纯JS导入导出文件(XLSX)
主要整理了一下怎样使用前端导入导出txt、csv和excel文件,代码都在chrome运行成功
目录
- 1. 前置知识
-
- 1.1 Blob类型
- 1.2 File API
- 1.3 FileReader
- 1.4 ArrayBuffer类型
- 1.5 URL.createObjectURL和URL.revokeObjectURL
- 1.6 下载文件的两种方法
- 2. 导入导出txt和csv
- 3. 导入导出excel文件
-
- 3.1 关于插件js-xlsx和xlsx-style
- 3.2 插件生成的对象结构
- 3.3 js-xlsx和xlsx-style中的API
- 3.4 导入excel文件
- 3.5 导出excel文件
- 参考链接
1. 前置知识
1.1 Blob类型
Blob中文名为二进制大型对象(Binary large Object)。是用于读取二进制文件的一个API。可以通过Blob构造函数创建Blob对象。
let blob = new Blob([字符串或二进制对象], { type: 'MIME类型' });
上述构造函数第一个参数为数组,内部元素可以是一个字符串,也可以是一个二进制对象(通常传入input拿到的File对象,也可以传入Blob对象)。第二个参数用来指定文件的MIME类型,如果省略则默认为text/plain,即文本类型。
// 将一段html保存为二进制文件
let html = `hello, world!
`,
blob = new Blob([html], { type: 'text/html' });
// 保存json数据
let json = [{ "name": "张三", "age": 18 }],
blob2 = new Blob([JSON.stringify(json)], { type: 'application/json' }); // Blob {size: 28, type: "application/json"}
可以通过Blob拿到文件的大小(以字节为单位)和MIME类型。Blob原型上有一个slice方法,可以按字节截取文件的一部分。通过这个方法可以做一些文件分片上传的操作,此处不做介绍。
let blob = new Blob(['1234']),
blob2 = blob.slice(0, 2, { type: 'application/json' }); // 参数分别为开始位置,结束位置和这个新的Blob对象的MIME类型,注意截取部分不包括结束位置
slice不同的浏览器可能存在兼容性,可以通过以下方法处理:
const slice = slice || webkitSlice || mozSlice;
Blob原型上还有一个text方法可以用来读取对象的内容。它返回一个Promise。
let blob = new Blob(['我是内容']);
blob.text().then(value => {
console.log(value); // 我是内容
});
1.2 File API
读取文件时,我们需要使用input元素,将type设置为file,就可以通过File的一些API拿到文件的信息和内容。
<input type="file" id="fileBtn" />
let fileBtn = document.getElementById('fileBtn');
fileBtn.onchange = function () {
let files = fileBtn.files,
file = files[0];
}
上面的files是一个FileList伪数组,内部的每一个元素都是一个File对象。我们可以通过File对象得到文件的信息。如下是一个JSON文件的File对象。
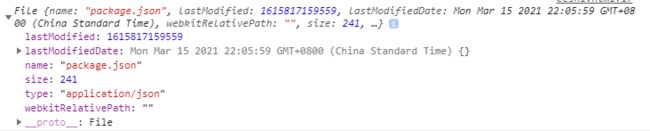
我们发现里面保存了文件的名字(name),大小(size,以字节为单位),类型(type),上次修改时间(lastModified和lastModifiedDate,分别是时间戳和标准时间格式,这个有可能别的浏览器没有)。File继承自Blob,因此Blob原型上的方法都可以使用。例如我们可以使用text方法读取上述JSON文件内容。
file.text().then(value => {
console.log(value);
})
// 打印内容如下
/*
{
"name": "vue常用测试文件",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"dependencies": {
"element-ui": "^2.15.1",
"vue": "^2.6.12",
"xlsx": "^0.16.9",
"xlsx-style": "^0.8.13"
}
}
*/
1.3 FileReader
通过HTML提供的input我们可以拿到文件的一些信息以及内容,但是使用text只能通过文本方式打印出来,在文件传输时,我们希望拿到文件的二进制数据,这时怎么办?我们当然可以通过codePointAt拿到每个字符的Unicode码点,然后根据文件的编码方式将这些字符的Unicode码点进行编码,然后转成二进制字符串或者ArrayBuffer。但是这样属实麻烦,JavaScript提供了FileReader用来按照不同格式读取文件内容。
let reader = new FileReader();
FileReader原型上有以下方法可以读取文件内容:
| 函数 | 参数 | 作用 |
|---|---|---|
| readAsText | 接受两个参数,第一个参数为一个File对象或Blob对象,第二个参数可选,表示文件编码方式,传入一个字符串,默认值为utf-8 |
返回普通字符串 |
| readAsBinaryString | File对象或Blob对象 | 返回一个二进制字符串,每个字符代表一个字节 |
| readAsArrayBuffer | File对象或Blob对象 | 返回一个ArrayBuffer数组 |
| readAsDataURL | File对象或Blob对象 | 返回base64 |
通过上述方法我们可以拿到不同格式的文本内容,下面是个案例:
<input type="file" id="fileBtn" />
let fileBtn = document.getElementById('fileBtn'),
file = fileBtn.files[0];
file.onchange = function () {
let reader = new FileReader();
reader.onload = function (e) {
let content = reader.result; // 这里也可以使用 e.target.result 拿到文件内容
console.log(content); // 你好
}
reader.readAsText(file, 'GBK'); // 这里需要注意,window的 txt 文件默认编码为 ANSI 编码,什么是 ANSI 编码?事实上这不是一种编码,而是一种统一标识,因为在不同国家文件编码方式不同,例如中国使用的是 GBK 编码,那么 ANSI 就表示 GBK 编码,美国使用 ASCII 编码,那么 ANSI 就表示 ASCII 编码。我们亦可以把 txt 文件另存为 utf-8 编码,这样`readAsText`的第二个参数就应该是 `utf-8`。注意编码方式不同则返回字符会是乱码。
}
上述案例中我们读取了一个文本文件,内容为 你好,里面使用了一个load事件,这个事件在文件读取成功时触发。此外,还有error事件和progress事件,分别在读取文件失败和读取文件过程中调用。此处不再做介绍,详细内容可以查看红宝书或者阮一峰的书。
1.4 ArrayBuffer类型
前面介绍的API都是文件相关,接下来简单介绍ES6新增的ArrayBuffer数组。和Blob以及File不同的是,ArrayBuffer针对的是内存,通过ArrayBuffer我们可以手动划分出一块连续的内存空间,方法如下:
let buffer = new ArrayBuffer(16); // 这样得到的是一块16个字节的内存
ArrayBuffer有一个byteLength属性,可以查看内存的大小,单位为字节。通过这个属性我们可以检测分配内存是否成功(因为在需要的内存比较大时,并不能保证总是有那么一大块连续的内存可供使用)。
let n = 16,
buffer = new ArrayBuffer(n);
if (n === buffer.byteLength) {
console.log('内存分配成功!');
} else {
console.log('内存分配失败!');
}
ArrayBuffer里面只有一个slice可以操作内存,其余需要借助于视图。
let buffer = new ArrayBuffer(8),
buffer2 = buffer.slice(0, 3); // 从 buffer 上划分出 3 个字节的内存,第一个参数为开始下标,第二个参数为结束下标,划分的内存不包括结束下标的内存。注意划分得到的内存和buffer指向同一块内存,只是长度不同
ES6给我们提供了两种视图来操作内存,分别为TypedArray和DataView。这里视图的概念就是相当于PS中的图层,能够让我们显式的观察到内存,并对其进行操作。注意视图只是一种操作内存的工具,并不是代表内存,数据保存还是在ArrayBuffer里面,视图就像是一只笔,能够读写内存,而ArrayBuffer就是那张承载数据的纸。
TypedArray视图共有9种类型,分别如下:
- Int8Array:8 位有符号整数,长度 1 个字节。
- Uint8Array:8 位无符号整数,长度 1 个字节。
- Uint8ClampedArray:8 位无符号整数,长度 1 个字节,溢出处理不同。
- Int16Array:16 位有符号整数,长度 2 个字节。
- Uint16Array:16 位无符号整数,长度 2 个字节。
- Int32Array:32 位有符号整数,长度 4 个字节。
- Uint32Array:32 位无符号整数,长度 4 个字节。
- Float32Array:32 位浮点数,长度 4 个字节。
- Float64Array:64 位浮点数,长度 8 个字节。
由于使用方式一样,这里只举一个例子:
let buffer = new ArrayBuffer(8),
uint1 = new Uint8Array(buffer),
uint2 = new Uint8Array(8),
uint3 = new Uint8Array(new Array(8)),
uint4 = new Uint8Array(uint1);
// [0, 0, 0, 0, 0, 0, 0, 0]
上述通过4种方法建立了8个字节的8位无符号整数视图,每一位的初始值都是0。注意通过普通数组和TypedArray建立的视图只是复制了数值,对应的内存是新开辟的,和原数组不同。此外,除了concat方法外,TypedArray视图几乎可以使用所有常用的数组方法。也可以将TypedArray视图转化为普通数组。
Array.prototype.slice.call(new Uint8Array(8)); // [0, 0, 0, 0, 0, 0, 0, 0]
DataView视图这里不做介绍,关于ArrayBuffer还有许多内容,详细的可以看阮一峰的ES6入门。
1.5 URL.createObjectURL和URL.revokeObjectURL
有时候我们需要做一些图片预览的操作,除了可以使用上述提到的FileReader对象的readAsDataURL获取到图片的base64编码以外,还可以通过URL.createObjectURL得到一个指向图片内存的URL,这个URL以blob开头,表明对应一个 Blob 对象,协议头后面是一个识别符,用来唯一对应内存里面的 Blob 对象。我们可以直接用于图片的src。
// 这里假设 imageFile 为用户上传的图片(File对象)
let url = URL.createObjectURL(imageFile); // blob:null/835cd17a-de14-48ab-a7ea-f68455b5db08
let image = document.createElement('img');
image.src = url;
image.onload = function () {
this.width = 100;
document.body.appendChild(this);
URL.revokeObjectURL(this.src);
}
上述代码可以生成一个图片缩略图用于预览,注意在使用完之后要使用revokeObjectURL释放掉创建的这个URL。
浏览器处理 Blob URL 就跟普通的 URL 一样,如果 Blob 对象不存在,返回404状态码;如果跨域请求,返回403状态码。Blob URL 只对 GET 请求有效,如果请求成功,返回200状态码。由于 Blob URL 就是普通 URL,因此可以下载。
1.6 下载文件的两种方法
使用JavaScript下载文件主要有两种方法。一种是通过window.open()拿到后端返回的文件地址下载,另一种是通过a标签的download属性下载。这里主要介绍第二种。
// 1、首先得到文件内容,这里假设从后端获取到二进制数据
let xhr = new XMLHTTPRequest();
xhr.open('GET', 接口url);
xhr.responseType = 'blob'; // 这里注意要将 responseType 设为 blob,这样接受的内容格式就是 Blob 类型
xhr.onload = function (e) {
let content = xhr.response;
// 2、生成 url
let url = URL.createObjectURL(content);
// 3、使用 a 标签下载
let a = document.createElement('a');
a.href = url;
a.download = '测试.txt'; // 这里假设下载为 txt 文件
document.body.appendChild(a);
a.click();
URL.revokeObjectURL(url);
document.body.removeChild(a);
}
2. 导入导出txt和csv
了解了前面的知识,那么我们就可以很容易的实现导入和导出txt和csv文件了。
<input type="file" onchange="upload(files[0])" />
<button onclick="exportFun('测试', 'csv')">导出文件button>
// 导入文件
function upload(file) {
let reader = new FileReader();
reader.addEventListener('load', function () {
let result = reader.result;
console.log(result); // 这里可以打印出 txt 或者 csv 文件的内容
});
reader.readAsText(file, 'GBK');
}
// 导出文件
let data = [
["姓名", "年龄", "性别"],
["王二", "18", "男"]
];
function exportFun(fileName, type) {
let finalData = data.map(item => item.toString()).join('\n'),
blob = '',
url = '';
if (type === 'txt') {
blob = new Blob([finalData], { type: 'text/plain' });
} else if (type === 'csv') {
// url = 'data:text/csv;charset=utf-8,\ufeff' + encodeURI(finalData);
// 可以使用上述方式导出 csv 文件,但是由于浏览器对 URL 长度的限制,所以大文件可能会出错
blob = new Blob(['\ufeff' + finalData], { type: 'text/csv' }); // 由于 excel 只能识别带 BOM(这里是指 Byte Order Mark,字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码) 的 UTF-8 编码,因此这里需要在文字开头加上 \ufeff
}
url = URL.createObjectURL(blob);
let a = document.createElement('a');
a.href = url;
a.download = fileName + '.' + type;
document.body.appendChild(a);
a.click(); // 注意 click 需要在设置 download 之后
URL.revokeObjectURL(url);
document.body.removeChild(a);
}
3. 导入导出excel文件
3.1 关于插件js-xlsx和xlsx-style
为了导出excel文件,我们需要使用两个插件。js-xlsx和xlsx-style都可以用于导出excel,但是如果导出的excel需要样式,则需要使用xlsx-style(因为这两个插件都是社区版,免费使用,所以功能比不上正式的付费版,但都是基于Sheet-js)。引入插件方式如下:
// 引入插件
yarn add xlsx
yarn add xlsx-style
如果需要在html文件中使用插件,则需要使用script引入dist/xlsx.full.min.js。在vue项目中使用则使用import导入即可。
3.2 插件生成的对象结构
我们使用插件时,主要是为了生成Excel能够解析的xlsx格式,两个插件生成的都是一个对象,格式差不多,这里介绍一下使用xlsx-style导出的对象:
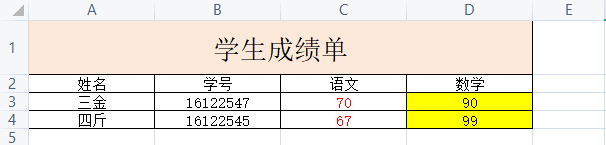
这是导入的excel文件
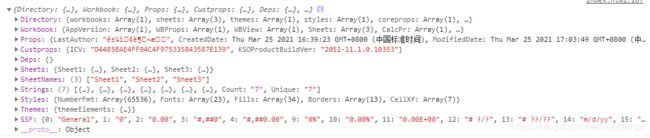
这是生成的对象
在这个对象中,最重要的是Sheets和SheetNames,这里面分别保存了excel文件每个Sheet页的内容和名字。展开Sheets可以看到下面的结构:

由于只有第一个Sheet填写了内容,因此后两个都是空(这里用的wps生成的excel文件,默认会建立3个Sheet页)。在第一个Sheet页中,!ref表示当前Sheet页的有效范围(这块在生成Sheet页的时候需要注意,有效范围要包含所有的单元格),因为内容都集中在从A1单元格到D4单元格,所以有效范围是A1:D4。!merges表示合并单元格,值是一个数组,数组内每一项表示一个合并单元格。!cols表示每一列的宽度,同样是个数组,每一项代表一列的宽度。表示其余的都是单元格数据。键名表示单元格位置,我们展开一个单元格数据看看:

里面有好几个属性,但是我们常用的只有三个,分别是t、v、s。t表示当前单元格内数据的类型(type),s表示这是一个字符型(string)。v表示单元格内的原始数据(value),A1单元格内放的是学生成绩单几个字。s表示这个单元格的样式(style)。接下来依次介绍:
t主要有以下几种:
| 缩写 | 含义 |
|---|---|
| s | string,表示JavaScript中的String类型 |
| n | number,表示JavaScript中的Number类型 |
| b | boolean,表示JavaScript中的Boolean类型 |
| d | date,表示JavaScript中的Date类型(注意读取文件时默认将日期格式的也显示为n类型) |
对于v没什么好说的,主要注意一些错误数据的显示,比如说在excel里输入=1/0会显示#DIV/0!,类似这种在v中怎么表示呢?如下:
| Value | Error Meaning |
|---|---|
0x00 |
#NULL! |
0x07 |
#DIV/0! |
0x0F |
#VALUE! |
0x17 |
#REF! |
0x1D |
#NAME? |
0x24 |
#NUM! |
0x2A |
#N/A |
0x2B |
#GETTING_DATA |
左边为v的值,右边为excel中显示的值
最后,比较重要的是s,它里面存放了单元格的所有样式设置,例如边框、颜色等。如下:

如图,alignment表示对齐方式,vertical和horizontal分别表示垂直和水平对齐的方式,他们可以设置left、right、center。border表示边框,每个方向的边框样式都用一个对象表示。如下:
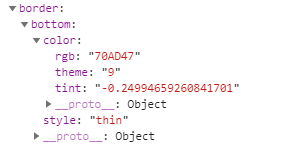
style表示边框的类型,thin相当于css中的solid。还可以设置以下值:
thinmediumthickdottedhairdashedmediumDasheddashDotmediumDashDotdashDotDotmediumDashDotDotslantDashDot
color用来设置边框的颜色,有三种设置颜色的方式,一种是使用excel提供的主题色,如下:

theme的值表示主题色的序号,从0开始编号,可以取0-9。例如上图中的theme为1。tint表示色彩的明度,也就是下图中的百分比数值的小数形式,默认值为0:
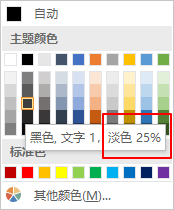
上图颜色可以表示为:color: { theme: 1, tint: 0.25 }
rgb的值是按照ARGB来表示的,简单来理解就相当于把rgba里面的透明度的设置放在最开头,并且使用十六进制表示。例如:00000000表示纯黑色,前两个0表示透明度为0,也就是不透明,后面的则是我们平时用的颜色的十六进制表示。透明度(Alpha)范围是0-255,用十六进制表示就是00-FF。注意不需要带#号。如果不写透明度,则默认不透明。通过求出透明度比例,我们可以换算出透明度的十六进制。上图颜色透明度为25%,因为透明度从0开始计算,所以我们这里使用256乘以25%,然后将所得结果减去1,得到63,转化为十六进制为3F。因此上图颜色用rgb表示为:color: { rgb: 3F000000 }。
第三种设置的颜色的方式基本不用,它是表示一个excel预设的默认值,也就是纯黑色,也就是说,如果我们不给边框设置颜色,则默认会是纯黑色。它的表示方法是:color: { auto: 1 }。
后续凡是设置颜色的都和上面一样
font表示单元格字体设置。可以设置如下参数:
| 含义 | 属性名 | 属性值 |
|---|---|---|
| 字体类别 | name | "Calibri" (默认类型) |
| 字体大小 | sz | "11" // font size in points |
| 字体颜色 | color | 使用theme或者rgb或者auto |
| 是否加粗 | bold | true / false |
| 是否添加下划线 | underline | true / false |
| 是否倾斜 | italic | true / false |
| 是否设置中划线(删除线) | strike | true / false |
| 是否设置outline | outline | true / false |
| 是否设置阴影 | shadow | true / false |
| 是否纵向显示 | vertAlign | true / false |
注意:如果要设置字体类别为中文,例如华文行楷,那么需要先手动转化为utf-8表示法,然后每个字节使用String.fromCharCode()转化为字符。比如华文行楷转化后:
åŽæ–‡è¡Œæ¥·这里可以使用下面的函数
// 用于编码
function encodeChinese(str) {
let encodeStr = '';
for (let s of str) {
if (s.codePointAt(0) > 255) {
let stringCodeArr = encodeURIComponent(s).split('%');
for (let i = 1; i < stringCodeArr.length; i++) {
encodeStr += String.fromCharCode(parseInt(stringCodeArr[i], 16));
}
} else {
encodeStr += s;
}
}
return encodeStr;
}
// 用于解码
function decodeChinese(str) {
let s = '';
for (let i = 0; i < str.length;) {
let binaryCode10 = str.charCodeAt(i),
binaryCode16 = (binaryCode10).toString(2).padStart(8, '0'),
index = (binaryCode16).split('').findIndex(item => item === '0');
if (index === 0) {
s += String.fromCharCode(binaryCode10);
i++;
} else {
let temp = '';
for (let j = 0; j < index; j++) {
let code = str.charCodeAt(i + j).toString(16);
temp += '%' + code;
}
s += temp;
i += index;
}
}
return decodeURIComponent(s);
}
例如,要设置字体为微软雅黑,12号,加粗,黑色,可以这么写:
font: {
name: 'microsoft yahei',
sz: 12,
color: { rgb: '000000' },
blod: true
}
最后再介绍fill,这个属性用来设置背景图案、前景色和背景色。这里背景色只有一个默认值,注意这里前景色相当于background-color。背景色指背景图案的颜色。由于是社区版,功能不全,因此如果设置了背景图案则背景色和前景色会失效。因此实际我们只需要关注前景色即可。
fill: {
fgColor: {
// 前景色
theme: 4,
tint: 0.5
},
bgColor: {
// 背景色
// 官方文档背景色的默认值为{ indexed: 64 }
theme: 4,
tint: 0.5
},
patternType: "grey0625" // 背景图案
}
// 注:如果我们需要知道一个背景图案的值,可以先在excel中设置好,再将这个excel转化为对象,但是由于官方文档patternType只给了none和solid两个可选项,因此最好不要使用patternType
接下来介绍怎么控制列宽,列宽使用一个数组存储,数组里每一项表示一列的宽度,使用wpx(像素)、wch(一个字符的宽度)作为单位。
!cols: [
{ wpx: 258 }, // 表示258px
{ wch: 14 } // 表示14个字符宽
]
// 注1:读取excel文件后发现!cols是一个二维数组,每个数组元素长度为0,里面有width,wpx,wch等属性。但我们导出excel时可以在!cols里面放置普通对象,这样更方便。
// 注2:如果没有设置列宽,或者只有某一列需要设置,则其余列的列宽为默认值,不需要设置为null。只需要设置需要设置列宽的列即可。
合并单元格需要使用!merges,!merges也是一个二维数组,数组每一项表示一个合并单元格。格式如下:
!merges: [
{
s: {
// s => start => 合并开始的单元格
c: 0, // 列下标
r: 0 // 行下标
},
e: {
// e => end => 合并结束的单元格
c: 1,
r: 0
}
}
]
// 与上同,导出时可以使用对象
3.3 js-xlsx和xlsx-style中的API
先谈谈js-xlsx中的常用方法。主要是XLSX.utils中的方法。
1. 生成workbook和sheet
// 生成一个空的workbook
let wb1 = XLSX.utils.book_new();
// 通过table生成workbook
let wb2 = XLSX.utils.table_to_book(document.getElementsByTagName('table')[0]);
// 使用json生成sheet 参数1:数组 参数2: 对象(对象内 header 表示表头,skipHeader 设置为 true 则省略表头)(参数1必传,参数2可不传)
let sheet1 = XLSX.utils.json_to_sheet([
{ A:"S", B:"h", C:"e", D:"e", E:"t", F:"J", G:"S" },
{ A: 1, B: 2, C: 3, D: 4, E: 5, F: 6, G: 7 },
{ A: 2, B: 3, C: 4, D: 5, E: 6, F: 7, G: 8 }
], {header:["A","B","C","D","E","F","G"], skipHeader:true});
// 使用二维数组生成 sheet 参数1:二维数组,二维数组内每个数组表示一行内容
let sheet2 = XLSX.utils.aoa_to_sheet([
"SheetJS".split(""),
[1,2,3,4,5,6,7],
[2,3,4,5,6,7,8]
]);
2. 在sheet中添加新数据
/*
* 1、使用 aoa_to_sheet 添加新数据,函数接受3个参数
*
* 参数1:一个 sheet 对象
* 参数2: 二维数组,即需要添加的数据
* 参数3:对象,origin 的值表示新数据开始添加的位置
*
* { origin: "A2" } 表示数据从excel表的 A2 单元格开始添加
* { origin: { r: 1, c: 4 } } 中 r 和 c 分别表示行号和列号(从 0 开始计数,{ r: 1, c: 4 } 表示第二行第五列对应的单元格)
* { origin: -1 } 表示从现有 sheet 表的最后一行下添加新行,从第一列到最后一列
* origin 默认值为 A1
*/
// 下面的代码生成如下格式的sheet表(第一行和第一列是模拟excel表的行号和列号)
XXX| A | B | C | D | E | F | G |
---+---+---+---+---+---+---+---+
1 | S | h | e | e | t | J | S |
2 | 1 | 2 | | | 5 | 6 | 7 |
3 | 2 | 3 | | | 6 | 7 | 8 |
4 | 3 | 4 | | | 7 | 8 | 9 |
5 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
/* 初始化一个sheet表,对应上图的第一行的 SheetJS */
var ws = XLSX.utils.aoa_to_sheet([ "SheetJS".split("") ]);
/* 从A2开始添加数据,对应上图从A2到B4的数据 */
XLSX.utils.sheet_add_aoa(ws, [[1,2], [2,3], [3,4]], { origin: "A2" });
/* 从E2开始添加数据,对应上图从E2到G4的内容 */
XLSX.utils.sheet_add_aoa(ws, [[5,6,7], [6,7,8], [7,8,9]], { origin: { r: 1, c: 4 } });
/* 添加一整行,对应上图最后一行内容 */
XLSX.utils.sheet_add_aoa(ws, [[4,5,6,7,8,9,0]], { origin: -1 });
/*
* 2、使用 sheet_add_json 添加新数据
* 参数1:数组 [ obj1, obj2, ... ]
* 参数2:对象,除了 header 、skipHeader , 还可以设置 origin
*/
// 下面代码和上述 sheet_add_aoa 效果一致
/* Initial row */
var ws = XLSX.utils.json_to_sheet([
{ A: "S", B: "h", C: "e", D: "e", E: "t", F: "J", G: "S" }
], {header: ["A", "B", "C", "D", "E", "F", "G"], skipHeader: true});
/* Write data starting at A2 */
XLSX.utils.sheet_add_json(ws, [
{ A: 1, B: 2 }, { A: 2, B: 3 }, { A: 3, B: 4 }
], {skipHeader: true, origin: "A2"});
/* Write data starting at E2 */
XLSX.utils.sheet_add_json(ws, [
{ A: 5, B: 6, C: 7 }, { A: 6, B: 7, C: 8 }, { A: 7, B: 8, C: 9 }
], {skipHeader: true, origin: { r: 1, c: 4 }, header: [ "A", "B", "C" ]});
/* Append row */
XLSX.utils.sheet_add_json(ws, [
{ A: 4, B: 5, C: 6, D: 7, E: 8, F: 9, G: 0 }
], {header: ["A", "B", "C", "D", "E", "F", "G"], skipHeader: true, origin: -1});
3. 将sheet加入workbook
let wb = XLSX.utils.book_new(),
sheet = XLSX.utils.json_to_sheet(jsonData);
XLSX.utils.book_append_sheet(wb, sheet, "Sheet1"); // 参数1: workbook 参数2:sheet 参数3:sheet的名字
4. 生成Excel对应的下标(这个函数xlsx-style也有,用法相同)
// 1、encode_cell
let cell_address = {
c: 0,
r: 0
};
XLSX.utils.encode_cell(cell_address); // 'A1'
// 2、decode_cell
XLSX.utils.decode_cell('A1'); // { c: 0, r: 0 }
// 3、encode_range
let range_address = {
s: { c: 0, r: 0 },
e: { c: 3, r: 3 }
};
XLSX.utils.encode_range(range_address); // 'A1:D4'
// 4、decode_range
XLSX.utils.decode_range('A1:D4');
/* {
s: { c: 0, r: 0 },
e: { c: 3, r: 3 }
}*/
5. 将sheet转为数组(xlsx-style也有)
XLSX.utils.sheet_to_aoa(sheet); // 转为二维数组,数组每一项是excel一行的文字,这个xlsx-style没有
XLSX.utils.sheet_to_json(sheet); // 转为一维数组,数组每一项是一个对象,对象的键名为第一行的内容,这个方法xlsx-style也有,用法一致
6. 读取excel文件(xlsx-style也有)
XLSX.read(data, {})
// 将input文件选择按钮得到的文件数据转为workbook对象
// 第一个参数是文件数据,根据第二个参数传入的type进行传参,第二个参数代表数据类型等
// 第二个参数是一个对象,属性type可以传以下值:
type |
对应第一个参数需要传入的类型 |
|---|---|
| array | 传入Uint8Array格式的ArrayBuffer(这个只有js-xlsx可用) |
| binary | 传入FileReader的readAsBinaryString方法调用后的返回值 |
注:这里其实官方文档有很多类型,但是测试后发现能用的只有这两个。
下面这些属性只在xlsx-style插件中生效:
| 属性名 | 默认值 | 含义 |
|---|---|---|
| cellStyles | false | 是否返回样式,如果设为true,则单元格样式会保存在 .s 中 |
| cellFormula | true | excel中的公式默认保存在.f中 |
| bookSteets | false | 如果设为true则只返回sheetNames |
7. 导出excel文件(xlsx-style也有)
XLSX.write(workbook, {})
// 将特定格式数据转化为excel可识别的格式
// 第一个参数为WorkBook对象
// 第二个参数常用配置选项为 type(传入数据类型) bookType(导出文件类型,默认为xlsx,还可以传xlsm和xlsb) bookSST(默认为false,传true则兼容性更好,但是性能差一些,需要更多的内存)
| type | 返回的数据类型 |
|---|---|
| binary | 返回一个二进制字符串,每个字符占据一个字节 |
| array | 返回一个ArrayBuffer数组(只有js-xlsx可用) |
3.4 导入excel文件
这里使用的是xlsx-style插件,由于js-xlsx和xlsx-style都使用的XLSX对象,因此如果要同时使用两个插件则需要修改源码。这里为了方便则不使用js-xlsx
<input type="file" id="fileBtn" />
uploadFun() {
let file = document.getElementById('fileBtn').files[0],
reader = new FileReader(),
resultData = [];
reader.addEventListener('load', function () {
let workbook = XLSX.read(reader.result, {
type: 'binary',
// cellStyles: true,
// cellDates: true,
// cellFormula: true
}),
data = XLSX.utils.sheet_to_json(workbook.Sheets[workbook.SheetNames[0]]);
for (let key in data[0]) {
resultData .push({
prop: key,
label: key
});
}
return resultData;
});
reader.readAsBinaryString(file);
}
3.5 导出excel文件
// 两个参数均是json数组(和element-ui里面的el-table的数据格式相同),数组里面每一项是一个对象
exportFun(tableHead, tableData) {
let array = [],
temp = [];
tableHead.forEach(item => {
temp.push(item.label);
});
array.push(temp);
tableData.forEach(item => {
let arr = [];
for (let key in item) {
arr.push(item[key]);
}
array.push(arr);
});
let wb = new Workbook(),
sheet = {},
range = {
s: {
c: 0,
r: 0
},
e: {
c: 10,
r: 10
}
};
for (let R = 0; R < array.length; R++) {
for (let C = 0; C < array[R].length; C++) {
if (range.s.c > C) {
range.s.c = C;
}
if (range.s.r > R) {
range.s.r = R;
}
if (range.e.c < C) {
range.e.c = C;
}
if (range.e.r < R) {
range.e.r = R;
}
let cell = {
v: array[R][C]
};
if (myTypeof(cell.v) === "number") {
cell.t = "n";
} else if (myTypeof(cell.v) === "boolean") {
cell.t = "b";
} else if (myTypeof(cell.v) === "date") {
cell.t = "n";
cell.v = cell.v.getTime();
} else {
cell.t = "s";
}
cell.s = {
alignment: {
vertical: "center",
horizontal: "center"
},
fill: {
// bgColor: {
// theme: "5"
// },
fgColor: {
theme: "3"
},
// patternType: "gray0625"
},
font: {
sz: "10",
color: {
theme: "1"
}
},
border: {
top: {
style: 'thin',
color: {
theme: "1"
}
},
bottom: {
style: 'thin',
color: {
theme: "1"
}
},
left: {
style: 'thin',
color: {
theme: "1"
}
},
right: {
style: 'thin',
color: {
theme: "1"
}
},
}
}
let cell_address = {
c: C,
r: R
},
cell_ref = XLSX.utils.encode_cell(cell_address),
range_ref = XLSX.utils.encode_range(range);
sheet[cell_ref] = cell;
sheet["!ref"] = range_ref;
}
}
sheet["!cols"] = [];
this.tableHead.forEach(item => {
sheet["!cols"].push({
wch: 10
});
});
wb.SheetNames.push('sheet1');
wb.Sheets[wb.SheetNames[0]] = sheet;
console.log(wb)
let finalData = XLSX.write(wb, {
type: "binary",
bookType: "xlsx"
});
console.log(finalData)
let blob = new Blob([s2ab(finalData)], {
type: "application/octet-stream" // application/octet-stream 表示任意二进制类型
});
download(blob, '测试');
}
}
});
function Workbook() {
if (!this instanceof Workbook) {
return new Workbook();
}
this.Sheets = [];
this.SheetNames = [];
}
function myTypeof(value) {
let type = typeof value;
if (type === "object") {
type = Object.prototype.toString.call(value).match(/\[object\s+?(\w+)\]/)[1].toLowerCase();
}
return type;
}
function s2ab(value) {
let buffer = new ArrayBuffer(value.length),
uint = new Uint8Array(buffer);
for (let i = 0; i < value.length; i++) {
uint[i] = value.charCodeAt(i) & 0x00ff; // 这里主要是获取二进制数据,& 0x00ff的目的在于保证补码的一致性,保证生成无符号的8位二进制视图
}
return buffer;
}
function download(blob, filename) {
let a = document.createElement('a'),
url = URL.createObjectURL(blob);
a.href = url;
a.download = filename + '.xlsx';
a.click();
document.body.appendChild(a);
URL.revokeObjectURL(url);
document.body.removeChild(a);
}
参考链接
[1]阮一峰-ES6教程