【Linux】探索进程的父与子
目录
- 1.获取进程PID
-
- 1.1进程PPID
- 2.通过系统调用创建进程-fork初识
-
- 2.1为什么fork函数要给子进程返回0,给父进程返回pid?
- fork函数如何做到返回两次的?fork干了什么事情?
- 怎么理解一个变量为什么有两个不同的值?
- 如果父子进程同时创建好,fork()往后,父子进程谁先运行呢?
- 理解bash
- 小结

博客主页:小智_x0___0x_
欢迎关注:点赞收藏✍️留言
系列专栏:Linux入门到精通
代码仓库:小智的代码仓库
1.获取进程PID
一个进程想要获取自己的PID可以通过调用系统调用接口getpid(),它会返回调用这个函数进程的PID,返回值是pid_t类型。

我们来写代码使用一下这个函数:
#include 我们在编译前可以写一个监控脚本:
while :; do ps axj | head -1 ; ps axj | grep proc | grep -v grep; sleep 1; done
这条命令的作用是每隔一秒检查并显示与 “proc” 相关的进程信息。下面是对这条命令的详细解释:
while :; do ... done:这是一个无限循环。: 是一个shell内建命令,什么都不做,只是返回一个状态码 0(表示成功)。while :的意思就是无限循环,因为 : 总是返回成功,所以这个循环会一直执行下去,直到被外部中断。ps axj | head -1: ps axj是一个显示所有进程的命令,j选项表示显示作业控制信息,a表示显示终端上的所有进程(包括其他用户的进程),x表示显示没有控制终端的进程。| head -1的意思是只显示第一行,也就是列头信息。ps axj | grep proc | grep -v grep:这个命令是用来查找与 “proc” 相关的进程。grep proc是查找包含 “proc” 的行,grep -v grep是排除掉包含 “grep” 的行,也就是排除掉查找 “proc” 的这个grep命令自身。sleep 1:这个命令是让循环暂停一秒,然后再继续执行。
我们下来编译运行一下看结果>

可以看到我们用ps命令查询出来的进程pid和进程自己打印出来的pid相同。
1.1进程PPID
当然进程除了pid之外呢,进程还有所谓的叫做父进程pid,那么当然我们查的时候呢,我们看到这儿有一个pid,那么这还有一个ppid,这个ppid什么意思呢,就第1个p呢,就相当于叫做parent啊,父母的意思,然后第2个p呢就是process ID ,所以PPID呢就是的父进程id号,所以呢,我们一般在进行我们进程所对应的一个操作的时候呢,除了能获得自己的id也能获得父进程的id值。
获取父进程pid的函数接口是getppid()返回值类型参数跟getpid()相同。
我们再来编一段代码,来获取父进程id值:
#include 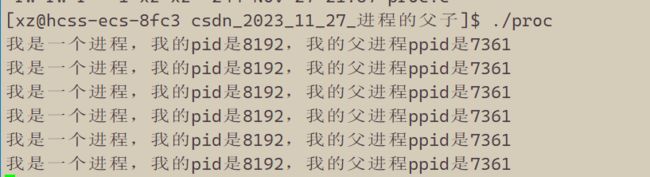
我们可以看到进程可以打印出他的id和他的父进程id,我们将进程重新跑起来>
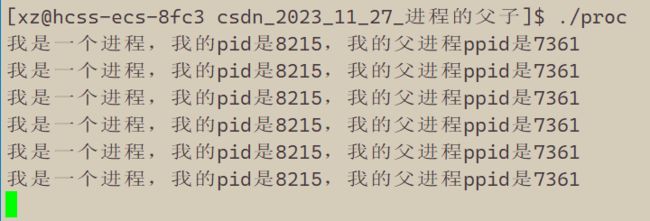
这里我们发现我们每次运行的时候进程pid是会发生变化的,那为什么父进程id值不变呢,那这个进程id号为7361的进程到底是个什么东西呢?
我们来使用下面指令来观察
ps axj | head -1 ; ps axj | grep 7361

我们的命令行解释器,那么它的核心那么命令行解释器那么它的核心是帮助获取用户的输入然后呢,帮助用户进行命令行解释。
给大家讲一个关于张三、王婆和操作系统的小故事,王婆每次接收到张三的请求都会尽力去执行,但总是失败。为了维护自己的声誉,王婆决定招募一批实习生来帮忙。自从有了这些实习生后,每当你需要命令行解释时,王婆不再亲自出马了,而是直接派遣实习生去协助你。在这个故事中,bash就像传说中的王婆一样。当我们运行一个进程时,命令行解释器会解释并执行你的指令。即使某个执行者出现问题,也不会影响到我们的bash进程。
而当我们退出xshell重新登录,我们对应的bash进程的id也会不同。
2.通过系统调用创建进程-fork初识
我们一直在讨论如何创建进程以及维护进程之间的父子关系。现在我们来谈一下实际创建进程的方法和如何维护这些关系。如果我想创建进程,我应该采取哪些方法呢?今天我们已经了解了其中一种创建进程的方法,那就是通过直接执行命令行来创建并运行一个进程。执行./proc命令就可以创建一个新的进程并在其上运行。但是,如果我想手动创建一个进程呢?为了满足这个需求,我们可以使用Linux系统中的fork函数来手动创建进程。这个函数允许我们创建一个新的进程,并在其中运行我们想要的代码。
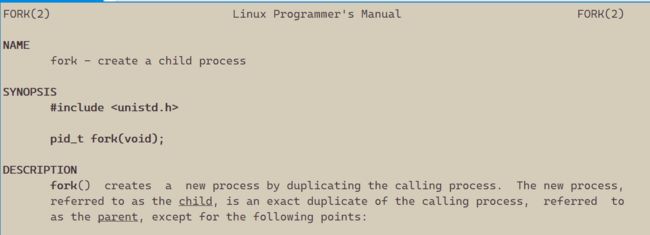
fork()函数通过复制调用它的进程(我们称之为父进程)来创建一个新的进程(我们称之为子进程)
我先给大家写一个demo代码,来演示一下效果:
int main()
{
printf("before:only one line\n");
fork();
printf("after:onlu one line\n");
sleep(1);
return 0;
}

这里我们看到fork之前的代码被执行了一次,但是fork之后的代码被执行了两次,这是因为我们在创建用fork创建进程的时候,fork之前只有一个执行流,fork之后就会变成两个进程.
那么怎么证明呢,我们再来使用man手册来查看fork函数:

当fork()成功执行时,它会在父进程中返回子进程的进程ID (PID),而在子进程中返回0。这种方式使得父进程可以得知子进程的PID,如果fork()执行失败,它会在父进程中返回-1,并且不会创建子进程。同时,全局变量errno会被设置为一个表示错误原因的值。
我们再来写一段代码演示一下:
int main()
{
printf("begin:我是一个进程,pid:%d,ppid:%d",getpid(),getppid());
pid_t id = fork();
if(id == 0)
{
//子进程
while (1)
{
printf("我是子进程,pid:%d,ppid:%d",getpid(),getppid());
sleep(1);
}
}
else if(id>0)
{
//父进程
while(1)
{
printf("我是父进程:pid:%d,ppid:%d",getpid(),getppid());
sleep(1);
}
}
else
{
//error
}
return 0;
}

通过打印结果我们可以得出,在上面的一份代码中 id 大于0和 id 等于0同时存在, if 和 else if 同时满足,这个现象说明此时一定存在两个进程,即原来的 proc 进程和在 proc 进程中创建的子进程,因为在一个进程中 if 和 else if 是不可能同时满足的。这也符合 fork 函数创建子进程的目的,fork 函数创建子进程后,子进程会执行if中的代码段,而父进程会执行else if中的代码段,会从原来的一个执行流变成两个执行流。
2.1为什么fork函数要给子进程返回0,给父进程返回pid?
返回不同的返回值,是为了区分让不同的执行流,执行不同的代码块!
一般而言啊,fork之后的代码父子共享啊,也就是说呢,其实当我们fork之后,后续的所有代码父子进父子进程他都能看到啊,只不过呢,我们是需要通过一定程度去区分,我们可以让父进程和子进程执行不同的代码块,那么当然应该这样,要不然我为什么创建子进程呢,我不就是想让你的子进程过来帮我忙嘛,把你创建出来,让你和我做不同的事情,所以我们的返回值一定是需要不同的,即便是返回值未来,如果假设系统设计者把它设成相同的了,未来我们一定也要有方法区分父子进程,这是这个,当然这不是这个问题的答案,问题是为什么要给子进程反回0给父进程反回pid,上面回答的是为什么父子进程反回值不同,我们现在知道了,因为父子进程,那么后续的代码是共享的,而我们可以通过不同的返回值来区分不同的执行流,让父子执行不同的代码块好也没有毛病,具体他执行的代码块要干啥我们后面来介绍啊 现在的问题是为什么要给子进程返回0给父进程返回pid。
给大家举一个生活当中的例子啊:
在现实生活中,一个父亲可以有多个子女,而每个子女只有一个父亲,这是容易理解的。在进程的世界中,一个父进程也可能有多个子进程。但有时,我们可能需要对特定的子进程进行控制。想象一下,如果一个家庭有10个孩子,当父亲喊“儿子,你过来”时,所有10个孩子都过来了,那么父亲到底是想叫哪个孩子呢?
因此,对于父进程来说,它必须有一种方法来区分每一个子进程。这就是为什么fork()在父进程中返回子进程的PID。这样,父进程就可以使用这个PID来标定和识别每一个子进程的唯一性。而对于子进程来说,情况就简单了。它只需要调用getppid()函数就可以直接获取其父进程的PID。所以,子进程要找到父进程并不需要花费太多成本,它只需要通过返回0来表示成功就可以了。这就是为什么我们在父进程中返回子进程的PID的原因,因为未来我们可能想通过父进程使用PID来明确控制我们要访问的是哪一个子进程。
fork函数如何做到返回两次的?fork干了什么事情?
理解一个函数如何被返回两次,尤其是fork(),首先需要深入了解fork()的工作原理。在没有调用fork()之前,系统中只有一个进程。进程由内核数据结构和与之关联的代码和数据组成。当创建一个新进程时,需要为它创建相应的进程控制块(PCB)以及与之关联的代码和数据。CPU随后会调度这个新进程,执行它的代码和数据。
调用fork()后,会创建一个新的子进程。创建子进程的本质是系统中多了一个新进程。由于进程由内核数据结构和代码及数据组成,因此新创建的子进程首先需要创建自己的task_struct(Linux内核中的进程描述符)。这个子进程的大部分属性是基于父进程的属性创建的,相当于复制了父进程的对象并对部分属性进行了修改。例如,子进程会有自己的PID,而其父进程ID(PPID)则设置为父进程的PID。这样,父子进程就有了自己的ID关系。
然而,子进程在刚创建时并没有自己的代码和数据,因此它只能访问父进程的代码和数据。这就是为什么fork()之后父子进程的代码是共享的。当CPU调度并运行父进程的代码时,它执行的是父进程的代码;当调度并运行子进程的代码时,它执行的仍然是父进程的代码。
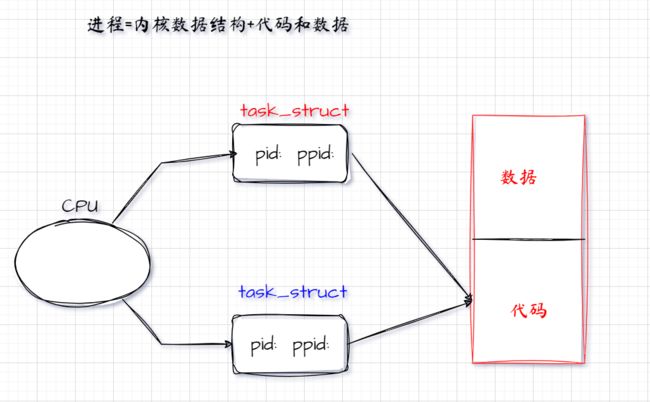
我们为什么要创建子进程呢?不就是为了让父子进程执行不同的事情,那就需要让父子进程执行不同的代码段,所以fork就必须要返回两个不同的返回值。
我们来看看fork函数具体做了哪些事情:

所以我们最终的结果也就来了:当我们准备在fork()之后进行return时,实际上子进程的创建工作已经完成。一旦fork()创建完毕,系统中就存在了子进程,于是CPU可以分别调度父进程和子进程来运行。需要注意的是,在创建子进程之后,父子进程的代码是共享的。由于return语句也是代码的一部分,当执行到这里时,父进程和子进程都已经存在。因为return语句是父子进程共享的,所以当父进程调度并执行这个函数时,它会返回一次;同样地,当子进程调度并执行时,它也会返回一次。这就是为什么fork()函数最终会被返回两次的原因。
怎么理解一个变量为什么有两个不同的值?
当使用fork()创建子进程时,系统中确实多了一个进程,这也意味着操作系统内必须为这个新进程创建一个对应的PCB(进程控制块)。这个子进程的PCB同样可以被CPU调度运行。与父进程不同,子进程在创建之初并没有自己的代码和数据。
需要明确的是,进程在运行时具有独立性。这意味着一个进程的崩溃或退出不会影响到其他进程。例如,如果在Windows上运行的QQ崩溃了,它不会影响到同时运行的画图软件或XShell等其他进程。每个进程都是独立的,它们的崩溃或退出不会影响其他进程。
为了保证进程的独立性,不能让父进程和子进程共享同一份数据,因为数据可能会被修改,修改后可能会影响其他进程。因此,虽然父子进程的代码是共享的,但数据不一定是共享的。理论上,子进程需要为自己拷贝一份父进程的数据。但实际上,数据的拷贝工作是由操作系统自动完成的。当子进程需要访问父进程的某部分数据时,操作系统会识别出这一需求,并在系统内存中为子进程重新开辟一段空间。子进程在新开辟的空间内进行数据的修改,这样就不会影响到父进程的数据。这种技术被称为写时拷贝(Copy-on-Write)。它确保了父子进程在数据层面的独立性,同时也避免了不必要的数据冗余。
总结来说,fork()创建的子进程具有独立的PCB,可以被CPU调度运行。虽然父子进程的代码是共享的,但数据不一定是共享的。操作系统通过写时拷贝技术确保父子进程在数据层面的独立性,同时也避免了数据冗余。
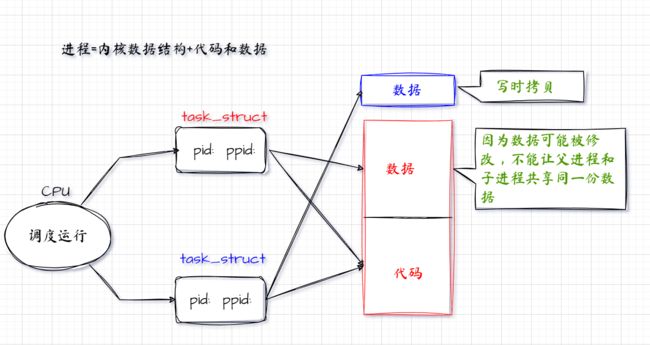
fork 函数在执行 return 返回的时候是往 id 变量里面写入嘛,父进程 return 一次,子进程 return 一次,子进程会执行写时拷贝,这就是为什么一个 id 变量有两个不同的数据,本质上是因为有两块空间。为什么同一个变量名可以有不同的内容,这个问题我们在后面介绍进程地址空间的时候为大家介绍。
如果父子进程同时创建好,fork()往后,父子进程谁先运行呢?
一般而言,当一个进程被创建后,作为用户,我们并不需要关心其具体的运行时机,因为这是由操作系统自动管理的。例如,我们打开网易云音乐、浏览器或画图软件时,并不需要知道这些软件在操作系统层面何时运行。操作系统负责底层进程的调度,而我们只需直接使用这些软件。
父子进程的运行顺序不是由用户决定的,而是由操作系统的调度器决定的。调度器是操作系统中的一个组件,负责决定哪个进程在何时运行。调度器的工作是基于特定的算法,从多个进程中选择一个合适的进程放到CPU上运行。
调度器的调度原则通常是尽可能平均或公平地分配时间片。例如,如果一个进程已经被调度了10毫秒,而另一个进程从未被调度过,那么调度器可能会选择这个未被调度过的进程来运行,以确保每个进程都有机会运行。这就是调度器的作用,确保所有进程都能得到公平的调度,并且不会有进程被遗漏。
需要注意的是,不同系统或不同时间段内,父子进程的运行顺序可能会有所不同,因为调度器的工作是基于特定的算法和当前系统的状态来决定的。因此,我们不能确定父子进程的确切运行顺序。
理解bash
我们接着从这个故事说起:
“王婆为了保证自己在给别人说媒时,如果失败了,不会影响到自己,她是通过创建子进程来实现的。现在我的问题是,bash是如何创建子进程的?虽然我们还没有看或写bash的源代码,但我可以推断一下这个过程。
bash一定会调用fork来创建子进程,并让自己的代码继续执行命令行解释,而让子进程去执行解释新的命令。那么,bash自己就会继续接受用户的输入,并打印出提示符,等待用户输入新的命令。这就是为什么我们运行的所有命令都是在bash内部,因为所有的进程都是通过fork创建出来的。
当然,这只是问题的一半,后面还有更多内容需要探讨。但我们已经理解了创建子进程的过程,核心结论就是bash也是一个进程,当执行命令时,bash内部一定会为我们fork创建新的子进程,然后执行我们的代码。”
小结
今天我们学习了"【Linux】探索进程的父与子"相信大家看完有一定的收获。种一棵树的最好时间是十年前,其次是现在! 把握好当下,合理利用时间努力奋斗,相信大家一定会实现自己的目标!加油!创作不易,辛苦各位小伙伴们动动小手,三连一波~~~,本文中也有不足之处,欢迎各位随时私信点评指正!