Redis队列Stream
1 缘起
项目中处理文件的场景:
将文件处理请求放入队列,
一方面,缓解服务器文件处理压力;
另一方面,可以根据文件大小拆分到不同的队列,提高文件处理效率。
这是Java开发组Leader佳汇提出的文件处理方案,非常实用。
从他那学习到之后,开始搜集Redis Stream相关的知识,整理成文,帮助开发者轻松应对知识交流和考核。
2 Redis Stream
Redis Stream是Redis 5.0.0版本新增的数据结构,想使用Stream需要Redis的最低版本是5.0。
Stream是一个高性能、高可靠的消息队列,用于异步消息处理,就是传统的队列功能,完成流量削峰。Redis 5.0之前的版本就有提供队列功能,如列表、有序集合和Pub/Sub均可实现队列功能。既然Redis已经有了队列功能,为什么还要Stream这个数据结构呢?
按照正常的思考过程,新事物的出现,一般是为了解决旧事物的问题,或者,为了防止垄断,当然, 技术圈也遵循这个理论。
2.1 解决的问题
Stream的出现是为了解决原先队列存在的问题:
(1)Pub/Sub模式无法持久化消息,如果Redis网络异常或者宕机,消息会丢失;
(2)列表和有序集合的方式支持消息持久化,但是,不支持消息多播和分组消费。
Redis Stream一一解决了上面的问题,实现了消息持久化、消息多播和分组消费。
Redis Stream既然是队列应用场景和其他队列一样:
(1)异步解耦;
(2)流量削峰;
不过Redis是基于内存的,如果是大量的消息数据建议选择其他消息队列,如RabbitMQ、Kafka、RocketMQ等。
2.2 架构
先来看一下Stream的总体架构:

Redis Stream有生产者、消费者和消费组,其中,
(1)消费组:有多个消费者,消费者之间是竞争关系,消费组中有一个last_delivered_id,消费组中的任意一消费者消费了消息,都会使last_delivered_id移动;
(2)消费者:消费者消费消息后,会产生pending_id,即消费者的状态变量,当消费者消费消息后,使用pending_ids记录被消费的消息,当客户端没有进行消费确认(ACK)时,pending_ids中的数据会一直增加,当客户端进行消息确认(ACK)后, 会移除pending_id。Redis官方称pending_ids为PEL(Pending Entries List),用于确保客户端至少消费一次消息,而不会在网络传输中丢失了处理。
2.3 数据结构
先从源码简单看下Stream相关的数据结构:
/* Stream item ID: a 128 bit number composed of a milliseconds time and
* a sequence counter. IDs generated in the same millisecond (or in a past
* millisecond if the clock jumped backward) will use the millisecond time
* of the latest generated ID and an incremented sequence. */
typedef struct streamID {
uint64_t ms; /* Unix time in milliseconds. */
uint64_t seq; /* Sequence number. */
} streamID;
typedef struct stream {
rax *rax; /* The radix tree holding the stream. */
uint64_t length; /* Current number of elements inside this stream. */
streamID last_id; /* Zero if there are yet no items. */
streamID first_id; /* The first non-tombstone entry, zero if empty. */
streamID max_deleted_entry_id; /* The maximal ID that was deleted. */
uint64_t entries_added; /* All time count of elements added. */
rax *cgroups; /* Consumer groups dictionary: name -> streamCG */
} stream;
由源码知,stream由Radix树和streamID类型的数据构成,
其中,streamID有两部分组成,ms和seq,ms即毫秒(10位),seq即序列号,
Stream中的每一条消息使用:{毫秒}-{序列号}唯一标识。
3 基础操作
3.1 新建数据:XADD
格式:
XADD key ID field value [field value ...]
参数:
XADD mystream-test * name xiaoyi age 10
XADD mystream-test * name xiaoer age 11

3.2 查询数据:XRANGE
格式:
XRANGE key start end [COUNT count]
参数:
| 参数 | 描述 |
|---|---|
| key | 队列名称 |
| start | 起始ID标识 |
| end | 结束ID标识 |
| COUNT | 查询的条数 |
3.2.1 查询所有数据
XRANGE mystream-test - +
参数:
-:第一条数据
+:最后一条数据
使用- + 表示拆寻所有数据。

3.2.2 查询指定条数
XRANGE mystream-test - + COUNT 1

3.2.3 查询指定范围数据
XRANGE mystream-test 1697335440000-0 1697359922197-0

3.3 读取数据
格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
参数:
| 参数 | 描述 |
|---|---|
| COUNT | 返回的条数 |
| BLOCK | 用于设置XREAD为阻塞模式,单位毫秒,默认为非阻塞模式。非阻塞模式下,读取完毕(即使没有任何消息)立即返回,而在阻塞模式下,若读取不到内容,则阻塞等待。如果在这个时间内没有新的数据流入,那么输出(nil) (1.05s) |
注:使用Block模式,配合 作为 I D ,表示读取最新的消息(在非阻塞模式 作为ID,表示读取最新的消息(在非阻塞模式 作为ID,表示读取最新的消息(在非阻塞模式无意义),若没有消息,命令阻塞!等待过程中,其他客户端向队列追加消息,则会立即读取到。
3.3.1 直接读取
XREAD STREAMS mystream-test 0

3.3.2 阻塞读取
XREAD BLOCK 4000 STRRAMS mystream-test $
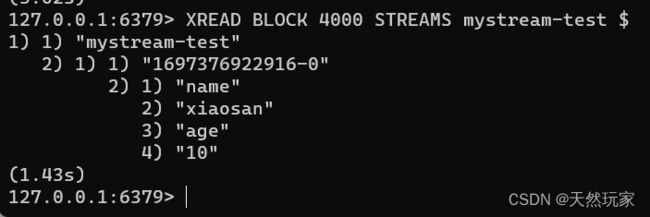
3.3.3 非阻塞读取
XREAD STREAMS mystream-test 0

3.4 删除数据
格式:
XDEL key ID [ID ...]
参数:
| 参数 | 描述 |
|---|---|
| key | 队列名称 |
| ID | 数据ID |
XDEL mystream-test 1697376922916-0

3.5 消费组
3.5.1 创建消费组:XGROUP
格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
参数:
| 参数 | 描述 |
|---|---|
| CREATE | 创建消费组 |
| key | 队列名称 |
| groupname | 消费组名称 |
| id | 接收指定ID之后的消息 |
| $ | 接收所有的消息 |
| 参数 | 描述 |
|---|---|
| DESTROY | 删除消费组 |
| key | 队列名称 |
| groupname | 消费组名称 |
| 参数 | 描述 |
|---|---|
| DELCONSUMER | 删除消费组中的消费者 |
| key | 队列名称 |
| groupname | 消费组组名称 |
| consumername | 消费者名称 |
# 创建接收最新消息的消费组
XGROUP CREATE mystream-test mygroup-1 $
# 创建接收所有消息的消费组
XGROUP CREATE mystream-test mygroup-2 0

3.5.2 删除消费组
# 删除消费组
XGROUP DESTROY mystream-test mygroup-1
XGROUP DELCONSUMER mystream-test mygroup-2
3.5.3 消费组消费消息:XREADGROUP
格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
| 参数 | 描述你 |
|---|---|
| group | 消费组名称。 |
| consumer | 消费者名称。 |
| count | 要读取的数量。 |
| milliseconds | 阻塞时间,以毫秒为单位。 |
| key | 键指定的队列名称。 |
| ID | 表示消息 ID。 |
XREADGROUP GROUP mygroup-1 myconsumer-1 COUNT 1 BLOCK 100000 STREAMS mystream-test >

3.6 查看等待确认状态:XPENDING
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]

3.7 消费信息确认:XACK
格式:
XACK key group ID [ID ...]
参数:
| 参数 | 描述 |
|---|---|
| key | 队列名称 |
| group | 消费组名称 |
| ID | 消息ID |
XACK mystream-test mygroup-1 1698558137966-0
![]()
3.8 查询信息:XINFO
格式:
XINFO [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP]
参数:
查询消费者信息
| 参数 | 名称 |
|---|---|
| CONSUMERS | 查询消费者名称 |
| key | 消费者名称 |
| groupname | |
| 查询消费组信息 | |
| 参数 | 名称 |
| – | – |
| GROUPS | 查询消费组信息 |
| key | 消费组名称 |
| 查询队列信息 | |
| 参数 | 名称 |
| – | – |
| STREAM | 查询队列信息 |
| key | 队列名称 |
3.8.1 查询队列信息
XINFO STREAM mystream-test

3.8.3 查询队列中的消费组
XINFO GROUPS mystream-test

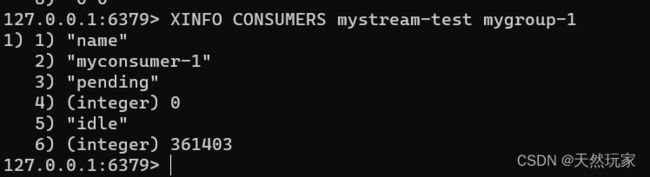
3.8.4 查询队列消费组中的消费者
XINFO CONSUMERS mystream-test mygroup-1
4 小结
Stream的出现是为了解决原先队列存在的问题:
(1)Pub/Sub模式无法持久化消息,如果Redis网络异常或者宕机,消息会丢失;
(2)列表和有序集合的方式支持消息持久化,但是,不支持消息多播和分组消费。
Redis Stream一一解决了上面的问题,实现了消息持久化、消息多播和分组消费。
Redis Stream既然是队列应用场景和其他队列一样:
(1)异步解耦;
(2)流量削峰;
不过Redis是基于内存的,如果是大量的消息数据建议选择其他消息队列,如RabbitMQ、Kafka、RocketMQ等。