SeaTunnel 2.1.3 任务执行流程源码解析
前言:
最近因为公司业务需求,调研了一下SeaTunnel的工作原理,现在记录下来,也分享给大家共同学习。
一、SeaTunnel是啥,有什么用
Apache SeaTunnel 是下一代高性能、分布式、海量数据集成框架。通过我们努力让Spark、Flink的使用更简单、更高效,将行业的优质经验和我们对Spar、Flinkk的使用固化到产品SeaTunnel中,显着降低学习成本,加速分布式数据处理能力的部署在生产环境中。
更多的不再叙述,毕竟来看源码的人肯定知道这是个啥,放上官网:Apache SeaTunnel | Apache SeaTunnel
二、基于源码展示SeaTunnel工作原理
我们以一个官方提供的flink-example来从源码展示SeaTunnel的执行流程。
首先我们通过使用bin/start-seatunnel-flink.sh脚本来提交Flink任务,我们来看脚本中比较关键的两行内容:
SeaTunnel通过脚本去执行了seatunnel-core-flink.jar并且入口类为org.apache.seatunnel.core.flink.FlinkStarter,我们接下来移步源码来看这个FlinkStarter类。
public class FlinkStarter implements Starter {
private static final String APP_NAME = SeatunnelFlink.class.getName();
private static final String APP_JAR_NAME = "seatunnel-core-flink.jar";
/**
* SeaTunnel parameters, used by SeaTunnel application. e.g. `-c config.conf`
*/
private final FlinkCommandArgs flinkCommandArgs;
/**
* SeaTunnel flink job jar.
*/
private final String appJar;
FlinkStarter(String[] args) {
this.flinkCommandArgs = CommandLineUtils.parseCommandArgs(args, FlinkJobType.JAR);
// set the deployment mode, used to get the job jar path.
Common.setDeployMode(flinkCommandArgs.getDeployMode());
Common.setStarter(true);
this.appJar = Common.appLibDir().resolve(APP_JAR_NAME).toString();
}
@SuppressWarnings("checkstyle:RegexpSingleline")
public static void main(String[] args) {
FlinkStarter flinkStarter = new FlinkStarter(args);
System.out.println(String.join(" ", flinkStarter.buildCommands()));
}
/**
* 构建Flink执行命令。入口类为SeatunnelFlink
* @return
*/
@Override
public List buildCommands() {
return CommandLineUtils.buildFlinkCommand(flinkCommandArgs, APP_NAME, appJar);
}
}
在FlinkStarter类中,Seatunnel使用buildCommands()构建Flink提交任务命令,下面是buildCommands的实现:
public static List buildFlinkCommand(FlinkCommandArgs flinkCommandArgs, String className, String jarPath) {
List command = new ArrayList<>();
command.add("${FLINK_HOME}/bin/flink");
command.add(flinkCommandArgs.getRunMode().getMode());
command.addAll(flinkCommandArgs.getFlinkParams());
command.add("-c");
command.add(className);
command.add(jarPath);
command.add("--config");
command.add(flinkCommandArgs.getConfigFile());
if (flinkCommandArgs.isCheckConfig()) {
command.add("--check");
}
// set System properties
flinkCommandArgs.getVariables().stream()
.filter(Objects::nonNull)
.map(String::trim)
.forEach(variable -> command.add("-D" + variable));
return command;
} 到这里,大概能推断出来SeaTunnel的执行逻辑:将自己作为一个Jar提交给Flink,在Flink执行时,以SeaTunnel为底座,根据用户编写的conf来装填对应的Source、Transform、Sink插件,最终拼好任务后提交给Flink去构建StreamGraph和JobGraph。我们继续往下看,来验证一下我们的想法。
在上面的FlinkStarter类中,SeaTunnel将要执行的jar的main设置为SeatunnelFlink.class,那么我们去看看这个类。
public class SeatunnelFlink {
public static void main(String[] args) throws CommandException {
// 解析conf中的参数
FlinkCommandArgs flinkCommandArgs = CommandLineUtils.parseCommandArgs(args, FlinkJobType.JAR);
// 校验解析出的参数是否合法
Command flinkCommand = new FlinkCommandBuilder()
.buildCommand(flinkCommandArgs);
// 执行
Seatunnel.run(flinkCommand);
}
} 这个类也很简单,主要做了两件事,分别是校验参数,以及执行任务,我们再去看run方法:
public static void run(Command command) throws CommandException {
try {
command.execute();
} catch (ConfigRuntimeException e) {
showConfigError(e);
throw e;
} catch (Exception e) {
showFatalError(e);
throw e;
}
} 同样很简单,我们去看execute方法
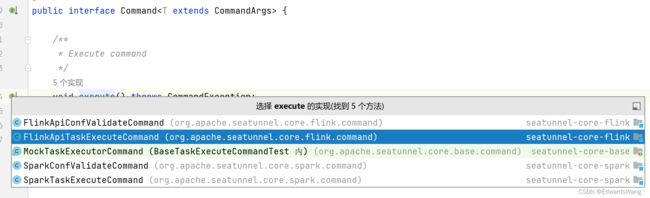
我们可以看到,execute方法有5个实现,第一个 FlinkApiConfValidateCommand用来校验配置参数是否合法,第二个FlinkApiTaskExecuteCommand是真正构建Flink作业的类,我们点进去再看
@Override
public void execute() throws CommandExecuteException {
// 配置计算引擎类型 Flink or Spark
EngineType engine = flinkCommandArgs.getEngineType();
Path configFile = FileUtils.getConfigPath(flinkCommandArgs);
// 解析conf文件中的配置
Config config = new ConfigBuilder(configFile).getConfig();
// 基于上面解析的conf和计算引擎类型,构建作业入口,Flink中的env
FlinkExecutionContext executionContext = new FlinkExecutionContext(config, engine);
// 解析Source、Transform、Sink
List> sources = executionContext.getSources();
List> transforms = executionContext.getTransforms();
List> sinks = executionContext.getSinks();
// 检查上面解析出的插件类型
checkPluginType(executionContext.getJobMode(), sources, transforms, sinks);
baseCheckConfig(sinks, transforms, sinks);
showAsciiLogo();
try (Execution,
BaseTransform,
BaseSink,
FlinkEnvironment> execution = new ExecutionFactory<>(executionContext).createExecution()) {
// 插件的生命周期方法,插件注册后将调用该方法
prepare(executionContext.getEnvironment(), sources, transforms, sinks);
// 开始执行
execution.start(sources, transforms, sinks);
close(sources, transforms, sinks);
} catch (Exception e) {
throw new CommandExecuteException("Execute Flink task error", e);
}
}
这个方法中的主要工作为解析插件信息以及创建当前选择的计算引擎的程序入口,对应于Flink中的env,我们继续看start方法,我们选择流式处理的FlinkStreamExecution实现:
@Override
public void start(List sources, List transforms, List sinks) throws Exception {
List> data = new ArrayList<>();
// 遍历用户选择的的Source插件
for (FlinkStreamSource source : sources) {
// 通过addSource.returns(RowTypeInfo)获取带有Schema的DataStream
DataStream dataStream = source.getData(flinkEnvironment);
data.add(dataStream);
// 将当前带有Schema的DataStream注册为FlinkTable
registerResultTable(source, dataStream);
}
DataStream input = data.get(0);
// 遍历用户选择的Transform插件
for (FlinkStreamTransform transform : transforms) {
// 通过schema创建FlinkTable,再用FlinkTable生成带Schema的DataStream
DataStream stream = fromSourceTable(transform.getConfig()).orElse(input);
// 执行Transform组件逻辑
input = transform.processStream(flinkEnvironment, stream);
// 将处理后的数据注册为表
registerResultTable(transform, input);
transform.registerFunction(flinkEnvironment);
}
for (FlinkStreamSink sink : sinks) {
// 拿到数据写如外部系统
DataStream stream = fromSourceTable(sink.getConfig()).orElse(input);
sink.outputStream(flinkEnvironment, stream);
}
try {
LOGGER.info("Flink Execution Plan:{}", flinkEnvironment.getStreamExecutionEnvironment().getExecutionPlan());
// 开始交由Flink执行
flinkEnvironment.getStreamExecutionEnvironment().execute(flinkEnvironment.getJobName());
} catch (Exception e) {
LOGGER.warn("Flink with job name [{}] execute failed", flinkEnvironment.getJobName());
throw e;
}
}
到此任务构建完成,后续工作交由FLink去完成。我们来看上面这段代码中的一些重要方法,首先是如何从Source组建中拿到DataSource
@Override
public DataStream getData(FlinkEnvironment env) {
StreamTableEnvironment tableEnvironment = env.getStreamTableEnvironment();
tableEnvironment
.connect(getKafkaConnect())
.withFormat(setFormat())
.withSchema(getSchema())
.inAppendMode()
.createTemporaryTable(tableName);
Table table = tableEnvironment.scan(tableName);
return TableUtil.tableToDataStream(tableEnvironment, table, true);
}
KafkaSource 通过用户在conf文件中配置的Schema信息,将从Kafka读进来的流注册为FlinkTable,在将Table转换为带有Schema属性的DataStream
我们再来看Transform组件是如何读数据和写出处理完成后的数据的,首先是根据SourceTableName读根据指定父级Source传递进来的数据:
private Optional> fromSourceTable(Config pluginConfig) {
// 如果配置了source_table_name
if (pluginConfig.hasPath(SOURCE_TABLE_NAME)) {
StreamTableEnvironment tableEnvironment = flinkEnvironment.getStreamTableEnvironment();
// 通过Schema创建FlinkTable
Table table = tableEnvironment.scan(pluginConfig.getString(SOURCE_TABLE_NAME));
// 将FlinkTable转换为带Schema的DataStream
return Optional.ofNullable(TableUtil.tableToDataStream(tableEnvironment, table, true));
}
return Optional.empty();
}
然后根据ResultTableName将处理完的数据注册为Flink动态表:
private void registerResultTable(Plugin plugin, DataStream dataStream) {
Config config = plugin.getConfig();
// 如果配置了 result_table_name
if (config.hasPath(RESULT_TABLE_NAME)) {
String name = config.getString(RESULT_TABLE_NAME);
StreamTableEnvironment tableEnvironment = flinkEnvironment.getStreamTableEnvironment();
// 判断环境中是否存在 此表
if (!TableUtil.tableExists(tableEnvironment, name)) {
if (config.hasPath("field_name")) {
String fieldName = config.getString("field_name");
// 将表注册如Flink StreamTableEnvironment中
tableEnvironment.registerDataStream(name, dataStream, fieldName);
} else {
tableEnvironment.registerDataStream(name, dataStream);
}
}
}
}
再来看Sink组件是如何将数据写入外部存储系统的,这里还是以Kafka为例,直接调用了env.addSink方法将流写出:
@Override
public void outputStream(FlinkEnvironment env, DataStream dataStream) {
FlinkKafkaProducer rowFlinkKafkaProducer = new FlinkKafkaProducer<>(
topic,
JsonRowSerializationSchema.builder().withTypeInfo(dataStream.getType()).build(),
kafkaParams,
null,
getSemanticEnum(semantic),
FlinkKafkaProducer.DEFAULT_KAFKA_PRODUCERS_POOL_SIZE);
dataStream.addSink(rowFlinkKafkaProducer);
}
总结:
将执行逻辑画了个图,下面把图方上帮助理解:
