SpringCloud gateway——Predicate,Filter,跨域,通过注册中心自动转发总结!
目录
1.1 SpringCloud Gateway 简介
1.2 SpringCloud Gateway 特征
1.3 SpringCloud Gateway和架构
1.3.1 SpringCloud Zuul的IO模型
1.3.2 Spring Cloud Gateway的处理流程
1.4 Spring Cloud Gateway路由配置方式
1.4.1 基础URI一种路由配置方式
1.4.2 基于代码的路由配置方式
1.4.3 和注册中心相结合的路由配置方式
1.5 详解:SpringCloud Gateway 匹配规则
1.5.1 Predicate 断言条件介绍
1.5.2 通过请求参数匹配
1.5.3 通过 Header 属性匹配
1.5.5 通过 Host 匹配
1.5.6 通过请求 ip 地址进行匹配
1.5.7 组合使用
1.6 GatewayFilter
1.6.1 AddRequestHeader 给请求头添加东西
1.6.2 AddRequestParameter给请求参数添加东西
1.7 Springcloud gateway 高级功能
1.6.1 实现熔断降级
1.6.2 分布式限流
1.7 网关配置跨域
1.7.1 通过配置:
1.7.2通过代码:
官网文档地址:https://docs.spring.io/spring-cloud-gateway/docs/3.0.0-SNAPSHOT/reference/html/#gatewayfilter-factories
1.1 SpringCloud Gateway 简介
SpringCloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
SpringCloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 2.0之前的非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
提前声明:Spring Cloud Gateway 底层使用了高性能的通信框架Netty。
1.2 SpringCloud Gateway 特征
SpringCloud官方,对SpringCloud Gateway 特征介绍如下:
(1)基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0
(2)集成 Hystrix 断路器
(3)集成 Spring Cloud DiscoveryClient
(4)Predicates 和 Filters 作用于特定路由,易于编写的 Predicates 和 Filters
(5)具备一些网关的高级功能:动态路由、限流、路径重写
从以上的特征来说,和Zuul的特征差别不大。SpringCloud Gateway和Zuul主要的区别,还是在底层的通信框架上。
简单说明一下上文中的三个术语:
(1)Filter(过滤器):
和Zuul的过滤器在概念上类似,可以使用它拦截和修改请求,并且对上游的响应,进行二次处理。过滤器为org.springframework.cloud.gateway.filter.GatewayFilter类的实例。
(2)Route(路由):
网关配置的基本组成模块,和Zuul的路由配置模块类似。一个Route模块由一个 ID,一个目标 URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配,目标URI会被访问。
(3)Predicate(断言):
这是一个 Java 8 的 Predicate,可以使用它来匹配来自 HTTP 请求的任何内容,例如 headers 或参数。断言的输入类型是一个 ServerWebExchange。
1.3 SpringCloud Gateway和架构
Spring在2017年下半年迎来了Webflux,Webflux的出现填补了Spring在响应式编程上的空白,Webflux的响应式编程不仅仅是编程风格的改变,而且对于一系列的著名框架,都提供了响应式访问的开发包,比如Netty、Redis等等。
SpringCloud Gateway 使用的Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架。
1.3.1 SpringCloud Zuul的IO模型
Springcloud中所集成的Zuul版本,采用的是Tomcat容器,使用的是传统的Servlet IO处理模型。
大家知道,servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init()进行初始化;container关闭时调用servlet destory()销毁servlet;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。
弊端:servlet是一个简单的网络IO模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的,但是一旦并发上升,线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单的业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势。

1.3.2 Spring Cloud Gateway的处理流程
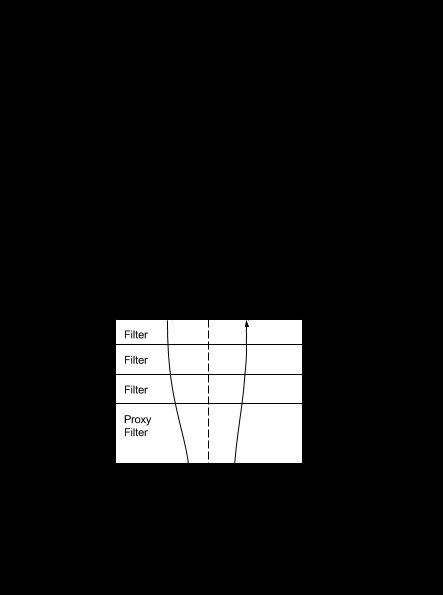
客户端向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
1.4 Spring Cloud Gateway路由配置方式
1.4.1 基础URI一种路由配置方式
如果请求的目标地址,是单个的URI资源路径,配置文件示例如下:
server:
port: 8080
spring:
application:
name: api-gateway
cloud:
gateway:
routes:
-id: url-proxy-1 (id:我们自定义的路由 ID,保持唯一)
uri: https://blog.csdn.net (uri:目标服务地址)
predicates:
-Path=/csdn
(predicates:路由条件,Predicate 接受一个输入参数,返回一个布尔值结果。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非))上面这段配置的意思是,配置了一个 id 为 url-proxy-1的URI代理规则,路由的规则为:当访问地http://localhost:8080/csdn/1.jsp时,会路由到上游地址https://blog.csdn.net/1.jsp。
1.4.2 基于代码的路由配置方式
转发功能同样可以通过代码来实现,我们可以在启动类 GateWayApplication 中添加方法 customRouteLocator() 来定制转发规则。
package com.springcloud.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("path_route", r -> r.path("/csdn")
.uri("https://blog.csdn.net"))
.build();
}
}1.4.3 和注册中心相结合的路由配置方式
在uri的schema协议部分为自定义的lb:类型,表示从微服务注册中心(如Eureka)订阅服务,并且进行服务的路由。一个典型的示例如下:
server:
port: 8084
spring:
cloud:
gateway:
routes:
-id: seckill-provider-route
uri: lb://seckill-provider
predicates:
- Path=/seckill-provider/**
-id: message-provider-route
uri: lb://message-provider
predicates:
-Path=/message-provider/**
application:
name: cloud-gateway
eureka:
instance:
prefer-ip-address: true
client:
service-url:
defaultZone: http://localhost:8888/eureka/
(这是一种很常用的方式,gataway默认也会根据微服务名匹配,转发到相应服务)
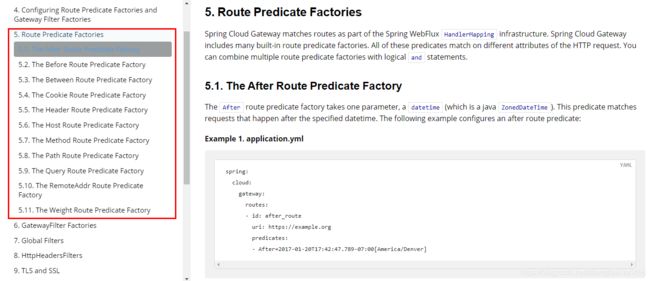
1.5 详解:SpringCloud Gateway 匹配规则
Spring Cloud Gateway 的功能很强大,我们仅仅通过 Predicates 的设计就可以看出来,前面我们只是使用了 predicates 进行了简单的条件匹配,其实 Spring Cloud Gataway 帮我们内置了很多 Predicates 功能。
Spring Cloud Gateway 是通过 Spring WebFlux 的 HandlerMapping 做为底层支持来匹配到转发路由,Spring Cloud Gateway 内置了很多 Predicates 工厂,这些 Predicates 工厂通过不同的 HTTP 请求参数来匹配,多个 Predicates 工厂可以组合使用。
官网给出示例:
1.5.1 Predicate 断言条件介绍
在 Spring Cloud Gateway 中 Spring 利用 Predicate 的特性实现了各种路由匹配规则,有通过 Header、请求参数等不同的条件来进行作为条件匹配到对应的路由。网上有一张图总结了 Spring Cloud 内置的几种 Predicate 的实现。

说白了 Predicate 就是为了实现一组匹配规则,方便让请求过来找到对应的 Route 进行处理,接下来我们接下 Spring Cloud GateWay 内置几种 Predicate 的使用
1.5.2 通过请求参数匹配
spring:
cloud:
gateway:
routes:
- id: query_route
uri: https://example.org
predicates:
- Query=red, gree.如果请求中包含red这个参数,并且这个参数的值可以和gree 正则匹配,则通过。如:green,greet都可以匹配。
curl localhost:8080?red=green (通过)
1.5.3 通过 Header 属性匹配
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://example.org
predicates:
- Header=X-Request-Id, \d+curl http://localhost:8080 -H "X-Request-Id:88"
则返回页面代码证明匹配成功。将参数-H "X-Request-Id:88"改为-H "X-Request-Id:spring"再次执行时返回404证明没有匹配。
1.5.4 通过 Cookie 匹配
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=chocolate, ch.pcurl http://localhost:8080 --cookie "chocolate=ch.p" 成功!
1.5.5 通过 Host 匹配
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Host=**.somehost.org,**.anotherhost.org如果请求头中有Host,并且其值为www.somehost.org 或者是 beta.somehost.org 或者 www.anotherhost.org都可通过。
1.5.6 通过请求 ip 地址进行匹配
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: https://example.org
predicates:
- RemoteAddr=192.168.1.1/24如果请求的远程地址是 192.168.1.10,则此路由将匹配。
1.5.7 组合使用
server:
port: 8080
spring:
application:
name: api-gateway
cloud:
gateway:
routes:
- id: gateway-service
uri: https://www.baidu.com
order: 0
predicates:
- Host=**.foo.org
- Path=/headers
- Method=GET
- Header=X-Request-Id, \d+
- Query=foo, ba.
- Query=baz
- Cookie=chocolate, ch.p
更多使用方法可以看官网!
1.6 GatewayFilter
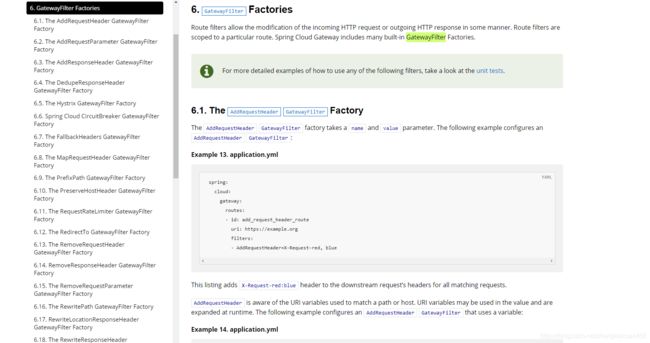
1.6.1 AddRequestHeader 给请求头添加东西
spring:
cloud:
gateway:
routes:
- id: add_request_header_route
uri: https://example.org
filters:
- AddRequestHeader=X-Request-red, blue该请求将X-Request-red:blue头添加到所有匹配请求的下游请求头中。
1.6.2 AddRequestParameter给请求参数添加东西
AddRequestParameter可以识别用于匹配路径或主机的URI变量。URI变量可以在值中使用,并在运行时展开。下面的示例配置了一个使用变量的AddRequestParameter GatewayFilter:
spring:
cloud:
gateway:
routes:
- id: add_request_parameter_route
uri: https://example.org
predicates:
- Host: {segment}.myhost.org
filters:
- AddRequestParameter=foo, bar-{segment}更多使用方法可以看官网!
1.7 Springcloud gateway 高级功能
1.6.1 实现熔断降级
为什么要实现熔断降级?
在分布式系统中,网关作为流量的入口,因此会有大量的请求进入网关,向其他服务发起调用,其他服务不可避免的会出现调用失败(超时、异常),失败时不能让请求堆积在网关上,需要快速失败并返回给客户端,想要实现这个要求,就必须在网关上做熔断、降级操作。
为什么在网关上请求失败需要快速返回给客户端?
因为当一个客户端请求发生故障的时候,这个请求会一直堆积在网关上,当然只有一个这种请求,网关肯定没有问题(如果一个请求就能造成整个系统瘫痪,那这个系统可以下架了),但是网关上堆积多了就会给网关乃至整个服务都造成巨大的压力,甚至整个服务宕掉。因此要对一些服务和页面进行有策略的降级,以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应,所以需要网关上请求失败需要快速返回给客户端。
spring:
cloud:
gateway:
routes:
- id: rateLimit_route
uri: http://localhost:8000
order: 0
predicates:
- Path=/test/**
filters:
- StripPrefix=1
- name: Hystrix
args:
name: fallbackCmdA
fallbackUri: forward:/fallbackA
hystrix.command.fallbackCmdA.execution.isolation.thread.timeoutInMilliseconds: 5000这里的配置,使用了两个过滤器:
(1)过滤器StripPrefix,作用是去掉请求路径的最前面n个部分截取掉。
StripPrefix=1就代表截取路径的个数为1,比如前端过来请求/test/good/1/view,匹配成功后,路由到后端的请求路径就会变成http://localhost:8888/good/1/view。
(2)过滤器Hystrix,作用是通过Hystrix进行熔断降级
当上游的请求,进入了Hystrix熔断降级机制时,就会调用fallbackUri配置的降级地址。需要注意的是,还需要单独设置Hystrix的commandKey的超时时间
fallbackUri配置的降级地址的代码如下:
package org.gateway.controller;
import org.gateway.response.Response;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class FallbackController {
@GetMapping("/fallbackA")
public Response fallbackA() {
Response response = new Response();
response.setCode("100");
response.setMessage("服务暂时不可用");
return response;
}
}
1.6.2 分布式限流
在Spring Cloud Gateway中,有Filter过滤器,因此可以在“pre”类型的Filter中自行实现上述三种过滤器。但是限流作为网关最基本的功能,Spring Cloud Gateway官方就提供了RequestRateLimiterGatewayFilterFactory这个类,适用在Redis内的通过执行Lua脚本实现了令牌桶的方式。具体实现逻辑在RequestRateLimiterGatewayFilterFactory类中。
首先在工程的pom文件中引入gateway的起步依赖和redis的依赖,代码如下:
server:
port: 8081
spring:
cloud:
gateway:
routes:
- id: limit_route
uri: http://httpbin.org:80/get
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]
filters:
- name: RequestRateLimiter
args:
key-resolver: '#{@userKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 3
application:
name: cloud-gateway
redis:
host: localhost
port: 6379
database: 0
在上面的配置文件,指定程序的端口为8081,配置了 redis的信息,并配置了RequestRateLimiter的限流过滤器,该过滤器需要配置三个参数:
-
burstCapacity,令牌桶总容量。
-
replenishRate,令牌桶每秒填充平均速率。
-
key-resolver,用于限流的键的解析器的 Bean 对象的名字。它使用 SpEL 表达式根据#{@beanName}从 Spring 容器中获取 Bean 对象。
这里根据用户ID限流,请求路径中必须携带userId参数
@Bean
KeyResolver userKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getQueryParams().getFirst("user"));
}
KeyResolver需要实现resolve方法,比如根据userid进行限流,则需要用userid去判断。实现完KeyResolver之后,需要将这个类的Bean注册到Ioc容器中。
如果需要根据IP限流,定义的获取限流Key的bean为:
@Bean
public KeyResolver ipKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getRemoteAddress().getHostName());
}- 加入 spring-boot-starter-data-redis-reactive 依赖:结合 Redis 限流
- 加入 spring-cloud-starter-netflix-hystrix 依赖:熔断器
1.7 网关配置跨域
1.7.1 通过配置:
spring:
cloud:
gateway:
discovery:
locator:
enabled: true
lowerCaseServiceId: true
# 跨域
globalcors:
corsConfigurations:
'[/**]':
allowedHeaders: "*"
allowedOrigins: "*"
allowedMethods:
- GET
- POST
- DELETE
- PUT
- OPTION
1.7.2通过代码:
@Bean
public CorsWebFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
// cookie跨域
config.setAllowCredentials(Boolean.TRUE);
config.addAllowedMethod("*");
config.addAllowedOrigin("*");
config.addAllowedHeader("*");
// 配置前端js允许访问的自定义响应头
config.addExposedHeader("setToken");
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(new PathPatternParser());
source.registerCorsConfiguration("/**", config);
return new CorsWebFilter(source);
}----------------------------------------------------------------2020-12-18新增--------------------------------------------------------------------------------------------
网关通过注册中心转发应该怎么做?
1.网关通过注册中心转发应该怎么做?
步骤一:加入eureka-client依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
——》保存,然后点击Import Changes
步骤二:在启动类GatewayApplication 上加
@EnableEurekaClient注解
@SpringBootApplication
@EnableEurekaClient
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
步骤三:配置application.yml
因为是Eureka Client
所以必须在配置文件中指定Eureka Server的默认网址
eureka:
client:
serviceUrl:
defaultZone: http://adbycool:123456@localhost:8001/eureka
通过注册中心会用到discovery
discovery下的locator默认是false,所以手动指定为true
discovery其实是服务注册的发现组件,通过discovery发现注册的服务的name来找到注册中心的服务
spring:
application:
name: gateway
cloud:
gateway:
discovery:
locator:
enabled: true
记得要先启动Eureka Server
再启动buildingservice
打开可以看到,注册中心的buildingservice的名字是全部大写字母的BUILDINGSERVICE
2.如果想通过小写字母来寻找注册在注册中心的服务,应该怎么做?
可以在application.yml中配置:
lower-case-service-id: true
spring:
application:
name: gateway
cloud:
gateway:
discovery:
locator:
enabled: true
lower-case-service-id: true
3.通常框架中,用户发出请求是通过网关来访问分发到某些应用服务比如buildingconsumer?
所以最终访问的url是:
localhost:9001/buildingconsumer/building/message
文章参考:https://www.cnblogs.com/crazymakercircle/p/11704077.html
欢迎关注我的公众号,一起学习!

关注「Java源码进阶」,获取海量java,大数据,机器学习资料!