CVPR 2017部分论文小结
语义分割与物体识别
One-Shot Video Object Segmentation

本文处理了视频物体分割的问题。
本文提出模型OSVOS,利用第一帧标注的图片来实现整个视频序列中该物体的分割。所有帧都均为独立处理,但结果却很稳定连贯,并达到state-of-the-art。具体方法为:

- Foreground Branch (图1.1):模型利用ImageNet,pre-train一个类似VGG的网络。修改包括:将用于分类的全连接层移除,使用快速的image-to-image inference,加separate skip paths等。输出为是否为前景,loss为每个像素点是否的交叉熵。由于ImageNet不带前后景训练集,pre-train (图2.1) 完成后在DAVIS数据进行前后景训练 (图2.2) ;最终利用第一帧的前景掩码进行fine-tune (图2.3) 。
- Contour Branch (图1.2):由于想要达到精准定位,需要获取物体的轮廓。模型提取轮廓的网络和Foreground Branch相同,输出为是否是轮廓。由于轮廓提取对recall的要求很高,网络采用了Pascal-context数据集进行训练。
- Boundary Snapping (图1.3):结合前景掩码和轮廓掩码。对轮廓掩码,使用较低阈值进行UCM(Ultra metric Contour map)来计算轮廓内的超像素。然后对这些像素点进行大多数投票(与前景掩码的重合度超过50%)来确定最后前景的分割。
Video Propagation Networks

本文提出一个在视频上传递信息(如语义分割,物体分割)的方法。
本文提出了VPN模型:给定前几帧的信息mask (可以离散,如语义;或连续,如颜色),根据对应帧的图像 ,我们可以得到一个函数 来预测下一个帧的信息。通过每下一帧的推断,信息最终可以传递到整个视频序列;并且由于模型一旦开始传播,给定输入图片不需要未来帧的加入,速度上可以完全实现在线级别。模型是一个完整的端到端的网络设计:

- 总体:文章先于第3部分介绍了双边滤波器(Bilateral Filter),并介绍双边滤波可以分为Splat(将图片向量投射到高维网格)、Convolve(高维滤波)、Slice(将结果投射到低维兴趣点)的三步实现。如图2、3所示,VPN的实现就是分为这三部分考虑。
- Bilateral Network (BNN):启发自joint bilateral upsampling和learnable bilateral filters,BNN有三个重点:
- Fast Bilateral Upsampling Across Frames:模型选用特征向量 来编码位置颜色和时间,这种表示方法使得各个pixel之间的同图相关性被降低。同时模型也测试了加入光流信息的特征向量。
- Learnable Bilateral Filters:对于每个 ,特征 可以被一个 矩阵替代,可以得到 ,整合得到的 分布在一个permutohedral lattice上。然而实际上 上的点之间的距离很接近,所以模型提出需要用一个filter bank 来处理。为了速度考虑,模型使用了 的filter,并整合Splat、Convolve和Slice为一个Bilateral Convolution Layer (BCL)。
- BNN Architecture:如图3所示,两层 和 使用不同的scale(比例通过学习得到)处理输入,经过一个 的卷积层重新输出到原先的维度。
- Spatial Network (CNN):网络只含有三个32通道的卷积层,用来refine第 个frame的信息。最后经过一个 的卷积层,输出
Not All Pixels Are Equal: Difficulty-Aware Semantic Segmentation via Deep Layer Cascade

本文处理了视频物体分割的问题,并获得第一届DAVIS Challenge语义分割比赛冠军。
本文认为,在语义分割任务中,图像中的像素不应该被平等对待,而是存在难易区别的。(疑问:其实也类似attention的思路?)经统计,本文将图片上的像素分成了简单,中等,困难三种集合,如对物体内部或者大块区域分割较为容易,而边界分割较为困难等。
因此,本文提出模型Deep Layer Cascade来针对性地处理不同难易程度的像素。如图所示,其中Layer Cascade (LC) 是在Inception-Resnet-v2的基础上改进的。模型分为三个阶段,每个阶段都会分叉出两层卷积层和softmax loss,进行单独的像素语义输出;同时每个阶段引入了一个概率阈值ρ,利用ρ来控制该阶段应该处理哪些像素:大于ρ的在本阶段处理,小于ρ的传至下一阶段,从而针对性处理像素并且提高计算速度。由于ρ的控制,每个阶段处理的像素不相同,最后将三个阶段所得输出直接相加就可以得到最终结果。

同时,为了针对性处理像素,本文提出Region Convolution来只处理每个阶段感兴趣的区域,并忽视其他区域。Region Convolution本质上是加了一个二值mask,感兴趣的区域标注1,其它区域标注0,进行选择性卷积。
Object Detection in Videos with Tubelet Proposal Networks

本文处理了视频物体检测的问题。(以下引用及改编自商汤科技)
相较于传统静止图片的物体检测问题,现有的视频物体检测方法通常基于时空「管道」(tubelets),即跨时间连接的检测框来有效的应用视频中的时域信息。但是现有方法中时空管道生成的质量和效率往往差强人意:基于运动信息的生成方法只能生成较短的时空管道;而基于图像信息的生成方法需要花费大量的计算量,也不能保证对于物体较高的召回率。
本文将传统针对静止图像的FasterRCNN框架进行了扩展:将视频物体检测框架扩展为「候选时空管道生成」和「候选时空管道识别」两个模块,并提出了一种高效率的候选时空管道生成方法,能够在保证时空管道较长长度的同时,尽可能的保留不同时空管道的多样性从而提高物体的召回率。基于这些高质量的候选时空管道应用编码-解码LSTM网络进行时空管道的识别能够有效的提升检测整体的正确率。作者还对Tubelet Proposal Network初始化和不同设置进行了详尽分析。基于TPN的物体检测平均正确率相较于静止图像检测框架有>5%的提升。
本文文是商汤科技在2016年ImageNet竞赛第一工作上进行扩展后提出的全新视频物体检测框架,相较于现有算法对视频中物体检测的效率和准确率进一步提升。
Surveillance Video Parsing with Single Frame Supervision

本文处理了视频物体检测分割的问题。
Instance-Level Salient Object Segmentation
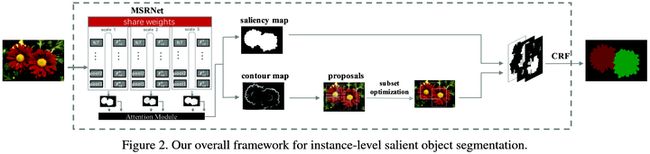
本文处理了图片中显著物体分割识别的问题。
如图所示,本文的方法分为三步:预测salient map,检测salient object轮廓,识别salient object实体。同时文章也建立了一个1000个图片的数据库,包括它们的salient instance annotations。详细的设计如下:

- Multi-scale Refinement Network:如图3所示,网络层设计自VGG16改编而来:
- 网络利用了U型的multi-scale方法来解决不同图片尺寸输入的问题(注:此方法今年很多paper都有用到)。另外,由于物体识别和salient object轮廓都需要同时提取low-level cues和high-level semantic information,网络的U型设计同时考虑了网络中bottom-up和top-down的信息传递。
- 网络将输入的图片分别scale到 ,分成三个并行的不同scale的模型,并且他们共享参数。
- 网络的输出为一个0到1的probability map,表示saliency的二元检测。最终输出如图4所示,经过一个attention模型,为三个map的per-pixel加权和。
- 训练的时候针对label不平衡做了一些tricks,详情见原文3.1.3
- Salient Instance Proposal:文章使用multiscale combinatorial grouping (MCG) 算法,从contours生成salient object proposals。详细的说,对于四个contour maps(三个来自不同的scale,另一个是他们的合成结果),每个分别生成单独的ultrametric contour map (UCM) 来表示hierarchical image segmentation。这四个hierarchy被对齐,然后结合生成一个hierarchical segmentation和一个ranked object proposals;这些proposals经过处理优化后最终输出salient object proposals。
- Refinement of Salient Instance Segmentation:文章使用CRF去结合salient regions和salient object proposals,详细方法见引用:
Suppose the number of salient instances is K. We treat the background as the (K+1) st class, and cast salient instance segmentation as a multi-class labeling problem. At the end, every pixel is assigned with one of the (K+1) labels using a CRF model. To achieve this goal, we first define a probability map with (K+1) channels, each of which corresponds to the probability of the spatial location being assigned with one of the (K+1) labels. If a salient pixel is covered by a single detected salient instance, the probability of the pixel having the label associated with that salient instance is 1. If a salient pixel is not covered by any detected salient instance, the probability of the pixel having any label is 1/K. Note that salient object proposals may have overlaps and some object proposals may occupy non-salient pixels. If a salient pixel is covered by k overlapping salient instances, the probability of the pixel having a label associated with one of the k salient instances is 1/k. If a background pixel is covered by k overlapping salient instances, the probability of the pixel having a label associated with one of the k salient instances is 1/(k+1), and the probability of the pixel having the background label is also 1/(k+1).
Temporal Convolutional Networks for Action Segmentation and Detection
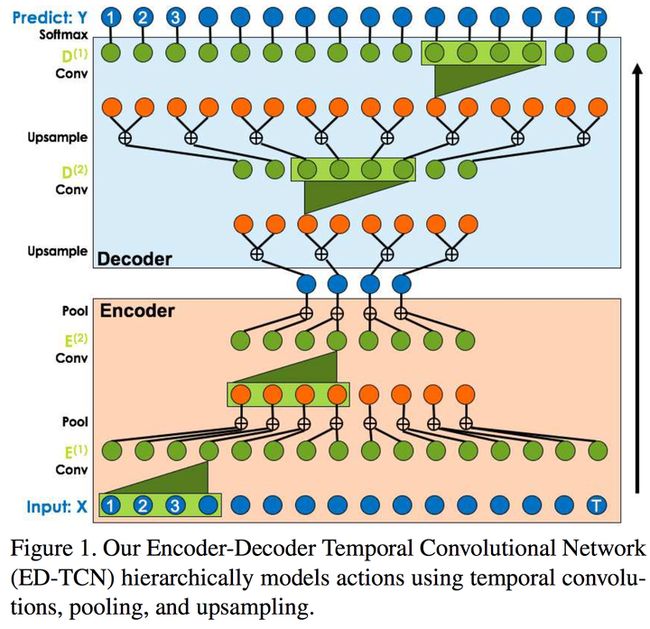
本文提出了一个视频动作分割和检测的方法。
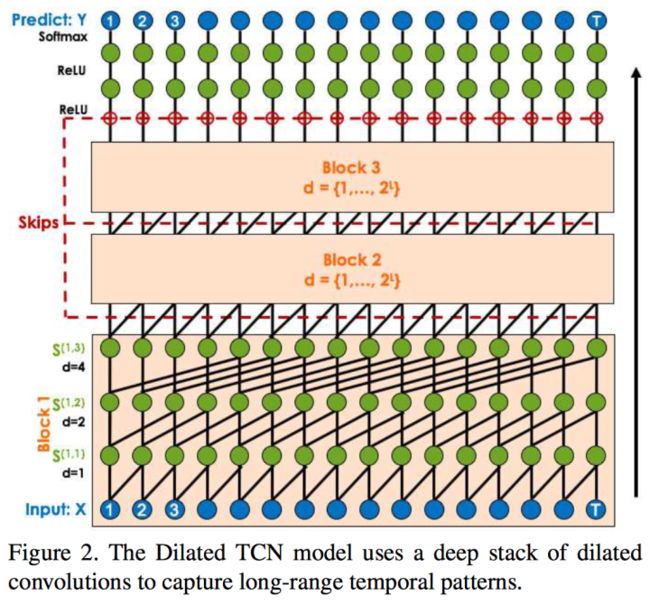
本文提出了模型TCN,其中Encoder-Decoder风格如图1所示,Dilated风格如图2所示,输入是一组video features,如其他视频卷积处理网络的输出;输出是动作标签。
风格转换
Real-Time Neural Style Transfer for Videos
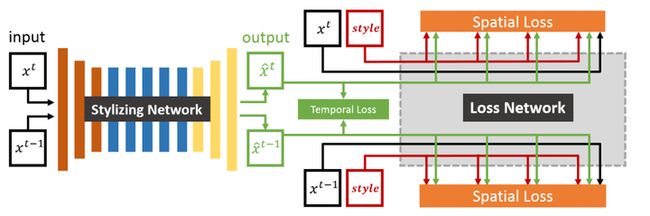
本文实现了实时的视频风格转换。
模型架构类似李飞飞的Perceptual Losses for Real-Time Style Transfer and Super-Resolution,先用一个下卷积+信息提取+上卷积的Resnet去stylize video, 然后进入Vgg-19来算spatial loss,同时加上{输出后帧}和{输出前帧+光流}的temporal loss。
文章的一大亮点是在保持了一定的coherency的前提下,达到了real-time级别(0.041s on NVIDIA Tesla K80 GPU)。由于只在training过程中使用光流做loss,而不是像MSRA的Coherent Online Video Style Transfer那样在inference过程也用到,节省了大量时间。
文章提到,考虑Long-Term Temporal Consistency与不考虑效果差不多;这一点实际基于在他们自己的模型架构上,对此结论仍然可以进行一些探讨。
超分辨率
Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution

本文实现了快速、高精度的超分辨率预测。
传统的超分辨率预测有一些共同点:
- 采用L2 loss:因为L2 loss函数不能找到由低分辨率到高分辨率的潜在的多模态分布,因此会不可避免地产生模糊的预测。例如,一个低分辨率的部分可能对应多个高分辨率的部分,用L2 loss会导致结果过于平滑,失去了部分信息,也不符合人类视觉。
- (除VDSR外)输入图片为固定尺寸:利用线性插值转为指定尺寸时增加了人为噪声。
- 从输入直接到超分辨率输出,无法获得中间的超分辨率结果。
本文模型LapSRN,进行了如下改进:
- 金字塔结构:网络有两个分支,分别负责特征提取和图像重构。蓝色箭头代表上采样,绿色箭头表示element-wise叠加,向右的红色箭头表示同尺寸采样,向下的红色箭头表示输出残差。 通过级联学习,网络可以输出不同大小的残差,得到不同大小的超分辨率预测。顺带一提,很多做超分辨率的网络都在加深网络结构,但是为了防止深层、高分辨率的信息不好反向传播,都采用了残差来优化。这里的残差用来更新上采样重构很有启发性。
- loss将每个尺寸下,真实图片和预测图片的差进行求和。简而言之就是用每个尺寸的直接差取代了总体的L2 loss。
网络设计
PolyNet: A Pursuit of Structural Diversity in Very Deep Networks

本文提出了一个新的网络设计方案。
本文提出一个问题:增加网络的深度和宽度是最好的优化网络表现的方法吗?文章反对这个看法,并认为时间复杂度和内存要求的quadratic growth是最大的局限性。如对深度进行实验时,发现ResNet-269比ResNet-50有显著提升,但是ResNet-500比ResNet-269只有千分之一的提升,却增加了一倍的消耗。
由此启发,文章对structural diversity进行讨论,提出几个可能使得网络效能好的关键点:(1) 使用ensembles;(2) ResNet的高性能来源于它的multiplicity而不是depth,它实际上是implicit ensemble of shallow networks;(3) Inception-ResNet-v2是目前相比最好的设计之一,效果优于ResNet并且layer更少.
对此,文章设计了PolyInception模块:每个模块是Inception units的组合;由于每个模块只是大网络的building blocks,因此可以被单独或组合着插入替代原来的模块。各种module设计见图4,注意其中多个F表示shared parameter,G表示不和F分享参数。

图5显示了网络整体结构。测试结果表明,PolyNet的准确率超过了Inception-ResNet-v2,却增加了一定的计算量。详细的网络比较见论文,例如增加Stage B的复杂度被认为是最有效的。同时,在stage内部采用mixed poly modules也可以提升一定的准确率,这说明了structural diversity的提高既存在于模块内部,也存在于模块之间的整合。

图9展示了插入新模块的方法。图10展示了一个新的方法stochastic paths:每个iteration随机drop一些path,相当于模块级的dropout,也是一种diverse ensemble implicitly embedded的体现。
Densely Connected Convolutional Networks

本文介绍了新的网络结构—— DenseNet。
传统直上直下的网络模型只有前后层相互连接,若有 层网络,那么连接数也是 。然而DenseNet却含有 个链接,即每一层都和下面所有的层进行连接。这样做有几个好处:缓解梯度消失问题、强化feature传递、鼓励feature再利用、极大减少参数总数量(这一点违反直觉,但实际上DenseNet的设计可以避免重复学习feature map;并且网络每一层的通道数非常少)。

网络设计如图2所示,每个Desne Block内部是全联接的卷积单元(卷积层+BN+Relu),Blocks之间用转移层(几个卷积层+平均池化)连接和降维。此外,还有一些独特的设计:
- Growth rate:给定每个卷积单元含有相同的通道数量 ,若输入的通道为 ,那么第 个卷积单元的通道数就是 。文章定义 为growth rate,且由实验和理论显示,很小的 就可以得出state-of-the-art的结果。
- Bottleneck layers:文章中提到可以在每个 的卷积单元前加一个 的卷积层减少通道数到 左右,以此增加计算速度。
- Compression:可以在转移层减少输入的通道数量,如减少一半。
多任务网络
Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification

本文介绍了一个自适应扩展的多任务网络学习方法。
如图所示,文章提出了一个从窄网络(thin network)开始的自下而上的方法,并在训练过程中使用一个促进类似任务分组的标准,贪婪地动态拓宽网络。但是,贪婪方法可能无法发现全局最优的模型,而将每个分支正好分配给一个任务不允许模型学习更复杂任务交互。
另外,Sebastian Ruder(机器之心翻译)也整理了一些流行的多任务模型,值得一看。
Multi-Task Clustering of Human Actions by Sharing Information

文章介绍了一个基于多任务的人类动作聚类分析的方法。
文章提出,不同视频集合通常含有很多相似的动作,但是在cross-view的视频里,相同的动作通常是从不同视角来拍摄的。文章把每个视角下,捕捉道德动作pattern作为一个训练任务;但是由于self-occlusions,单一视角无法学习到鲁棒的动作识别。并且,虽然目前的单一任务学习的准确度很高,但是仍然存在以下挑战:(1) 忽略动作之间的shared information,如一些利用LDA来分类动作的方法,而且也无法解决多视角的问题。(2) 制定shared information measurement的困难性。
对此,文章提出了Multi-task Information Bottleneck (MTIB) 方法。如图所示,方法首先使用基于bag-of-visual-words模型的agglomerative information maximization (AIM) 的方法去建造一个多任务之间的high-level common library;然后转化为information loss minimization,即任意两类的shared information可以被common library中的distributional correlation based on the co-occurrence words量化。
迁移学习
Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-Tuning

本文介绍了一种图片分类迁移学习的方法。
本文提出了Deep Transfer Learning through Selective Joint Fine-Tuning,分步为:
- Source and Target Domain:选用足够大的图片识别数据库,如ImageNet和COCO。
- Similar Image Search:·只有和target domain的图片在low-level特征相似的source domain图片会被加入训练集。具体方法为:
- 对于source和target domain的图片,用一个包含很多过滤器的filter bank处理它们,来获取histograms。文章采用了Gabor filter和pre-trained AlexNet low-level kernels,后者为Alexnet靠近input的那些提取低级信息的层。
- 针对每个filter map,扫描整个target domain在它上面的histogram,根据扫描的统计结果把每个filter map分成不同的自适应大小的bin,每个bin含有基本相同数量的pixel,从而使histogram较均匀地离散化。这样通过列举所有的filter maps,每一个图像就可以得到长度等于filter map数量的离散histogram特征向量。
- 因为每个filter map/kernel本身的权重就不同,文章规定source和target图片的距离为根据权重加权平均过的、用特征向量计算的KL散度。每个target图片根据此距离选取K个邻居作为对于的source图片。
- 此外,对于target domain那些难以训练的样本,可能需要更多的邻居来训练它们。因为文章提出了一个信息熵函数来测量分类不确定性,打分高的被认为是难以训练的样本。确定邻居数量时进行了五次迭代,每次迭代中被认为难以训练的样本、以及预测错误的样本的邻居选取数量增加,其余保持上一次迭代的邻居数量不变。这种方式起到了自适应选取合适的feature representation的作用。
- CNN:网络选用的是在对应source数据集上pre-train过的ResNet-152。source和target图片经过相同的卷积网络;因为source和target的标签空间可能不同,最后分出来两个linear classifier,分别负责source和target的图片分类。
- Source-Target Joint Fine-tuning:Fine-tune网络时,每个task在joint fine-tuning的cost函数是相互独立的,而且每一个training图只贡献自己对应的那个domain (source 或 target)。
对抗学习
Learning from Simulated and Unsupervised Images through Adversarial Training

本文提出了一种Simulated+Unsupervised Learning (S+U) 方法。
模型的名称为SimGAN。不同于一般的GAN,SimGAN的输入为合成的假图片而非随机向量,优化目标是一个优化器(refiner)。同时,SimGAN还有几个重要的改变:增加了正则项、使用local adversarial loss、用已经优化过的图像来更新discriminator。

算法如上图算法1所示,其中对抗loss为
,优化器loss为 ,其中利用的discriminator loss如图3所示。此外,传统的利用最近一次计算的图片来更新网络的方法,会导致对抗训练有较大的divergence,且优化器会引入discriminator已经忘记的artifacts。因此,算法维护了一个历史buffer,每次选用数据的时候,一半来自于最近一次计算,一半来自于buffer;同时buffer的大小是固定的,每次更新一半buffer里的历史数据。