常见的集合类型
集合
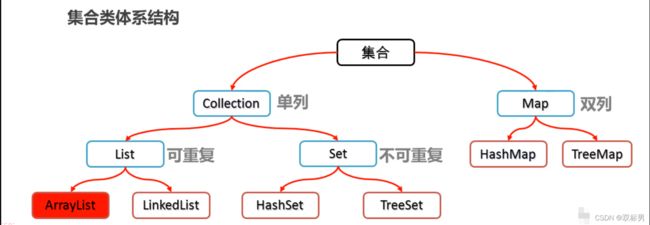 蓝色为接口,红色是实现类
蓝色为接口,红色是实现类
文章目录
- 集合
- 单列集合
-
- 1.概念
- 2.顶层
- 3.常用方法
- 4.迭代器
-
- 概述
- 获取迭代器
- 如何操作
- 增强for循环
- 循环场景使用
- 数据结构
-
- 概述
- 作用
- 常见的数据结构
- 泛型
-
- 概述
- 好处
- 泛型的使用
- List集合
-
- 概述
- 特点
- 特有方法
- 数据结构
- 数组和链表
- List集合子类的特点
- LinkedList集合的特有方法
- Set集合
-
- 概述和特点
- TreeSet集合
-
- TreeSet集合概述和特点
- 排序方法
- 小结
-
- TreeSet构造方法
- TreeSet排序规则注意事项
- 成员方法
- HashSet集合
-
- hashSet特点
- hashSet构造方法
- hashSet成员方法
- 底层数据结构
-
- 哈希表结构
- 哈希值
- 去重复的依据
- 双列集合:map集合
-
- 概述
- 使用
- 特点
- 具体实现类
-
- hashMap集合
-
- 构造方法
- 成员方法
- 遍历的三种方式
- 小结
-
- TreeMap集合
-
- 构造方法
单列集合
Collection
1.概念
1.是单列集合的顶层接口,表示一组对象,这些对象也称为Collection的元素
2.Jdk不提供此接口的任何直接实现,它提供更具体的子接口(set和list)来实现
2.顶层
Collection
创建Collection方式:多态的方式
3.常用方法
Boolean add(E e):添加元素
Boolean remove(Object o):删除元素
Boolean remove(lambda条件):根据条件删
void clear():清空集合
boolean contains(Object o):判断集合中是否存在指定的元素
Boolean isEmpty():判断集合是否为空
int size():集合的长度,也就是集合中元素总和
4.迭代器
概述
lterator:迭代器,集合的专门遍历方式
获取迭代器
Iterator iterator():返回集合中的迭代器对象,该迭代器对象指向当前集合的0索引
如何操作
(1).判断是否下一个可以获取的元素
Boolean hasNext()
(2).获取当前位置的元素,将迭代器对象移向下一个索引位置 E next();
(3).删除当前位置的元素 remove();
增强for循环
增强for:简化数组和Collection集合的遍历
内部原理就是迭代器
只有实现Iterable接口的类才可以使用迭代器和增强for
格式:for(元素数据类型 变量名:数组或者Collection集合){
执行代码块
}
(1).应用场景:单列集合或数组
(2).语法格式:for(元素的数据类型 变量名 : 要遍历的集合或数组){ 在这里使用变量名就是集合中的每个元素 } )
(3).快捷键 :数组名或集合名.for; iter
循环场景使用
1.如果需要操作索引,使用普通for循环
2.如果在遍历中需要删除元素,使用迭代器
3.如果只想遍历数据,使用增强for
数据结构
概述
数据结构是计算机存储\组织数据的方式.是指相互之间存在的一种或多种特点关系的数据元素的集合.
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率.
作用
影响程序或选用了某种数据结构的容器的特点和性能;
常见的数据结构
(1).队列:先进先出的模型
(2).栈:先进后出的模型
(3).数组:查询快,增删慢
(3).链表:查询慢,增删快
泛型
是jdk5中引入的特性,提供了编译时类型安全检测机制
概述
很宽泛的一种类型,简单理解是特殊的变量,因为泛型可以允许调用者将一个引用数据类型作为参数进行传递;
好处
(1).把运行时期的问题提前到了编译期间
(2).写代码的时候可以避免强制类型转换
泛型的使用
(1).编写类或接口的时候在类的后面直接使用<泛型名>
(2).使用者在创建类的对象或接口的实现类对象的时候,可以<具体的引用数据类型>将指定的数据类型传递给编写泛型的类或接口
List集合
概述
(1).有序集合,这里的有序指的是存取顺序
(2).用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
(3).与Set集合不同,列表通常允许重复的元素
特点
有序:存储和取出的元素顺序一致
有索引:可以通过索引操作元素
可重复:储存的元素可以重复
特有方法
void add(int indexx,E element):在此集合位置中插入指定的元素
E remove(int index):删除指定索引处的元素,返回被删除的元素
E Set(int index,E element):修改指定索引处的元素,返回被修改的元素
E get(int index):返回指定索引处的元素
数据结构
存储数据的一种模型;(组织数据的一种方式)
数组和链表
数组结构:查询快\增删慢 因为他是内存中一块连续的空间;
链表结构:查询慢\增删快 因为它的每个节点都是相互的独立的
List集合子类的特点
ArrayList集合:底层是数组结构实现,查询快,增删慢
LinkedList集合:底层是链表结构实现,查询慢,增删快
LinkedList集合的特有方法
public void addFirst(E e):在该列表开头插入指定的元素
public void addLast(E e):将指定的元素追加到此列表的末尾
public E getFirst():返回此列表中的第一个元素
public E getLast():返回此列表中的最后一个元素
public E removeFirst():从此列表中删除并返回第一个元素
public E removeLast():从此列表中删除并返回最后一个元素
Set集合
概述和特点
(1).不可以存储重复元素
(2).无序,没有索引
(3).没有带索引的方法,不能使用普通for循环遍历,也不能通过索引获取,删除Set集合中的元素
(3).属于Collection单列集合下的一个子接口;
TreeSet集合
TreeSet集合概述和特点
(1).不可以存储重复元素
(2).没有索引
(3).可以将元素按照规则进行排序,指定排序的规则
排序方法
TreeSet():根据其元素的自然排序进行排序.
![]()

要求JavaBean必须实现compareable接口,重写compareTo方法,在方法内指定排序规则,一般加一个次要条件来保证数据的正常存储
1.如果是负数表示存入的数据比较小,往左存;
2.返回0表示是重复的数据;
3.返回正数表示存入的数据比较大,往右存.
TreeSet(Comparator comparator) :根据指定的比较器进行排序.
o1表示现在存入的元素,o2表示已经存入的元素
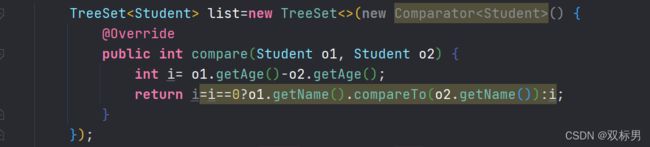
1.TreeSet的带参构造方法使用的是比较器排序对元素进行排序
2.比较器排序,就是让集合构造方法接受comparetor的实现类对象,重写compare(o1,o2)方法
3.重写方法时,一定要注意排序规则,必须按照要求的主要条件和次要条件来写
要求javabean可以实现compareable接口也可以不实现compareable接口,如果实现了compareable接口,对排序规则也没有影响;(Comparator 优先级更高)
1.如果是负数表示存入的数据比较小,往左存;
2.返回0表示是重复的数据;
3.返回正数表示存入的数据比较大,往右存.
小结
自然排序:自定义类实现compareable接口,重写compareTo方法,根据返回值进行排序
比较器排序:创建TreeSet对象的时候传递COmparetor的实现类对象,重写compare方法,根据返回值进行排序
在使用的时候,默认使用自然排序,在自然排序不满足当前的需求时,使用比较器排序
TreeSet构造方法
(1).空参数构造方法 :要求javabean必须实现compareable接口
(2).带比较器的构造方法 :需要我们在比较强中自定义排序规则;(Comparator);
(3).带Collection类型的参数的构造方法 :可以让Collection系列的集合之间进行相互转换
TreeSet排序规则注意事项
指定排序规则的时候,一定要加入次要排序条件,如果不加,会导致主要条件一样的时候,无论其他数据是否一样,都会去重;
成员方法
跟Collation即可
HashSet集合
HashSet集合要存储自定义对象,就必须重写hashcode和equals方法
hashSet特点
(1).底层数据结构为哈希表
(2).不能保证存储和取出的顺序完全一致
(3).没有带索引的方法
(4).是Set集合,所以元素唯一
hashSet构造方法
(1).空参数构造方法
(2).传递一个Collection类型的容器
hashSet成员方法
参考Collation即可
底层数据结构
哈希表结构
jdk8之前,底层采用数组加链表实现
jdk8之后,底层采用数组加链表加红黑树组成
哈希值
是Jdk根据对象的地址或者属性值,算出来的int类型的整数
(1).没有重写的时候,Object类是按照对象的地址值生成的哈希值:
同一个对象多次调用hascode()方法返回的哈希值是一样的,不同对象的哈希值是不一样的
(2).重写后是按照对象的属性值生成的哈希值:
如果不同对象的属性值一样的化,那么他们的哈希值是一样的
去重复的依据
依赖hashCode和equals方法,二者缺一不可
(1).先比哈希值,如果哈希值不一样,直接认为两个对象不一样
(2).如果哈希值一样,则在此利用equals方法确人内容是否一样
双列集合:map集合
概述
双列集合,存储的都是键值对数据
使用
需要指定两个泛型,第一个表示键的数据类型,第二个表示值的数据类型
特点
(1).键值对数据(键和值是一一映射关系)
(2).键不能重复(值可以重复)
具体实现类
hashMap集合
hash表结构的map集合,要求key必须重写hashcode和equals方法;
构造方法
(1).空参数构造方法
(2).带map集合的构造方法
成员方法
V put(k,v):添加数据
V remove(k):根据键删除键值对数据
void put(k,v):根据键修改键值对数据
void clear():移除所有的键值对数据
get(k):通过键获取对应的值
values():获取所有的值
keySet():获取所有键的集合(Set集合)
entrySet():获取所有的键值对
int size():集合中键值对的个数
Boolean contaionsValues():判断是否包含指定的值
Boolean contaionsKey(k):判断是否包含指定的键
Boolean isEmpty():判断集合是否为空
遍历的三种方式
(1).键找值:KeySet()先获取所有的key,然后遍历key的过程中,根据key找对应的value即可
(2).键值对:entrySet() 先获取所有的键值对对象,然后遍历得到每个键值对对象后,利用键值对对象提供的getKey()和getValue()方法获取数据即可;
(3).默认方法forEach :直接传递lambda即可,带两个形参,分别表示键和值;
小结
HashMap底层是哈希表结构的
依赖hashCode方法和equals方法保证键的唯一
如何键储存的是自定义对象,需要重写HashCode和equals方法
TreeMap集合
红黑树结构
要求key必须指定排序规则,依赖的是自然排序规则或者比较器规则
如果键存储的是自定义对象,需要实现compareable接口或者在创建Treemap对象时给出比较器排序规则
构造方法
(1).空参数构造方法
(2).带map集合的构造方法