分层级联Transformer!苏黎世联邦提出TransCNN: 显著降低了计算/空间复杂度!
导读
本文是苏黎世联邦理工-Luc Van Gool组联合南开大学和电子科技大学在Transformer上的最新工作,这项工作主要提出了一个新的分层级联多头自注意力模块(MHSA),通过分层级联的方式显著降低了计算/空间复杂度。H-MHSA 模块可轻松插入任何CNN架构中,并且可以通过反向传播进行训练。基于此,我们提出了一种新的骨干网络叫做TransCNN,它完美继承了CNN和Transformer的优点,与当前最具竞争力的基于CNN和Transformer的网络架构相比,TransCNN在计算/空间复杂度和准确率上实现了最先进的性能。

作者单位:苏黎世联邦理工(Luc Van Gool大佬组)、南开大学, 电子科大
论文:https://arxiv.org/abs/2106.03180
代码: https://github.com/yun-liu/TransCNN
摘要与介绍
本文主要提出了一种分层级联自注意力模块(MHSA),通过以一种级联计算的方式解决了多头自注意(MHSA)中由于计算/空间复杂度高而导致视觉Transformer效率低下的问题,同时该模块还可以使得Transformer中的自注意力计算更加灵活和高效。具体来说,首先将图像拆分为多个patch,而每一个patch都可视为一个token(标记)来学习小网格内的特征关系。我们不再跨所有patch去计算注意力,而是将patch进一步分组到每个小网格中,并在每个网格中计算自注意力,从而捕获局部特征关系,并产生可区分的局部特征表示。然后,将小网格合并到较大网格中,同时将上一步中的小网格视为一个新的token来重新计算下一个网格中的注意力。通过反复迭代这个过程以逐渐减少token的数量。在整个过程中,我们的H-MHSA模块在不断增加的区域网络大小中逐步计算自我注意力,并自然地以分层的方式对全局特征关系进行建模。由于每个网格在每一步只有少量的标记,所以,我们可以显著降低视觉Transformer的计算/空间复杂度。最后,H-MHSA 模块可轻松插入任何CNN架构中,并且可以通过反向传播进行训练。因此,我们提出了一种新的骨干网络叫做TransCNN,它本质上继承了Transformer和CNN的优点。所以,它具有学习尺度变换以及位移不变特征表示的能力,还可以对输入数据建立长期依赖关系。根据ImageNet和MS-COCO数据集的实验结果表明:与当前最具竞争力的基于CNN和Transformer的网络架构相比,TransCNN在计算复杂度和准确率上实现了最先进的性能。
模型架构

最近关于很多vision Transformer的工作通常旨在建立纯Transformer网络,同时为视觉和自然语言处理任务提供统一的体系结构。然而,这对于视觉任务可能不是最优的选择,因为这些架构不擅长学习那些对视觉数据至关重要的局域表示。受此启发,我们设计了H-MHSA模块,它可以很容易地插入到任何现有的CNN架构中。同时,我们的网络基本上可以继承Transformer和CNN的优点。首先,我们在骨干网络中保留3D特征输入图,并使用全局平均池化层和全连接层来预测图像类别。这点与现有的依赖另一个1D类标记进行预测的Transformer是不同的。之前的Transformer网络通常采用GELU函数进行非线性激活。然而,在网络训练中,GELU函数需要大量内存。根据经验发现,SiLU函数的性能与GELU相同,而且更利于存储。因此,这里我们使用SiLU函数进行非线性激活。TransCNN的总体架构如图1所示。在开始阶段,不同于之前的Transformer通过直接拉直图像patch,我们应用了两个顺序的vanilla 卷积,每个卷积的步长为2,然后将输入图像下采样到原来的1/4尺度大小.然后,我们将H-MHSA和卷积块进行交替叠加使用,主要分为4个阶段,分别以1/4,1/8,1/16,1/32的金字塔特征尺度进行划分。我们采用倒残差瓶颈块(IRB,图1c)和深度可分离卷积。在每个阶段的最后,我们设计了一个简单的二分支降采样块(TDB,图1d)。它包括两个分支:一个分支是步长为2的vanilla 卷积;另一个分支包括一个池化层和一个 卷积。在特征降采样过程中,这两个分支通过按元素求和的方式融合,以保留更多的上下文信息。实验表明,TDB的性能优于直接降采样。TransCNN的详细配置如表1所示。我们提出了两个版本: TransCNN-small和TransCNN-base。具体网络结构配置如下表所示:

模型方法
接下来,我们首先回顾一下视觉Transformer。然后,我们将详细介绍本文提出的H-MHSA模块。
Revisit Vision Transformer
Transformer主要依赖MHSA来建模长期特征依赖关系,这里,我们用 表示输入, 和 分别代表Token的数量以及每个token的特征维度,然后,我们有the query : , the key: , the value: ,并且
在假设输入和输出具有相同维度的情况下,传统的MHSA可以通过下式计算:
其中 表示近似归一化,将Softmax函数应用于矩阵的每一行。注意,为了简单起见,我们在这里省略了多个头的计算。矩阵乘积 具体做法是首先计算每对token之间的相似度。然后,在所有token的组合基础上再派生获取得到每个新的token。在MHSA计算后,可以进一步添加残差连接以方便优化,如:
在这里, 是特征投影的权重矩阵。最后,采用MLP来对特征进行增强,表示形式为:
这里, 代表一个Transformer block的输出。MHSA的计算复杂度表示如下:因此,很容易推断出空间复杂度(内存消耗)应当为 级别。因此对于高分辨率的输入特征图, 可能变得非常大,这就大大限制了vision Transformer在视觉任务中的泛化性。基于此,我们的目标是在不降低性能损失的基础上,进一步降低计算/空间复杂度,并保持全局特征关系建模的能力。
Hierarchical Multi-Head Self-Attention
在这里,我们的H-MHSA模块,它可以降低计算/空间复杂度。首先,我们不是针对整个输入中计算注意力,而是以分层的方式计算注意力,这样每个步骤只处理有限数量的token。图1b为H-MHSA的范式。
假设输入特征映射 的高度为 ,宽度为 ,我们有 。然后,我们可以将特征图划分为小网格,每个网格大小为 ,因此,我们对输入的特征图进行重构得到新的 :
并且:对于产生的局部自注意力 。为了简化网络优化,我们也进行如下变换:
添加残差连接后:
因为 式计算每个小的 网络快,所以这个计算复杂度得到了显著地减少。对于第 步,我们可以将第 步得到的更小的网络块 视为一个新的token,它可以简单地通过对注意力特征 进行下采样来实现:
这里, 和 分别表示:最大池化和平均池化。进一步针对
这里
然后我们同样将 划分为 大小的网格,并重新得到:
然后进一步有:
最后,我们得到:
残差连接: 这个过程将不断迭代,直到足够小。然后我们停止切分网格块。H-MHSA的最终输出为:
其中 表示将注意力特征上采样到原始大小, 是特征投影的权重矩阵。 为最大迭代步数。通过这种方式,H-MHSA可以建立全局特征依赖关系,相当于传统的MHSA。很容易证明,在所有 都相同的假设下,H-MHSA的计算复杂度为:
所以,我们显著降低了计算复杂度,即从 降低到了 ,并且这里 比 小得多。同理,空间复杂度也得到了显著降低。
Experiments
本文我们主要在ImageNet数据集上对提出来的TransCNN网络结构进行图像分类任务。首先,为了更好地理解我们的TransCNN结构,我们设计了一个消融实验。然后,我们将TransCNN与现有的基于CNN和Transformer的主干网络结构进行比较。最后,我们将TransCNN应用于MS-COCO数据集上进行目标检测和实例分割任务,进一步验证了该算法的优越性。
首先,我们对所提出的TransCNN的各种设计方案进行了评估,消融实验结果如下表所示:

在ImageNet数据集上,TransCNN与最先进的CNN和Transformer网络架构的在分类任务识别效果的比较,具体结果如下所示:

在MS-COCO val2017数据集上物体检测效果如下所示:

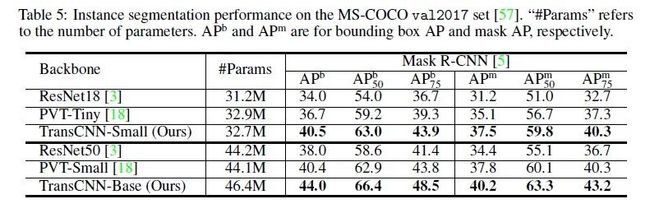
在MS-COCO val2017数据集上实例分割效果如下所示:
本文创新点总结
1. 本文提出了一个级联的MHSA模块,即H-MHSA,显著地降低了计算/空间复杂度。H-MHSA有两个显著的优势: i)直接对输入特征图进行全局依赖关系建模,ii)能够轻松处理大量输入图像。
2. H-MHSA可以灵活的插入到CNN中,而不用像传统的ViT那样,在注意力计算之后使用MLP进行特征增强。
3. TransCNN完美的继承了Transform和CNN的优点,根据图像分类、目标检测和实例分割的实验结果表明,TransCNN在特征表示学习方面有着较大的潜力和高效性。
4. 未来,神经结构搜索技术也可以应用于TransCNN进行参数配置优化。
重磅!DLer-AI顶会交流群已成立!
大家好,这是DLer-AI顶会交流群!首先非常感谢大家的支持和鼓励,欢迎各位加入DLer-AI顶会交流群!本群旨在学习交流人工智能顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)写作与投稿事宜。包括第一时间发布论文信息和公开演讲视频,以及各大会议的workshop等等。希望能给大家提供一个更精准的研讨交流平台!!!
添加请备注:AI顶会+学校/公司+昵称(如CVPR+上交+小明)

???? 长按识别添加,即可进群!