Spark 学习笔记3. spark-submit + spark-shell
spark-submit:
相当于 hadoop jar 命令 ---> 提交MapReduce任务(jar文件 )
提交Spark的任务(jar文件 )
Spark提供Example例子:/root/training/spark-2.1.0-bin-hadoop2.7/examples/spark-examples_2.11-2.1.0.jar
# java python r resources scala
#resources ----> 测试数据(格式:txt json avro parquet列式存储文件) --> Spark SQL中
示例:蒙特卡罗求PI(3.1415926******)
[root@BigData11 spark-2.1.0-bin-hadoop2.7]# bin/spark-submit --master spark://BigData11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/10/12 21:22:36 INFO SparkContext: Running Spark version 2.1.0
Pi is roughly 3.141484157074208
spark-shell:
类似Scala的REPL命令行,类似Oracle中的SQL*PLUS
Spark的交互式命令行
两种运行模式
作为一个Application运行
(*)本地模式 bin/spark-shell
不连接到集群,在本地执行任务,类似Storm的本地模式
日志:
Spark context Web UI available at http://192.168.157.111:4040
Spark context available as 'sc' (master = local[*], app id = local-1528291341116).
Spark session available as 'spark'.
开发程序:*****.setMaster("local")
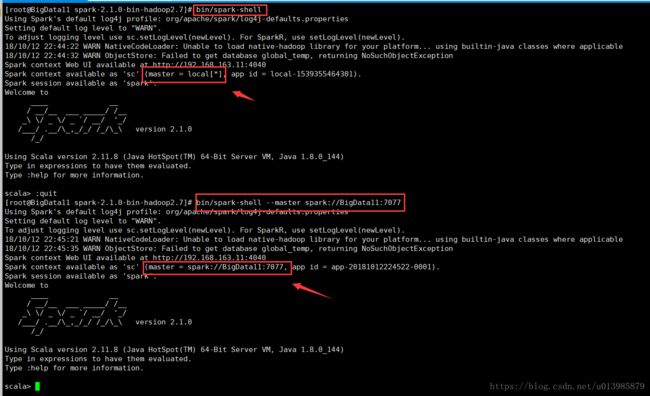
(*)集群模式 : 连接到集群,在集群执行任务,类似Storm的集群模式
bin/spark-shell --master spark://bigdata111:7077
日志:
Spark context Web UI available at http://192.168.157.111:4040
Spark context available as 'sc' (master = spark://bigdata111:7077, app id = app-20180606212511-0001).
Spark session available as 'spark'.
开发程序:*****
开发一个WordCount程序:处理HDFS数据
sc.textFile读取HDFS: sc.textFile("hdfs://bigdata111:9000/input/data.txt")
sc.textFile读取本地: sc.textFile("/root/temp/data.txt")
程序
sc.textFile("hdfs://bigdata111:9000/input/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://bigdata111:9000/output/0606/spark")
单步运行WordCount(每一步执行的时候,会产生一个新的RDD集合)
var rdd1 = sc.textFile("hdfs://bigdata111:9000/input/data.txt"): 延时读取数据
var rdd2 = rdd1.flatMap(_.split(" ")): 将每句话进行分词,再合并到一个集合(Array)
var rdd3 = rdd2.map((_,1)) : 每个单词记一次数
完整: rdd2.map(word=>(word,1))
var rdd4 = rdd3.reduceByKey(_+_) 把相同的key的value进行累加
注意:reduceByKey(_+_) 完整: reduceByKey((a,b)=>a+b)
举例:Array((Tom,1),(Tom,2),(Mary,3),(Tom,4))
第一步:分组
(Tom,(1,2,4))
(Mary,(3))
第二步:每组对value求和
1+2 = 3
3+4 = 7
总结:(1)算子(函数、方法):Transformation延时计算
Action立即执行
(2)RDD之间存在依赖关系:宽依赖、窄依赖
scala> var rdd1 = sc.textFile("hdfs://192.168.163.11:9000/data/data.txt")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://192.168.163.11:9000/data/data.txt MapPartitionsRDD[1] at textFile at :24
scala> rdd1.
++ context filter getStorageLevel map preferredLocations saveAsTextFile toDS zip
aggregate copy first glom mapPartitions productArity setName toDebugString zipPartitions
cache count flatMap groupBy mapPartitionsWithIndex productElement sortBy toJavaRDD zipWithIndex
canEqual countApprox fold id max productIterator sparkContext toLocalIterator zipWithUniqueId
cartesian countApproxDistinct foreach intersection min productPrefix subtract toString
checkpoint countAsync foreachAsync isCheckpointed name randomSplit take top
coalesce countByValue foreachPartition isEmpty partitioner reduce takeAsync treeAggregate
collect countByValueApprox foreachPartitionAsync iterator partitions repartition takeOrdered treeReduce
collectAsync dependencies getCheckpointFile keyBy persist sample takeSample union
compute distinct getNumPartitions localCheckpoint pipe saveAsObjectFile toDF unpersist
scala> rdd1.collect
res0: Array[String] = Array(I love Beijing, I love China, Beijing is the captial of the China)
scala> var rdd2=rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at flatMap at :26
scala> rdd2.collect
res2: Array[String] = Array(I, love, Beijing, I, love, China, Beijing, is, the, captial, of, the, China)
scala> var rdd3 = rdd2.map((_,1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at map at :28
scala> rdd3.collect
res3: Array[(String, Int)] = Array((I,1), (love,1), (Beijing,1), (I,1), (love,1), (China,1), (Beijing,1), (is,1), (the,1), (captial,1), (of,1), (the,1), (China,1))
scala> rdd3.
++ count foldByKey iterator persist saveAsHadoopDataset toDF
aggregate countApprox foreach join pipe saveAsHadoopFile toDS
aggregateByKey countApproxDistinct foreachAsync keyBy preferredLocations saveAsNewAPIHadoopDataset toDebugString
cache countApproxDistinctByKey foreachPartition keys productArity saveAsNewAPIHadoopFile toJavaRDD
canEqual countAsync foreachPartitionAsync leftOuterJoin productElement saveAsObjectFile toLocalIterator
cartesian countByKey fullOuterJoin localCheckpoint productIterator saveAsSequenceFile toString
checkpoint countByKeyApprox getCheckpointFile lookup productPrefix saveAsTextFile top
coalesce countByValue getNumPartitions map randomSplit setName treeAggregate
cogroup countByValueApprox getStorageLevel mapPartitions reduce sortBy treeReduce
collect dependencies glom mapPartitionsWithIndex reduceByKey sortByKey union
collectAsMap distinct groupBy mapValues reduceByKeyLocally sparkContext unpersist
collectAsync filter groupByKey max repartition subtract values
combineByKey filterByRange groupWith min repartitionAndSortWithinPartitions subtractByKey zip
combineByKeyWithClassTag first id name rightOuterJoin take zipPartitions
compute flatMap intersection partitionBy sample takeAsync zipWithIndex
context flatMapValues isCheckpointed partitioner sampleByKey takeOrdered zipWithUniqueId
copy fold isEmpty partitions sampleByKeyExact takeSample
scala> var rdd4 = rdd3.reduceByKey(_+_)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[5] at reduceByKey at :30
scala> rdd4.collect
res4: Array[(String, Int)] = Array((is,1), (love,2), (captial,1), (Beijing,2), (China,2), (I,2), (of,1), (the,2))
scala> var rdd5= rdd4.saveAsTextFile("hdfs://192.168.163.11:9000/spark/data/1021")
saveAsTextFile("hdfs://192.168.163.11:9000/spark/data") #目录不能提前存在,否则抛异常
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.163.11:9000/spark/data already exists
at org.apache.hadoop.mapred.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:131)
查看hdfs 上的数据,我们发现有两个分区
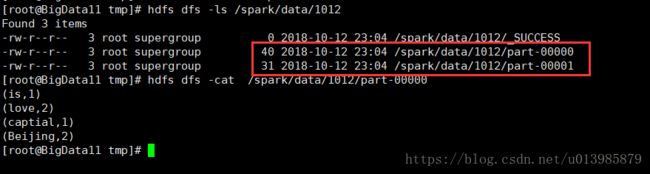
如何保存一个分区:
scala> rdd4.r
randomSplit reduce reduceByKey reduceByKeyLocally repartition repartitionAndSortWithinPartitions rightOuterJoin
scala> rdd4.repartition(1).saveAsTextFile("hdfs://192.168.163.11:9000/spark/data/1012")
