Python3 - list sort方法实现多条件自定义排序
基础语法
Python3的list的sort方法定义如下

sort方法:
- 会改变列表本身
- 默认将列表元素进行升序
- 返回None
sort方法可以接收两个参数:
- key:该参数接收一个函数,函数又会接收当前列表的每一个元素作为入参,而函数的返回值会作为对应列表元素的排序优先级
- reverse:接收布尔值True或者False,默认是False,即不进行倒序,如果传入True,相当于进行降序
列表元素是不同类型时的排序规则
数值列表的按照数值大小进行排序
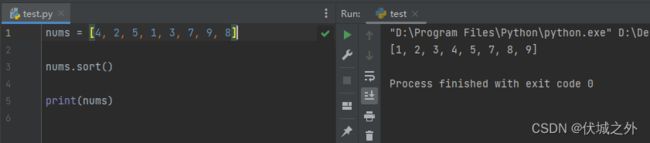

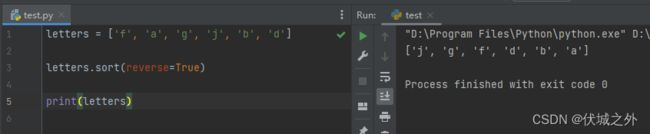
字母列表按照字母的ASCII码值大小进行排序

元素是列表时的排序规则

可以发现,如果列表元素是一个列表时,首先会按照元素列表的第一个元素进行比较,比如我们看输出结果中,都是按照元素列表的第一个元素值进行的升序。如果元素列表的第一个元素值相同,则继续按照列表元素的第二个值进行升序。

降序同理。
元素是元组时的排序规则
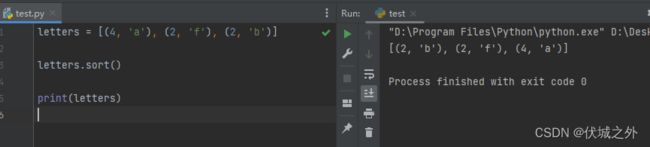

和元素是列表时同理。
自定义排序
利用key进行自定义排序
有时候我们可能并不想列表的默认规则进行排序,比如下面例子:
nums = [-2, 1, -4, 3, -5]
请对上面的数值列表按照绝对值大小升序。
此时,我们就无法利用sort的默认排序规则实现了,此时需要基于key参数进行自定义排序

上面例子中,我们将priority函数传给了key参数,此时底层,sort方法会遍历列表,将每一个遍历到的元素传入priority函数的形参x,而priority函数的返回值将作为对应列表元素的排序优先级。
上面priority函数将列表元素的绝对值作为了对应列表元素的排序优先级,因此最后输出结果为
[1, -2, 3, -4, -5]
lamdba优化
当key参数传入的函数非常简单时,可以进行lamdba优化
比如上面priority函数
def priority(x):
return abs(x)
可以简化为一个lamdba函数
lamdba x : abs(x)

lambda函数并没有多难,其实就是一个匿名函数,即没有名字的函数。具体关于具名函数转化为lambda函数的规则,后面有机会我再写一篇博客,或者大家可以自行查找。
利用key实现降序
通常我们都是基于sort函数reverse参数实现的列表降序,比如

那么有没有办法不基于reverse参数实现列表元素的降序呢?
大家可以看下面代码实现,基于key也同样实现了列表元素降序

我们知道,如果不给sort方法的reverse参数传True,那么sort方法默认就是升序,因此上面排序其实还是升序,但是这里的升序并不是基于列表元素本身,而是基于列表元素的优先级。
为什么呢?
因为我们为key传入一个lamdba函数,该函数将每个列表元素取负,作为对应列表元素的优先级。
即:
元素4的优先级是-4
元素2的优先级是-2
元素1的优先级是-1
.....
因此,元素值越大,其优先级反而越小,这里按照元素的优先级升序的话,其实就是按照元素本身值得大小降序。
如果大家理解了上面基于key实现降序的原理,可能还会有疑问,我明明可以用reverse参数实现降序,为什么要舍简求繁地定义一个优先级函数传给key来实现降序呢?
答案是:为了后面多条件自定义排序做准备。
多条件自定义排序
前面讨论地其实都是单条件排序,比如按照元素自身的大小,或者按照元素的绝对值大小。但是现实场景中,大多都需要完成多条件排序。
比如有需求如下:
- 张三的身高180cm,体重90kg
- 李四的身高160cm,体重50kg
- 王五的身高160cm,体重60kg
现在请你按照身高进行升序,如果身高相同,则再按照体重进行降序。
此时,靠着前面的单条件排序的知识其实就不太够用了。此时有两种方式实现多条件排序:
- 基于原生key进行多条件排序
- key接收functools.cmp_to_key
其中functools.cmp_to_key可以自行了解,这里只介绍基于原生key实现多条件自定义排序。
我们先回顾下之前单条件排序时的一个知识:
当要排序的列表元素是:元组(或列表)时,此时排序是按照元组(或列表)的元素进行依次比较的。
比如上面例子中,对一个元组列表进行升序排序,首先会按照元组的第一个元素进行升序,如果第一个元素相同,则继续按照第二个元素进行升序。
而这是实现多条件排序的关键前置知识。下面我们直接上本需求的实现代码:

上面代码中persons是一个列表,其元素也是列表,元素的含义是[身高,体重]
这里我们给sort方法的key参数传入了一个priority函数,sort方法底层会遍历每一个列表元素,作为入参传给priority函数,priority函数用于计算入参的优先级,并返回该优先级。
上面代码中priority函数参数x就是persons列表的每一个元素,而priority函数的返回值是一个元组(x[0], -x[1]),该元组就是对应元素x的优先级。
其中x[0]就是身高,x[1]就是体重。
因此sort排序是就是按照每个元素的优先级(x[0], -x[1])进行排序的。根据前面的知识:当列表的元素是元组时,此时排序是按照元组的每一个元素进行依次比较的。
即先按照x[0]进行升序,如果x[0]相同的话,则继续按照-x[1]进行升序。而-x[1]进行升序,其实就是按照x[1]进行降序。
因此,上面代码就实现了按照身高进行升序,如果身高相同,则继续按照体重继续降序。
多条件自定义排序中的字典序降序实现
如果前面的需求,改一下,按照身高升序,如果身高相同,则继续按照体重降序,如果体重相同,则最后按照名字字典序降序。
- zhangsan的身高180cm,体重90kg
- lishi的身高160cm,体重60kg
- wangwu的身高160cm,体重60kg
此时,如何在多条件自定义排序中实现某个条件的字典序降序呢?
首先,我们需要了解下,字典序是什么?
所谓字典序,即按照ASCII码值排序,
比如 b 的ASCII码值为98,a 的ASCII码值为97,因此 b > a。
而字典序,默认指的是字典序升序。即按照ASCII码值升序。
而字符串的字典序比较,其实就是字符串的逐个字母的ASCII码值比较,比如
- “aba”
- "abc"
结果是"abc"字典序更大。因为上面两个字符串的第3个字符:c的ASCII码值大于a的
在多条件中,实现某个条件的中字符串的字典序降序,其实就是将对应字符串转成ASCII码值列表进行降序
比如"aba"字符串,转为ASCII码值列表就是 [97, 98, 97]
比如"abc"字符串,转为ASCII码值列表就是 [97, 98, 99]
降序的话,则在对上面列表进行取负操作,即
比如"aba"字符串,转为ASCII码值列表,并取负就是 [-97, -98, -97]
比如"abc"字符串,转为ASCII码值列表,并取负就是 [-97, -98, -99]
此时就可以实现多条件中的字典序降序了。
而python中获取一个字符的ASCII码值,可以使用ord函数

因此本需求实现,如下图:
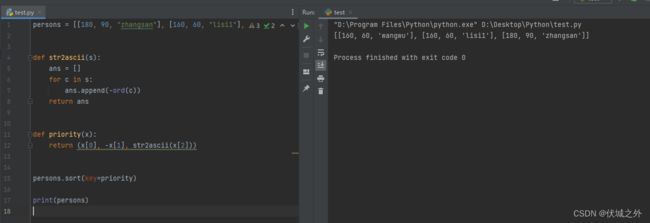
其中str2ascii用于将一个字符串转为ascii码列表,并且对元素取负
当然,我们可以用推导式进行简化

当然,我们也可以继续将priority函数优化为lamdba函数
