编译原理实验一 《词法分析程序设计与实现》
编译原理实验一 《词法分析程序设计与实现》
一、实验目的
加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。
二、实验内容
自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。词法分析程序的实现可以采用任何一种编程语言和编程工具。从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符。并依次输出各个单词的内部编码及单词符号自身值(遇到错误时可显示“Error”,然后跳过错误部分继续显示)。
三、实验要求
1、对单词的构词规则有明确的定义;
2、编写的分析程序能够正确识别源程序中的单词符号;
3、识别出的单词以<种别码,值>的形式保存在符号表中,正确设计和维护符号表;
4、对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成整个源程序的词法分析。
四、实验步骤
1、定义目标语言的可用符号表和构词规则;
这里使用简化的C++语言作为编译对象的程序设计语言,考虑从关键字、标识符、常数、运算符、分隔符五个方面描述其构词规则。
(1) 假设一段简单的C++程序代码需要识别的词如下:
① 关键字:if、int、for、while、do、return、break、continue;单词种别码为1;
② 标识符;单词种别码为2;
③ 常数为无符号整形数;单词种别码为3;
④ 运算符包括:+、-、*、/、=、>、<、>=、<=、==;单词种别码为4;
⑤ 分隔符包括:,、;、{、}、(、); 单词种别码为5。
(2) 考虑该简单C++程序代码的文法的符号串集合 Σ Σ Σ 为(综合上面的词的构成):
Σ = { a , … z , A , … Z , 0 , 1 , … 9 , , + , − , ∗ , / , < , > , = , , , ; , { , } , ( , ) } \Sigma = \{a,…z, A,…Z, 0, 1,…9, _, +, -, *, /, <, >, =, ,, ;, \{, \}, (, )\} Σ={a,…z,A,…Z,0,1,…9,,+,−,∗,/,<,>,=,,,;,{,},(,)}
(3) 考虑该简单C++程序代码的LEX描述如下:
① AUXILIARY DEFINITION /* 辅助定义 */
k e y → i f ∣ i n t ∣ f o r ∣ w h i l e ∣ d o ∣ r e t u r n ∣ b r e a k ∣ c o n t i n u e l e t t e r → a ∣ b ∣ … ∣ z ∣ A ∣ B ∣ … ∣ Z ∣ _ d i g i t → 0 ∣ 1 ∣ 2 ∣ … ∣ 9 o p e r a t o r → + ∣ − ∣ ∗ ∣ / s e p a r a t o r → , ∣ ; ∣ ∣ ∣ ( ∣ ) \begin{align*} & \mathbf { key → if | int | for | while | do | return | break | continue }\\ & \mathbf {letter → a|b|…|z|A|B|…|Z|\_ }\\ & \mathbf {digit → 0|1|2|…|9 }\\ & \mathbf {operator → + | - | * | / }\\ & \mathbf {separator → , | ; | { | } | ( | ) }\\ \end{align*} key→if∣int∣for∣while∣do∣return∣break∣continueletter→a∣b∣…∣z∣A∣B∣…∣Z∣_digit→0∣1∣2∣…∣9operator→+∣−∣∗∣/separator→,∣;∣∣∣(∣)
② RECOGNITION RULES /* 识别规则 */
| 词形 | 动作 |
|---|---|
| key | {return(1, -)} |
| letter(letter|digit)* | {return(2, -)} |
| digit(digit)* | {return(3, -)} |
| operator|<|>|=|<=|>=|== | {return(4, -)} |
| separator | {return(5, -)} |
注:考虑到<=、>=、==等复合操作符的特殊性,为方便使用类似超前搜索的方法,将<、>、=从operator中分离开来,作为一个单独的部分处理;为了方便实现,将下划线“_”归到letter当中。
2、构造相应的确定有限自动机DFA或者可以编程实现的状态转换图;
对于该简单C++程序代码,根据LEX描述构造状态转换图如下:(关键字 key 和一般标识符的识别方式相同,因此将 key 的识别归在标识符的识别当中,在具体编程实现时再进行区分)
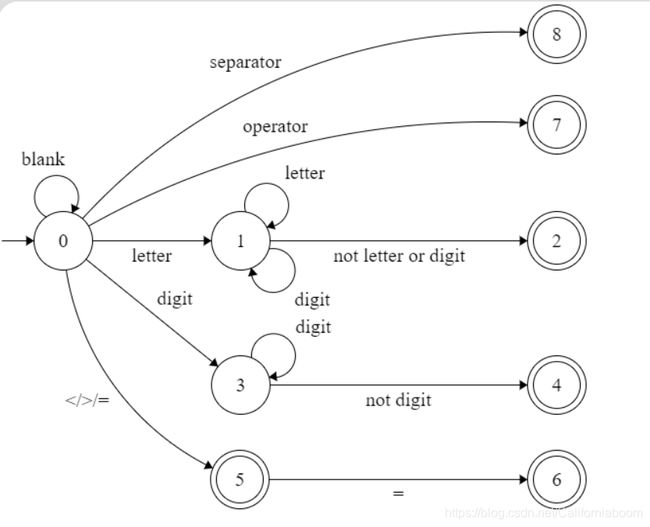
3、为编译程序的具体实现进行必要的准备工作;(使用 C++、STL)
① 准备工作1:从.txt文件当中读取出代码(即文件全部内容)并形成缓存,即将其暂存于一个string对象当中。
实现由函数getSrcString(const string &path) 完成,代码如下。
/* 读取文件所有内容 */
string getSrcString(const string &path) {
ifstream myfile;
// path为目标源文件路径
myfile.open(path);
// 读取全部内容
string res((istreambuf_iterator<char>(myfile)), (istreambuf_iterator<char>()));
myfile.close();
return res;
}
② 准备工作2:去除代码段首尾的空白字符;这里仅考虑空格、换行和制表符。
实现由函数StringTrim(string &s)完成,代码如下。
/* 删去字符串首尾空白符 */
void StringTrim(string &s) {
// 首部的空白符
int index = 0;
if ( isBlank(s[index]) ) {
while ( isBlank(s[index]) ) {
index++;
}
s.erase(0, index);
}
// 尾部的空白符
index = s.size()-1;
if ( isBlank(s[index]) ) {
while ( isBlank(s[index]) ) {
index--;
}
s.erase(index+1);
}
}
其中函数bool isBlank(const char &c)用于判断传入的字符c是否为上述三个空白符。
③ 准备工作3:定义合适的数据结构。
识别出的单词种别码使用枚举类型以便维持可读性。
enum WordType {
BEGIN, KEYWORD, IDENTIFIER, CONSTANT, OPERATOR, SEPARATOR, ERROR
};
注:BEGIN是为了符合之前的规定而做出的填充,ERROR指识别出错的情况,也属于种别码。
需要输出的内容将被存储在符号表当中,符号表使用结构体作为每个单词的存储单位;
struct CompleteWord {
string word;
WordType type;
CompleteWord(WordType type, string& word) {
this->type = type;
this->word = word;
}
};
整个符号表使用一个vector对象op_table存储以统一管理,该对象存储所有识别出的单词的结构体指针:vector
④ 准备工作4:符号表内容的输出与符号表的销毁(所有结构体的内存空间释放),由以下两个函数完成。
void PrintOPTable(vector
void ClearOPTable(vector
4、根据上述DFA或者状态转换图,编写源程序,依次读入源程序符号,对源程序进行逐个字符的读入,然后判别再处理,将识别结果(包括识别成功的结果和识别错误的结果)存进新建的结构体并将其指针存进符号表对象op_table中,直到源程序结束;
参考思路(部分实现细节不同):
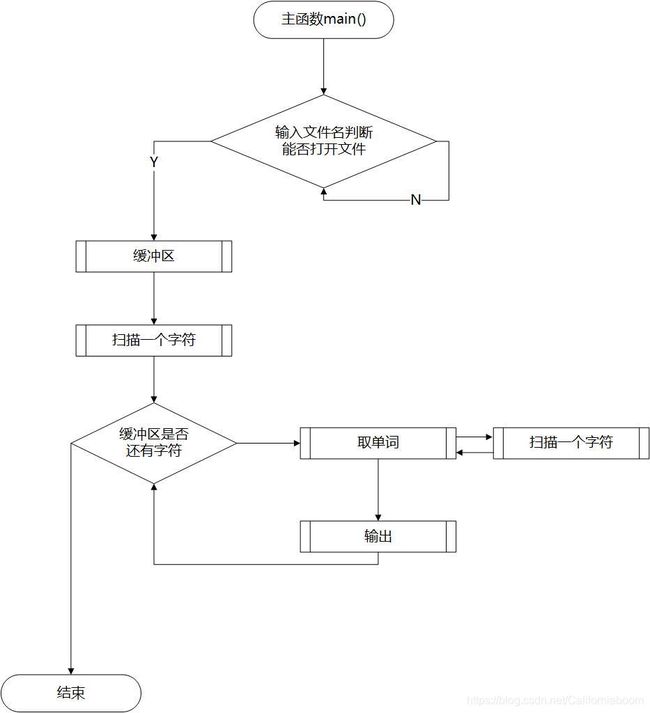
- 输出所得符号表的所有内容;
- 为符号表释放内存并完成销毁。
五、实验结果
实验测试源代码保存在文件test.txt当中,其中包含关键字(int、if、return)、标识符(main、_a7x、c_)、常数(0、86、10)、运算符(=、+、>=、==)、分隔符(,、;、(、)、{、})以及错误输入(?=、50nb、%),并且首尾均有一定量的空白字符如换行(\n)、空格、制表(\t)等,对应自定义的目标可用符号表内容均包含在内,能够完整的展示程序功能。
test.txt如下(部分空白位置为空白字符):

实验识别结果如下:

可见识别结果正确的单词以(种别码,单词)形式出现,而错误结果则以ERROR:… 形式出现,后面会附加上大致的错误原因,如Unrecognized Character代表词法分析器不能识别该字符,INDENTIFIER and CONSTANT error代表标识符与常数混合错误。
六、实验结论
实验利用自定义的源程序进行测试,结果正确,符合预期结果,测试源码及结果截图和说明如上所示。
七、实验小结
对于词法分析器,最好还是通过状态转换图或DFA的构造来决定具体编程实现,如果不这样分析而是直接对程序运行过程进行分析也可以得到一个分析程序,但是这样可能会出现很多没有考虑到的情况(比如,部分单词识别错误造成连带识别,使得两个单词被错误识别为一个单词)。
实验过程中也出现了一些问题,比如对于复合操作符<=、>=、==的识别较为困难,一开始如果直接把<、=、>简单的归于operator当中,则难以进行后续识别,因为operator当中除上述三个字符外的其他符号后面不能接“=”符号,需要对<、>、=符号进行超前搜索,因此将其单独处理比较合适。即当识别到<、>、=符号时,前进一个字符进行试探,试探成功则完成识别,试探失败则退回一个字符完成识别,类似于超前搜索;还有,针对C++的标识符组成结构,_符号也属于标识符的一部分,并且所起的作用与字母是相同的,因此将其归类到letter当中方便编程实现。
八、附录
实验源码如下。
#include