一步一步带你熟悉SpringBoot 配置slf4j+logback
前言
对于一个web项目来说,日志框架是必不可少的,日志的记录可以帮助我们在开发以及维护过程中快速的定位错误。相信很多人听说过slf4j,log4j,logback,JDK Logging等跟日志框架有关的词语,所以这里也简单介绍下他们之间的关系。
关系
首先slf4j可以理解为规则的制定者,是一个抽象层,定义了日志相关的接口。log4j,logback,JDK Logging都是slf4j的实现层,只是出处不同,当然使用起来也就各有千秋,这里放一张网上的图更明了的解释了他们之间的关系:

为什么使用slf4j+logback
我使用这个框架是因为一开始接触的时候就用的这个,后来在网上了解到slf4j+logback也确实当下最流行的日志框架,并且自己用着也确实很顺手,也就一直用了下来。
在Spring boot中使用slf4j+logback日志框架
添加配置文件
在Spring boot使用是非常方便的,不需要我们有什么额外的配置,因为Spring boot默认支持的就是slf4j+logback的日志框架,想要灵活的定制日志策略,只需要我们在src/main/resources下添加配置文件即可,只是默认情况下配置文件的命名需要符合以下规则:
- logback.xml
- logback-spring.xml
其中
logback-spring.xml是官方推荐的,并且只有使用这种命名规则,才可以配置不同环境使用不同的日志策略这一功能。
配置文件详解
首先介绍配置文件的关键节点:
框架介绍
scan:当配置文件发生修改时,是否重新加载该配置文件,两个可选值trueorfalse,默认为true。scanPeriod:检测配置文件是否修改的时间周期,当没有给出时间单位时默认单位为毫秒,默认值为一分钟,需要注意的是这个属性只有在scan属性值为true时才生效。debug:是否打印loback内部日志信息,两个可选值trueorfalse,默认为false。
根节点logback.xml配置文件具备很强的灵活性:
-
name:指定该节点的名称,方便之后的引用。class:指定该节点的全限定名,所谓的全限定名就是定义该节点为哪种类型的日志策略,比如我们需要将日志输出到控制台,就需要指定class的值为ch.qos.logback.core.ConsoleAppender;需要将日志输出到文件,则class的值为ch.qos.logback.core.FileAppender等。
-
name:用来指定受此level:可选属性,用来指定日志的输出级别,如果不设置,那么当前additivity:是否向上级传递输出信息,两个可选值trueorfalse,默认为true。
在该节点内可以添加子节点
,该节点有一个必填的属性ref,值为我们定义的节点的name属性的值。
name属性为root的additivity属性,所以该节点只有一个level属性。
介绍了根节点的三个主要的子节点,下面再介绍两个不那么重要但可以了解的子节点:
-
default,但可以使用设置成其他名字,用于区分不同应用程序的记录,一旦设置,不能修改,可以通过%contextName来打印日志上下文名称,一般来说我们不用这个属性,可有可无。 -
${}来使用变量,两个属性,当定义了多个name:变量名value:变量值
好了,介绍了上边的节点我们就已经可以搭建一个简单的配置文件框架了,如下:
demo
上面搭建了框架,定义了一个输出到控制台的ConsoleAppender以及输出到文件的FileAppender,下面来细说这两个最基本的日志策略,并介绍最常用的滚动文件策略的RollingFileAppender,这三种类型的日志策略足够我们的日常使用。
输出到控制台的ConsoleAppender的介绍:
先给出一个demo:
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
ConsoleAppender的功能是将日志输出到控制台,有一个encoder节点,所以这里我们介绍encoder节点即可。
该节点主要做两件事:
- 把日志信息转换成字节数组
- 将字节数组写到输出流
该节点的子节点%+转换符的格式定义,下面列出常用的转换符:
-
%date{}:输出时间,可以在花括号内指定时间格式,例如-%data{yyyy-MM-dd HH:mm:ss},格式语法和java.text.SimpleDateFormat一样,可以简写为%d{}的形式,使用默认的格式时可以省略{}。 -
%logger{}:日志的logger名称,可以简写为%c{},%lo{}的形式,使用默认的参数时可以省略{},可以定义一个整形的参数来控制输出名称的长度,有下面三种情况:- 不输入表示输出完整的
- 输入
0表示只输出 - 输入其他数字表示输出小数点最后边点号之前的字符数量
- 不输入表示输出完整的
-
%thread:产生日志的线程名,可简写为%t -
%line:当前打印日志的语句在程序中的行号,可简写为%L -
%level:日志级别,可简写为%le,%p -
%message:程序员定义的日志打印内容,可简写为%msg,%m -
%n:换行,即一条日志信息占一行
介绍了常用的转换符,我们再看看上边的例子中我们定义的格式:
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
日志的格式一目了然,可以看出我们在最前面加了[eran]的字符串,这里是我个人的使用习惯,一般将项目名统一展现在日志前边,而且在每个转换符之间加了空格,这更便于我们查看日志,并且使用了>>字符串来将%msg分割开来,更便于我们找到日志信息中我们关注的内容,这些东西大家可以自己按照自己的喜好来。
输出到文件的FileAppender
先给出一个demo:
D:/test.log
true
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
FileAppender表示将日志输出到文件,常用几个子节点:
true和false,默认为true,表示每次日志输出到文件走追加在原来文件的结尾,false则表示清空现存文件ConsoleAppender一样
显而易见,样例中我们的日志策略表示,每次将日志信息追加到D:/test.log的文件中。
滚动文件策略RollingFileAppender介绍
按时间滚动TimeBasedRollingPolicy
demo如下:
D:/logs/test.%d{yyyy-MM-dd}.log
7
1GB
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
RollingFileAppender是非常常用的一种日志类型,表示滚动纪录文件,先将日志记录到指定文件,当符合某种条件时,将日志记录到其他文件,常用的子节点:
-
class来指定使用什么滚动策略,最常用是按时间滚动TimeBasedRollingPolicy,即负责滚动也负责触发滚动,有以下常用子节点:日志文件名+%d{}.log来命名,这边日期的格式默认为yyyy-MM-dd表示每天生成一个文件,即按天滚动yyyy-MM,表示每个月生成一个文件,即按月滚动logback就会删除最早创建的那一个日志文件。
以上就是关于RollingFileAppender的常用介绍,上面的demo的配置也基本满足了我们按照时间滚动TimeBasedRollingPolicy生成日志的要求,下面再介绍一种常用的滚动类型SizeAndTimeBasedRollingPolicy,即按照时间和大小来滚动。
按时间和大小滚动SizeAndTimeBasedRollingPolicy
demo如下:
D:/logs/test.%d{yyyy-MM-dd}.%i.log
100MB
7
1GB
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
仔细观察上边demo中的TimeBasedRollingPolicy中定义的.%i的字符,这个很关键,在SizeAndTimeBasedRollingPolicy中是必不可少的。
上边的demo中多了一个
日志过滤
级别介绍
在说级别过滤之前,先介绍一下日志的级别信息:
TRACEDEBUGINFOWARNERROR
上述级别从上到下由低到高,我们开发测试一般输出DEBUG级别的日志,生产环境配置只输出INFO级别甚至只输出ERROR级别的日志,这个根据情况而定,很灵活。
过滤节点
过滤器通常配置在Appender中,一个Appender可以配置一个或者多个过滤器,有多个过滤器时按照配置顺序依次执行,当然也可以不配置,其实大多数情况下我们都不需要配置,但是有的情况下又必须配置,所以这里也介绍下常用的也是笔者曾经使用过的两种过率机制:级别过滤器LevelFilter和临界值过滤器ThresholdFilter。
在此之前先说下
DENY:日志将被过滤掉,并且不经过下一个过滤器NEUTRAL:日志将会到下一个过滤器继续过滤ACCEPT:日志被立即处理,不再进入下一个过滤器
级别过滤器LevelFilter
过滤条件:只处理INFO级别的日志,格式如下:
INFO
ACCEPT
DENY
就如上边的demo中的配置一样,设置了级别为INFO,满足的日志返回ACCEPT即立即处理,不满足条件的日志则返回DENY即丢弃掉,这样经过这一个过滤器就只有INFO级别的日志会被打印出输出。
临界值过滤器ThresholdFilter
过滤条件:只处理INFO级别之上的日志,格式如下:
INFO
当日志级别等于或高于临界值时,过滤器返回NEUTRAL,当日志级别低于临界值时,返回DENY。
带过滤器的
下面给出一个带过滤器的
D:/logs/test.%d{yyyy-MM-dd}.%i.log
100MB
7
1GB
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
INFO
INFO
ACCEPT
DENY
上边的demo中,我们给按时间和大小滚动SizeAndTimeBasedRollingPolicy的滚动类型加上了过滤条件。
异步写入日志AsyncAppender
都知道,我们的日志语句是嵌入在程序内部,如果写入日志以及程序执行的处于一个串行的状态,那么日志的记录就必然会阻碍程序的执行,加长程序的响应时间,无疑是一种极为损耗效率的方式,所以实际的项目中我们的日志记录一般都用异步的方式来记录,这样就和主程序形成一种并行的状态,不会影响我们程序的运行,这也是我们性能调优需要注意的一个点。
AsyncAppender并不处理日志,只是将日志缓冲到一个BlockingQueue里面去,并在内部创建一个工作线程从队列头部获取日志,之后将获取的日志循环记录到附加的其他appender上去,从而达到不阻塞主线程的效果。因此AsynAppender仅仅充当事件转发器,必须引用另一个appender来写日志。
0
512
常用节点:
BlockingQueue还有20%容量,他将丢弃TRACE、DEBUG和INFO级别的日志,只保留WARN和ERROR级别的日志。为了保持所有的日志,设置该值为0。BlockingQueue的最大容量,默认情况下,大小为256。
上边花费了很长的篇幅介绍了
上文已经简单介绍了logback-spring.xml文件中,该节点到底扮演怎样的角色,以及他的运行原理,看下边的demo:
首先在这里给出项目结构:

下面定义两个
当存在多个name属性指定的包名来判断,包名级别越高则
上边我们定义了logger1和logger2,很明显看出logger1是logger2的父级,以本例给出多个
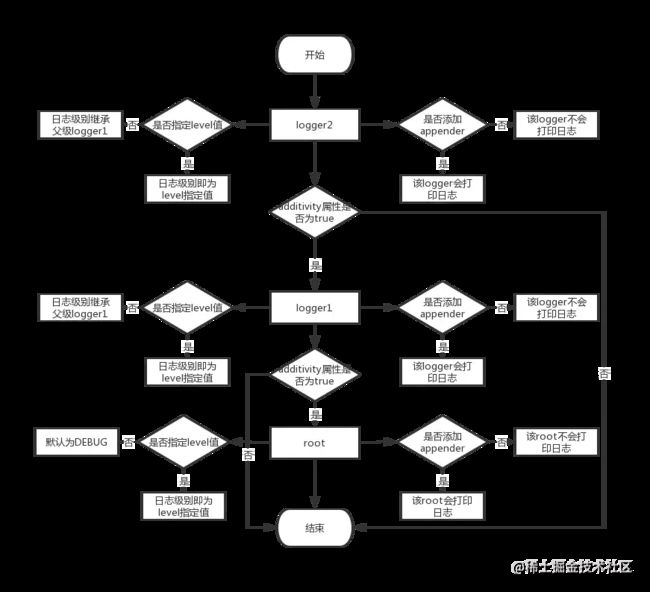
流程图看着一目了然,这里就不再赘述,只是在实际的项目中我们一般都不让
配置profile
profile即根据不同的环境使用不同的日志策略,这里举例开发和生产环境:
可以看到我们只需要在name属性的值,在配置文件里边配置好之后,怎么启用,这里介绍两种方式:
- 执行
jar包时添加参数:
java -jar xxx.jar --spring.profiles.active=prod
- 在项目的
application.properties配置文件中添加:
spring.profiles.active=prod
整合
最后将所有的模块整合在一起形成一个完整的配置文件:
[%contextName]%date [%thread %line] %level >> %msg >> %logger{10}%n
D:/test.log
true
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
D:/logs/test.%d{yyyy-MM-dd}.log
7
1GB
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
D:/logs/test.%d{yyyy-MM-dd}.%i.log
100MB
7
1GB
[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n
INFO
INFO
ACCEPT
DENY
0
512
代码中使用
终于到最后一步了,上边介绍了怎么配置logback-spring.xml配置文件,下面介绍怎么在项目中引入日志对象,以及怎么使用它输出日志,直接上代码:
package com.example.demo.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestLog {
private final static Logger log = LoggerFactory.getLogger(TestLog.class);
@RequestMapping(value="/log",method=RequestMethod.GET)
public void testLog() {
log.trace("trace级别的日志");
log.debug("debug级别日志");
log.info("info级别日志");
log.warn("warn级别的日志");
log.error("error级别日志");
}
}
在每一个需要使用日志对象的方法里边都要定义一次private final static Logger log = LoggerFactory.getLogger(xxx.class);其中xxx代指当前类名,如果觉得这样很麻烦,也可以通过@Slf4j注解的方式注入,但是这种方式需要添加pom依赖并且需要安装lombok插件,这里就不概述了,需要了解的朋友可以自己google。