大模型轻量化技术调研
笔记,仅供参考,未完
大模型轻量化技术调研
- 1. 调研论文
-
- 1.1 汇总
- 1.2 详细介绍
-
- MODEL COMPRESSION VIA DISTILLATION AND QUANTIZATION
- LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Successive Pruning for Model Compression Via Rate Distortion Theory
- Towards a Unified View of Parameter-Efficient Transfer Learning
- DeepSpeed
- 2. 数据集&benchmark
-
- 2.1 数据集
- 2.2 benchmark
- 3. 实验与方法
-
- MODEL COMPRESSION VIA DISTILLATION AND QUANTIZATION
- LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Successive Pruning for Model Compression Via Rate Distortion Theory
- Towards a Unified View of Parameter-Efficient Transfer Learning
- 实验相关指标
- 4. 工具整理
- 5. 附录
1. 调研论文
1.1 汇总
| id | title | label | time | conclusion |
|---|---|---|---|---|
| 1 | MODEL COMPRESSION VIA DISTILLATION AND QUANTIZATION | 大模型轻量化技术 | 介绍两种模型压缩方式,分别是在深度上进行压缩的量化蒸馏方法,和在宽度上进行压缩的可微量化法 | |
| 2 | LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS | 大模型轻量化技术 | 通过对大型语言模型进行低秩适应来加快模型的微调。由于低秩表示比原始模型小得多,因此适应特定任务或领域所需的时间大大减少 | |
| 3 | Successive Pruning for Model Compression Via Rate Distortion Theory | 大模型轻量化技术 | 通过研究神经网络压缩问题,从Rate-Distortion理论的角度来看待压缩比和神经网络性能之间的关系。它提出了一种新的压缩方法,称为successive-pruning, | |
| 4 | Towards a Unified View of Parameter-Efficient Transfer Learning | 大模型轻量化技术 | ||
| 5 | DeepSpeed | 大模型轻量化 | 2023/4 |
1.2 详细介绍
MODEL COMPRESSION VIA DISTILLATION AND QUANTIZATION
- 量化蒸馏
该部分在深度方面进行复合压缩,提炼出一个较浅的student-model,使其精度和较深的teacher-model相似
利用蒸馏损失来训练一个量化的学生网络。它的目标是利用蒸馏损失在训练过程中,通过将蒸馏损失(相对于教师网络)结合到一个较小的学生网络的训练中,来压缩学生网络的权重。这种方法使用投影梯度下降,在全精度训练中进行梯度下降步骤,然后将新参数投影到有效解集合中。在每次投影步骤中,累积误差累积到下一步的梯度中。

- 可微量化
该部分在宽度方面进行压缩,将student-model的weight量化到一组有限整数水平,并且让student-model的每一层weight参数量更少
它通过利用非均匀量化点的位置来提高量化神经网络的准确性。它使用非均匀量化函数,试图找到一组量化点 p p p,使得使用 Q ( v p ) Q(vp) Q(vp)量化模型时准确性损失最小。关键的观察是,我们可以使用随机梯度下降来找到这组 p p p,因为我们能够计算 Q Q Q关于 p p p的梯度。该算法通过SGD或类似方法更新量化点。

LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
用于使大型预训练语言模型(如 GPT-3 和 GPT-2)适应特定的任务或领域。随着预训练模型大小的增加,微调所有模型参数的传统方法变得不可行。LoRa 冻结了预训练的模型权重,并将可训练的等级分解矩阵注入到 Transformer 架构的每一层,从而大大减少了下游任务的可训练参数的数量。
对于预训练好的模型参数冻结,在微调训练中不改变,设计专用于微调训练的低秩矩阵注入到Transformer架构的每一层以减少训练参数

(仅个人理解)如图,预训练好的矩阵 W ∈ R d ∗ d W∈R^{d*d} W∈Rd∗d冻结,有两个低秩矩阵 A A A和 B B B。在fine-tune过程中,输入 x x x分别传入已经预训练好的模型W和用于微调的低秩矩阵 A A A、 B B B中分别计算,并且将二者的输出相加。损失仅返回给低秩矩阵进行学习,而预训练好的模型参数保持不变。
损失仅传递给低秩矩阵进行学习的过程称为低秩适应
具体来说,假设预训练矩阵 W 0 ∈ R d ∗ k W_0∈R^{d*k} W0∈Rd∗k(图中画的是d*d),其更新可表示为 W 0 + Δ W = W 0 + B A , B ∈ R d ∗ r , A ∈ R r ∗ k W_0+ΔW=W_0+BA , B∈R^{d*r},A∈R^{r*k} W0+ΔW=W0+BA,B∈Rd∗r,A∈Rr∗k, 其中秩 r < < m i n ( d , k ) r<
Successive Pruning for Model Compression Via Rate Distortion Theory
-
successive pruning 连续修剪
(1) 对指数源进行压缩的原因
由于对NN权重分布进行分析,(a)图可看出权重可以用高斯分布或者拉普拉斯分布进行估计,这里选用拉普拉斯分布。
u ∼ f L ( u ; μ , b ) ⇒ ∣ u − μ ∣ ∼ f e x p ( u ; 1 / b ) 。 u ∼ f_L(u; μ, b) ⇒ |u − μ| ∼ f_{exp}(u; 1/b)。 u∼fL(u;μ,b)⇒∣u−μ∣∼fexp(u;1/b)。
且拉普拉斯分布有上述特点,使之可以用指数分布对无符号权重进行处理(图b)。所以本文分析无符号权重,即对指数源进行压缩(有些扰动可能会对权重的符号造成错误,所以分析无符号权重更为精确)

(2)loss compress 有损压缩
对具有指数分布的独立同分布源序列进行压缩,同时保持一定的失真度量。作者研究了如何使用one-side l 1 l1 l1失真度量来衡量压缩后的数据与原始数据之间的差异。
他们提出了一种启发式编码方案,可以在不生成随机码字或计算每次迭代中U(t-1)和V(t)之间的失真度的情况下实现压缩。这种方法可以有效地对具有指数分布的数据进行压缩,同时保持一定的失真度量。这种能够通过迭代地减少重构序列中的非零元素来减少数据的表示大小。在每次迭代中,算法都会找到满足 U ( t − 1 ) > = λ 1 / t − 1 U(t-1)>=λ_{1/t-1} U(t−1)>=λ1/t−1的索引 i i i,并将其对应的元素减少 λ 1 / t − 1 λ_{1/t-1} λ1/t−1。这样,随着迭代次数的增加,重构序列中的非零元素会逐渐减少,最终变得稀疏 (稀疏性sparsity:序列中非零元素的个数占比)

(3) lossless compress 无损压缩
在每次迭代的信息传递过程中,需要从encoder向decoder传递index信息,如果采用熵编码对index进行无损压缩,效率更高
(4) successive pruning
每个successive pruning包含loss compress和lossless compress两个部分,Decoder2同时获得m1和m2,故Decoder2用 D 2 D_2 D2重建 U 2 n U_2^n U2n时,其性能要词语Decoder1,但是这种方式可以更好地权衡rate和distortion之间的关系。
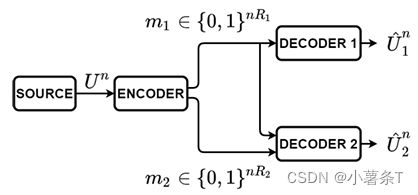
-
使用successive pruning对模型进行压缩
对于修剪模型进行微调以调整未修剪权重是一种广泛接受的做法,本文也使用这种做法
(1) PHASE 1
将successive pruning应用于未修剪的权重 w w w,直到达到所需的稀疏度s(s=稀疏度不增加的时候对应的s)
(2) PRUNING MASK
根据重构weight中非零元素的位置,构造掩码mask: ∧ w i > 0 时, M p , i = 1 ^\wedge w_i>0时,M_{p,i}=1 ∧wi>0时,Mp,i=1,再用mask对原始权重进行修建,的 w p r u n e d = M p ⊙ w w_{pruned}=M_p\odot w wpruned=Mp⊙w
(3) RETRAINING
通过 w p r u n e d w_{pruned} wpruned进行retrain,获得重训练后的权重 w r e t r a i n e d w_{retrained} wretrained
(4) PHASE 2
在重置重构权重w = 0之后,我们开始第二阶段。在第二阶段,我们对具有稀疏度s的wretrained应用successive pruning。在第二阶段结束时,我们获得了一个稀疏性下限为s的重构权重w。
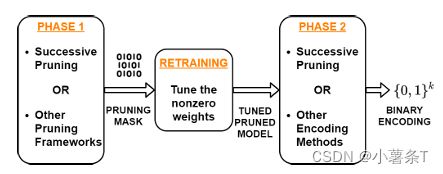
总之,第一阶段输出一个修剪掩码,用于修剪模型;而第二阶段致力于找到修剪并再训练模型的二进制表示。通过这种两阶段方法,连续修剪始终优于现有的修剪策略 -
使用successive pruning对federal learning进行压缩
Towards a Unified View of Parameter-Efficient Transfer Learning
DeepSpeed
-
what is DeepSpeed
DeepSpeed是一个开源深度学习训练优化库,其中包含的一个新的显存优化技术—— ZeRO(零冗余优化器),通过扩大规模,提升速度,控制成本,提升可用性,极大地推进了大模型训练能力。DeepSpeed 已经帮助研究人员开发了图灵自然语言生成模型( Turing-NLG),其在发表时为世界上最大的语言模型(拥有 170 亿参数),并有着最佳的精度。
DeepSpeed的核心就在于,GPU显存不够,CPU内存来凑
在数据并行做了节省内存的创新:1,对optimizer 阶段的重构,从原来上来就allreduce,各个节点都保持一份weight, gradient以及adam 需要mean, var等,变成只在一个节点保存,通信变成了reduce和broadcast;2,各个层次的参数生命周期不重叠,每个节点仅保存计算时需要的参数。 -
contributions
用 3D 并行化实现万亿参数模型训练: DeepSpeed 实现了三种并行方法的灵活组合:ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。此外,其提高的通信效率使用户可以在网络带宽有限的常规群集上以 2-7 倍的速度训练有数十亿参数的模型。
ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型: 为了同时利用 CPU 和 GPU 内存来训练大型模型,我们扩展了 ZeRO-2。我们的用户在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,并保持有竞争力的吞吐量。此功能使数十亿参数的模型训练更加大众化,,并为许多深度学习从业人员打开了一扇探索更大更好的模型的窗户。
通过 DeepSpeed Sparse Attention 用6倍速度执行10倍长的序列: DeepSpeed提供了稀疏 attention kernel ——一种工具性技术,可支持长序列的模型输入,包括文本输入,图像输入和语音输入。与经典的稠密 Transformer 相比,它支持的输入序列长一个数量级,并在保持相当的精度下获得最高 6 倍的执行速度提升。它还比最新的稀疏实现快 1.5–3 倍。此外,我们的稀疏 kernel 灵活支持稀疏格式,使用户能够通过自定义稀疏结构进行创新。
1 比特 Adam 减少 5 倍通信量: Adam 是一个在大规模深度学习模型训练场景下的有效的(也许是最广为应用的)优化器。然而,它与通信效率优化算法往往不兼容。因此,在跨设备进行分布式扩展时,通信开销可能成为瓶颈。我们推出了一种 1 比特 Adam 新算法,以及其高效实现。该算法最多可减少 5 倍通信量,同时实现了与Adam相似的收敛率。在通信受限的场景下,我们观察到分布式训练速度提升了 3.5 倍,这使得该算法可以扩展到不同类型的 GPU 群集和网络环境。 -
How to use
将DeepSpeed训练框架应用于模型的方法:https://zhuanlan.zhihu.com/p/256236705
github地址:https://github.com/microsoft/DeepSpeed -
直接使用DeepSpeed Chat做代码修复模型
2. 数据集&benchmark
2.1 数据集
| id | dataset | 说明 |
|---|---|---|
| 1 | CIFAR-10数据集 | CIFAR-10数据集是一个用于计算机视觉和机器学习的常用基准测试数据集。它包含60000张32x32像素的彩色图像,分为10个类别,每个类别有6000张图像。其中50000张图像用于训练,10000张图像用于测试。数据集被分为5个训练批次和1个测试批次,每个批次包含10000张图像。测试批次包含每个类别精确选择的1000张图像 |
| 2 | OpenNMT 集成测试数据集 | 包含 200K 个训练句子和 10K 个用于德英翻译任务的测试句子 |
| 3 | WMT13 翻译数据集 | WMT13翻译任务的重点是欧洲语言对。翻译质量将在一个共享的、未见过的新闻故事测试集上进行评估。我们提供了一个平行语料库作为训练数据,一个基线系统和可供下载的其他资源 |
| 4 | ImageNet Dataset | 计算机视觉数据集,它包含超过1400万张标注的图像,涵盖了超过2万个类别 |
| 5 | GLUE基准测试集 | 是一个用于评估自然语言理解模型的基准测试集。它包含了多个不同的自然语言理解任务,如文本蕴含、情感分析和语义相似性等。包含的任务有MNLI SST-2 MRPC CoLA QNLI QQP RTE STS-B |
2.2 benchmark
| id | benchmark | 说明 |
|---|---|---|
| 1 | PM Quant | post-mortem量化,这种方法在训练后对权重进行均匀量化,而不进行任何其他操作。它可以与分桶一起使用,也可以不使用分桶 |
3. 实验与方法
MODEL COMPRESSION VIA DISTILLATION AND QUANTIZATION
https://github.com/antspy/quantized_distillation
-
在CIFAR-10数据集上进行的实验结果

它比较了不同模型(包括全精度模型、量化模型和基于蒸馏的模型)的准确性。
2bit、4bit和8bit指的是用来表示量化模型权重的位数。例如,一个2bit模型只使用2位来表示每个权重,从而显著减小了模型大小。表格显示,即使使用这样低的位精度,量化模型也能达到高准确性水平,特别是当与基于蒸馏的方法结合使用时。
论文中的表 1 列出了 CIFAR-10 数据集的实验结果,比较了不同模型的性能。其中teacher-model有5.3Mparam,模型大小21M,准确率89.71%。表格内对不同大小的student-model分别进行全精度训练,PM Quant不带桶, PM Quant带桶, 量化蒸馏, 全微量训练
总体而言,表 1 全面评估了所提出的方法及其在资源受限环境中压缩深度神经网络的有效性。 -
在OpenNMT数据集上的实验结果
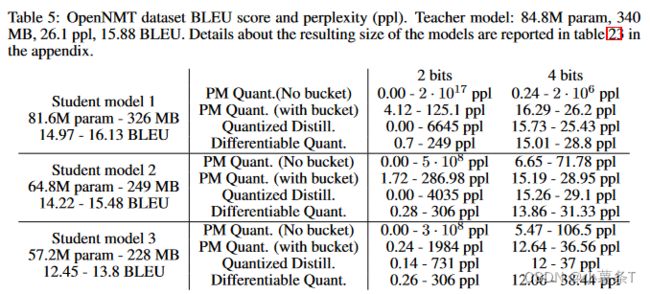
比较了不同模型在翻译任务上困惑度大小
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
https://github.com/microsoft/LoRA
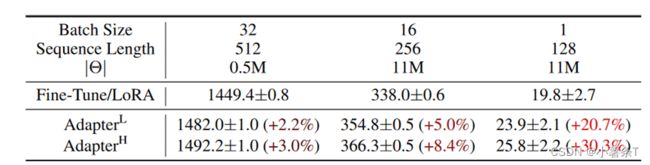
这张表没看懂……以下仅个人理解……TAT
上表为在GPT-2 模型中单次前向传递的推理延迟(以毫秒为单位测量,平均超过 100 次试验)
前两行是语言模型的批数和数据处理的最大序列长度,第三行 ∣ θ ∣ |θ| ∣θ∣是使用LoRA后的模型参数大小。第四行Fine-Tune/LoRA是全微调相比于LoRA微调的推理延迟倍数比(百分比)。
LoRA 的可训练参数明显少于完全微调,这降低了计算硬件要求。
LoRA 的训练吞吐量高于完全微调,这意味着可以更快地训练。
总体而言,表 1 显示,Low-Rank Adaption 是使大型预训练语言模型适应特定任务或领域的有前途的方法,因为与完全微调相比,在可训练参数明显减少、训练吞吐量更高的情况下,它可以实现与完全微调相当或更好的性能。
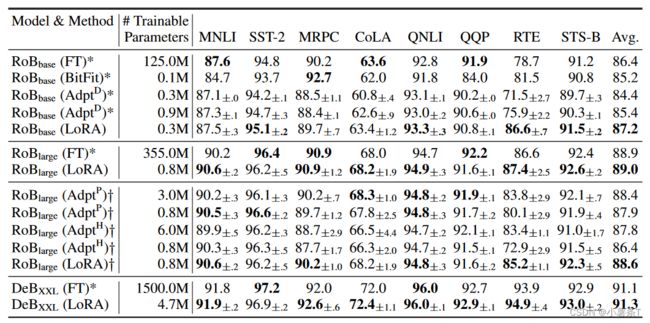
该表展示了不同大模型( R o B b a s e RoB_{base} RoBbase、 R o B l a r g e RoB_{large} RoBlarge、 D e B X X L DeB_{XXL} DeBXXL)上分别使用LoRA和其他baseline压缩(FT,BitFit,AdptD等)后的参数大小,以及分别在GLUE基准测试及上的结果。
可以看出绝大部分测试中,采用LoRA的效果甚至比全微调更好

GPT-2 medium (M) 和 large (L) 在 E2E NLG Challenge 上采用不同的适应方法。对于所有指标,越高越好。 LoRA 在可训练参数相当或更少的情况下优于几个基线。
Successive Pruning for Model Compression Via Rate Distortion Theory
https://github.com/xxx/SuccessivePruning
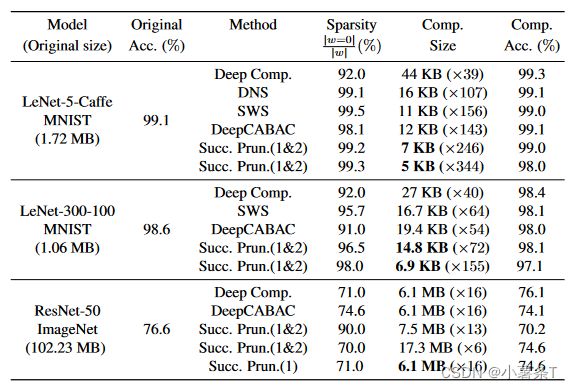
连续修剪与其他修剪策略在准确性、稀疏性和大小方面的比较。Succ.Prun.(1&2):两个阶段都使用连续剪枝;Succ.Prun.(1): phase-1的连续剪枝+phase-2的CSR和Huffman
Successive Pruning在保持模型原有准确性的同时,在MNIST数据集上使用LeNet-5-Caffe和LeNet-300-100架构实现了高压缩率。然而,对于ImageNet数据集上的ResNet-50,Successive Pruning提供的内存效率并不高于以前的工作。

上图比较了Successive Pruning与Magnitude Pruning在准确性-稀疏性权衡方面的表现,使用了ImageNet和CIFAR-10数据集上的ResNet-50、ResNet-18和小型VGG-16架构。x轴显示了剪枝模型的稀疏度,y轴显示了剪枝模型的测试准确性。该图表明,在相同的稀疏度约束下,Successive Pruning始终比Magnitude Pruning实现更好的测试准确性。Successive Pruning的改进在更高的稀疏率下更为明显。例如,在CIFAR-10上,VGG-16的95%稀疏度下,Magnitude Pruning的测试准确率为10%(随机预测),而Successive Pruning在相同稀疏度下实现了90%的准确率。
Towards a Unified View of Parameter-Efficient Transfer Learning
https://github.com/jxhe/unify-parameter-efficient-tuning
实验相关指标
| id | benchmark | 说明 |
|---|---|---|
| 1 | BLEU score | BLEU分数(双语评估替补)是一种用于评估从一种自然语言机器翻译成另一种自然语言的文本质量的算法。质量被认为是机器输出与人类输出之间的对应关系:“机器翻译越接近专业人类翻译,就越好”——这是BLEU背后的核心思想。它总是在0和1之间输出一个数字,这个值表示候选文本与参考文本之间的相似程度,值越接近1表示文本越相似。 |
| 2 | perplexity(ppl) | 困惑度(perplexity)是信息论中用来衡量概率分布或概率模型预测样本的能力的一种度量。它可以用来比较概率模型。低困惑度表明概率分布在预测样本方面表现良好。 |
4. 工具整理
| id | title | description |
|---|---|---|
| 1 | *** | *** |
5. 附录
-
Teacher Model & Student Model
(1) Teacher Model: 大而复杂的模型,已经在数据集中进行训练,并且达到高精度
(2) Student Model: 更小更简单的模型,学习teacher model的输出分布,模仿teacher model的行为 -
Quantization Distillation 量化蒸馏
将NN params从高精度浮点数(全精度模型)变为低比特宽度的定点数(低精度模型) -
量化误差 & 蒸馏损失
(1) 量化误差: 在量化过程产生的误差,比如原精度为3.42,量化为3或者3.4,则产生误差
(2) 蒸馏损失: 是指在知识蒸馏过程中,用来衡量学生网络输出与教师网络输出之间差距的损失函数。常用的蒸馏损失函数是KL散度损失函数
学生网络的损失函数通常由两部分组成:一部分是蒸馏损失,用来衡量学生网络输出与教师网络输出(软目标)之间的差距;另一部分是交叉熵损失,用来衡量学生网络输出与正确标签之间的差距。 -
Scaling Bucketing 缩放分桶
针对量化过程中量级不平衡的情况,此时使用单一缩放因子会出问题。
使用bucketing将向量分成固定大小的同,每个桶应用缩放函数
-
均匀量化&不均匀量化
均匀量化是指量化点之间的间隔相等,而不均匀量化则允许量化点之间的间隔不相等。
这两种方法的区别在于它们如何处理数据的分布。如果数据分布均匀,则使用均匀量化可能更合适;如果数据分布不均匀,则使用不均匀量化可能更合适,因为它可以更好地适应数据的分布。 -
随机量化
随机量化是一种量化方法,它通过概率舍入来量化数据。与确定性量化不同,它不是将每个数据点分配给最近的量化点,而是以概率方式进行舍入,使得结果值是数据点的无偏估计,具有最小方差。
例如,在均匀随机量化中,每个数据点被分配给最近的两个量化点之一,分配的概率与数据点到这两个量化点的距离成反比。假设我们有一个数据点,其值为2.6,我们希望使用均匀随机量化将其量化为2或3。在这种情况下,我们可以计算数据点到两个量化点的距离,即0.6和0.4。然后,我们可以根据这些距离计算分配概率。在这种情况下,数据点被分配给2的概率为0.4,被分配给3的概率为0.6。因此,我们可以通过生成一个随机数来确定数据点的量化值。
当将随机量化应用于神经网络时,它相当于在每一层的输出中添加一个零均值误差项。这个误差项渐进正态分布,它的方差取决于量化级别。这意味着量化权重等同于在每一层的输出中添加噪声。 -
投影梯度下降
是一种优化算法,用于解决带有约束条件的优化问题。在正常的梯度下降过程中,如果待优化的变量存在约束 x ∈ C x∈C x∈C ,那么在梯度算法中的更新公式需要用投影来代替。
假设我们要最小化函数 f ( x ) = x 2 f(x) = x^2 f(x)=x2 ,但是我们的变量 x x x 必须满足约束条件 x > = 0 x >= 0 x>=0。这意味着我们不能让 x x x 取负值。
如果我们使用普通的梯度下降法,那么迭代公式为 x k + 1 = x k − α k ∗ f ’ ( x k ) x_{k+1} = x_k - α_k * f’(x_k) xk+1=xk−αk∗f’(xk) ,其中 f ’ ( x ) f’(x) f’(x) 是函数 f ( x ) f(x) f(x) 的导数, α k α_k αk是步长。由于 f ’ ( x ) = 2 x f’(x) = 2x f’(x)=2x ,所以迭代公式可以写成 x k + 1 = x k − α k ∗ 2 x k x_{k+1} = x_k - α_k * 2x_k xk+1=xk−αk∗2xk 。如果我们从一个正数 x 0 x_0 x0 开始迭代,那么在某一步中, x k x_k xk 可能会变成负数,这就违反了我们的约束条件。
为了避免这种情况,我们可以使用投影梯度下降法。在每次迭代时,我们先按照普通梯度下降法更新 x k x_k xk ,然后将更新后的结果投影回可行域内。在这个例子中,可行域就是所有非负实数,所以投影操作就是将负数变成零。因此,投影梯度下降法的迭代公式为 x k + 1 = m a x ( 0 , x k − α k ∗ 2 x k ) x_{k+1} = max(0, x_k - α_k * 2x_k) xk+1=max(0,xk−αk∗2xk) 。这样,在每次迭代时,如果 x k − α k ∗ 2 x k > = 0 x_k - α_k * 2x_k >= 0 xk−αk∗2xk>=0 ,那么 x k + 1 = x k − α k ∗ 2 x k x_{k+1} = x_k - α_k * 2x_k xk+1=xk−αk∗2xk ,否则 x k + 1 = 0 x_{k+1} = 0 xk+1=0 。这样就保证了在整个迭代过程中, x x x 始终满足约束条件。 -
残差连接
残差连接是一种用于训练深度神经网络的技术,它通过在网络中添加直接连接来解决梯度消失和梯度爆炸问题。这些直接连接被称为“跳过连接”,它们允许梯度在训练期间直接流经网络,从而更容易训练深层网络。残差连接最初是在He等人(2015)的论文中提出的,用于训练深度卷积神经网络,但现在已经被广泛应用于各种类型的深度神经网络中。
举个例子,假设我们有一个深度神经网络,其中每一层都是一个线性变换,然后是一个非线性激活函数。
在没有残差连接的情况下,第l层的输出可以表示为: h l = f ( W l ∗ h ( l − 1 ) + b l ) h_l = f(W_l * h_(l-1) + b_l) hl=f(Wl∗h(l−1)+bl),其中 W l W_l Wl和 b l b_l bl分别是第 l l l层的权重和偏置, f f f是非线性激活函数, h ( l − 1 ) h_(l-1) h(l−1)是第 l − 1 l-1 l−1层的输出。
现在,我们在第 l l l层添加一个残差连接,它将第 l − 1 l-1 l−1层的输出直接连接到第 l l l层的输出。这样,第 l l l层的输出就变成了: h l = f ( W l ∗ h ( l − 1 ) + b l ) + h ( l − 1 ) h_l = f(W_l * h_(l-1) + b_l) + h_(l-1) hl=f(Wl∗h(l−1)+bl)+h(l−1)
可以看到,残差连接将第 l − 1 l-1 l−1层的输出直接添加到了第 l l l层的输出中。这样,在反向传播期间,梯度可以直接流过残差连接,而不会受到中间层的影响。这有助于解决梯度消失和梯度爆炸问题。 -
推理延迟
是指在机器学习模型中,从输入数据到输出结果所需的时间。它通常用来衡量模型的实时性能,即模型能够多快地对新数据进行预测。推理延迟取决于多种因素,包括模型的复杂度、计算硬件的性能以及输入数据的大小。在某些应用场景中,如自动驾驶汽车或语音识别,低延迟推理是非常重要的,因为它可以帮助系统快速做出反应。
举个例子,假设我们有一个语音识别系统,它使用深度神经网络来将语音信号转换为文本。当用户说话时,系统需要快速地对语音信号进行预测,以便实时地显示识别结果。
在这种情况下,推理延迟就非常重要了。如果模型的推理延迟很高,那么用户说完一句话后,可能需要等待几秒钟才能看到识别结果。这会严重影响用户体验。
为了降低推理延迟,我们可以采取多种措施。例如,我们可以使用更快的计算硬件来加速模型推理;我们也可以对模型进行压缩和优化,以减少计算量;此外,我们还可以使用更高效的算法来加速模型推理。
总之,推理延迟是衡量机器学习模型实时性能的一个重要指标。通过采取适当的措施,我们可以有效地降低推理延迟,提高模型的实时性能。 -
Adapter tuning
一种模型压缩方法,它在自注意力模块(和MLP模块)之间插入适配器层,并在随后的残差连接之后。
适配器层中有两个带偏置的全连接层,中间有一个非线性。这种原始设计被称为AdapterH。最近,Lin等人(2020)提出了一种更有效的设计,其中适配器层仅在MLP模块之后和LayerNorm之后应用。我们称之为AdapterL。这与Pfeiffer等人(2021)提出的另一种设计非常相似,我们称之为AdapterP。我们还包括另一种基线称为AdapterDrop(Rücklé等人,2020),它删除了一些适配器层以提高效率(AdapterD)。
在所有情况下,我们都有 ∣ Θ ∣ = ˆ L A d p t × ( 2 × d m o d e l × r + r + d m o d e l ) + 2 × ˆ L L N × d m o d e l |Θ| = ˆLAdpt × (2 × dmodel × r + r + dmodel) + 2 × ˆLLN × dmodel ∣Θ∣=ˆLAdpt×(2×dmodel×r+r+dmodel)+2׈LLN×dmodel,其中 ˆ L A d p t ˆLAdpt ˆLAdpt是适配器层数, ˆ L L N ˆLLN ˆLLN是可训练LayerNorms的数量(例如,在AdapterL中)。 -
GLUE基准测试集
包含了多个不同的自然语言理解任务,包括:
CoLA(Corpus of Linguistic Acceptability):判断给定的句子在语法上是否合理。
SST-2(Stanford Sentiment Treebank):判断电影评论的情感倾向是积极还是消极。
MRPC(Microsoft Research Paraphrase Corpus):判断两个句子是否表达相同的意思。
STS-B(Semantic Textual Similarity Benchmark):计算两个句子的语义相似度。
QQP(Quora Question Pairs):判断两个问题是否等效。
MNLI(Multi-Genre Natural Language Inference):判断一个句子是否蕴含另一个句子。
QNLI(Question Natural Language Inference):将阅读理解问题转换为自然语言推理问题。
RTE(Recognizing Textual Entailment):判断一个文本是否蕴含另一个文本。
WNLI(Winograd NLI):解决Winograd模式挑战,要求模型具有常识推理能力。 -
E2E NLG Challenge
是一个共享任务,旨在评估最近的端到端自然语言生成(NLG)系统能否通过从包含更高词汇丰富性、句法复杂性和多样化话语现象的数据集中学习来生成更复杂的输出。该挑战旨在比较不同的端到端NLG方法,包括基于机器学习和基于规则或模板的方法。 -
失真率理论(Rate Distortion Theory)
是信息论的一个重要分支,它提供了有损数据压缩的理论基础。它解决了确定每个符号应通过信道传输的最小比特率R的问题,以便源(输入信号)可以在不超过预期失真D的情况下在接收器(输出信号)处近似重构。
举个例子,假设我们有一个图像压缩系统,它需要将一张高分辨率图像压缩为较小的文件大小,以便更快地传输。在这种情况下,我们可以使用失真率理论来确定最佳的压缩比特率。首先,我们需要定义一个失真度量,用来衡量压缩后的图像与原始图像之间的差异。这可以是像素值之差的平方和,也可以是更复杂的度量,如结构相似性指数(SSIM)。然后,我们可以使用失真率理论来计算在给定失真度量下,每个符号应通过信道传输的最小比特率R。这样,我们就可以确定在不超过预期失真D的情况下,可以实现的最大压缩比特率。在实际应用中,失真率理论可以帮助我们确定最佳的压缩参数,以便在保证图像质量的同时实现最大的压缩效果。 -
互信息(Mutual Information)
是信息论中的一个概念,它衡量两个随机变量之间的相互依赖性。更具体地说,它量化了通过观察一个随机变量而获得的关于另一个随机变量的“信息量”。
互信息与熵的概念密切相关,熵是信息论中的一个基本概念,它量化了随机变量中所含的期望“信息量”
举个例子,假设我们有两个随机变量X和Y。如果X和Y是独立的,那么知道X的值并不能给我们关于Y的任何信息,反之亦然。因此,它们之间的互信息为零。然而,如果X和Y不是独立的,那么知道其中一个变量的值会减少我们对另一个变量的不确定性。这种减少的不确定性就是互信息。
互信息的计算取决于两个随机变量的联合概率分布和边缘概率分布。对于离散随机变量X和Y,它们的互信息可以通过以下公式计算: I ( X ; Y ) = ∑ y ∈ Y ∑ x ∈ X p ( X , Y ) ( x , y ) l o g p ( X , Y ) ( x , y ) p X ( x ) p Y ( y ) I(X;Y)=\sum_{y \in Y}\sum_{x \in X}p(X,Y)(x,y)log\frac{p(X,Y)(x,y)}{p_X(x)p_Y(y)} I(X;Y)=y∈Y∑x∈X∑p(X,Y)(x,y)logpX(x)pY(y)p(X,Y)(x,y) 其中 p X ( x ) p_X(x) pX(x)和 p Y ( y ) p_Y(y) pY(y)分别是X和Y的边缘概率分布, p ( X , Y ) ( x , y ) p(X,Y)(x,y) p(X,Y)(x,y)是X和Y的联合概率分布 -
L2距离(L2 distance)
也称为欧几里得距离(Euclidean distance),它是欧几里得空间中两点之间的距离。它可以通过两点的笛卡尔坐标使用勾股定理来计算,因此有时也被称为勾股距离。
对于N维空间中的两个点,它们的L2距离可以通过以下公式计算: d = ∑ i = 1 N ( x i − y i ) 2 d=\sqrt{\sum_{i=1}{N}(x_i-y_i)2} d=i=1∑N(xi−yi)2 其中 x i x_i xi和 y i y_i yi分别是两个点在第i维上的坐标。 -
熵编码(Entropy coding)
是一种无损数据压缩方法,它试图接近香农源编码定理所声明的下限,该定理指出任何无损数据压缩方法的预期代码长度必须大于或等于源的熵1。熵编码的目的是通过使用尽可能少的位来表示出现频率高的模式,而使用更多的位来表示出现频率低的模式,从而压缩数字数据。 霍夫曼编码(Huffman coding)就是一种熵编码 -
模型的二进制表示
是指使用二进制代码来表示模型。在神经网络压缩中,一种新的剪枝策略被提出,通过熵编码找到模型的最小长度二进制表示,可以将模型大小减少2.5倍。这种方法不仅剪枝模型,还通过熵编码找到模型的最小长度二进制表示 -
逐步细化(Successive refinement)
是一种方法,它通过首先使用少量信息来近似数据,然后在提供更多信息的情况下迭代地改进近似值。目标是在每个阶段都获得最佳描述 -
联邦学习(Federated Learning)
是一种机器学习技术,它通过在多个分散的边缘设备或服务器上训练算法来实现,这些设备或服务器持有本地数据样本,但不交换它们。这种方法与传统的集中式机器学习技术不同,后者将所有本地数据集上传到一个服务器,也不同于更经典的分散式方法,后者通常假设本地数据样本是独立同分布的。联邦学习使多个参与者能够在不共享数据的情况下构建一个共同的、强大的机器学习模型,从而解决诸如数据隐私、数据安全、数据访问权和异构数据访问等关键问题。它的应用遍布多个行业,包括国防、电信、物联网和制药业。目前一个主要的悬而未决的问题是,通过联邦数据学习到的模型相对于汇集数据时的模型劣势有多大。另一个悬而未决的问题涉及边缘设备的可靠性以及恶意参与者对学习模型的影响。
一个联邦学习的例子是智能手机上的键盘预测。在这种情况下,每个用户的手机都有一个本地数据集,包括用户的输入历史记录和文本习惯。通过联邦学习,每个手机都可以在本地训练一个预测模型,然后将模型参数上传到服务器。服务器将所有手机上传的参数进行平均,然后将更新后的模型发送回每个手机。这样,每个手机都可以使用更新后的模型来提高预测准确性。
这种方法的优点在于,用户的输入数据不需要离开手机,从而保护了用户的隐私。此外,由于每个手机都在本地训练模型,因此可以利用每个用户独特的文本习惯来提高预测准确性。总之,联邦学习通过在多个分散的设备上训练模型来实现有效的机器学习,同时保护用户隐私并提高模型性能。
已收到消息. 一个联邦学习的例子是智能手机上的键盘预测。在这种情况下,每个用户的手机都有一个本地数据集,包括用户的输入历史记录和文本习惯。通过联邦学习,每个手机都可以在本地训练一个预测模型,然后将模型参数上传到服务器。服务器将所有手机上传的参数进行平均,然后将更新后的模型发送回每个手机。这样,每个手机都可以使用更新后的模型来提高预测准确性。 这种方法的优点在于,用户的输入数据不需要离开手机,从而保护了用户的隐私。
此外,由于每个手机都在本地训练模型,因此可以利用每个用户独特的文本习惯来提高预测准确性。 总之,联邦学习通过在多个分散的设备上训练模型来实现有效的机器学习,同时保护用户隐私并提高模型性能。 -
Magnitude Pruning
是一种神经网络压缩技术,它通过删除神经网络中权重的绝对值较小的连接来实现模型压缩。
这种方法基于这样一种假设:权重的绝对值较小的连接对模型的性能影响不大,因此可以安全地删除。在Magnitude Pruning中,通常会设置一个阈值,将权重的绝对值低于该阈值的连接删除。这样可以减少模型中的参数数量,从而实现模型压缩。在剪枝之后,通常会对剩余的非零权重进行重新训练,以进一步优化模型性能。
Magnitude Pruning是一种简单且易于实现的神经网络压缩方法,在许多情况下都能取得不错的效果。 -
迁移学习
是一种机器学习方法,它利用已经在一个任务上训练好的模型来帮助解决另一个相关任务。这种方法的基本思想是,如果两个任务之间存在某些相似性,那么在一个任务上学到的知识可能对解决另一个任务有所帮助。
举个例子,假设我们已经训练了一个能够识别猫和狗的图像分类模型。现在我们想要训练一个能够识别狮子和老虎的模型。由于猫、狗、狮子和老虎都属于哺乳动物,它们之间存在一些相似性,因此我们可以利用已经训练好的猫狗分类模型来帮助我们训练狮虎分类模型。具体来说,我们可以将猫狗分类模型中的一部分层(通常是靠近输入端的层)复制到新模型中,并在此基础上继续训练。这样,新模型就可以利用已经学到的特征提取能力来更快地学习如何识别狮子和老虎。
迁移学习在深度学习领埴中得到了广泛应用,特别是在计算机视觉领域。它可以大大减少训练新模型所需的数据量和计算资源,并且通常能够取得更好的性能。