文件操作(Java)
一、File 类
1.认识 File
File 是 java.io.包下的类,File 类的对象, 用于代表当前操作系统的文件(可以是文件或文件夹)
注意:File 类只能对文件本身进行操作,不能读写文件里面存储的数据
2.创建对象
1)File 创建对象需要对应文件及文件夹的位置


public class Test {
public static void main(String[] args) {
// 对文件夹进行操作
File f1 = new File("C:\\Users\\HP\\Desktop\\Java");
System.out.println(f1.length()); // 4096
// 对不存在的文件或文件夹进行操作
File f2 = new File("C:\\Users\\HP\\Desktop\\Java\\abcdef.txt");
System.out.println(f2.length()); // 0
System.out.println(f2.exists()); // false
// 对文件进行操作
File f3 = new File("C:\\Users\\HP\\Desktop\\Java\\abc.txt");
System.out.println(f3.length()); // 3
// 以绝对路径接收工程模块下的文件
File f4 = new File("E:\\卷死你\\Java\\untitled\\JAVA\\src\\test1.txt");
System.out.println(f4.length()); // abcdefg -> 7
// 以相对路径接收工程模块下的文件
File f5 = new File("JAVA\\src\\test1.txt");
System.out.println(f5.length()); // 7
}
}注意:1)获取文件夹的大小时,不是获取的其包含内容的大小,而是文件夹本身的大小
2)File 类可以创建空地址的对象,并且可以判断该对象是否为空
3)绝对路径:从盘符开始
相对路径:不带盘符,默认到当前工程下的目录开始(路径不需要包含主工程模块)
2)File 类创建对象时可以识别三种形式的地址
public class Test {
public static void main(String[] args) {
File f1 = new File("C:\\Users\\HP\\Desktop\\Java\\abc.txt");
File f2 = new File("C:/Users/HP/Desktop/Java/abc.txt");
File f3 = new File("C:"+File.separator+"Users"+File.separator+"HP"+File.separator+"Desktop"+File.separator+"Java"+File.separator+"abc.txt");
}
}注意:第三种形式在多平台的转换中很实用,可以自动识别平台支持的路径分隔符
3. File 的常用方法
1)获取 File 对象的信息

public class Test {
public static void main(String[] args) {
File f1 = new File("C:\\Users\\HP\\Desktop\\Java\\abc.txt");
System.out.println(f1.exists()); // true
System.out.println(f1.isFile()); // true
System.out.println(f1.isDirectory()); // false
System.out.println(f1.length()); // 3
System.out.println(f1.getName());// abc.txt
long time = f1.lastModified();
System.out.println(time); // 1697543901214
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(time)); // 2023-10-17 19:58:21
File f2 = new File("JAVA\\src\\test1.txt");
System.out.println(f1.getPath()); // C:\Users\HP\Desktop\Java\abc.txt
System.out.println(f2.getPath()); // JAVA\src\test1.txt
System.out.println(f1.getAbsoluteFile()); // C:\Users\HP\Desktop\Java\abc.txt
System.out.println(f2.getAbsoluteFile()); // E:\卷死你\Java\untitled\JAVA\src\test1.txt
}
}注意:1)lastModified 方法返回的是时间毫秒值,需要用 SimpleDateFormat 对象转换
2)getPath 方法返回的是创建对象传入的路径,而 getAbsoluteFile 方法返回的是绝对路径
2)创建和删除文件或文件夹


public class Test {
public static void main(String[] args) throws IOException {
File f1 = new File("C:\\Users\\HP\\Desktop\\Java\\abcdefg.txt");
System.out.println(f1.createNewFile()); // 第一次为true,后为false
File f2 = new File("C:\\Users\\HP\\Desktop\\Java\\1");
System.out.println(f2.mkdir()); // 第一次为true,后为false
File f3 = new File("C:\\Users\\HP\\Desktop\\Java\\1\\2\\3\\4\\5");
System.out.println(f3.mkdirs()); // 第一次为true,后为false
System.out.println(f1.delete()); // 第一次为true,后为false
System.out.println(f2.delete()); // false
System.out.println(f3.delete()); // 第一次为true,后为false
}
}注意:delete 方法不能删除非空文件夹,而且删除的文件不会进入回收站
3)遍历目录下的一级文件或文件夹

public class Test {
public static void main(String[] args) throws IOException {
File f1 = new File("C:\\Users\\HP\\Desktop\\Java");
String[] names = f1.list();
for (String name : names) {
System.out.println(name);
}
File[] files = f1.listFiles();
for (File file : files) {
System.out.println(file.getAbsoluteFile());
}
}
}listFiles 方法的注意事项:
1)当主调是文件,或者路径不存在时,返回 null
2)当主调是空文件夹时,返回一个长度为0的数组
3)当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹的路径放在 File 数组中返回,包含隐藏文件
4)当主调是一个文件夹,但是没有权限访问该文件夹时,返回 null
4)深层文件搜索(递归)
先找出对应目录下的所有一级文件对象
遍历全部一级文件对象,判断是否是文件
如果是文件,判断是否是自己想要的
如果是文件夹,需要继续进入到该文件夹,重复上述过程
直到找到自己想要的文件,跳出递归
public class Test {
public static void main(String[] args) {
// 找到cc.txt这个文件
// 路径:C:\Users\HP\Desktop\Java\1\2\3\cc.txt
File f = new File("C:\\Users\\HP\\Desktop\\Java");
File result = dfs(f,"cc.txt");
System.out.println(result.getAbsoluteFile());
}
public static File dfs(File f,String name){
if(f.isFile()||!f.exists()||f == null){
return null;
}
File[] files = f.listFiles();
for (File file : files) {
if(file.isFile()){
if(file.getName().equals(name)){
return file;
}
}
else {
File result = dfs(file,name);
if(result == null){
continue;
}
else {
return result;
}
}
}
return null;
}
}4.补充:方法递归
1)认识方法递归
递归是一种算法,从形式上说,方法调用自身的形式称为方法递归
直接递归:方法自己调用自己
间接递归:方法调用其他方法,其他方法又回调方法自己
注意:递归如果没有控制好终止,会出现递归死循环,导致栈内存溢出错误。
2)应用1:求阶乘
public class Test {
public static void main(String[] args) {
System.out.println(func(5));
}
public static int func(int n){
if(n == 1){
return 1;
}
return n*func(n-1);
}
}5. 应用:清空文件夹
public class Test {
public static void main(String[] args) {
File f = new File("C:\\Users\\HP\\Desktop\\Java");
removeDir(f);
}
public static void removeDir(File f) {
if (!f.exists()||f == null)
return;
if(f.isFile()){
f.delete();
return;
}
File[] files = f.listFiles();
for (File file : files) {
if(file.isFile()){
file.delete();
}
else {
removeDir(file);
file.delete();
}
}
}
}注意:操作前要判断该文件对象是否为 null,因为Java读取某些文件可能会被系统限制,导致创建了一个空的文件对象
二、IO 流
1.补充知识:字符集
1)标准ASCII字符集
美国信息交换标准代码,包括了英文、符号等
标准ASCII使用1个字节存储一个字符,首位是0,总共可表示128个字符
2)GBK:汉字编码字符集(汉字内码扩展规范,国标)
包含了2万多个汉字等字符,一个中文字符编码成2个字节的形式存储,汉字的第一个字节的第一位必须是1
注意:GBK兼容了ASCII字符集
3)Unicode字符集
Unicode 是国际组织制定的,几乎容纳世界上所有文字、符号的字符集。
UTF- 8:是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节
其中,英文字符、数字等只占1个字节(兼容标准ASCII编码),汉字字符占用3个字节。
注意:1)字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码
2)英文,数字一般不会乱码,因为很多字符集都兼容了ASCII编码
4)字符集的编码和解码操作
编码:把字符按照指定字符集编码成字节

解码:把字节按照指定字符集解码成字符。

public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
String data = "a我m";
byte[] bytes1 = data.getBytes(); // 使用平台默认字符集(UTF-8)来编码
System.out.println(Arrays.toString(bytes1)); // [97, -26, -120, -111, 109]
byte[] bytes2 = data.getBytes("GBK");
System.out.println(Arrays.toString(bytes2)); // [97, -50, -46, 109]
String s1 = new String(bytes1); // 使用平台默认字符集(UTF-8)来解码
System.out.println(s1); // a我m
String s2 = new String(bytes2);
System.out.println(s2); // a��m
String s3 = new String(bytes2,"GBK");
System.out.println(s3); // a我m
}
}注意:在调用指定字符集的方法时,会抛出一个异常,以防止输入的字符集名称有误,需要在main 方法后抛出这个异常
2.认识 IO 流
IO 流是用于读写数据的(可以读写文件或网络等等中的数据)
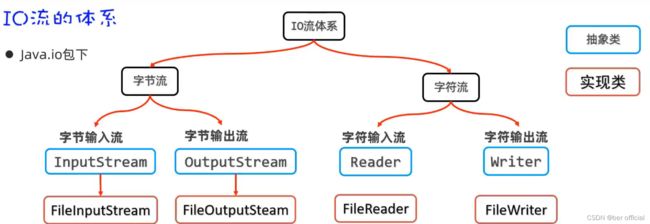
字节输入流:以内存为基准,来自磁盘文件/网络中的数据以字节的形式读入到内存中去的
字节输出流:以内存为基准,把内存中的数据以字节写出到磁盘文件/网络中去的流
字符输入流:以内存为基准,来自磁盘文件/网络中的数据以字符的形式读入到内存中去的流
字符输出流:以内存为基准,把内存中的数据以字符写出到磁盘文件/网络介质中去的流
注意:1)字节流适合操作所有类型的文件,如音频,视频,图片,文本文件的复制、转移等
2)字符流只适合操作一些纯文本的文件,如读写 txt、java 文件等
3. 流资源的释放方式
当程序在运行中出现异常时,程序会中断运行, 导致流资源无法正常释放,所以需要利用 try 语句来捕获异常,然后正常释放流
1)try - catch - finally
finally代码区:无论 try 中的程序是否出现异常,最后都一定会执行 finally 区,除非JVM终止
作用:一般用于在程序执行完成后进行资源的释放操作
public class Test {
public static void main(String[] args) {
try{
System.out.println(10/0);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("程序结束");
}
}
}注意:1)即使 try 区域有 return 语句,程序也依然会执行 finally 区
2)如果函数有返回值,则不要将返回语句写在 finally 区,这样会使函数无效化(只返回一个值)
3)通过 System.exit(0) 可以直接终止程序,跳过 finally 区
public class Test {
public static void main(String[] args) {
InputStream is = null;
OutputStream os = null;
try {
is = new FileInputStream("C:\\Users\\HP\\Desktop\\杂项\\文档\\生涯发展报告.docx");
os = new FileOutputStream("C:\\Users\\HP\\Desktop\\Java\\生涯发展报告.docx");
byte[] bytes = new byte[20*1024];
int len;
if((len = is.read(bytes))!=-1){
os.write(bytes,0,len);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
if(os != null) os.close();
if(is != null) is.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}注意:1)如果直接将流定义在 try 区里,会导致在 finally 无法读取到创建的流,所以需要在 try 区外先定义好空的流对象
2)如果在给流赋文件对象之前,出现了异常,则无需释放流,所以在调用 close 方法前要加条件
2)try with resource
在 try 后定义流,流资源使用完毕后,会自动调用其 close 方法,完成对资源的释放
public class Test {
public static void main(String[] args) throws Exception {
try ( InputStream is = new FileInputStream("C:\\Users\\HP\\Desktop\\杂项\\文档\\生涯发展报告.docx");
OutputStream os = new FileOutputStream("C:\\Users\\HP\\Desktop\\Java\\生涯发展报告.docx");
){
byte[] bytes = new byte[20*1024];
int len;
if((len = is.read(bytes))!=-1){
os.write(bytes,0,len);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}注意:1)try 后面只能定义流对象(资源对象)
2)流对象一般是实现了 AutoCloseable 接口,具有 close 方法的类对象
三、字节流
1. FileInputStream


1)每次只读取一个数据
public class Test {
public static void main(String[] args) throws Exception {
// File f = new File("JAVA\\src\\test1.txt");
// InputStream is = new FileInputStream(f);
InputStream is = new FileInputStream("JAVA\\src\\test1.txt");
// 文本内容为:abcdefg1234567
int b;
while((b = is.read()) != -1){
System.out.print((char)b); // abcdefg1234567
}
is.close();
}
}注意:1)使用 read 方法读取文件内容的效率极低
2)无法读取汉字,会直接出现乱码
3)InputStream 对象使用完毕后,一定要记得调用 close 方法来关闭,释放系统资源
2)每次读取一组数据
public class Test {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("JAVA\\src\\test1.txt");
// 文本内容为:abcdefg1234567
int len;
byte[] buffer = new byte[5];
while((len = is.read(buffer)) != -1){
// String rs = new String(buffer); // 错误结果:abcdefg12345673
String rs = new String(buffer,0,len); // 正确结果
System.out.print(rs);
}
is.close();
}
}注意:错误结果的出现,是因为重复的使用了同一个数组,最后一次存储时没有将数组全部占用,导致遗留了上次读取的数据
补充:汉字乱码问题
可以定义一个与文件一样大的字节数组,一次性读取完文件的全部字节,这样就不会出现汉字乱码
3)一次读取全部数据
public class Test {
public static void main(String[] args) throws Exception {
File f = new File("JAVA\\src\\test1.txt");
InputStream is = new FileInputStream(f);
// long length = f.length();
// byte[] buffer = new byte[(int) length];
// is.read(buffer);
// System.out.println(new String(buffer));
byte[] buffer = is.readAllBytes();
System.out.println(new String(buffer));
is.close();
}
}注意:1)readAllBytes 方法是JDK9之后出现的,需要注意,而且在调用此方法时,要保证该文件对象存在
2)当文本过大时,使用字节流会创建很大的字节数组,会导致内存溢出,一般情况下使用字符流更加合适
2. FileOutputStream


public class Test {
public static void main(String[] args) throws Exception {
// 写入模式,无视原文本内容,强制改为代码的文本操作
OutputStream os = new FileOutputStream("JAVA\\src\\test2.txt");
os.write(97);
os.write('b');
byte[] bytes = "我爱你".getBytes();
os.write(bytes);
os.write(bytes,3,3);
// 文本内容为:ab我爱你爱
os.close();
}
}public class Test {
public static void main(String[] args) throws Exception {
// 追加模式,在原文本内容之后,添加代码的文本操作
OutputStream os = new FileOutputStream("JAVA\\src\\test2.txt",true);
os.write("\r\n".getBytes());
os.write(97);
os.write('b');
byte[] bytes = "我爱你".getBytes();
os.write(bytes);
os.write(bytes,3,3);
// 文本内容为:ab我爱你爱
os.close();
}
}注意:1)OutputStream 可以对已存在的文件进行操作,也可以创建一个正确路径下的新输出流
2)如果想要输出换行符,建议使用 \r\n,多平台适用
3. 应用:文件复制
以复制一个文档为例
public class Test {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("C:\\Users\\HP\\Desktop\\杂项\\文档\\生涯发展报告.docx");
OutputStream os = new FileOutputStream("C:\\Users\\HP\\Desktop\\Java\\生涯发展报告.docx");
byte[] bytes = new byte[20*1024];
int len;
if((len = is.read(bytes))!=-1){
os.write(bytes,0,len);
}
// byte[] bytes = is.readAllBytes();
// os.write(bytes);
os.close();
is.close();
}
}四、字符流
1. FileReader


1)每次读取一个字符
public class Test {
public static void main(String[] args) throws Exception {
try ( Reader r = new FileReader("JAVA\\src\\test1.txt")
){
int index;
while((index = r.read())!= -1) {
System.out.println((char)index);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}2)每次读取一组字符
public class Test {
public static void main(String[] args) throws Exception {
try ( Reader r = new FileReader("JAVA\\src\\test1.txt")
){
char[] buffer = new char[3];
int len;
while((len = r.read(buffer)) != -1){
System.out.print(new String(buffer,0,len));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}2. FileWriter


写入模式 (不再演示追加模式~~)
public class Test {
public static void main(String[] args) throws Exception {
try (Writer w = new FileWriter("JAVA\\src\\test2.txt")){
w.write(97);
w.write('b');
w.write("\r\n");
w.write("我爱你");
w.write(new char[]{'我','爱','你'});
w.write("我爱你",0,2);
w.write(new char[]{'我','爱','你'},0,2);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}重点注意:字符输出流写出数据后,必须刷新流,或者关闭流,写出去的数据才能生效
public class Test {
public static void main(String[] args) throws Exception {
Writer w = new FileWriter("JAVA\\src\\test2.txt");
w.write(97);
w.write('b');
w.flush();
w.write("我爱你");
w.write(new char[]{'我','爱','你'});
// 最后只输出了ab
}
}五、缓冲流
1.认识缓冲流

作用:对原始流进行包装,以提高原始流读写数据的性能
2.字节缓冲流
原理:字节缓冲流在内存中自带一个8KB的字节缓冲池,先将要读取的文件拿到缓冲池里,再将其提取到对应的字节数组里(因为提取到数组的操作是在内存中操作,效率极高)

具体方法的使用和字节流相同
3.字符缓冲流
原理:字符缓冲流在内存中自带一个8K(8192)大小的字符缓冲池
1)BufferedReader

新增方法:读取一行的数据

public class Test {
public static void main(String[] args) throws Exception {
Reader fr = new FileReader("JAVA\\src\\test1.txt");
BufferedReader br = new BufferedReader(fr);
String s;
while((s = br.readLine())!=null){
System.out.println(s);
}
}
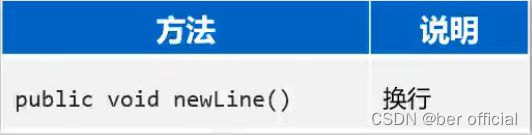
}2)BufferedWriter

新增方法:换行
public class Test {
public static void main(String[] args) throws Exception {
Writer fw = new FileWriter("JAVA\\src\\test2.txt");
BufferedWriter bw = new BufferedWriter(fw);
for(int i = 0;i<5;i++){
bw.write('a'+i);
bw.newLine();
}
bw.close();
fw.close();
}
}4.原始流与缓冲流的性能分析
这里不再演示测试代码,直接提出结论
1)在对较小的文件操作时,原始流和缓冲流的差别几乎没有
2)在对较大的文件操作时,原始流和缓冲流的差别很大(字节数组只开1K大小)
3)字节数组开8K大小时,原始流和缓冲流的差别大幅缩小
4)字节数组开32K大小时,原始流和缓冲流的差别几乎没有,原始流性能甚至超过缓冲流
5)字节数组再开大后,原始流和缓冲流性能提升微乎其微
六、字符转换流
1.认识字符转换流
如果代码编码和被读取的文本文件的编码是不一致的,使用字符流读取文本文件时就会出现乱码
2. InputStreamReader

public class Test {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("JAVA\\src\\test1.txt");
InputStreamReader isr = new InputStreamReader(is,"GBK");
BufferedReader br = new BufferedReader(isr);
String line;
while((line = br.readLine()) != null){
System.out.println(line);
}
}
}注意: InputStreamReader 和 FileReader 的方法基本上相同,也可以包装成 BufferedReader 对象
3. OutputStreamWriter

public class Test {
public static void main(String[] args) throws Exception {
OutputStream os = new FileOutputStream("JAVA\\src\\test2.txt");
OutputStreamWriter osw = new OutputStreamWriter(os,"GBK");
BufferedWriter bw = new BufferedWriter(osw);
bw.write("时间跨度abc");
bw.newLine();
bw.write("2131sada");
bw.close();
}
}七、其他流
1.打印流
作用:打印流可以实现更方便、更高效的打印数据(输出数据)
1)PrintStream
PrintStream 继承自字节输出流 OutputStream,支持写字节数据


public class Test {
public static void main(String[] args) {
try {
PrintStream ps = new PrintStream(new FileOutputStream("JAVA\\src\\test2.txt"),true,"GBK");
// PrintStream ps = new PrintStream("JAVA\\src\\test2.txt", Charset.forName("GBK"));
ps.println(97);
ps.print('a');
ps.print('b');
ps.println('c');
ps.write(97);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}2)PrintWriter
PrintWriter 继承自字符输出流 Writer,支持写字符数据


public class Test {
public static void main(String[] args) {
try {
PrintWriter pw = new PrintWriter(new FileOutputStream("JAVA\\src\\test2.txt",true));
pw.println(97);
pw.print('a');
pw.print('b');
pw.println('c');
pw.write(97);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}注意:上述表格有误,PrintWriter 的最后一种构造器指定字符编码集,不能使用 String 类型,需要用 Charset 类型
3)应用:输出语句的重定向
使用 System.setOut 方法,将 sout 方法的输出定向在文件中
public class Test {
public static void main(String[] args) {
System.out.println("abc");
try {
PrintStream ps = new PrintStream(new FileOutputStream("JAVA\\src\\test2.txt"));
System.setOut(ps);
System.out.println("abcs");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}注意:System.setOut 方法只能接收 PrintStream 对象
2.数据流
对数据及其类型同时进行读取和输出操作
1)DataInputStream
DataInputStream 继承自字节输入流 InputStream,支持写字节数据


2)DataOutputStream
DataOutputStream 继承自字节输出流 OutputStream,支持写字节数据


public class Test {
public static void main(String[] args) {
try ( DataOutputStream dos = new DataOutputStream(new FileOutputStream("JAVA\\src\\test3.txt"));
DataInputStream dis = new DataInputStream(new FileInputStream("JAVA\\src\\test3.txt"))
){
dos.writeInt(99);
dos.writeDouble(99.9);
dos.writeBoolean(true);
dos.writeUTF("奶奶滴");
dos.flush();
System.out.println(dis.readInt()); // 99
System.out.println(dis.readDouble()); // 99.9
System.out.println(dis.readBoolean());// true
System.out.println(dis.readUTF()); // 奶奶滴
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}注意:写入后的文本内容基本上是一段乱码,这是因为数据流本身将数据和类型同时导入,有独特的编码形式,只能数据输出流和数据输入流相互配合使用
3.序列化流
1)ObjectInputStream
用于对象反序列化:把文件里的 Java对象读出来


2)ObjectOutputStream
用于对象序列化:把 Java对象写入到文件中去


class People implements Serializable{
private String name;
// 该成员变量不参与序列化
private transient int age;
public People() {}
public People(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {return name;}
public void setName(String name) {this.name = name;}
public int getAge() {return age;}
public void setAge(int age) {this.age = age;}
@Override
public String toString() {
return "People{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class Test {
public static void main(String[] args) {
try ( ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("JAVA\\src\\test4.txt"));
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("JAVA\\src\\test4.txt"))
){
People p = new People("cxk",18);
oos.writeObject(p);
System.out.println(ois.readObject()); // People{name='cxk', age=0}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}注意:1)如果要将对象序列化,那么其对应的类要实现 Serializable 接口(序列化标记接口)
2)如果不想使对象的某一成员变量序列化,则可以在类中将该成员变量用 transient 修饰,如上述代码,反序列化后读取的对象 age 的值为0,证明age变量没有被序列化
补充:一次序列化多个对象
用一个ArrayList集合存储多个对象,然后直接对集合进行序列化即可
注意:ArrayList集合已经实现了序列化接口
八、IO框架
1.认识框架
用于解决某类问题,编写的一套类、接口等(可以理解成半成品程序),大多框架都是第三方研发的
好处:在框架的基础上开发,可以得到优秀的软件架构,能提高开发效率
框架的形式:一般是把类、接口等编译成 class 形式,再压缩成一个 jar 结尾的文件发行出去
2.认识IO框架
封装了 Java 提供的对文件、数据操作的代码,对外提供了更简单的方式来对文件进行操作,对数据进行读写等
1)Commons-io
是 apache 开源基金组织提供的一组有关IO操作的小框架,目的是提高IO流的开发效率


3.使用框架
1)下载框架,并整合到编译环境中
以导入 Commons-io 框架为例:
在项目中创建一个文件夹:lib
将 commons-io-2.14.jar 文件复制到 lib 文件夹
在 jar 文件上点右键,选择 Add as Library -> 点击OK
2)然后可以直接使用框架所提供的类和接口
九、特殊文本文件操作
1.认识特殊文本文件
如 Properties 属性文件、XML 文件等
作用:1)存储有关系的数据,做为系统的配置文件
2)作为信息进行传输
2. Properties 属性文件
1)特点:1)与 Map 双列集合特点类似,内容只能是键值对,且键不能重复
2)文件后缀一般是 .properties 结尾
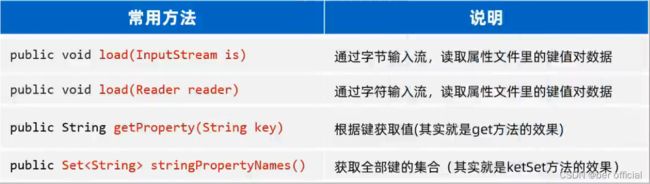
2)Properties 类
是一个Map集合(键值对集合),但是一般不会当集合使用
作用:Properties 是用来代表属性文件的,通过 Properties 可以读写属性文件里的内容

public class Test {
public static void main(String[] args) {
Properties properties = new Properties();
try {
properties.load(new FileReader("JAVA\\src\\Practice6\\User.properties"));
System.out.println(properties); // {wyb=10, cxk=20, fzc=40, zth=30}
System.out.println(properties.getProperty("cxk")); // 20
Set keys = properties.stringPropertyNames();
for (String key : keys) {
System.out.println(key + "=" +properties.getProperty(key));
}
properties.forEach((k,v) -> System.out.println(k+"="+v));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
} 注意:1)proerties 类具有和 Map 集合一样的特点,无序无索引
2)如果读取的文件是 txt 文件,如果其内容格式与 proerties 文件相同,则也可以使用 proerties 类的操作

public class Test {
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.setProperty("cxk","10");
properties.setProperty("wyb","30");
properties.setProperty("cxk","20");
properties.setProperty("fzc","22");
properties.store(new FileOutputStream("JAVA\\src\\Practice6\\User.properties"),
"name=age");
}
}注意:1)如果传入的键有重复,只传入最后的数据
2)store 方法必须写入一段注释,这是书写 Properties 属性文件的要求
3. XML
1)认识 XML
XML,可拓展标记语言
作用:本质是一种数据格式,可以存储复杂的数据结构和数据关系
应用场景:经常用来做为系统的配置文件,或者作为一种特殊的数据结构,在网络中进行传输
特点:1)XML中的<标签名>被称为一个标签或一个元素,一般是成对出现的
2)XML中的标签名可以自己定义(可扩展) ,但必须要正确的嵌套
3)XML中只能有一个根标签
4)XML中的标签后可以定义属性
5)如果一个文件中放置的是XML格式的数据,这个就是XML文件,后缀一般要写成 .xml
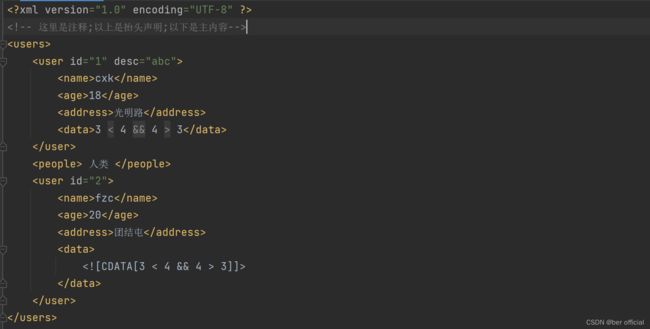
语法规则:1)XML文件的后缀名为:xml,文档声明必须是第一行
2)XML中可以定义注释信息:
3)XML中书写”<”、“&” 等字符时,可能会出现错误,此时可以用一些特殊字符替代 

4)XML中可以写CDATA数据区:,其中内容不限
2)解析XML文件(Dom4j)
使用Java中的原始IO流来解析XML框架不方便,所以这里使用 Dom4j 框架来操作
文档对象模型:对XML文件进行以下操作

SAXReader:Dom4j 框架提供的解析器
Document:SAXReader 解析器获取的文件对象
Element: Document 文件对象下的元素
public class Test {
public static void main(String[] args) throws Exception {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read("JAVA\\src\\Practice6\\hello_world.xml");
Element root = document.getRootElement();
System.out.println(root.getName());
List elements = root.elements();
for (Element element : elements) {
System.out.println(element.getName()+"->"+element.elementText("name"));
}
Element element1 = root.element("people");
System.out.println(element1.getName()); // people
System.out.println(element1.getText()); // 人类 (有空格)
System.out.println(element1.getTextTrim()); // 人类(无空格)
List elements1 = root.elements("user");
for (Element element : elements1) {
System.out.println(element.attributeValue("id"));
Attribute a = element.attribute("id");
System.out.println(a.getName()+"->"+a.getValue());
List attributes = element.attributes();
for (Attribute attribute : attributes) {
System.out.println(attribute.getName()+"->"+attribute.getValue());
}
}
}
} 注意:1)在使用 element 方法获取指定的子元素时,如果有多个重名的子元素,默认获取第一个
2)可以使用 elements 方法来获取多个重名的子元素,返回一个 List 集合
3)使用 attribute 方法可以获取指定的 Attribute 对象,使用 attributes 方法可以获取全部Attribute 对象,返回一个 List 集合
4)如果使用 elementText 或 getText 方法获取文本内容,可能字符串首尾包含一些没有意义的空格,这时可以使用 elementTextTrim 或 getTextTrim 方法来得到首尾没有空格的字符串
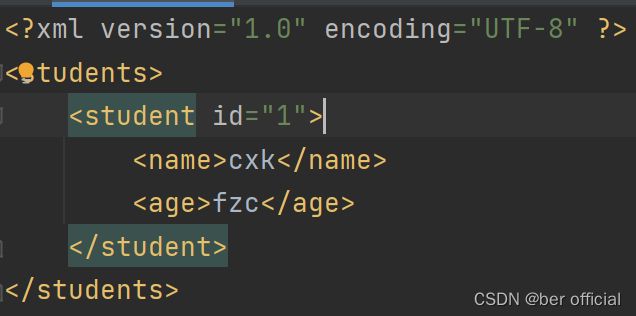
3)写入XML文件
不建议用 Dom4j 做,推荐直接把程序里的数据拼接成XML格式,然后用IO流写出去
public class Test {
public static void main(String[] args){
StringBuilder sb = new StringBuilder();
sb.append("\r\n");
sb.append("").append("\r\n");
sb.append("\t").append("").append("\r\n");
sb.append("\t\t").append("").append("cxk").append(" ").append("\r\n");
sb.append("\t\t").append("").append("fzc").append(" ").append("\r\n");
sb.append("\t").append(" ").append("\r\n");
sb.append(" ").append("\r\n");
try ( BufferedWriter bw = new BufferedWriter(new FileWriter("JAVA\\src\\Practice6\\Student.xml"))){
bw.write(sb.toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
十、日志技术
1.认识日志
作用:方便程序员定位bug,并了解程序的执行情况等
特点:1)把程序运行的信息记录到指定位置中,如控制台、文件、数据库等,
2)可以随时以开关的形式控制日志的启停,无需到源代码中去进行修改
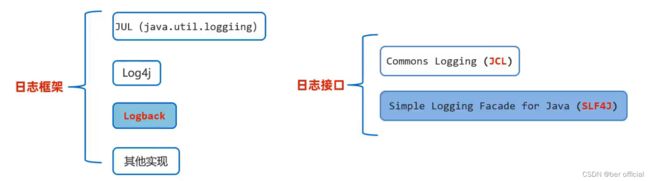
最常用的是 Logback 框架,它是基于 slf4j 日志规范实现的
2. Logback 框架
1)导入 Logback 框架到项目中去(slf4j-api、logback-core、logback-classic)
2)将 Logback 框架的核心配置文件 logback.xml 直接拷贝到 src 目录下(必须是 src 下)
3)创建 Logback 框架提供的 Logger 对象,然后用 Logger 对象调用其提供的方法就可以记录系统的日志信息![]()
public class Test {
public static final Logger LOGGER = LoggerFactory.getLogger("LogBackTest");
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
try {
LOGGER.info("程序开始运行~~");
int a = sc.nextInt();
int b = sc.nextInt();
func(a,b);
LOGGER.info("程序运行成功~~");
} catch (Exception e) {
LOGGER.error("程序运行失败~~");
}
}
public static void func(int x,int y){
LOGGER.debug("参数1:"+x);
LOGGER.debug("参数2:"+y);
System.out.println(x/y);
}
}注意:1)在创建 Logger 对象时,要注意不要创建成 java 自带的 Logger 对象
2)在主程序中可以使用 info 方法记录首尾,程序运行失败用 error 记录,在方法中用 debug 记录
3. logback.xml 核心配置文件
作用:对 logback 日志框架进行控制
1)可以设置2个输出日志的位置:控制台、系统文件![]()
![]()
2)控制开启日志(ALL)、取消日志(OFF)

3)设置日志级别
日志级别指的是日志信息的类型,日志都会分级别
常见的日志级别如下(优先级从低到高):


注意:只有日志的级别是大于或等于核心配置文件配置的日志级别,才会被记录,否则不记录