EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network:
EPSANet:一种基于卷积神经网络的高效金字塔切分注意力模块
- EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network:
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
-
- 3.1Revisiting Channel Attention
- 3.2PSA Module
- 3.3网络设计
- 4.实验
-
- 4.5消融实验
- 5.结论
EPSANet:一种基于卷积神经网络的高效金字塔切分注意力模块)
文章信息:

源码地址: EPSANet
摘要
在这项工作中,提出了一种新的轻量级和有效的注意力方法,名为金字塔切分注意力(PSA)模块。通过在ResNet的瓶颈层中用PSA模块替换3x 3卷积,得到了一个新模块EPSA。EPSA模块可以作为即插即用组件轻松添加到完善的骨干网络中,并可以显著提高模型性能。因此,在这项工作中,通过堆叠这些ResNet风格的EPSA块,开发了一个简单而高效的主干架构EPSANet。相应地,一个更强的多尺度表示能力,可以提供所提出的EPSANet的各种计算机视觉任务,包括但不限于,图像分类,对象检测,实例分割等。所提出的EPSANet的性能优于大多数通道注意力方法的sota。与SENet-50相比,在ImageNet数据集上,Top-1准确率提高了1.93%,在目标检测方面,使用Mask-RCNN在MS-COCO数据集上取得了更大的提升,box AP提高了+2.7,实例分割的mask AP提高了+1.7。
1.介绍
注意力机制广泛应用于许多计算机视觉领域,如图像分类、目标检测、实例分割、语义分割、场景解析和动作定位 [1, 2, 3, 4, 5, 6, 7]。具体而言,有两种类型的注意方法,即通道注意和空间注意。最近的研究表明,通过使用通道注意、空间注意或两者都可以实现显著的性能提升 [8, 9, 10, 11, 12]。通道注意最常用的方法是Squeeze-and-Excitation (SE) 模块 [13],可以在成本相对较低的情况下显著提高性能。SENet的缺点在于它忽视了空间信息的重要性。因此,提出了Bottleneck Attention Module (BAM) [14] 和 Convolutional Block Attention Module (CBAM) [5],通过有效地结合空间和通道注意来丰富注意图。然而,仍然存在两个重要且具有挑战性的问题需要解决。第一个问题是如何高效地捕获和利用具有不同尺度的特征图的空间信息,以丰富特征空间。第二个问题是通道或空间注意只能有效地捕获局部信息,而在建立长程通道依赖性方面存在问题。相应地,提出了许多方法来解决这两个问题。基于多尺度特征表示和跨通道信息交互的方法,如PyConv [15]、Res2Net [16] 和HS-ResNet [17],被提出。另一方面,正如[2, 18, 19]所示,可以建立起远距离通道依赖性。然而,上述所有提到的方法都增加了模型复杂性,因此网络承受了沉重的计算负担。基于以上观察,我们认为有必要开发一个低成本但有效的注意模块。在这项工作中,提出了一种低成本且高性能的新型模块,称为金字塔切分注意力(PSA)。所提出的PSA模块具有处理多尺度输入张量的能力。具体而言,普通的特征图被分割成S组,每组具有 C S \frac CS SC个通道。然后,使用多尺度金字塔卷积结构在每个通道特征图上集成不同尺度的信息。通过这样做,可以更精确地合并上下文特征的相邻尺度。最后,通过提取多尺度特征图的通道注意权重,建立了跨维度交互。采用Softmax操作来重新校准相应通道的注意权重,从而建立了距离通道依赖性。因此,通过在ResNet的瓶颈层中用PSA模块替换3x3卷积,得到了一种新的块,称为高效金字塔切分注意力(EPSA)。此外,通过将这些EPSA块堆叠成ResNet风格,提出了一种名为EPSANet的网络。如图1所示,所提出的EPSANet不仅在Top-1准确率方面胜过先前的方法,而且在所需参数方面更加高效。这项工作的主要贡献总结如下:
- 提出了一种新的高效金字塔切分注意力(EPSA),它它可以有效地提取多尺度空间信息在更细粒度的程度上,并且能形成长远的通道依赖。所提出的EPSA块是非常灵活和可扩展的,因此可以应用于各种各样的网络架构,用于许多计算机视觉任务。
- 提出了一种新的主干结构EPSANet,它可以学习更丰富的多尺度特征表示,并自适应地重新校准跨维通道注意力权重。
- 大量的实验证明,在ImageNet和COCO数据集上,所提出的EPSANet在图像分类、目标检测和实例分割任务中都取得了令人期待的结果。

图1(横坐标为模型参数,纵坐标为top-1准确率)
2.相关工作
注意力机制
注意力机制被用来强化对最具信息表达的特征的分配,同时抑制不太有用的特征,从而使模型能够自适应地关注上下文中的重要区域。在[13]中,Squeeze-and-Excitation(SE)注意力能够通过选择性地调节通道的比例来捕捉通道之间的相关性。在[5]中,CBAM通过为具有大尺寸卷积核的通道注意力添加最大池化特征来丰富注意力特征。受CBAM启发,[20]中的GSoP提出了一种二阶池化方法,以提取更丰富的特征集。最近,提出了非局部块[19],用于构建稠密的空间特征图,并通过非局部操作捕获长程依赖性。基于非局部块,Double Attention Network(A2Net)[8]引入了一个新颖的关系函数,将注意力与空间信息嵌入到特征图中。随后,在[21]中引入的SKNet引入了一种动态选择注意机制,允许每个神经元根据多尺度输入特征图自适应地调整其感受野大小。ResNeSt [12]提出了一个类似的Split-Attention块,可以在特征图的多个组之间实现注意力。Fcanet [9]提出了一种新颖的多光谱通道注意,实现了在频域中的通道注意机制的预处理。GCNet [1]引入了一个简单的空间注意模块,从而建立了长程通道依赖性。ECANet [11]采用一维卷积层来减少全连接层的冗余。DANet [18]通过从不同分支的两个注意模块中取和,自适应地整合局部特征和它们的全局依赖。上述方法要么集中在设计更复杂的注意模块,不可避免地增加更大的计算成本,要么无法建立长程通道依赖性。因此,为了进一步提高效率并减少模型复杂性,提出了一种名为PSA的新型注意模块,其目标是以低模型复杂性学习注意权重,并有效地整合局部和全局注意以建立长程通道依赖性。
多尺度特征表示
多尺度特征表示的能力对于各种视觉任务至关重要,例如实例分割[22]、面部分析[23]、目标检测[24]、显著物体检测[25]和语义分割[7]。设计一种能够更有效地提取多尺度特征的好算子对于视觉识别任务至关重要。通过将多尺度特征提取算子嵌入卷积神经网络(CNN)中,可以获得更有效的特征表示能力。另一方面,CNNs通过一系列卷积算子可以自然地学习粗到细的多尺度特征。因此,设计更好的卷积算子是改善CNN多尺度表示的关键。
3.方法
3.1Revisiting Channel Attention
通道注意力
通道注意力机制允许网络有选择地对每个通道的重要性进行加权,从而生成更多信息的输出。设 X ∈ R C × H × W X∈R^{C×H×W} X∈RC×H×W表示输入特征图,其中H、W、C分别表示其高度、宽度、输入通道数。一个SE块包括两个部分:挤压和激励,这是分别设计用于编码的全局信息和自适应重新校准的通道的方式的关系。通常,可以通过使用全局平均池化来生成通道的信息统计,全局平均池化用于将全局空间信息嵌入到通道描述中。全局平均池化运算符可以通过以下等式计算

SE块中第c个通道的注意权重可以写为:

其中符号δ表示如[26]中的ReLU运算, W 0 ∈ R C × C r W_0 ∈ R^{C×\cfrac{C}{r}} W0∈RC×rC和 W 1 ∈ R C r × C W_1 ∈ R^{\cfrac{C}{r}×C} W1∈RrC×C表示全连接(FC)层。两个全连通层可以更有效地组合通道间的线性信息,有利于通道高、低维信息的交互。符号σ表示激励函数,并且在实践中通常使用Sigmoid函数。通过使用激励函数,我们可以在信道交互后为信道分配权重,从而可以更有效地提取信息。上面介绍的生成t通道关注度权重的过程在[13]中被命名为SEWeight模块,SEWeight模块如图2所示。

图2:SE模块(输入->全局平均池化->两个全连接层->通道权重)
3.2PSA Module
这项工作的动机是构建一个更加高效和有效的通道注意机制。因此,提出了一种新颖的金字塔分割注意(PSA)模块。如图3所示,PSA模块主要通过四个步骤实现。
首先,通过实施提出的分割和连接(SPC)模块获得通道-wise 上的多尺度特征图。
其次,通过使用SEWeight模块获取通道注意向量,以提取具有不同尺度的特征图的注意力。
第三,通过使用Softmax重新校准通道注意向量,获得多尺度通道的重新校准权重。
第四,对重新校准的权重和相应的特征图进行逐元素乘法运算。
最终,作为输出获得一个更丰富的多尺度特征信息的精炼特征图。

如图4所示,用于在所提出的PSA中实现多尺度特征提取的基本算子是SPC。输入特征图X被分成S个部分,如由 [ X 0 , X 1 , ⋅ ⋅ ⋅ , X S − 1 ] [X_0,X_1,· · ·,X_{S-1}] [X0,X1,⋅⋅⋅,XS−1]沿着信道维度所表示的。对于每个切分部分,它具有 C ′ = C'= C′= C S \cfrac{C}{S} SC个公共通道,并且第i个特征图是 X i ∈ R C × H × W X_i ∈ R^{C ×H×W} Xi∈RC×H×W,其中i = 0,1,· · ·,S − 1。请注意,C应该被S整除。通过这种切分方式,我们可以在多个尺度上并行处理输入张量,从而可以获得包含单一类型卷积核的特征图。相应地,可以提取关于每个逐通道特征图的空间信息。并且可以通过在金字塔结构中使用多尺度卷积核来生成不同的空间分辨率和深度。对于每个切分的部分,它独立地学习多尺度空间信息,并以局部方式建立跨通道交互。然而,随着卷积核大小的增加,参数的数量将得到巨大的改善。为了在不增加计算代价的情况下处理不同核尺度下的输入张量,引入了一种组卷积方法,并将其并行应用于卷积核。此外,我们设计了一个新的标准选择组的大小,而不增加参数的数量。多尺度卷积核大小和组大小之间的关系可以写为:
![]()
其中K是卷积核大小,G是组大小。消融实验验证了上述方程的正确性,特别是当k × k = 3 × 3,G默认为1时。最后,多尺度特征图生成函数由下式给出:
![]()
其中,第i个核大小 k i = 2 × ( i + 1 ) + 1 k_i = 2×(i +1)+1 ki=2×(i+1)+1,第i个组大小 G i = 2 k i − 1 2 G_i = 2^{\frac {k_i-1}{2}} Gi=22ki−1, F i ∈ R C × H × W Fi ∈ R^{C ×H×W} Fi∈RC×H×W表示具有不同尺度的特征图。整个多尺度预处理特征图可以通过级联方式获得
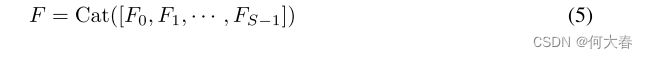

图4:所提出的S=4的Split and Concat(SPC)模块的详细说明,其中“Split”意味着在通道维度中相等地分割,K是卷积核大小,G是组大小,并且“Concat”意味着在通道维度中连接特征。
注意:论文讲的图4和源码实现的方式不太一样,个人观点,仅供参考。
# 配上chatgpt的解析:
# 这段代码定义了一个名为 PSAModule 的PyTorch模型模块,该模块包含了一些卷积层和注意力机制。以下是对代码的解读:
# __init__ 方法:在初始化方法中,定义了 PSAModule 类的一些属性和成员变量。其中包括四个卷积层 (self.conv_1, self.conv_2, self.conv_3, self.conv_4),每个卷积层的输入通道数为 inplans,输出通道数为 planes//4。这些卷积层使用不同的卷积核大小和组数。此外,还有一个 SEWeightModule 模块 (self.se),用于计算通道注意力权重。最后,定义了一个变量 self.split_channel 表示每个通道的输出特征数的四分之一,以及一个 softmax 操作 (self.softmax)。
# forward 方法:前向传播方法实现了整个模块的前向计算过程。首先,通过四个不同的卷积层对输入 x 进行处理,得到 x1、x2、x3、x4 四个特征图。然后,将这四个特征图沿通道维度连接起来,形成一个包含四个通道的特征图 feats。
# 接下来,通过 SEWeightModule 对每个单独的特征图进行通道注意力的计算,得到 x1_se、x2_se、x3_se、x4_se 四个通道注意力特征图。
# 将这四个通道注意力特征图沿通道维度连接起来,并进行 softmax 操作,得到 attention_vectors。然后,将 feats 与 attention_vectors 相乘,得到加权的特征图 feats_weight。
# 最后,将加权的特征图沿通道维度连接起来,得到最终的输出 out,并返回。
#总体来说,这段代码实现了一种通过多个卷积核生成多尺度特征图,然后使用注意力机制(SE模块)对这些特征图进行通道注意力加权的操作。这有助于模型学习更丰富的多尺度特征表示。
class PSAModule(nn.Module):
def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
super(PSAModule, self).__init__()
self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,
stride=stride, groups=conv_groups[3])
self.se = SEWeightModule(planes // 4)
self.split_channel = planes // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((x_se_weight_fp, out), 1)
return out
其中 F ∈ R C × H × W F ∈ R^{C×H×W} F∈RC×H×W是所获得的多尺度特征图。通过从多尺度预处理后的特征图中提取信道注意力权重信息,得到不同尺度的注意力权重向量。在数学上,注意力权重的向量可以表示为
![]()
其中 Z i ∈ R C ′ × 1 × 1 Z_i ∈ R^{C' ×1×1} Zi∈RC′×1×1是注意力权重。SEWeight模块用于从具有不同尺度的输入特征图中获得注意力权重。通过这样做,我们的PSA模块可以融合不同尺度的上下文信息,并为高级特征图产生更好的像素级注意力。进一步,为了实现注意力信息的交互,在不破坏原始通道注意力向量的前提下,融合交叉维向量。并且因此以级联方式获得整个多尺度通道注意力向量:
![]() 其中,⊕ 是concat算子, Z i Z_i Zi是来自 F i F_i Fi的注意力值,Z是多尺度注意力权重向量。软注意力用于跨通道自适应地选择不同的空间尺度,这是由紧凑的特征描述符Zi引导的。软分配权重由下式给出:
其中,⊕ 是concat算子, Z i Z_i Zi是来自 F i F_i Fi的注意力值,Z是多尺度注意力权重向量。软注意力用于跨通道自适应地选择不同的空间尺度,这是由紧凑的特征描述符Zi引导的。软分配权重由下式给出:

其中Softmax用于获得多尺度信道的重新校准的权重 a t t i att_i atti,其包含空间上的所有位置信息和通道中的注意力权重。通过这样做,实现了本地和全局通道注意力之间的交互。接着,将特征重校准的通道注意力以级联方式进行融合和拼接,从而可以获得整个通道注意力向量,
![]()
其中att表示注意力交互之后的多尺度信道权重。然后,我们将多尺度信道注意力 a t t i att_i atti的重新校准的权重与对应尺度 F i F_i Fi的特征图相乘,
![]()
其中, ⊙ \odot ⊙表示逐通道乘法, Y i Y_i Yi是指具有所获得的多尺度逐通道注意力权重的特征图。拼接算子比求和算子更有效,因为它可以完整地保持特征表示而不破坏原始特征图的信息。总之,获得细化输出的过程可以写为:

如上述分析所示,我们提出的PSA模块可以将多尺度空间信息和跨通道注意力整合到每个切分的特征组的块中。因此,我们提出的PSA模块,可以获得更好的信息之间的相互作用的局部和全局的通道注意力。
3.3网络设计
如图5所示,通过在ResNet的bottelneck块中的相应位置用PSA模块替换3x3卷积,进一步获得了名为高效金字塔七分注意力(EPSA)块的新块。多尺度空间信息和跨通道的注意力是通过我们的PSA模块集成到EPSA块。因此,EPSA块可以在更细粒度级别上提取多尺度空间信息,并开长距离通道依赖性。相应地,通过将所提出的EPSA块堆叠为ResNet样式,开发了一种新型高效的骨干网络EPSANet。EPSANet继承了EPSA块的优点,具有较强的多尺度表示能力,能够自适应地重新校准跨维通道权重。如表1所示,提出了EPSANet的两种变型,EPSANet(Small)和EPSANet(Large)。对于所提出的EPSANet(Small),在SPC模块中将核和组大小分别设置为(3,5,7,9)和(1,4,8,16)。建议的EPSANet(Large)具有更高的组大小,并在SPC模块中设置为(32,32,32,32)。


4.实验
总结:效果在图像分类、目标检测、实例分割上都不错,具体参照论文。
4.5消融实验
如表5所示,我们调整了组的大小,以验证我们的网络在ImageNet数据集上的有效性。并行增加卷积核大小将导致参数数量的显著增加。为了在不增加计算量的情况下利用空间域中多尺度的位置信息,我们对每个不同尺度的特征图独立地应用组卷积。通过适当地调整组的大小,参数的数量和计算成本可以减少一个因子,该因子等于组的数量。如表5所示,我们提出的EPSANet可以实现性能和模型复杂度之间的良好平衡。

5.结论
本文提出了一种高效、轻量级的即插即用注意力模块-金字塔切分注意力(PSA)。该模型能够充分提取通道注意力向量中的多尺度空间信息和重要的跨维度特征。提出的高效金字塔切分注意(EPSA)块可以在更细粒度的水平上提高多尺度表示能力,并开发长距离通道依赖性。EPSANet算法能够有效地融合多尺度上下文特征和图像级分类信息。通过大量的定性和定量实验,验证了所提出的EPSANet方法在图像分类、目标检测和实例分割等方面的性能优于其他传统的通道注意方法。作为我们未来的工作,我们将研究将PSA模块添加到更轻量级的CNN架构中的效果。
在这个上下文中, W 0 ∈ R C × C r W_0 \in \mathbb{R}^{C \times \frac{C}{r}} W0∈RC×rC 和 W 1 ∈ R C r × C W_1 \in \mathbb{R}^{\frac{C}{r} \times C} W1∈RrC×C 表示两个全连接(FC)层的权重矩阵。解析每个字母的含义如下:
W 0 W_0 W0 和 W 1 W_1 W1: 这两个符号分别表示两个全连接层的权重矩阵。
∈ \in ∈: 表示"属于"或"在…中"。在这里, W 0 W_0 W0 和 W 1 W_1 W1 属于(或定义在)实数空间 R \mathbb{R} R 中。
R \mathbb{R} R: 表示实数集合,即所有实数的集合。
C C C: 表示输入的通道数(或特征数)。在全连接层中, C C C 通常表示输入特征的数量。
C r \frac{C}{r} rC: 表示压缩因子(compression factor)。这通常用于减小全连接层的参数数量,其中 r r r 是一个大于1的整数。这种参数的设置有助于减小模型的复杂性,并提高计算效率。
总体来说, W 0 W_0 W0 是一个维度为 C × C r C \times \frac{C}{r} C×rC 的权重矩阵, W 1 W_1 W1 是一个维度为 C r × C \frac{C}{r} \times C rC×C 的权重矩阵。在全连接层中,这些权重矩阵用于将输入特征映射到输出特征,其中 C C C 是输入通道数, C r \frac{C}{r} rC 是输出通道数。