敏, 赵敏, 素素]
//2.foreach和Lambda遍历删除,出现解决不了bug
//3.for循环遍历删除需要倒的删除,不然会漏删
for (int i = list.size() - 1; i >= 0; i--) {
String ele = list.get(i);
if ("赵敏".equals(ele)) {
list.remove("赵敏");
}
}
System.out.println(list);//[黑马,黑马, 素素]
//4.for循环解决遍历防止漏删问题:
for (int i = 0; i < list.size(); i++) {
String ele = list.get(i);
if ("黑马".equals(ele)) {
list.remove("黑马");
i--;
}
}
System.out.println(list);//[素素] 3.那种遍历且删除元素不出问题:
1、迭代器遍历集合但是用迭代器自己的删除方法可以解决。
2、使用for循环遍历并删除元素不会存在这个问题。
8.补充知识:泛性深入
1.泛性的概述和优势:
1.泛性概述:
1、泛性:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
2、泛性格式:<数据类型>;注意:泛性只能支持引用数据类型
3、集合体系的全部接口和实现类都是指出泛型的使用。
2.泛性的概述:
1、统一数据类型。
2、把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为编译 阶段类型就能确定下来。
3.泛性可以在很多地方进行定义:
1、类后面 泛性类 2、方法申请上 泛性方法 3、接口后面 泛性接口
2.自定义泛性类:
1、泛性类的概述:
1、定义类时同时定义了泛型的类就是泛性类。
2、泛型类的格式:修饰符class类名<泛型变量>{}
范例:public class MyArrayList
{} 3、此处泛型变量T可以随意写为任意标识符,常见的如E、T、K、V等
4、作用:编译阶段可以指定数据类型,类似于集合的作用。
2、课程案例导学
1、模拟ArrayList集合自定义一个集合MyArrayList集合,完成添加和删除功能的泛型设计即 可。
public static void main(String[] args) {
//需求:模拟ArrayList定义一个MyArrayList,关注泛型设计
MyArrayList list = new MyArrayList<>();
list.add("JAVA1");
list.add("JAVA");
list.add("MySQL");
list.remove("MySQL");
System.out.println(list);//[JAVA1, JAVA]
MyArrayList list2 = new MyArrayList<>();
list2.add(23);
list2.add(24);
list2.add(25);
list2.remove(25);
System.out.println(list2);//[23, 24]
} public class MyArrayList {
private ArrayList lists=new ArrayList();
public void add(E e) {
lists.add(e);
}
public void remove(E e) {
lists.remove(e);
}
@Override
public String toString() {
return lists.toString();
}
} 3.泛型类的核心原理:
1.把出现泛型变量的地方全部替换成传输的真是数据类型。
4.泛型类的作用:
1、编译阶段约定操作的数据的类型,类似于集合的作用。
3.自定义泛型方法:
1、泛型方法的概述:
1、定义方法的同时定义了泛型的方法就是泛型方法。
2、泛型方法的格式:修饰符<泛型变量>方法返回值 方法名称(形参列表){}
3、范列:public
void show(T t){} 4、作用:方法中可以使用泛型接受一切实际类型的参数。方法更具备通用性。
2、课堂案例导学:
1、给你任何一个类型的数组,都能返回它的内容。也就是实现Arrays.toString(数组)的功 能。
public static void main(String[] args) {
String[] names = {"小路", "蓉蓉", "小何"};
printArray(names); //[小路,蓉蓉,小何 ]
Integer[] ages = {10, 20, 30};
printArray(ages); //[10,20,30 ]
}
public static void printArray(T[] arr) {
if (arr != null) {
StringBuilder sb = new StringBuilder("[");
for (int i = 0; i < arr.length; i++) {
sb.append(arr[i]).append(i == arr.length - 1 ? " " : ",");
}
sb.append("]");
System.out.println(sb);
} else {
System.out.println(arr);
}
} 3、泛型方法的原理:
1、把出现泛型变量的地方全部替换成传输的真实数据类型。
泛型方法的核心思想:把出现泛型变量的地方全部替换成传输的真实数据类型。
泛型方法的作用:方法中可以使用泛型接受一切参数类型的参数,方法更具备通透性。
4.自定义泛型接口:
1、泛型接口概述:
1、使用了泛性定义的接口就是泛型接口。
2、泛型接口的格式:修饰符interface接口名称<泛型变量>{}
3、范例:public interface Data
{} 4、作用:泛型接口可以让实现类选择当前功能需要操作的数据结构
2、课程案例导学:
1、教务系统,提供一个接口可约束一定要完成数据(学生,老师)的增删改查操作。
3、泛型接口的原理:
实现类可以在实现实现接口的时候传入自己操作的数据类型,这样重写的方法都将是针对于该类的操作。
public interface Data {
void add(E e);
void update(E e);
void delete(int id);
E queryById(int id);
} public class StudentData implements Data{
@Override
public void add(Student student) {
}
@Override
public void update(Student student) {
}
@Override
public void delete(int id) {
}
@Override
public Student queryById(int id) {
return null;
}
} 4、泛型接口的作用:
泛性接口可以约束实现类,实现类可以在实现接口的时候传入自己操作的数据类型这样重写的方法都将是针对于该类型的操作。
5.泛型统配符,上下限:
1.通配符:?
1、?可以在“使用泛型"的时候代表一切类型
2、E、T、K、V是在定义泛型的时候使用。
2、泛型通配符:案例教学
1、开发一个极品飞车的游戏,所有的汽车都能一起参加比赛。
注意:虽然BMW和BENZ都继承了Car但是ArrayList
和ArrayList 没有关系的1!
3、泛型的上下限:
?extends Car:?必须是Car或者其子类 泛性上限
? super Car:?必须是Car或者其父类 泛型下限
public class GenericDemo { public static void main(String[] args) { ArrayListbmws = new ArrayList<>(); bmws.add(new BMW()); bmws.add(new BMW()); bmws.add(new BMW()); bmws.add(new BMW()); go(bmws); } public static void go(ArrayList cars) { } } class BMW extends Car { } //父类 class Car { }