激光感知(十):深度学习算法发展简史
目录
- 前言
- 一、Point-based
-
- 1. PointNet / PointNet++
- 2. F-PointNet
- 3. PointRCNN
- 总结
- 二、Voxel-based
-
- 1. VoxelNet
-
- VoxelNet特征提取流程
-
- 1)Voxel特征提取
- 2)全局特征提取
- 2. SECOND
-
- 稀疏卷积
- 3. 后续
- 总结
前言
在深度学习方法出现之前,基于点云的目标检测已经有一套比较成熟的处理流程:分割地面->点云聚类->特征提取->分类,我们将这类方法称之为传统算法,传统算法在使用过程中存在以下问题:
1)地面分割和聚类通常依赖于人为设计的特征和规则,如设置一些阈值、表面法线等,泛化能力差;
2)多阶段的处理流程意味着可能产生复合型错误——聚类和分类并没有建立在一定的上下文基础上,目标周围的环境信息缺失,在复杂环境下,聚类和分类效果难以保障;
3)这类方法对于单帧激光雷达扫描的计算时间和精度是不稳定的,这和自动驾驶场景下的安全性要求(稳定,小方差)相悖。
因此,近年来不少基于深度学习的点云目标检测方法被提出,其检测效果与传统学习算法相比要好,尤其是在复杂环境下目标检测的准确性和精度都有较大的提升。
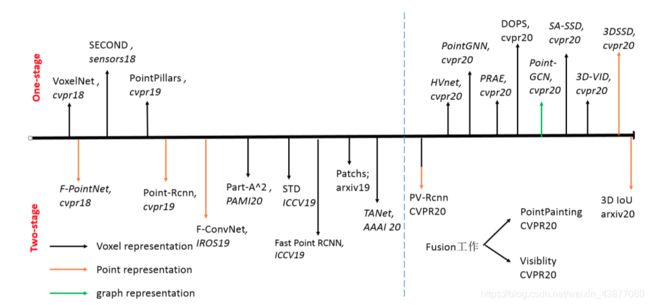
点云因为其具有稀疏性和无规则性使得在二维上非常成熟的CNN结构不能直接的运用在点云中,所以设计一种合适的点云表达形式显得尤为重要。下图是近年来重要的3D检测算法图鉴,虽然新算法不断提出,但其点云表达形式不外乎两大类:Point-based、Voxel-based。
一、Point-based
Point-based采用最原始的点作为深度学习网络的输入,不采用任何的预处理工作,这类工作都是在PointNet++的基础上进行的。下面对Point-based系列算法做一个初步介绍,后续文章会有详细解释。
1. PointNet / PointNet++
斯坦福大学Charles等人在CVPR2017上发表的论文,提出了一种直接处理点云的深度学习网络:PointNet,其后又提出了PointNet改进版:PointNet++,PointNet系列具有里程碑意义,标志着点云处理进入一个新的阶段。
PointNet++为我们带来了Point-based方法的基础backbone,由point-encoder层和point-decoder层组成,encoder层主要逐渐下采样采点特取语义信息,decoder过程是将encoder过程得到的特征信息传递给没有被采样到的点。使得全局的点都具有encoder的特征信息。最后再通过每个点作为anchor提出候选框。

2. F-PointNet
CVPR18上的F-PointNet,PointNet/PointNet++同源之作,具体做法如下可知,首先通过二维的检测框架得到二维目标检测结果,然后将二维检测结果通过视锥投影到三维,再采用三维PointNet++延伸结构检测为三维目标框。算是三阶段的基于point输入的目标检测方法。

3. PointRCNN
随后的CVPR19的比较经典的Point-based方法是PointRCNN,第一个基于原始点云的3D目标检测,和上诉的F-PointNet比较没有采用二维信息,仅仅采用点云作为网络输入。如下图所示,该工作是一个两阶段的检测方法,第一阶段根据语义分割信息对每一个点都提出一个候选框,随后再采用多特征融合进一步优化proposals。

总结
该类方法的优点是作为最原始的点云数据,保留了最细致的几何结构信息,网络的输入信息损失几乎是所有representation方法中最小的。但是缺点也很明显,第一点,MLP的感知能力不如CNN,因此主流的effective的方法都是voxel-based的,第二点,pointnet++结构的采样是很耗时的,所以在实时性上也不及voxel-based的方法。所以今年的CVPR oral文章3D-SSD为了实时性,丢掉了FP层,同时设计了新的SA模块。
二、Voxel-based
1. VoxelNet
CVPR18的VoxelNet是Voxel-based方法的开山之作,VoxelNet将三维点云划分为一定数量的Voxel,经过点的随机采样以及归一化后,对每一个非空Voxel使用若干个VFE(Voxel Feature Encoding)层进行局部特征提取,得到Voxel-wise Feature,然后经过3D Convolutional Middle Layers进一步抽象特征(增大感受野并学习几何空间表示),最后使用RPN(Region Proposal Network)对物体进行分类检测与位置回归。
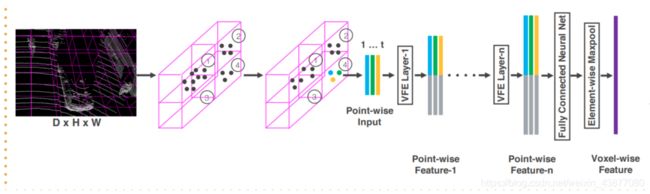 VoxelNet是对PointNet以及PointNet++这两项工作的拓展与改进,粗浅地说,是对点云划分后的Voxel使用"PointNet"。这里详细介绍一下VoxelNet特征提取流程。
VoxelNet是对PointNet以及PointNet++这两项工作的拓展与改进,粗浅地说,是对点云划分后的Voxel使用"PointNet"。这里详细介绍一下VoxelNet特征提取流程。
VoxelNet特征提取流程
1)Voxel特征提取
voxel特征提取的含义就是将point的特征转化为voxel特征,VoxelNet第一步得到了很多的voxel,每一个voxel中包含了少于max_points_number个点,如何根据voxel中的point特取得到voxel特征,这里介绍两种常用的特征提取方法:
(1)MLP提取,即是对voxel中的点采用几层全连接层将voxel中的point信息映射到高维,最后再在每个特征维度上使用maxpooling()得到voxel的特征,但是这种方法必须保证每一个voxel中的点数一样,所以所有的voxel就仅仅只有两种状态,要么是空的,要么是有max_points_number个点的(可以采用重采样的方式保证每一个voxel的点数一样多),一般来说这种特征提取的方式每一个voxel的点数比较多。
(2)均值特征。顾名思义,即是将voxel的point的特征(坐标+反射强度)直接取平均,目前这是比较优的point_fea2voxel_fea的方法。
Voxel-based的方法开始起步的时候,采用的voxel特征提取是上述中的第一种MLP提取方式,所以说VoxelNet是对PointNet以及PointNet++这两项工作的拓展与改进。经过上述特征提取,我们就得到了每一个voxel的特征,下一步就是提取得到更加全局的特征。
2)全局特征提取
接下来采用感知能力强大的CNN结构来进行全局特征提取。下图中左边表示voxel特征(C表示特征维度),其中空的voxel表示在原始空间没有点的在该voxel内,3D CNN则是对这样一个(H,W,L,C)的四维张量做3D空间中的卷积,示意图的kernel大小为(222)(一般情况下是333的大小),真实情况中空的voxel比示意图中还要多得多。由于kernel也是三维的,经过4次stride=2的卷积再加一次额外的高度维的stride=2的卷积后得到了右图的feature map ,但是这个时候仍然是三维的feature map。
 经过下图的操作,即将高度维的特征直接压缩到特征维中,变成了二维的feature map。所以此后就可以直接采用二维RPN 网络结构对三维物体进行目标检测。
经过下图的操作,即将高度维的特征直接压缩到特征维中,变成了二维的feature map。所以此后就可以直接采用二维RPN 网络结构对三维物体进行目标检测。

从上面的示意图和介绍中,我们不难发现至少有如下的几个问题:(1)3D卷积的kernel为三维kernel,因此会存在参数量巨大的问题,可能不好学习或者导致过拟合。(2)输入的整个场景的voxels含有很多空的voxel,但是在卷积过程需要将其的特征填充为0,是很占显存的,同时时间效率也降低。为例解决上述问题,18年SECOND提出了。
2. SECOND
SECOND引入了稀疏卷积使得内存占用大大减少,3D卷积本身会对空间中每一个voxel都进行卷积,但是3D稀疏卷积只保留了空间中非空的voxel,采用map映射的方式得到卷积后的voxel空间索引。
稀疏卷积
实际上就是先将原始空间中的非空的voxel的空间索引记录起来,将其特征排成一列map,卷积操作也是通过计算索引来完成的,也就是说最终的结果仅仅是在二维中通过索引计算得到的,最后将final-feature-map通过最终的空间索引还回成voxel表达即可。一样的,为了使用二维RPN网络,一般的设计都是和上面一样将H层直接压缩到特征。

3. 后续
次年的CVPR19的pointpillars则是直接将voxel改进为pillar直接跳过了3D卷积这一步骤,后续的19年ICCV则是将基于voxel的方法的参数优化(由于稀疏卷积的引入,使得更小的voxel可以被使用)以及改进为两阶段的方法fastpointrcnn,其中STD是直接将体素划分改为了球体划分(具有更好的方向性)。同样的19年的NIPS的文章有开始考虑从整个场景中粗略的先注意到大致的object,再对该场景进行划分。该类的方法的核心思想就是把点云的无序性通过体素划分使其规整,但是不可避免的会有信息丢失。
总结
voxel-representation的方法的优点即是性能好又高效,不仅仅在精度上有着point-based的方法目前无法比拟的精度,在速度上也是很可观的,尤其是在稀疏卷积和3D流型卷积引入到3D目标检测后,发展更为迅速。但是缺点则是该类方法对参数比较敏感,预处理划分voxel的时候需要设置合适的参数,当然从信息论的方面理解,体素划分必然带来信息的丢失,尤其是局部细节信息的丢失,因此今年CVPR20上至少有三篇文章(SA-SSD,pointpainting,HVnet)在细节几何结构上做了一定的研究工作。