多线程(生产者和消费者模型)
生产者和消费者模型
基于阻塞队列实现cp模型
引言
在上一节,我们了解了有关线程同步的知识
所谓的线程同步,是解决死锁问题的其中一种方法
在安全的规则下,多线程按照一定顺序的访问资源,进行协同工作,我们称之为线程同步
基于互斥和同步的概念,我们可以提出不同的模型
今天要介绍的就是生产者和消费者模型
并且我们基于BlockQueue(阻塞队列)来尝试实现它
回归生活
生产者和消费者模型,这个名字我们一听,可能会觉得非常高大上
但是实际上,在生活中我们处处可见
建立在这模型之上,最常见的例子,就是我们的超市

供应商(生产者)生产我们的商品,将其运往我们的超市
顾客(消费者)从超市中购买自己需要的商品
但是我们是否想过,为什么生活中需要存在超市呢?
顾客可以直接去对应的供应商买相应的商品不就行了吗?这样价格反而会更加便宜
原因主要有两个
第一,无论供应商做什么,它的最终目的都是赚钱,以利益作为一切的根本,损害利益的事情,商人是不会做的
谈到利益,成本往往是无法躲开的一个话题,供应商每次生产产品,可能就要开动数台机器,而这些都是需要耗费成本的
但是顾客的需求是零散的,供应商是不可能为了你一个顾客要买一包零食,整个工厂哗哗的运行起来
而超市作为交易场所,则能够充当一定缓冲的作用(缓存)
供应商只管生产商品,而不再需要考虑顾客需求零散的问题,更进一步来说,超市还能够根据食品的销量,反馈给供应商,使其调整对应产品的生产
第二,我们在超市中所买的食物等等,看一下保质期,其实大多都不是当天生产出来,然后运往到我们的超市里
也就是说,超市的存在,允许生产消费的步调可以不一致,达到某种解耦合的作用
假如我们把超市对应于我们的的缓冲区,一种数据结构,它可以是队列,也可以是栈等等
把消费者和生产者对应于我们的线程
把商品对应于我们的“数据”
这就是我们的消费者和生产者模型
进一步探讨
但是,在我们上面生活的小例子中,其实蕴含了一个大前提
超市,是需要被顾客和供应商同时看到的
换句话说,假如顾客不知道这个超市的存在,从来没在这买过商品;或者说超市联系不上对应的供应商,没有对应的商品销售
就根本谈不上算我们的消费者和生产者模型
同理:交易场所必须先被所有线程所看到!
说起这句话,其实我们很熟悉,因为我们之前所了解过的管道,其实就是这个模型的一个实例
而既然,交易场所,会被所有线程所看到
这就注定了,交易场所一定是一个会被多线程并发访问的公共资源!
也就注定了,在这种模型下,我们要维护线程互斥与同步的关系
如何进行维护呢?
想要谈如何进行维护,不如先问,我们需要维护什么?
是维护不同线程吗?
答案是维护不同线程之间的关系!互斥与同步是线程与线程之间的关系
在生产模型中,一共有三种关系
第一,生产者和生产者
第二,生产者和消费者
第三,消费者和消费者
我们先来看第一种,生产者和生产者之间是什么关系呢?
答案是互斥,超市的空间资源是有限的,不同供应商肯定都希望自己的商品尽可能占据更多更优的位置,两者之间是互相竞争的
再来看第二种,生产者和消费者之间又是什么关系呢?
当供应商没有运送商品到超市的时候,消费者能够进行消费吗?
或者说,一个超市没有顾客来,供应商还会不断生产商品运往该超市吗?
因此,无论是作为生产者线程,或者是消费者线程,都不可能频繁访问超市中的资源,必须按照一定顺序,供应商生产后,消费者进行消费
因此两者是同步(互相协同)的关系
最后是第三种,消费者和消费者之间又是什么关系呢?
举个极端点的例子,超市只剩下最后一包薯片,你和另外一个人,同时都想吃薯片,此时两人可能就会进行竞争,看谁更快拿到薯片
因此两者是互斥的关系
总结
所以,如何实现生产者和消费者模型呢?
本质就是用代码来实现,我们所说的321原则
3:三种关系
2:消费者和生产者
1:1个交易场所,通常是缓冲区
代码实现
成员变量
说了这么多,没有代码实现,都是纸上谈兵
首先着手实现我们的阻塞队列
第一步,思考类中包含的私有成员有什么?
queue队列肯定不能少
由于queue队列是公共的资源,所有线程都能看到
因此,一把公共锁(互斥量)也是必不可少的
同样的,我们前面提到过消费者和生产者之间的关系是同步,所以我们还需要条件变量作为我们的成员变量
并且由于同时存在消费者和生产者,所以我们需要两个条件变量,也就是有两个不同的队列,维护等待关系
最后为了实现方法的方便,我们还补充一个_cap,用来记录队列能够存储多少元素

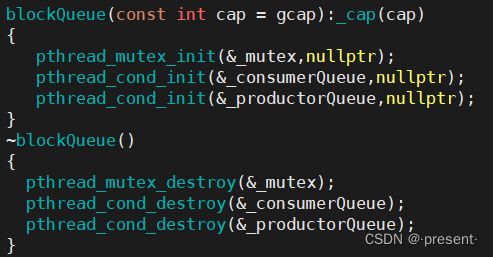
构造与析构
构造函数就没有什么要说的,初始化时,用户只需要传入队列的容量即可
然后在构造和析构中,前者我们需要初始化锁,条件变量
后者我们需要销毁锁,条件变量
pop,push
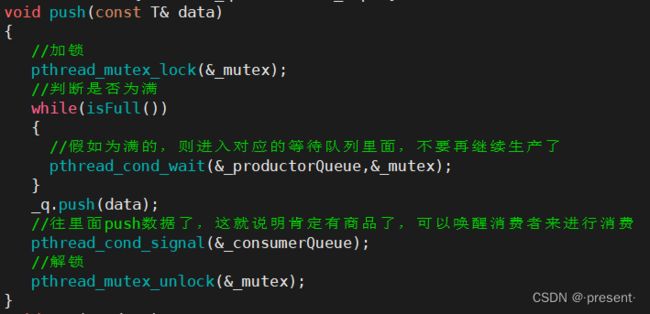
push相应元素进队列(入列)
必定需要先检查队列是否为满,假如队列已经满了,是无法进行入列这个操作的
因此,为了使代码更为清晰,我们可以先在类内部实现isFull方法,用来判断队列是否为满
![]()
push之前,先进行加锁操作,保证不会出现多线程访问临界资源,而导致并发问题出现
假如队列满了,那该线程就要条件变量进行等待
还有两点需要注意!
第一.所谓的等待,本质来说就是线程切换
也就意味着,当线程被重新唤醒的时候,注定了会从临界区内部继续向后执行,因为线程是在临界区被切走的
但是在条件变量等待时,锁已经被释放了,后续甚至还有解锁的操作
因此,被重新唤醒时,该线程还需要重新申请锁,申请成功后,才会彻底返回
第二.当执行完往队列里面放元素的操作后,此时队列一定不为空
因此,我们要及时唤醒消费者过来消费 这个操作放到解锁之前或者解锁后,没有差别.
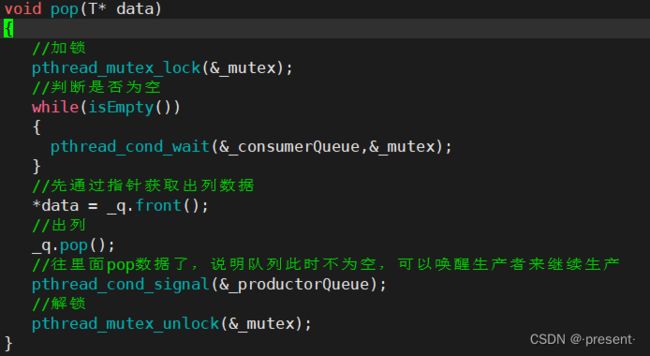
实现完push操作,pop操作也是类似的
当然,push的时候,由于入队列的数据并不会被修改,因此直接传引入作为参数即可
但是pop操作需要获取出列的元素,所以应该传相应的指针进来
同样的,当队列为空时,是无法进行出列操作的
因此,我们还是先实现isEmpty函数,用来判断队列是否为空
![]()
整体代码展示
1 #pragma once
2 #include <iostream>
3 #include <pthread.h>
4 #include <queue>
5
6 const int gcap = 5;
7 template <class T>
8 class blockQueue
9 {
10 public:
11 blockQueue(const int cap = gcap):_cap(cap)
12 {
13 pthread_mutex_init(&_mutex,nullptr);
14 pthread_cond_init(&_consumerQueue,nullptr);
15 pthread_cond_init(&_productorQueue,nullptr);
16 }
17 ~blockQueue()
18 {
19 pthread_mutex_destroy(&_mutex);
20 pthread_cond_destroy(&_consumerQueue);
21 pthread_cond_destroy(&_productorQueue);
22 }
23 //判断队列是否为空
24 bool isEmpty() { return _q.empty(); }
25 //判断队列是否为满
26 bool isFull() { return _q.size() == _cap; }
27 void push(const T& data)
28 {
29 //加锁
30 pthread_mutex_lock(&_mutex);
31 //判断是否为满
32 while(isFull())
33 {
34 //假如为满的,则进入对应的等待队列里面,不要再继续生产了
35 pthread_cond_wait(&_productorQueue,&_mutex);
36 }
37 _q.push(data);
38 //往里面push数据了,这就说明肯定有商品了,可以唤醒消费者来进行消费
39 pthread_cond_signal(&_consumerQueue);
40 //解锁
41 pthread_mutex_unlock(&_mutex);
42 }
43 void pop(T* data)
44 {
45 //加锁
46 pthread_mutex_lock(&_mutex);
47 //判断是否为空
48 while(isEmpty())
49 {
50 pthread_cond_wait(&_consumerQueue,&_mutex);
51 }
52 //先通过指针获取出列数据
53 *data = _q.front();
54 //出列
55 _q.pop();
56 //往里面pop数据了,说明队列此时不为空,可以唤醒生产者来继续生产
57 pthread_cond_signal(&_productorQueue);
58 //解锁
59 pthread_mutex_unlock(&_mutex);
60 }
61 private:
62 std::queue<T> _q; //队列
63 int _cap; //容量
64 pthread_mutex_t _mutex; //锁
65 pthread_cond_t _consumerQueue; //消费者条件变量
66 pthread_cond_t _productorQueue; //生产者条件变量
67 };
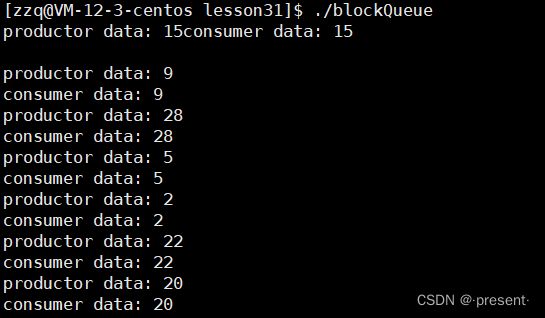
结果展示
主函数构建两个线程,一个往队列存数据,另外一个往队列取数据,一直循环进行
1 #include "blockQueue.hpp"
2 #include <iostream>
3 #include <unistd.h>
4 #include <pthread.h>
5 #include <ctime>
6
7 using namespace std;
8 void* consumer(void* args)
9 {
10 blockQueue<int>* bq = static_cast<blockQueue<int>*>(args);
11 //一直往里面取数据
12 while(true)
13 {
14 int data;
15 bq->pop(&data);
16 cout << "consumer data: " << data << endl;
17 }
18 }
19 void* productor(void* args)
20 {
21 blockQueue<int>* bq = static_cast<blockQueue<int>*>(args);
22 while(true)
23 {
24 sleep(1);
25 int data = rand()%30 + 1;
26 bq->push(data);
27 cout << "productor data: " << data << endl;
28 }
29 }
30 int main()
31 {
32 srand((uint64_t)time(nullptr) ^ getpid());
33 blockQueue<int>* bq = new blockQueue<int>();
34 pthread_t c,p; //创建两个线程
35 pthread_create(&c,nullptr,consumer,(void*)bq);
36 pthread_create(&p,nullptr,productor,(void*)bq);
37
38 pthread_join(c,nullptr);
39 pthread_join(p,nullptr);
40
41 return 0;
42 }
从结果也可以看出,存取数据的快慢,取决于生产者和消费者之间较慢的那一个,假如我们让消费者先sleep1秒,则生产者在迅速产生出5个随机数,放入队列后,就会被阻塞
细节剖析
细节1
为什么采用while,而不是采用if?
1.1 pthread_cond_wait函数是让当前执行流进行等待的函数,是函数就意味着有可能调用失败,调用失败后该执行流就会继续往后执行。
1.2 其次,我们现在只是单生产者单消费者,假如是多生产者多消费者,情况又将不一样,举一个极端例子,假如队列此时为空,则多个消费者线程都会进入条件变量中等待,如果此时有一个生产者,生产了一个数据,然后将全部消费者唤醒,此时其中一个消费者就会立马出列,而队列又会陷入空的情况,此时其它消费者线程就会陷入伪等待的状态,队列里面为空,但还是要执行出列操作,因此程序就会崩溃
所以,为了保证在任何时候,都要符合条件,才进行生产,我们将if修改为while
细节2
如何理解高效呢?
理解这个问题的关键,在于正确认识生产和消费
假如单纯取数据,读数据,是没有任何高效可言的,反而因为加锁的缘故,由原来的并发执行转为串行执行,使效率降低
但是高效率针对的是获取数据的过程和数据处理的部分!
我们拿到数据后,还需要对数据进行处理,那其它消费者线程依旧是并行执行的,它们依旧可以继续处理数据,彼此间互不干扰
同理,获取数据也是如此,有生产者线程往队列里面存数据,并不影响其它生产者线程继续获取数据
这就是我们前面提到的缓存
同样,消费者线程不需要等待生产者线程什么时候往队列里面存数据,彼此之间互不干扰,生产与消费独立开来
这就是我们前面提到的解耦
细节3
不要认为队列里面只能放数据
还可以放对象!这些对象可以是一个个的任务,分发给多消费者进行执行
我们可以对代码进行简单的修改实现上面的说法
实现一个Task类,里面就包含各种运算符实现的操作
入队列时,传入一个Task类的实例对象
出队列时,调用对象里面的方法,进行计算,返回相应的结果
1 #pragma once
2 #include <iostream>
3 #include <string>
4
5 class Task
6 {
7 public:
8 //无参构造
9 Task()
10 {}
11 Task(int x,int y,char op):_x(x),_y(y),_op(op),_result(0),_exitflag(0)
12 {}
13 ~Task()
14 {}
15 void operator()()
16 {
17 switch(_op)
18 {
19 case '+':
20 {
21 _result = _x + _y;
22 break;
23 }
24 case '-':
25 {
26 _result = _x - _y;
27 break;
28 }
29 case '*':
30 {
31 _result = _x * _y;
32 break;
33 }
34 case '/':
35 {
36 if(_y == 0)
37 _exitflag = -1;
38 else
39 _result = _x / _y;
40 break;
41 }
42 case '%':
43 {
44 if (_y == 0)
45 _exitflag = -2;
46 else
47 _result = _x % _y;
48 break;
49 }
50 default:
51 break;
52 }
53 }
54 std::string formatArgs()
55 {
56 return std::to_string(_x) + _op + std::to_string(_y) + "=";
57 }
58 std::string formatRes()
59 {
60 return std::to_string(_result) + "(" + std::to_string(_exitflag) + ")";
61 }
62 private:
63 int _x;
64 int _y;
65
66 char _op; //运算符
67 int _result; //运算的结果
68 int _exitflag; //退出成功与否
69 };
修改后的主函数代码
1 #include "blockQueue.hpp"
2 #include "Task.hpp"
3 #include <iostream>
4 #include <unistd.h>
5 #include <pthread.h>
6 #include <ctime>
7
8 using namespace std;
9 void* consumer(void* args)
10 {
11 blockQueue<Task>* bq = static_cast<blockQueue<Task>*>(args);
12 //一直往里面取数据
13 while(true)
14 {
15 Task t;
16 bq->pop(&t);
17
18 t();
19 cout << "consumer task: " << t.formatArgs() << t.formatRes() << endl;
20 }
21 }
22 void* productor(void* args)
23 {
24 sleep(1);
25 blockQueue<Task>* bq = static_cast<blockQueue<Task>*>(args);
26 std::string opers = "+-*/%";
27 while(true)
28 {
29 int x = rand()%30 + 1;
30 int y = rand()%20 + 1;
31 char op = opers[rand()%(opers.size())];
32
33 //创建任务
34 Task t(x,y,op);
35 bq->push(t);
36 cout << "productor task: " << t.formatArgs() << "?" << endl;
37 }
38 }
39 int main()
40 {
41 srand((uint64_t)time(nullptr) ^ getpid());
42 blockQueue<int>* bq = new blockQueue<int>();
43 pthread_t c1,c2,p1,p2; //创建多个线程
44 pthread_create(&c1,nullptr,consumer,(void*)bq);
45 pthread_create(&c2,nullptr,consumer,(void*)bq);
46
47 pthread_create(&p1,nullptr,productor,(void*)bq);
48 pthread_create(&p2,nullptr,productor,(void*)bq);
49 //pthread_create(&p3,nullptr,productor,(void*)bq);
50
51 pthread_join(c1,nullptr);
52 pthread_join(c2,nullptr);
53 pthread_join(p1,nullptr);
54 pthread_join(p2,nullptr);
55 //pthread_join(p3,nullptr);
56 delete bq;
57 return 0;
58 }
细节4
为什么我们这份代码,只用一把锁呢?
根本原因在于我们生产和消费的是同一个队列Queue,并且Queue被当作整体进行使用
该阻塞队列是共同的临界资源,一个临界资源,防止出现并发问题,必须遵守同样的规则,也就是共用同一把锁
基于循环队列实现cp模型
信号量
引言
平时看电影之前,我们都需要买票
买票的本质是什么呢?
1.对座位资源的预定机制
2.确保不会因为多放出去特定的座位资源,而导致资源不足的情况
假如你买了票,那这个座位,就是你的!即便你临时有事,没有去看电影,那这个座位在这个时段的所有权依旧归你所有
同时,你能够买票成功,也就意味着这份资源是存在的,并不会存在没有座位,但电影院仍然卖票给你的情况
信号量,就和我们的电影票类似,它的本质是一个计数器
通过对资源的预定,从而实现线程同步协作,解决我们的死锁问题
那什么叫做对资源的预定呢?
其实就是对计数器进行pv操作(加减操作)
其中p和–相等,v和++相等,两个的操作都是原子性的!
和我们之前编写阻塞队列,从而实现cp模型不同,现在我们不把队列看作一个整体进行操作(之前需要把队列看作一个整体,进行判空,判满的操作)
现在我们把队列看作一个个小的资源组合体

每一个线程,在访问对应资源的时候,先申请信号量,申请成功,则表示该线程允许使用该资源;申请失败,则意味着资源不足!
就和我们买电影票一样,一旦电影票买到手了,这个座位也就被提前预定归属于我,任何人都无法抢走;假如没买到,就意味着你想买的座位已经属于别人了!
这样做的一个直接好处是
我们之前提到过,在临界区前加锁后,我们需要判断资源,如果该资源不存在,就进入对应的条件变量进行等待,来实现我们的线程同步
但是现在我们可以把判断转化成为对信号量的申请,而不再需要在临界区中进行判断,只要信号量不为0,则表示资源可用,表示线程可以访问
可以在申请锁之前,申请对应信号量,以此实现线程同步的功能
认识接口
信号量的接口都非常简单明了
sem_init()
通过该接口,我们可以实现对一个信号量的初始化,其中pshread我们经常设为0,初始值我们按照具体需求进行指定

sem_destroy()
通过该接口,我们可以将一个信号量进行销毁,和指针类似,申请使用完后,记得及时销毁
sem_wait()
通过该接口,我们可以实现P操作,即对信号量进行-1操作
sem_post()
通过该接口,我们可以实现V操作,即对信号量进行+1操作

代码实现
思考的问题
与之前阻塞队列不同,现在我们采取的循环队列容器,会被肢解为一个个小的资源,然后供不同的线程进行预定
但是生产者和消费者锁关注的资源是相同的吗?
答案是不一样
对于生产者来说,它关注的应该是队列是否还有空间剩余,假如空间满了,它继续生产也没有任何意义
而对于消费者来说,它关注的则是数据,假如没有数据可以从队列中取出,则消费者不可能继续进行消费
因此,从我们上述的说法中也可以看出
只要消费者和生产者访问不同的区域,生产和消费行为是可以同步进行的!
因为两者想要的东西并不相同
生产者只管生产,消费者只管消费即可,你放我拿,这就是我们前面所说的解耦
但是假如访问相同的区域呢?此时就意味着队列已经为满或者为空
队列为满,意味空间资源耗尽,则必须让消费者先进行消费,带来新的空间资源
队列为空,意味数据资源耗尽,则必须让生产者先进行生产,带来新的数据资源
因此,我们在设计信号量的时候,必须存在两个信号量
一个是数据信号量sem_data,另一个是空间信号量sem_room
当消费者对数据信号量进行p操作时,同时要对空间信号量进行v操作
当生产者对空间信号量进行p操作时,同时要对数据信号量进行v操作
保持申请自己的资源,互相v对方的资源的原则
当队列为空的时候,消费者线程是不可能会运行的,因为无法申请到数据信号量,必须要生产者先生产后,对数据信号量进行v操作,消费者线程才会运行
同理,队列为满的时候,生产者线程是不可能会运行的,因为无法申请到空间信号量,必须要消费者先消费后,对空间信号量进行v操作,生产者线程才会运行
成员变量
同样,没有代码实现,都是纸上谈兵
我们开始着手实现我们的循环队列
第一步依旧是思考类中包含的私有成员有什么?
循环队列ring肯定不能少,这里我们采用经典的实现方法,也就是ring实际上是一个vector
想要实现循环队列,头指针front和尾指针rear也是必不可少的,当然,两个指针还有另外一个作用,就是告诉对应的线程访问队列中的哪一部分资源,从而真正实现我们把循环队列拆分成一个个小资源的说法
然后是我们之前提到过的两个信号量,用来维护我们生产者和消费者之间的同步关系
但是,这样就够了吗?
答案肯定是不行!生产者和生产者,消费者和消费者的互斥关系,我们还没有进行维护
也就是锁肯定也是必须的!
要几把呢?
之前由于我们把队列看作一个整体进行操作,访问的是同一个临界资源,因此,只需要一把锁就足够
但是现在关注的临界资源数可不止一个,有两个,分别是数据和空间
因此我们需要两把锁,来维护互斥关系
当一个消费者线程取数据的时候,其它消费者线程不要也一起取数据;同理,当一个生产者线程存数据的时候,其它生产者线程不要也一起存数据,这都会导致并发问题的出现
可以看见,代码的实现,本质还是维护我们三个线程关系
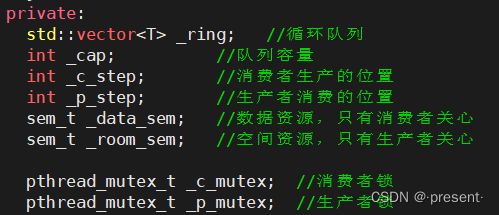
构造析构
由于有两把锁,两个信号量
所以分别要调用相应的接口进行初始化
同样的,我们规定刚开始生产的时候,消费者和生产者的位置下标都从0开始
为了使代码看上去更为简便,我们可以稍微对原来的接口函数进行封装

设定队列初始容量为5
![]()
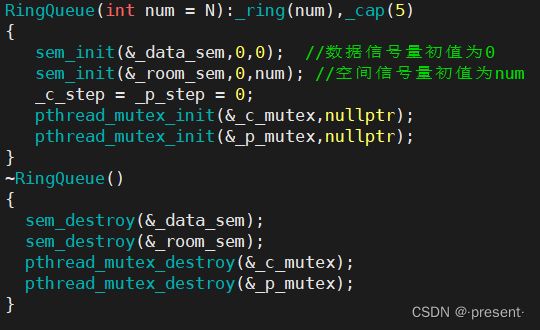
pop,push
思路:
申请资源----加锁----pop,push操作-----解锁-----给对方资源加1的思路即可完成push,pop的代码

整体代码展示
1 #pragma once
2
3 #include <iostream>
4 #include <pthread.h>
5 #include <semaphore.h>
6 #include <vector>
7
8 static const int N = 5;
9 template <class T>
10 class RingQueue
11 {
12 public:
13 void P(sem_t&m)
14 {
15 sem_wait(&m);
16 }
17 void V(sem_t&m)
18 {
19 sem_post(&m);
20 }
21 void Lock(pthread_mutex_t& l)
22 {
23 pthread_mutex_lock(&l);
24 }
25 void Unlock(pthread_mutex_t& l)
26 {
27 pthread_mutex_unlock(&l);
28 }
29 public:
30 RingQueue(int num = N):_ring(num),_cap(5)
31 {
32 sem_init(&_data_sem,0,0); //数据信号量初值为0
33 sem_init(&_room_sem,0,num); //空间信号量初值为num
34 _c_step = _p_step = 0;
35 pthread_mutex_init(&_c_mutex,nullptr);
36 pthread_mutex_init(&_p_mutex,nullptr);
37 }
38 ~RingQueue()
39 {
40 sem_destroy(&_data_sem);
41 sem_destroy(&_room_sem);
42 pthread_mutex_destroy(&_c_mutex);
43 pthread_mutex_destroy(&_p_mutex);
44 }
45
46 //生产
47 void push(const T&in)
48 {
49 P(_room_sem); //申请空间信号量
50 Lock(_p_mutex); //加锁,实现多生产者互斥关系
51 _ring[_p_step++] = in;
52 _p_step %= _cap; //判断是否越界,及时返回
53 Unlock(_p_mutex);
54 V(_data_sem); //数据信号量加1
55 }
56 //消费
57 void pop(T *out)
58 {
59 P(_data_sem); //申请数据信号量
60 Lock(_c_mutex);
61 *out = _ring[_c_step++];
62 _c_step %= _cap;
63 Unlock(_c_mutex);
64 V(_room_sem); //空间信号量加1
65 }
66 private:
67 std::vector<T> _ring; //循环队列
68 int _cap; //队列容量
69 int _c_step; //消费者生产的位置
70 int _p_step; //生产者消费的位置
71 sem_t _data_sem; //数据资源,只有消费者关心
72 sem_t _room_sem; //空间资源,只有生产者关心
73
74 pthread_mutex_t _c_mutex; //消费者锁
75 pthread_mutex_t _p_mutex; //生产者锁
76 };
结果展示
1 #include "RingQueue.hpp"
2 #include <pthread.h>
3 #include "Task.hpp"
4 #include <unistd.h>
5 #include <cstring>
6
7
8 using namespace std;
9
10 const char* opers = "+-/*%";
11 void* ConsumerRoutine(void* args)
12 {
13 RingQueue<Task> *rq = static_cast<RingQueue<Task>*>(args);
14 while(true)
15 {
16 Task t;
17 rq->pop(&t);
18 t();
19 cout << "Answer: " << t.formatRes()<< endl;
20 }
21 }
22 void* ProductorRoutine(void* args)
23 {
24 RingQueue<Task> *rq = static_cast<RingQueue<Task>*>(args);
25 while(true)
26 {
27 int x = rand()%100;
28 int y = rand()%100;
29 char op = opers[(x + y) % strlen(opers)];
30 Task t(x,y,op);
31 rq->push(t);
32 cout << "productor task: " << t.formatArgs() << "?" << endl;
33 }
34 }
35 int main()
36 {
37 srand((uint64_t)time(nullptr) ^ getpid());
38
39 RingQueue<Task> *rq = new RingQueue<Task>();
40 pthread_t c[3],p[2];
41 for (int i = 0;i < 3;i++)
42 {
43 pthread_create(c + i,nullptr,ConsumerRoutine,rq);
44 }
45 for (int i = 0;i < 2;i++)
46 {
47 pthread_create(c + i,nullptr,ProductorRoutine,rq);
48 }
49
50 //线程等待
51 for(int i = 0;i < 3;i++)
52 {
53 pthread_join(c[i],nullptr);
54 }
55 for(int i = 0;i < 2;i++)
56 {
57 pthread_join(p[i],nullptr);
58 }
59
60 delete rq;
61 return 0;
62 }

细节剖析
细节1
信号量在前,先申请信号量,再申请锁比较推荐
由于持有锁后,后面线程就无法继续执行临界区里面的代码了,所以假如信号量放在临界区里,则其它线程无法提前申请信号量
就像座位安排,每次只有一个人能够进教室,然后找到一个位置坐下
信号量就是我们的座位资源
虽然每一次只能有一个人能够进入教室,但是座位是可以提前被安排(预定)的!
这样进教室就不用找座位,而是直接到对应位置坐下即可,更为高效
细节2
同样的,cp模型的意义绝对不在于从缓冲区中放入和拿出数据,而是获取和处理数据的部分!
两种实现方法对比总结
信号量与条件变量最大一点的不同
就在于信号量不需要在临界区内部进行判断,它是一个计数器,通过信号量的剩余多少,我们就可以知道临界资源的使用情况
但是条件变量不同,我们需要在临界区内部对资源多少进行判断,假如不存在相应的资源,我们需要及时把对应的线程挂起,避免死锁情况,等有相应的资源,才会重新被唤醒
因此,什么时候使用条件变量,什么时候使用信号量呢?
关键就在于对应的临界资源,你把它看作是一个整体,还是切分成一个个小资源集合
假如是前者,那你只需要一把锁,维护互斥关系,还有两个条件变量,维护同步关系
假如是后者,那则需要两把锁,维护互斥关系,还有两个信号量,维护同步关系