ChatGLM3详细安装部署
一、安装NVIDIA
找到任务栏的右下角,右键选择NVIDIA进行安装。

这里正在进行安装,稍等片刻。等待安装完毕。

安装好之后打开,选择驱动程序进行下载。
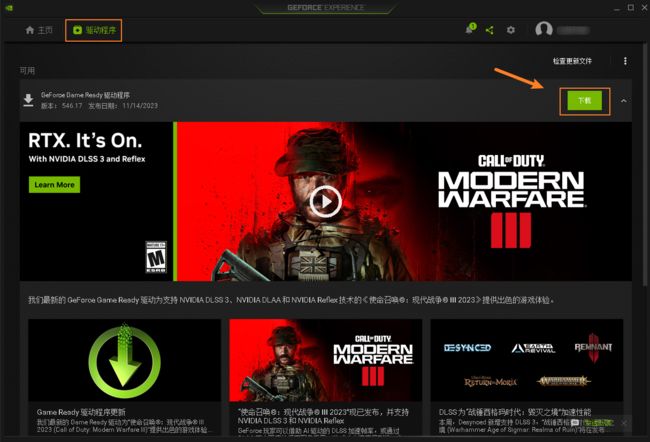
下载好,可以选择快速安装即可。
安装完之后,进行重新启动系统。
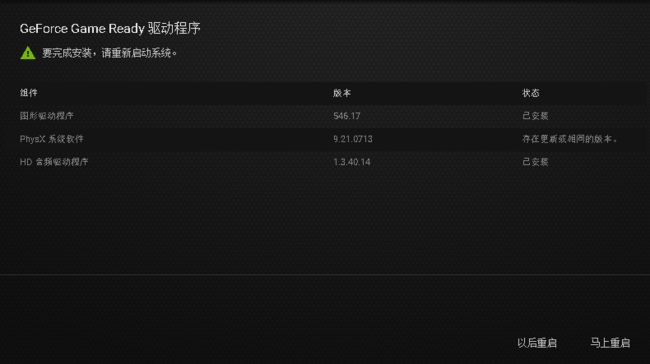
二、下载CUDA
访问CUDA官网进行下载,CUDA Toolkit 12.3 Update 1 Downloads | NVIDIA Developer
下面的选项和操作系统可以根据自己的情况自己选择下载。

下载完成后,进行安装。安装目录可以自行选择,最好是新建一个新的文件夹。
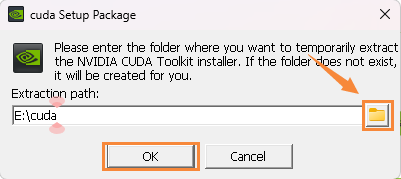
等待下载完成即可。
下载安装好之后,打开选择同意并继续;

这里可以选择默认的【精简】- 更新现有驱动程序并保留当前NVIDIA设置,然后点击:下一步;

NVIDIA图形驱动程序的安装流程是全自动的,耐心等待即可;

安装好之后选择下一步;
这里就显示NVIDIA安装程序已完成,关闭即可。

三、对NVIDIA的安装程序进行验证
按下Win+R键,打开命令提示符,输入nvidia-smi进行验证。验证成功,显示CUDA Version: 12.3。
四、下载ChatGLM3_Package
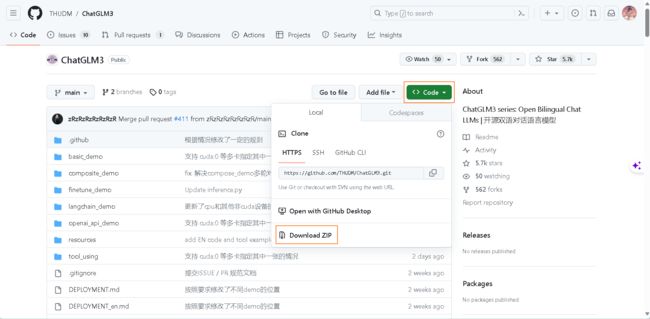
ChatGLM3的github下载地址:GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
选择下载为zip压缩包,然后解压到你自己指定的目录。
五、安装anaconda配置python环境
这里选用清华大学开源软件镜像站:anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
下载的速度更快。
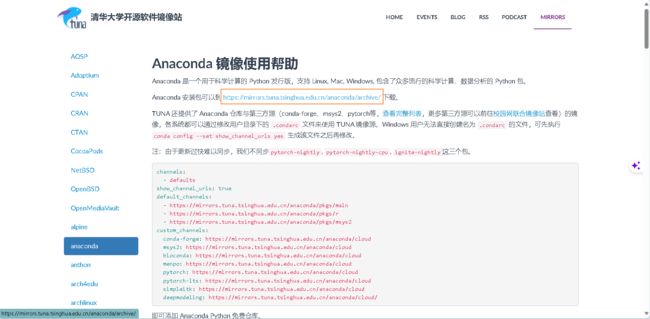
点击下载链接:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
往下翻,找到最新的.exe进行下载。
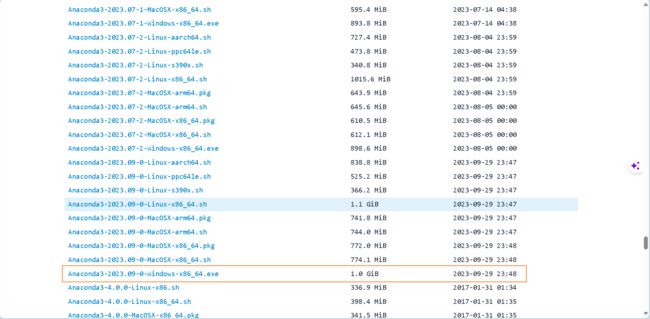
安装anaconda时,只需要注意一下你存放的路径,其他都直接默认next即可。
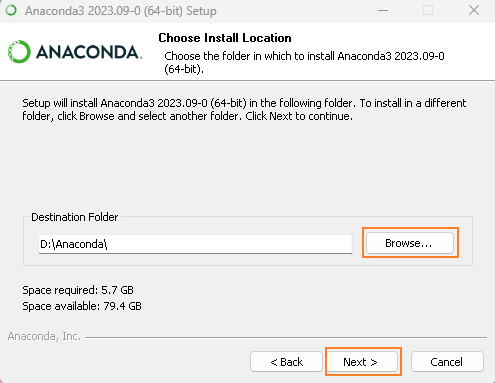
这里,第二个自动帮你添加环境变量的选项,如果是图个方便的话可以勾选,但环境变量可以后期进行设置,更加明确些;

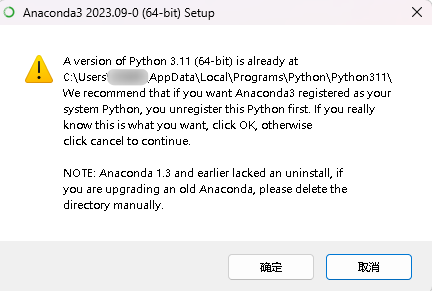
第三个是将anaconda设置为系统的python3.11,python3.11我之前有下载过,所以在勾选的时候会跳出警示框,选择确认即可。
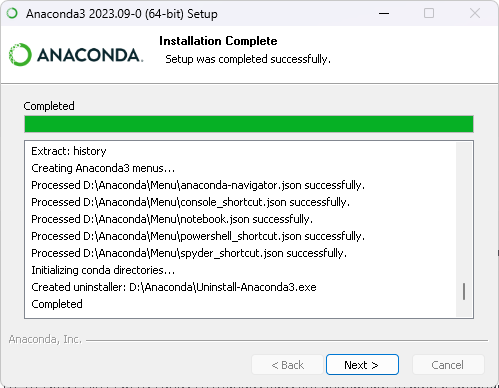
安装可能需要花上一段时间,请稍等。这里已经显示安装完成,点击Next。
这里的两个选项可以不进行勾选,大多都是推广的软件,勾选了后续也会关闭。

在系统环境变量中找到Path,新建以下的目录路径,完成之后点击确定。
E:\Anaconda
E:\Anaconda\Scripts
E:\Anaconda\Library\bin
E:\Anaconda\Library\mingw-w64\bin
E:\Anaconda\Library\usr\bin 
同样,打开命令提示符,输入conda --version或conda info查看当前conda版本信息。
如果提示conda不是内部或外部命令,那一般是,Anaconda的环境变量没配置好。需要好好检查一下。
六、阅读README.md进行环境依赖
打开到README.md的目录,在E:\ChatGLM3-main\composite_demo\README.md,如果安装的文件夹不同,路径可能会发生改变。打开README.md。
执行以下命令新建一个 conda 环境并安装所需依赖
conda create -n chatglm3-demo python=3.10
conda activate chatglm3-demo
pip install -r requirements.txt
conda install -c huggingface huggingface_hub请注意,本项目需要 Python 3.10 或更高版本。
此外,使用 Code Interpreter 还需要安装 Jupyter 内核:
ipython kernel install --name chatglm3-demo --user
七、下载ChatGLM3训练模型
可以在E:\ChatGLM3-main目录下右键打开Git Bash Here,
下面用 Git LFS 从 Hugging Face Hub 将模型下载到本地,
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b如果你从 HuggingFace 下载比较慢,也可以从 ModelScope 中下载。
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git下载模型需要等待较长时间,毕竟内存比较大。
下载完毕后,打开下载到的目录,目录内容如下。
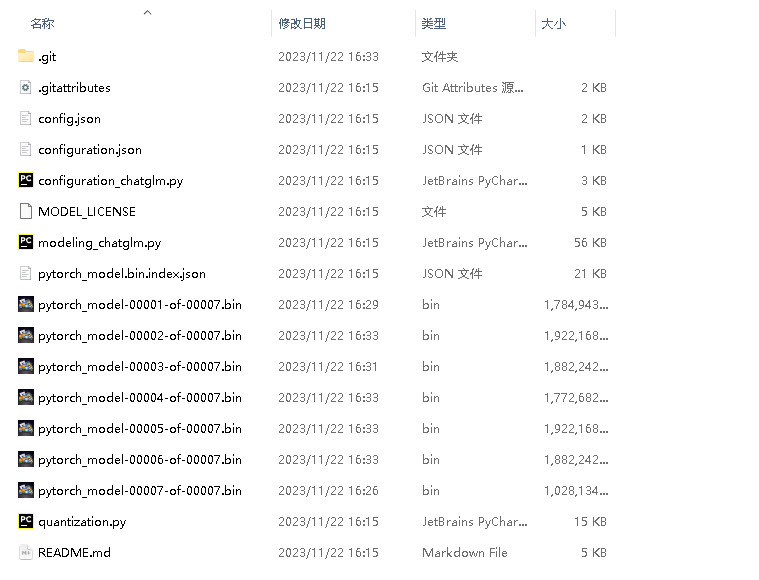
八、配置模型对应的环境变量
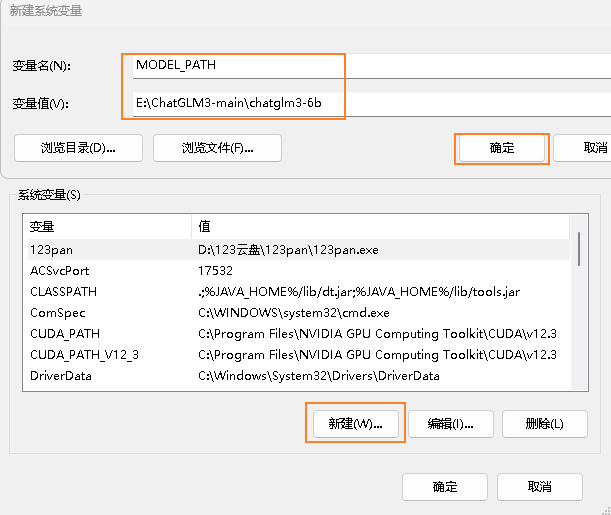
复制上面打开的文件夹目录路径,我这里是E:\ChatGLM3-main\chatglm3-6b
同样,打开环境变量,在系统变量中新建变量。
变量名:MODEL_PATH
变量值:E:\ChatGLM3-main\chatglm3-6b
再新建一个环境变量,
变量名:IPYKERNEL
变量值:chatglm3-demo

九、启动运行ChatGLM3
运行以下命令在本地加载模型并启动 demo:
streamlit run main.py如果已经在本地下载了模型,可以通过 export MODEL_PATH=/path/to/model 来指定从本地加载模型。如果需要自定义 Jupyter 内核,可以通过 export IPYKERNEL=
这里的两步就是对应的上面两步新建环境变量。
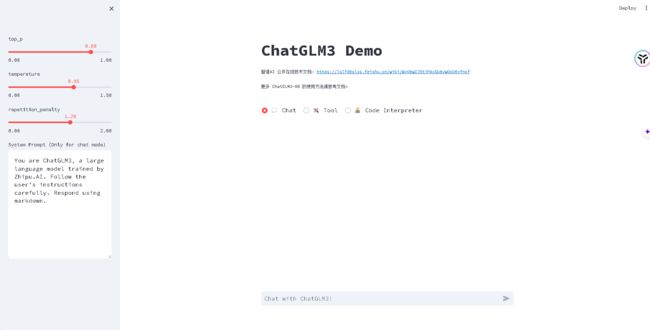
输入streamlit run main.py后等待加载完毕。
加载完毕,已经可以顺利的看到我们的ChatGLM3页面了。
十、模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
十一、CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()