nodejs大文件上传
nodejs大文件上传我用了两种方式来实现
先介绍写大文件上传的方式吧这里是用的分片上传,也就是前端通过slice方法将文件分成多片然后通过一个接口上传,传完之后在调用一个合并接口进行合并。
先上代码想用的直接用然后在进行讲解
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<script src="./axios.min.js">script>
head>
<body>
<input type="file" id="shangchuan">
<div id="jindu">div>
<script>
function upFile(obj, callback) {
let { file, urlUpload, urlMerge, slicingBig = 1024 } = obj
if (!file) return
var arrAxios = []
var slicingSize = 1024 * 1024 * slicingBig;//-----------------------------------------这里可以设置多大内存分成一片现在是1g
var slicingCount = Math.ceil(file.size / slicingSize); // 分片总数
var ext = file.name.split('.');
ext = ext[ext.length - 1]; // 获取文件后缀名
var random = Math.floor(Math.random() * (100 - 1)) + 1;
var hash = Date.now() + random + file.lastModified; // 文件 hash 实际应用时,hash需要更加复杂,确保唯一性,可以使用uuid
//创建数组代理来判断完成多久
var arr = new Proxy(new Array(slicingCount), {
set(target, key, value, receiver) {
var prose = 0;
target.forEach(item => {
if (item) {
prose += item
}
})
callback({ name: 'upload', value: (prose / slicingCount).toFixed(2), msg: "上传中" })
return Reflect.set(target, key, value, receiver);
},
get(target, key) {
return target[key];
}
})
for (let i = 0; i < slicingCount; i++) {
let start = i * slicingSize,
end = Math.min(file.size, start + slicingSize);
const form = new FormData();//通过formdata的方式提交
form.append('file', file.slice(start, end));
form.append('name', file.name);
form.append('total', slicingCount);
form.append('ext', ext);
form.append('index', i);
form.append('size', file.size);
form.append('hash', hash);
arrAxios.push(axios.post(urlUpload, form, {
onUploadProgress: progressEvent => {
let complete = (progressEvent.loaded / progressEvent.total * 100 | 0)
arr[i] = complete;
}
}));//这改成你的分片请求路径
}
axios.all(arrAxios).then(res => {
const data = {
name: file.name,
fileId:"2",
total: slicingCount,
ext,
hash
};
axios.post(urlMerge, data, {
onUploadProgress: progressEvent => {
let complete = (progressEvent.loaded / progressEvent.total * 100 | 0)
callback({ name: 'merge', value: complete, msg: "合并中" })
}
}).then((res) => {//这改成你的分片合并请求路径
callback({ name: 'ok', value: res.data, msg: "完成" })
}).catch((err) => {
callback({ name: 'err', value: err, msg: "失败" })
})
})
}
window.onload = function () {
var shangchuan = document.getElementById("shangchuan")
shangchuan.onchange = function () {
var file = document.getElementById("shangchuan").files[0];
upFile({
file,
urlUpload: "http://192.168.10.42:8089/newtrickle/upload_chunks",
urlMerge: "http://192.168.10.42:8089/newtrickle/merge_chunks",
},function(res){
console.log(res)
})
}
}
script>
body>
html>
nodejs(这里是buffer版本,下面还会有stream版本)(app.js)

var express = require('express');
const multer = require('multer');//这里是接收前端传的文件模块,可以开我之前的文章
const fs = require("fs");
var bodyParser = require("body-parser")
var app = express();
app.use(bodyParser.urlencoded({ extended: true }))
app.use(bodyParser.json())
app.use(multer().any());//上传任何文件
app.all("/*", function (req, res, next) {
// 跨域处理
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "*");
res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS");
res.header("Content-Type", "application/json;charset=utf-8");
next(); // 执行下一个路由
})
const chunksBasePath = '~uploads/';//创建虚拟文件路径
app.post('/newtrickle/upload_chunks', (req, res) => {
// 创建chunk的目录
const chunkTmpDir = chunksBasePath + req.body.hash + '/';
// 判断目录是否存在
if (!fs.existsSync(chunkTmpDir)) fs.mkdirSync(chunkTmpDir);
// 写切片文件
fs.writeFile(chunkTmpDir + req.body.index, req.files[0].buffer, function (err) {
if (err) {
console.log(err)
res.send({ status: -1, msg: "失败" })
} else {
res.send({ status: 200, msg: "成功" })
}
})
});
app.post('/newtrickle/merge_chunks', (req, res) => {//这里要规定前端传一些参数然后进行合并
const total = req.body.total;//这里是切片总数用来判断
const hash = req.body.hash;//这里是切片合并的名字
const fileId = req.body.fileId;//这里其实可以不要,只是我们当时要记录存到指定的id文件夹中方便我们后端调取指定的id文件
const name = req.body.name;//文件的名字
if (!fileId) res.send({ status: -1, msg: "失败请传文件id" })
const saveDir = "fileSave/" + fileId + "/" + new Date().toLocaleDateString().replace(/\//g, "-");
const savePath = saveDir + '/' + name;
const chunkDir = chunksBasePath + hash + '/';
try {
// 创建保存的文件夹(如果不存在)
if (!fs.existsSync("fileSave/" + fileId + "/")) fs.mkdirSync("fileSave/" + fileId + "/");
if (!fs.existsSync(saveDir)) fs.mkdirSync(saveDir);
// 创建文件
fs.writeFileSync(savePath, '');
// 读取所有的chunks 文件名存放在数组中
const chunks = fs.readdirSync(chunksBasePath + hash);
// 检查切片数量是否正确
if (chunks.length !== total || chunks.length === 0) return res.send({ code: -1, msg: '切片文件数量不符合' });
for (let i = 0; i < total; i++) {
// 追加写入到文件中
fs.appendFileSync(savePath, fs.readFileSync(chunkDir + '/' + i));
// 删除本次使用的chunk
fs.unlinkSync(chunkDir + '/' + i);
}
// 删除chunk的文件夹
fs.rmdirSync(chunkDir);
// 返回uploads下的路径,不返回uploads
res.json({ code: 0, msg: '文件上传成功',url: savePath});
} catch (err) {
console.log(err)
res.json({ code: -1, msg: '出现异常,上传失败' });
}
});
app.listen(8089);
所需要的依赖(只有三个)
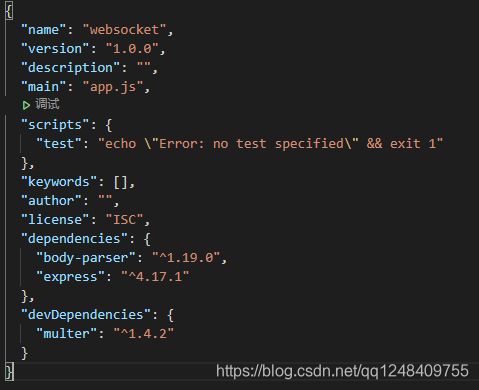
stream版本的(这个版本和上面的版本只有在合并的时候用的方式不同,这种会更快一些)
var express = require('express');
const multer = require('multer');
const fs = require("fs");
var bodyParser = require("body-parser")
var app = express();
app.use(bodyParser.urlencoded({ extended: true }))
app.use(bodyParser.json())
app.use(multer().any());//上传任何文件
app.all("/*", function (req, res, next) {
// 跨域处理
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "*");
res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS");
res.header("Content-Type", "application/json;charset=utf-8");
next(); // 执行下一个路由
})
const chunksBasePath = '~uploads/';//创建虚拟文件路径
app.post('/newtrickle/upload_chunks', (req, res) => {
// 创建chunk的目录
const chunkTmpDir = chunksBasePath + req.body.hash + '/';
// 判断目录是否存在
if (!fs.existsSync(chunkTmpDir)) fs.mkdirSync(chunkTmpDir);
// 写切片文件
fs.writeFile(chunkTmpDir + req.body.index, req.files[0].buffer, function (err) {
if (err) {
console.log(err)
res.send({ status: -1, msg: "失败" })
} else {
res.send({ status: 200, msg: "成功" })
}
})
});
app.post('/newtrickle/merge_chunks', async (req, res) => {
const total = req.body.total;
const hash = req.body.hash;
const fileId = req.body.fileId;
const name = req.body.name;
if (!fileId) res.send({ status: -1, msg: "失败请传文件id" })
const saveDir = "fileSave/" + fileId + "/" + new Date().toLocaleDateString().replace(/\//g, "-");
const savePath = saveDir + '/' + name;
const chunkDir = chunksBasePath + hash + '/';
try {
// 创建保存的文件夹(如果不存在)
if (!fs.existsSync("fileSave/" + fileId + "/")) fs.mkdirSync("fileSave/" + fileId + "/");
if (!fs.existsSync(saveDir)) fs.mkdirSync(saveDir);
// 创建文件
// 读取所有的chunks 文件名存放在数组中
const chunks = fs.readdirSync(chunksBasePath + hash);
var targetStream = fs.createWriteStream(savePath);//这里用了流的操作,创建一个写的流
// 检查切片数量是否正确
if (chunks.length !== total || chunks.length === 0) return res.send({ code: -1, msg: '切片文件数量不符合' });
for (let i = 0; i < total; i++) {
await mergeChunks(chunkDir + '/' + i,targetStream)//用下面的方法来解决异步的问题
}
fs.rmdirSync(chunkDir);
// 返回uploads下的路径,不返回uploads
res.json({ code: 0, msg: '文件上传成功', url: savePath });
} catch (err) {
console.log(err)
res.json({ code: -1, msg: '出现异常,上传失败' });
}
});
app.listen(8089);
function mergeChunks(path,targetStream){
return new Promise((resolve,reject)=>{
let originStream = fs.createReadStream(path);
originStream.pipe(targetStream, {end: false});//与写的流建立管道进行传输数据,这样的话就不会像buffer一样先把数据放在缓存里然后在写入文件,会比较快
originStream.on('end', function () {
// 删除文件
fs.unlinkSync(path);
resolve(true)
})
originStream.on("error",function(err){
reject(err)
})
})
}
注释写到了相应的代码上,小伙伴们有疑问的可以评论,希望对你们有帮助,有兴趣的可以在研究研究断点续传。