dubbo接口自动化用例性能优化
前言
去年换了一个新部门,看了下当前的自动化用例的情况,发现存在三类性能问题:
- 本地调试运行时等待时间较长,就算是一个简单的case,执行时间都需要1分钟以上
- 单用例执行时间比较长,部分用例执行时间超过2分钟
- 集成到CI中运行时,执行时间较长
对于上述三个问题花时间进行了一定程度的优化,总结如下
优化本地调试时间
通过调试可以发现,一个需要执行660ms的case,在执行前的初始化工作就需要消耗约1分半钟,那么就需要思考下能否减少这部分初始化时间了。
公司用的自动化框架是基于AbstractTestNGSpringContextTests的框架。AbstractTestNGSpringContextTests是一个spring集成testNg的工具,可以通过ApplicationContext加载bean。ApplicationContext实现的默认行为就是在启动服务器时将所有bean提前进行实例化。提前实例化意味着作为初始化过程的一部分,applicationContext实例会创建并配置所有的bean。
如果是作为一个spring服务,在启动时将bean提前进行实例化,然后可以处理所有的请求,这样的做法是很合理的。但是作为本地调试,更关注是自己case运行时所需要的bean是否实例化,而不需要将所有bean进行实例化。
查阅了下spring相关文档,发现可以引入lazy-init来告诉ApplicationContext按需加载bean。
配置方式有两种:
default-lazy-init参数,其配置形式如下:
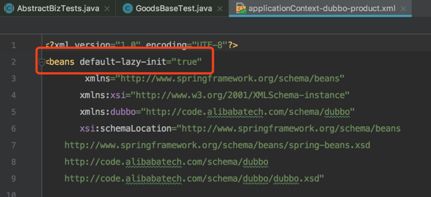
lazy-init参数,其配置形式如下:
配置完成后,运行了一下,发现并没有速度上的提升,原因是之前编写时将大部分的bean的初始化放在了测试用例里的基类里面,导致启动时认为这些bean都需要初始化。

这说明要让lazy-init生效,提高单用例的启动速度,那就要尽可能少的使用不需要的bean,需要做一定改造:
- 将service/DAO初始化挪到测试用例里面。
- 去除不需要的多余的service/DAO。
按照上面的思路对用例进行了优化,可以将用例的初始化时间精简到30秒左右。

单用例执行时间的优化
为什么会出现很多的用例执行时间超过2分钟呢?做了一些分析和调试后,主要有几个原因:
- 业务决定了服务之间很多是通过消息的方式进行传递,存在异步调用,所以需要等待再进行后续执行,为了用例的稳定性往往设置了过大的sleep time。
- 一些数据准备和初始化操作不合理,无谓的耗时。
下面来看几个案例
在beforeclass里面都会有一段初始化数据的操作,先调接口查询数据是否存在,不存在则进行初始化,导致每运行一个测试用例类都需要做一次对应操作。

实际上这些数据初始化完后可以一直被使用,不需要多次检查,可以优化的地方是用个静态变量判断数据已初始化的话就不检查,或者将该操作设置为跑一次用例集只运行一次。
大量使用了sleep做等待,如果操作需要等待1s左右才生效,那么用sleep往往需要sleep2秒,所以sleep一般会造成50%左右的性能浪费。
引入异步校验工具Awaitility对原有代码进行改写。
Awaitility的基本的语法为:
- pollInterval:执行间隔
- pollDelay:等待多久开始执行
- atMoast:执行的超时时间
- until()-> 执行其中的语句直到返回true或超时

这样的写法比较优雅简介,如果判断执行完成可以提前结束等待,避免时间浪费。
提高并发
当优化了单用例的运行时间后,虽然对总体自动化集成测试的运行速度有一定帮助,但当用例越来越多的时候,时间也会变得无法忍受,能想到的一个办法是增加用例的并发。
用例能够并发执行的前提是用例之间具有隔离性,一个用例的执行不会影响另一个用例的执行,比如我在店铺A下单和在店铺B下单这两个用例就不会有干扰,又比如我在店铺A创建商品和我在店铺A下单也不会有影响。
所以考虑用例并发的时候,需要先针对自己的业务特性进行一定程度的分组隔离。
在我们的案例中,考虑对店铺进行分组,用例并发用到的并发基本机制是testNG parallel="tests"/"class" thread-count=“N"。
在实际执行中,分组的实施也会有两种模式,按case的纬度还是按照类的纬度:
1.使用店铺id分组进行并发,使用group=店铺id 维度
优点:任意维度扩展
缺点:每个case需要加@group
2.把不同测试类按店铺id分组,使用package/class维度
优点:改动简单
缺点:需要每个测试类只使用一个店铺id,缺乏扩展性,需要频繁改动配置文件
最后选择了按case纬度,因为现存的用例并未很好的按店铺id进行组织,比较散乱,使用类的纬度改动较大。

使用了两个并发以后,性能提升明显,时间从547s->270s。

最后
解决了一部分性能问题后,尤其是提高了用例并发以后,对用例稳定性也更高了。
和开发写代码需要考虑异常和容错处理一样,测试人员在自动化设计、实施等各阶段都需要考虑用例的稳定性问题:
- 减少外部依赖。如果执行过程需要依赖其他系统的接口,那么其他系统发生了变更或故障就会影响自身用例的进行。可以考虑通过预先生成的数据来替代调用外部接口生成数据在用例中使用。第三方接口的调用可以考虑mock 。
- 预置数据代替创建过程。由于操作越多稳定性越低,使用预置数据而不是实时生成它,速度更快,稳定性更高。
- 使用不同维度进行隔离。通过隔离,用例执行失败的脏数据就不会影响其他用例。
- 调优:超时、等待时间。线上超时时间设置的比较短,测试环境的机器配置不如线上,需要适时调大超时和等待时间来保证接口调用不会超时。
- 防御式编程。编写测试代码时不能假设数据已存在或者没有脏数据残留,所以预先的判断和清理很重要,比如检查到数据缺失就实时修复、用例运行之前考虑清除临时数据等。
- 定位并解决不稳定的问题。有时候偶现用例失败,可以考虑给被测应用增加日志,同时持续多次运行用例多次(如 testNg 里增加threadPoolSize=1, invocationCount=50)来复现问题,最终解决问题。
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取
