MySQL基于成本的优化
MySQL的成本是什么?MySQL在执行一个查询的时候,其实是有多种不同的方案的,但是最终会选择一种成本比较低的方案,那么这个成本都体现在什么地方?如何计算?
MySQL的成本
I/O成本 : 把数据从磁盘加入到内存的过程损耗的时间。 读取一个页面花费成本是1
CPU成本 : 读取以及检测结果是否满足对应的搜索条件,对结果集进行排序等操作损耗的时间。读取以及检测一条记录是否符合搜索条件的成本默认是0.2 。
基于成本的优化步骤是什么?
在执行一条查询语句之前,MySQL的查询优化器会找出来该语句使用的索引方案,对比成本之后选出来一个最低的方案,最低成本方案也叫做执行计划。 总结来看,有4步:
1. 根据搜索条件查找所有可能使用的索引
2. 计算全表扫描的代价
3. 计算不同的索引执行查询的代价
4. 对比各种执行方案,找出成本最低的方案
根据搜索条件查找所有可能使用的索引
对于B+树索引来说,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以写成<>)或者LIKE操作符连接起来,就可以产生一个所谓的范围区间(LIKE匹配字符串前缀也行),也就是说这些搜索条件都可能使用到索引
计算全表扫描的代价
全表扫描的过程是:把聚簇索引中的记录都依次和给定的搜索条件做一下比较,把符合搜索条件的记录加入到结果集中,所以需要将聚簇索引对应页面加载到内存中,然后在对其进行筛选。 查询成本 是 I/O成本 + CPU成本。
聚簇索引占用的页面数量决定 I/O成本
表中的记录数量决定 CPU成本。
这两个数量从何而来? MySQL的大佬为每个表维护了一个统计信息,这个数据已经被收集存放好了。 我们直接使命命令查看即可:
SHOW TABLE STATUS LIKE 'single_table'\G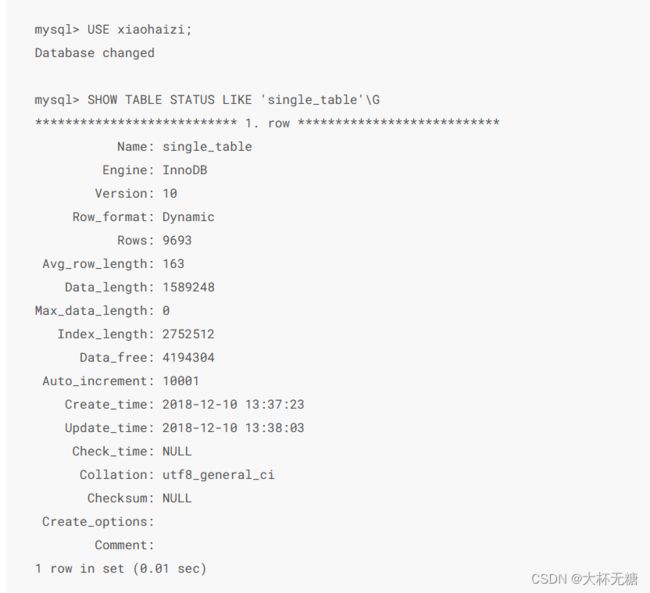
找到我们关心的参数,Rows 和Data_length ,其中Rows表送的记录数量,是模糊的,大致准确的。 我们重点来看一下Data_length,该参数表示该表占用的存储空间的字节数,对于InnoDB存储引擎来说,该值就是聚簇索引占用的存储空间大小。
Data_length = 聚簇索引的页面数量 * 每个页面的大小于是我们很容易的就求出来了聚簇索引页面的数量。 有了聚簇索引页面的数量和rows,我们就可以计算出来全表扫描的成本了。
计算不同索引执行查询的代价
MySQL查询优化器会查找到所有可能用到的索引,然后分别计算其成本 ,然后还要计算使用联合索引的成本。 如果是唯一二级索引的话,会优先分析。
建表语句
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
搜索条件
SELECT * FROM single_table WHERE
key1 IN ('a', 'b', 'c') AND
key2 > 10 AND key2 < 1000 AND
key3 > key2 AND
key_part1 LIKE '%hello%' AND
common_field = '123';
先来分析idx_key2 执行查询的成本分析

对于二级索引+ 回表的方式,成本依赖于两个方面
一:范围区间的数量。不管该范围的二级索引导致占用了几个页面,默认一个范围和读取一个页面的成本是相同的,都是1
二:需要回表的记录数。 对于本例子的范围查询,就是要找区间最左记录和区间最右记录,然后即可统计出来符合条件的索引记录条数了,每条记录的成本是0.2 。 这种方式叫做 index dive
如何统计具体的条数,简单来说,就是最左和最右两条记录都分别对应一个数据页,只需要记录页b和页c对应的目录项记录之间隔着几条记录,就相当于是页b和页c之间隔着几个数据页。
三:根据这些记录里面的主键值到聚簇索引中做回表操作。 MySQL默认回表一次的成本和访问一个页的成本一样,都是1
四:回表操作后得到用户的完整记录,然后再监测其他搜索条件是否成立,每次是0.2
idx_key1同理,不再赘述
基于索引统计数据的成本计算 适用于什么场景? 是为了解决什么样的问题呢?
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
上面的查询会产生很多的单点访问区间,我们对每个区间都要去使用index dive 去查询区间最左记录和区间最右记录的话,很耗费性能,MySQL中默认会有一个参数,如果小于这个值,使用index dive查询,如果超过了这个值,就要用到我们上面说的,基于索引统计数据的成本进行估算。

这里所说的统计索引数据指的是这两个值:一是使用 SHOW TABLE STATUS 展示出的Rows 值,也就是一个表中有多少记录。 二是上面表格中的Cardinality 。 两者结合,可以计算出索引列中的值一个平均出现X次。
假设上面的查询语句有20000个参数,那成本就是20000 * X。 很明显,没有index dive准确。
连接查询的成本
上面说的,都是单表查询的成本,接下来我们看一下连接查询的成本。
根据之前的知识,MySQL连接查询采用的是循环嵌套连接算法,驱动表被访问一次,被驱动表被访问多次,所以查询的成本就是两个部分构成:一是单次查询驱动表的成本; 二是多次查询被驱动表的成本。 驱动表进行查询之后得到的记录条数称为被驱动表的扇出。
两表连接的计算成本是:单次访问驱动表的成本 + 驱动表扇出数量 * 单次访问被驱动表的成本
对于外连接来说,驱动表是固定的,所以只用分别为驱动表和被驱动表选择成本最低的访问方法。
对于内连接来说,多了一步,不同的表作为驱动表最终查询的成本是不一样的,需要考虑最优的表的链接顺序。 然后分别为驱动表和被驱动表选择成本最低的访问方法。