实施工程师&运维工程师面试题

Linux
1.请使用命令行拉取SFTP服务器/data/20221108/123.csv 文件,到本机一/data/20221108目录中。
使用命令行拉取SFTP服务器文件到本机指定目录,可以使用sftp命令。假设SFTP服务器的IP地址为192.168.1.100,用户名为username,密码为password,要拉取的文件路径为/data/20221108/123.csv,目标路径为本机/data/20221108目录中,可以执行以下命令:
bash
sftp username@192.168.1.100 -o password=password <<EOF
get /data/20221108/123.csv /data/20221108/
bye
EOF
其中,-o password=password指定密码,<<EOF和EOF之间的内容为sftp命令。
2.有一个备份程序mybackup,需要在周一至周五下午1点和晚上8点各运行一次,使用crontab来完成这项工作?
crontab -e
0 13 * * 1-5 mybackup
0 20 * * 1-5 mybackup
或者
crontab -e
0 13,20 1-5 mybackup
3.使用命令行查看linux服务器中,8080端口的占用情况
netstat -anp | grep 8080
或者
sudo lsof -i:8080
或者
netstat -tnlp | grep 8080
4.有一个java应用程序报错,报错信息为:“Caused by: MetaException(message:Filtering is supported only on partition keys of type string)”项目日志目录/app/bdmeth/QueryServer/logs/query.20221108.log如何查询报错的上下文信息。
grep "Caused by: MetaException(message:Filtering is supported only on partition keys of type string)" /app/bdmeth/QueryServer/logs/query.20221108.log
或者
grep -i "Caused by: MetaException" /app/bdmeth/QueryServer/logs/query.20221108.log
5、请简述linux服务器之间免密互信操作流程
第一步:生成密钥(包括公钥 id_rsa 和私钥 id_rsa.pub)
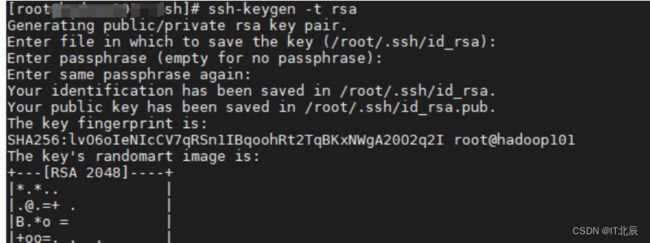
命令:ssh-keygen -t rsa
说明:
Enter file in which to save the key (/root/.ssh/id_rsa): 的意思是保存私钥的路径默认为
(/root/.ssh/id_rsa) 确定即可
Enter passphrase (empty for no passphrase): 给私钥加密, 默认为空
Enter same passphrase again: 确定上一步的密码
第二步:保存公钥到authorized_keys
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
可以继续输入命令:cat ~/.ssh/authorized_keys [进行查看公钥是否已经保存到这里]
此时继续输入命令:ssh hadoop101 [就能进行自连接]
说明:
这个authorized_key 文件夹本身是没有的 cat 过去就会有
那为什么要取这个名字 :系统认这个 。(暂时这么解释)
第三步:发送公钥到其他服务器
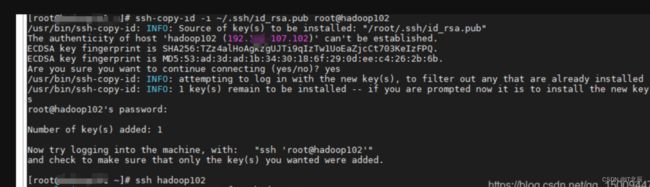
命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop102
输入命令:ssh hadoop102 [看看能不能连接]
说明:
发送命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop102 的时候 在hadoop102服务器那边也会在家目录生成 .ssh/ authorized_keys
发送ssh hadoop102 请求的时候 会输入hadoop102的密码
后面再执行就不用输了
前三步实现了hadoop101的自连接 和 对 hadoop102的连接
第四步:hadoop102 进行自连接 和对 hadoop101的连接
命令:ssh-keygen -t rsa [生成hadoop102的公钥和私钥]
命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [保存公钥到authorized_keys,注意这边要用 >> 追加 而不能用 > 覆盖 因为 hadoop102 的authorized_keys 里面 已经有 第三步hadoop101发过来的公钥了 ]
输入命令: ssh hadoop102 [看看能不能自连]
输入命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop101 [发送公钥到hadoop101的authorized_keys ,可以在hadoop101 服务器输入命令:cat ~/.ssh/authorized_keys 查看]
说明:
id_rsa // 私钥文件
id_rsa.pub // 公钥文件
authorized_keys // 存放客户端公钥的文件
known_hosts // 确认过公钥指纹的可信服务器列表的文件
以上几步完成了两个服务器之间的免密互连 多台之间的连接,也是差不多的 ,多台连接的本质还是两台两台连 。连接期间肯定会有很多异常和报错 要看清楚是什么原因 ,登录其他服务器之后 如果还要继续对本服务器操作的话 最好先exit 断开一下 操作比较干净。

二、SQL
1.编写一个SQL查询,查找Person表中所有重复的电子邮箱。
示例:
| Id | |
|---|---|
| 1 | apb.com |
| 2 | cod.com |
| 3 | apb.com |
根据以上输入,你的查询应返回议下结果
| apb.com |
说明:所有电子邮箱都是小写字母。
创建表:
CREATE TABLE `person` (
`ID` int NOT NULL,
`Email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
INSERT INTO `person` VALUES (1, 'apb.com');
INSERT INTO `person` VALUES (2, 'cod.com');
INSERT INTO `person` VALUES (3, 'apb.com');
解决SQL:
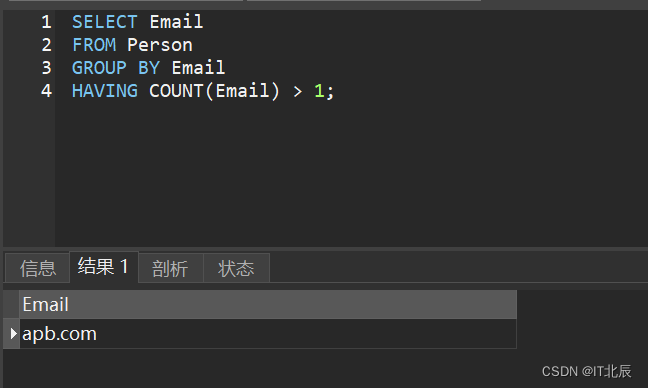
SELECT Email
FROM Person
GROUP BY Email
HAVING COUNT(Email) > 1;
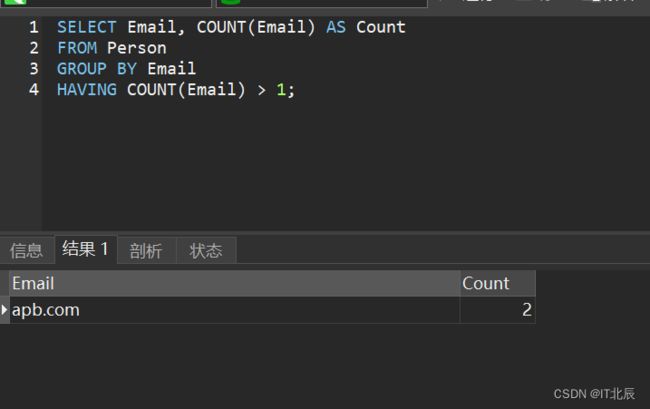
看一下统计数
SELECT Email, COUNT(Email) AS Count
FROM Person
GROUP BY Email
HAVING COUNT(Email) > 1;
2.编写 SQL 查询以查找每个部门中薪资最高的员工。按任意顺序返回结果表。
表:Employee
| 列名 | 类型 |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
id是此表的主键列。
departmentId是Department表中ID的外键。
此表的每一行都表示员工的ID、姓名和工资。它还包含他们所在部门的ID。
表:Department
| 列名 | 类型 |
|---|---|
| id | int |
| name | varchar |
id是此表的主键列。
此表的每一行都表示一个部门的ID及其名称。
CREATE TABLE Department (
id INT PRIMARY KEY,
name VARCHAR(255)
);
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(255),
salary INT,
departmentId INT,
FOREIGN KEY (departmentId) REFERENCES Department(id)
);
INSERT INTO Department (id, name) VALUES (1, 'Sales');
INSERT INTO Department (id, name) VALUES (2, 'Marketing');
INSERT INTO Employee (id, name, salary, departmentId) VALUES (1, 'John Doe', 5000, 1);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (2, 'Jane Smith', 6000, 1);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (3, 'Mike Johnson', 5500, 2);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (4, 'Emily Davis', 6500, 2)


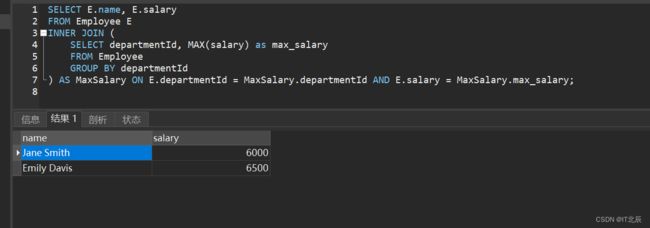
SELECT E.name, E.salary
FROM Employee E
INNER JOIN (
SELECT departmentId, MAX(salary) as max_salary
FROM Employee
GROUP BY departmentId
) AS MaxSalary ON E.departmentId = MaxSalary.departmentId AND E.salary = MaxSalary.max_salary;
第二种:
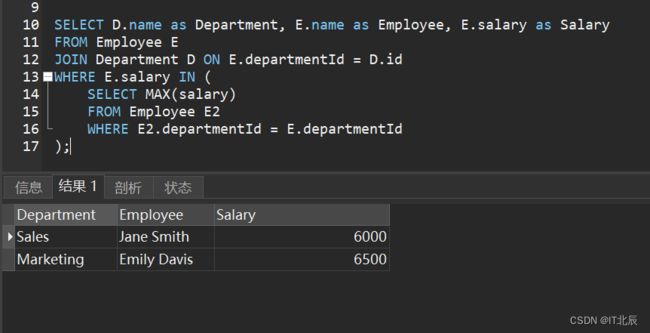
SELECT D.name as Department, E.name as Employee, E.salary as Salary
FROM Employee E
JOIN Department D ON E.departmentId = D.id
WHERE E.salary IN (
SELECT MAX(salary)
FROM Employee E2
WHERE E2.departmentId = E.departmentId
);
解释:
SELECT D.name as Department, E.name as Employee, E.salary as Salary: 这一行表示我们想从查询结果中选择哪些字段。具体来说,我们想要获取Department的名称(别名为D.name),员工(别名为E.name)以及他们的工资(别名为E.salary)。
FROM Employee E: 这一行说明我们将从名为Employee的表中开始查询,并为这个表设置了一个别名E。
JOIN Department D ON E.departmentId = D.id: 这一行是一个JOIN操作,它用于将Employee表和Department表连接在一起。连接条件是员工表中的departmentId与部门表中的id相等。为Department表设置了一个别名D。
WHERE E.salary IN ( ... ): 这一行是一个子查询,它筛选出工资最高的员工。子查询如下:
SELECT MAX(salary) FROM Employee E2 WHERE E2.departmentId = E.departmentId: 这个子查询从Employee表中找出每个部门的最高工资。MAX(salary)会返回每个部门中最大的工资值。
总的来说,这个查询是为了找出每个部门中工资最高的员工及其工资。它首先通过子查询找出每个部门的最高工资,然后在主查询中根据这些最高工资值筛选出对应的员工信息。